python+正则提取+ip代理爬取糗事百科文字信息
很多网站都有反爬措施,最常见的就是封ip,请求次数过多服务器会拒绝连接,如图;

在程序中设置一个代理ip,可有效的解决这种问题,代码如下;
# 需要的库
import requests
import re
from multiprocessing import Pool
# 设置代理ip
proxy = {
'https':'111.231.140.109:8888'
}
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
# 主函数
def get_character(url):
# 请求网页,里面加入代理ip
response = requests.get(url,headers,proxies=proxy)
# 正则提取内容(作者昵称,内容,好笑数量,评论数量)
data = re.findall('<h2>(.*?)</h2>.*?<div class="content">.*?<span>(.*?)</span>.*?</div>.*?<span class="stats-vote">.*?'
'<i class="number">(.*?)</i>(.*?)</span>.*?<i class="number">(.*?)</i>(.*?)</a>',response.text,re.S)
# 遍历获取到的数据
for i in data:
# 以追加方式写入当前文件加下的qiubai.txt
with open('qiubai.txt','a+',encoding='utf8') as f:
# 转换为字符串格式,去空格,替换掉多余内容每条内容加换行
f.write(str(i).strip().replace(r'\n','')+'\n')
# 控制台打印查看爬取过程
print(str(i).strip().replace(r'\n','')+'\n') # 程序入口
if __name__ == '__main__':
# 构造所有url
urls = ['https://www.qiushibaike.com/text/page/{}/'.format(i) for i in range(1,14)]
# 开启多进程
pool = Pool()
# 启动程序
pool.map(get_character,urls)
print('爬取完毕')
控制台输出;
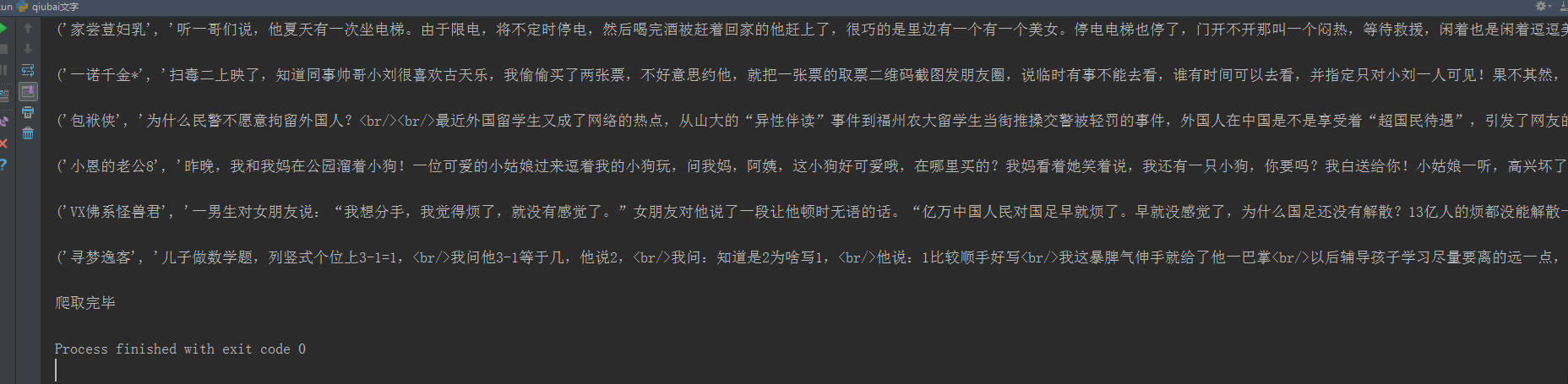
打开文件夹查看是否下载成功;

done
python+正则提取+ip代理爬取糗事百科文字信息的更多相关文章
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- 8.Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- python爬虫29 | 使用scrapy爬取糗事百科的例子,告诉你它有