菜鸟学IT之豆瓣爬取初体验
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
可以用pandas读出之前保存的数据:
newsdf = pd.read_csv(r'F:\duym\gzccnews.csv')
截图:
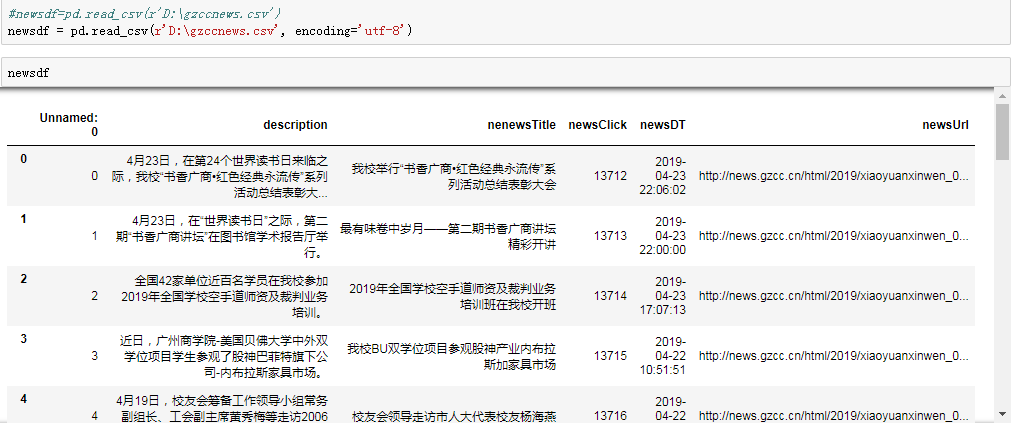
一.把爬取的内容保存到数据库sqlite3
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnews',con = db)
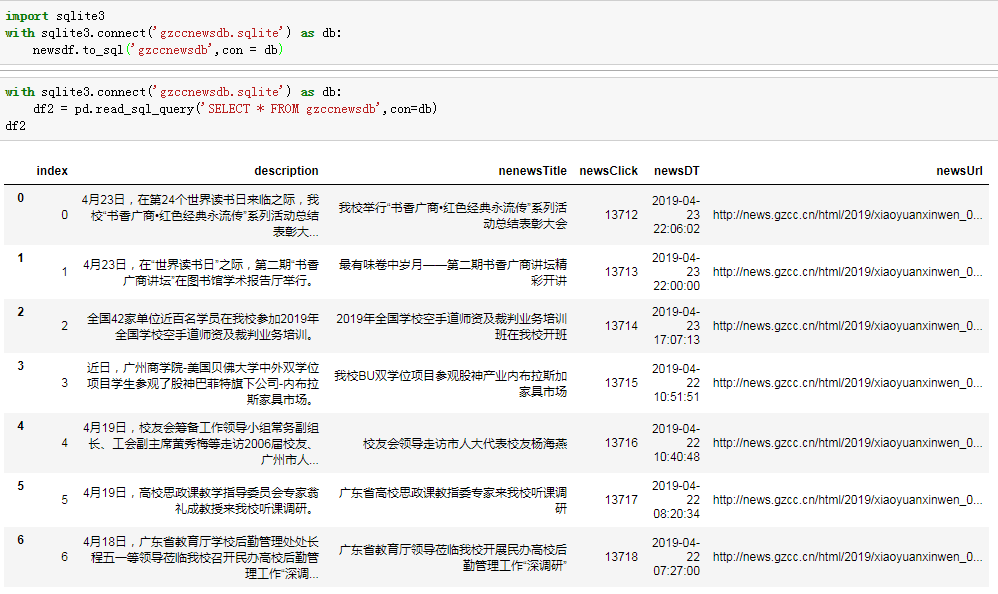
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('SELECT * FROM gzccnews',con=db)
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
newsdf.to_sql('gzccnewsdb',con = db)
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pd.read_sql_query('SELECT * FROM gzccnewsdb',con=db)
df2
效果截图:
保存到MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
import pymysql
from sqlalchemy import create_engine
coninfo='mysql+pymysql://root:@localhost:3306/gzccnews?charset=utf8'
engine=create_engine(coninfo,encoding='utf-8') newsdf.to_sql(name='news',con = coninfo,if_exists='append',index=False)
conn=pymysql.connect(host='localhost',port=3306,user='root',passwd='',db='gzccnews',charset='utf8')xiaoguo
效果截图:

二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
本次作业主题是爬取中国豆瓣影评战狼2:https://movie.douban.com/subject/26363254/

吴京主导的战狼系列之战狼3正在火热拍摄中,战狼粉丝们也在期许中。回顾战狼系列曾经战狼2拍摄是“负资累累”才拍摄完毕,但是成果也是巨大的。《战狼2》是中国电影界第一部走出去的电影,也是中国第一部跻身全球票房100强的中国电影。网上论坛对战狼2的影评也是议论纷纷,有好的,有坏的。下面小编就爬取豆瓣网战狼2的影评信息来了解战狼2粉丝的评论。
1.获取豆瓣网url
https://movie.douban.com/subject/26363254/comments/start=20&limit=20&sort=new_score\&status=P&percent_type=''&comments_only=1
- id # ID
- username# 用户名
- user_center # 用户主页链接
- vote # 赞同这条评论的人数
- star # 开始爬取的条数
- time # 时间
- content # 评论
对数据进行爬取:
# 构造函数
def __init__(self, movie_id, start, type=''):
'''
:type: 评论
:movie_id: 影片的ID号
:start: 开始的记录数,0-480
'''
self.movie_id = movie_id
self.start = start
self.type = type
self.url = 'https://movie.douban.com/subject/{id}/comments?start={start}&limit=20&sort=new_score\&status=P&percent_type={type}&comments_only=1'.format(
id=str(self.movie_id),
start=str(self.start),
type=self.type
)
# 创建数据库连接
self.session = create_session()
f _get(self):
self._random_UA() # 调用随机产生的User-Agent
res = '' # res定义字符串 # 获取网页信息并爬取
try:
res = requests.get(self.url, cookies=self.cookies, headers=self.headers,proxies=self.proxies)
time.sleep(random.random() * 3)
res = res.json()['html']
# 返回的数据为json数据,需要提取里面的HTML
except Exception as e:
print('IP被封,请使用代理IP')
print('正在获取{} 开始的记录'.format(self.start))
return res
对数据进行整理:
def _parse(self):
res = self._get()
dom = etree.HTML(res)
# id号
self.id = dom.xpath(self.base_node + '/@data-cid')
# 用户名 所有div节点下class名叫avatar的节点下面的a标签
self.username = dom.xpath(self.base_node + '/div[@class="avatar"]/a/@title')
# 用户连接
self.user_center = dom.xpath(self.base_node + '/div[@class="avatar"]/a/@href')
# 点赞数
self.vote = dom.xpath(self.base_node + '//span[@class="votes"]/text()')
# 评分
self.star = dom.xpath(self.base_node + '//span[contains(@class,"rating")]/@title')
# 发表时间
self.time = dom.xpath(self.base_node + '//span[@class="comment-time "]/@title')
# 评论内容 所有span标签class名为short的节点文本
self.content = dom.xpath(self.base_node + '//span[@class="short"]/text()')
if __name__ == '__main__':
# [综合评论、好评、中评、差评]
for i in ['', 'h', 'm', 'l']:
# 最多爬取24页
for j in range(1,30):
fetcher = CommentFetcher(movie_id=26363254, start=j * 20, type=i)
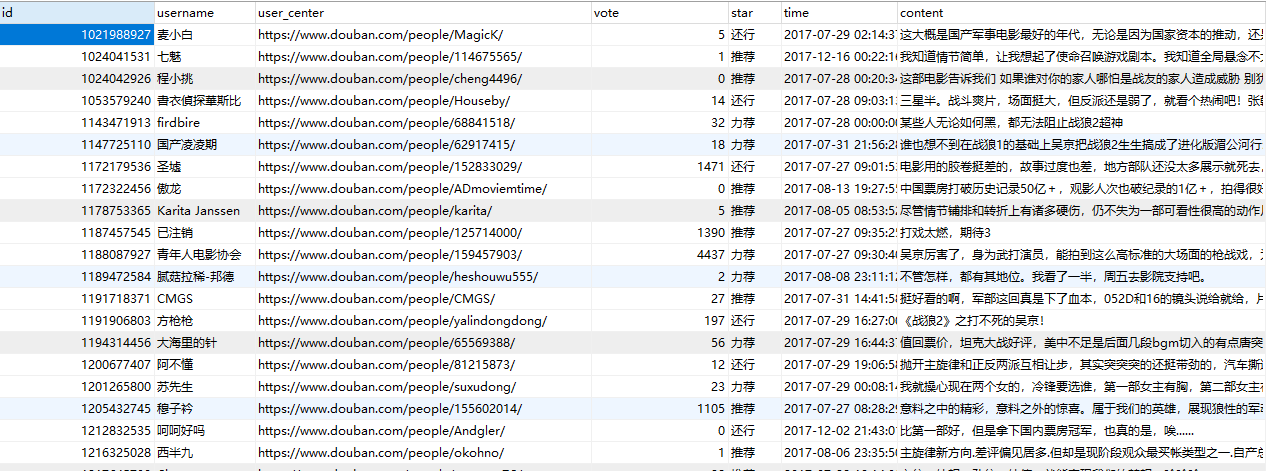
数据截图:
- 通过xpath函数解析html文本,增加爬取效率
2. 使用代理IP
IP =[" http://10.10.1.10:3128",
" http://10.10.1.10:1080",
"http://110.88.126.70"] #随机调用代理IP
def _random_IP(self):
self.proxies["http:"] = random.choice(IP)
由于爬取数据比较多,为防止豆瓣网监控封取IP,故使用代理IP.(由于这些IP都是西刺网上的免费的代理IP,故有效时长不长获取的数据也不完整)
3.在SQL创建表
from sqlalchemy import Column, String, create_engine, Integer, Text, DateTime
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker # 初始化数据库连接
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/douban?charset=utf8')
Base = declarative_base() class Comments(Base): __tablename__ = 'test' id = Column(Integer, primary_key=True) # ID
username = Column(String(64), nullable=False, index=True) # 用户名
user_center = Column(String(64), nullable=True) # 用户主页链接
vote = Column(Integer, nullable=True) # 赞同这条评论的人数
star = Column(String(10), nullable=True) # 开始爬取的条数
time = Column(DateTime, nullable=True) # 时间
content = Column(Text(), nullable=False, index=True) # 评论 def create_session():
# 创建DBSession类型:
Session = sessionmaker(bind=engine)
session = Session()
return session if __name__ == '__main__':
#创建数据表
Base.metadata.create_all(engine)
4.使用jieba进行中文过滤
import pandas as pd
from wordcloud import WordCloud
import jieba
import matplotlib.pyplot as plt
import PIL.Image as image
import numpy as np txt = open(r'G:\aa\zhanlang2.txt', 'r', encoding='utf8').read() # 打开评论数据
jieba.load_userdict(r'G:\aa\ZL2.txt') # 读取战狼2词库 Filess= open(r'G:\aa\stops_chinese.txt', 'r', encoding='utf8') # 打开中文停用词表
stops = Filess.read().split('\n') # 以回车键作为标识符把停用词表放到stops列表中 wordsls = jieba.lcut(txt) # 使用jieba中文分词组件
wcdict = {} tokens=[token for token in wordsls if token not in stops]
print("过滤后中文内容对比:",len(tokens), len(wordsls)) # 统计词频次数
for word in tokens:
if len(word) == 1:
continue
else:
wcdict[word] = wcdict.get(word, 0) + 1 # 词频排序
wcls = list(wcdict.items())
wcls.sort(key=lambda x: x[1], reverse=True) # 打印前30词频最高的中文
for i in range(20):
print(wcls[i]) # 存储过滤后的文本
pd.DataFrame(wcls).to_csv('2.csv', encoding='utf-8') # 读取csv词云
txt = open('2.csv', 'r', encoding='utf-8').read() # 用空格键隔开文本并把它弄进列表中
cut_text = "".join(jieba.lcut(txt)) mywc = WordCloud().generate(cut_text) plt.imshow(mywc)
plt.axis("off")
plt.show()
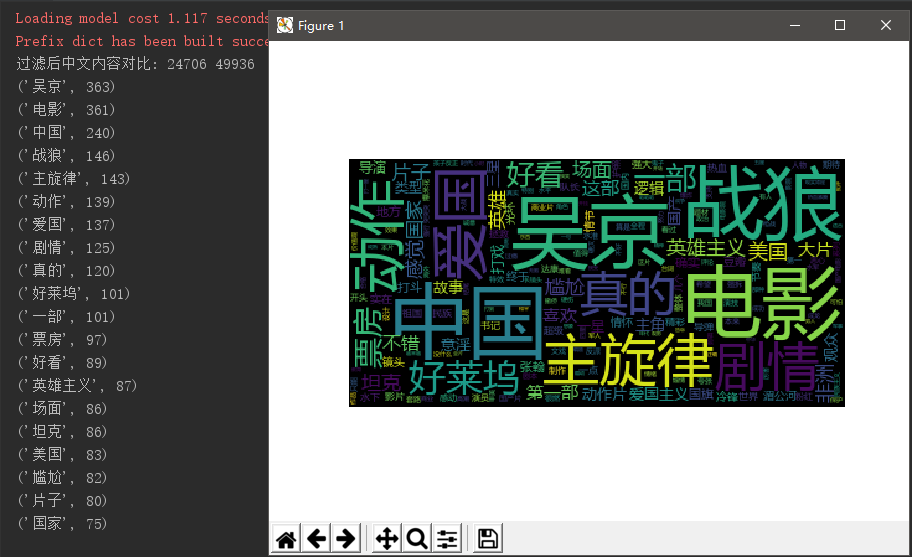
- 根据jieba分词后词频统计前20可以看出,这部片是吴京主演。根据“国家”与“爱国”两个字可以推测的出剧情有爱国表现,以及国家与国家的对抗的。“坦克”也可以看的战争情景震撼。“好看”一词也表达了观众对这部影评大体来说是满意的。
5.评分等级
import matplotlib
import matplotlib.pyplot as plt #显示中文
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
matplotlib.rcParams['axes.unicode_minus'] = False
#631137
alt=[124965,215218,198808,56171,35975]
index='力荐', '推荐', '还行', '较差','很差'
plt.axes(aspect=1)
plt.pie(x=alt,labels=index,autopct='%.0f%%')
plt.show()
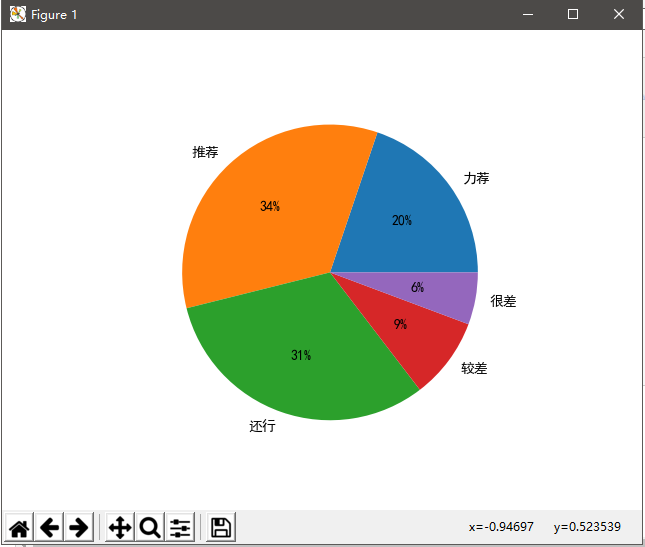
- 由图形表可以看出80%以上的人看影片都觉得不错。仅15%左右的小伙伴可能觉得对这部影片期许度过高导致对这部影片不理想吧。
6.总结
在这次爬取过程中得到了许多,遇到的困难也比较多。由于爬取的数据量比较大,豆瓣识别IP并封停IP号。随后我尝试使用免费的代理IP号进行数据的爬取,为了再一次被封IP,我每一次爬取时间随机间隔爬取,以及使用代理IP随机爬取故而爬取效率变得很低,并且爬取是单线程爬取,爬取效率也是十分的低。
在第二次想要爬取用户地理位置时,由于访问次数太多。豆瓣系统识别我的IP,并且把我的账号永久封号故而无法再进一步爬取地理数据。网上的代理免费的代理IP也失效了,问题随着知识的增长每一次都会发现新的问题,我相信经过自己不断汲取知识,争取爬取整个豆瓣的详细数据。
菜鸟学IT之豆瓣爬取初体验的更多相关文章
- 菜鸟学IT之python网页爬取初体验
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2881 1. 简单说明爬虫原理 爬虫简单来说就是通过程序模拟浏览器放松请求站 ...
- 菜鸟学IT之python词云初体验
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2822 1. 下载一长篇中文小说. 2. 从文件读取待分析文本. txt = ...
- Python爬虫:现学现用xpath爬取豆瓣音乐
爬虫的抓取方式有好几种,正则表达式,Lxml(xpath)与BeautifulSoup,我在网上查了一下资料,了解到三者之间的使用难度与性能 三种爬虫方式的对比. 这样一比较我我选择了Lxml(xpa ...
- python学习(七)--豆瓣爬取电影名,评分以及演员
import requestsimport re #爬取豆瓣电影排名pageNum = int(input("要查看第几页电影分数:"))#已知豆瓣默认每页展示20条#url= & ...
- crawler碎碎念5 豆瓣爬取操作之登录练习
import requests import html5lib import re from bs4 import BeautifulSoup s = requests.Session() #这里要提 ...
- 菜鸟学python之大数据的初认识
这次作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2639 1.这些分析所采用数据来源是什么? 国家数据库:中国铁路 ...
- crawler碎碎念6 豆瓣爬取操作之获取数据
import requests from lxml import etree s = requests.Session() for id in range(0,251,25): url ='https ...
- Scrapy 通过登录的方式爬取豆瓣影评数据
Scrapy 通过登录的方式爬取豆瓣影评数据 爬虫 Scrapy 豆瓣 Fly 由于需要爬取影评数据在来做分析,就选择了豆瓣影评来抓取数据,工具使用的是Scrapy工具来实现.scrapy工具使用起来 ...
- python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记. 第 ...
随机推荐
- v8--sort 方法 源码 (1) 插入排序法
v8--sort方法源码中对于长度较短的数组使用的是插入排序法. 部分源码: function InsertionSort(a, from, to) { for (var i = from + 1; ...
- Android存储及getCacheDir()、getFilesDir()、getExternalFilesDir()、getExternalCacheDir()区别
存储介绍 Android系统分为内部存储和外部存储,内部存储是手机系统自带的存储,一般空间都比较小,外部存储一般是SD卡的存储,空间一般都比较大,但不一定可用或者剩余空间可能不足.一般我们存储内容都会 ...
- 【RMAN】RMAN脚本中使用替换变量
[RMAN]RMAN脚本中使用替换变量--windows 下rman全备脚本 一.1 BLOG文档结构图 一.2 前言部分 一.2.1 导读 各位技术爱好者,看完本文后,你可以掌握如下的技能,也 ...
- js 数组去重求和 (转载)
方法一:js数组id去重,value值相加问题 来源:https://www.jianshu.com/p/8f79e31b46ed // js let arr = [ { id: 1, value: ...
- 自定义View(二),强大的Canvas
本文转自:http://www.jcodecraeer.com/a/anzhuokaifa/androidkaifa/2012/1212/703.html Android中使用图形处理引擎,2D部分是 ...
- python关于time几种格式处理方法总结
一.日期时间的表示方法: 时间戳 timestamp: 简介:时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量,是一个float类型 展示形式:1575278720.331 时间 ...
- 美好的童年伙伴:360 智能儿童手表 P1体验评测
写在前面 少年儿童作为祖国的花朵,未来的栋梁,也是我们每个做家长的心头肉.近年来各种新闻报道中校园欺凌.虐待事件频发,虽然依然只是个别事件,但我们依然会心怀担忧. 360作为安防软件起家的专业公司,凭 ...
- TCN时间卷积网络——解决LSTM的并发问题
TCN是指时间卷积网络,一种新型的可以用来解决时间序列预测的算法.在这一两年中已有多篇论文提出,但是普遍认为下篇论文是TCN的开端. 论文名称: An Empirical Evaluation of ...
- Subsequence(HDU3530+单调队列)
题目链接 传送门 题面 题意 找到最长的一个区间,使得这个区间内的最大值减最小值在\([m,k]\)中. 思路 我们用两个单调队列分别维护最大值和最小值,我们记作\(q1\)和\(q2\). 如果\( ...
- 按键精灵PC端脚本
定义变量的时候不需要定义类型 ,由于是易语言,变量名可以是中文 文本路径 = "C:\Users\Administrator\Desktop\1.txt"//改成自己的文本路径 T ...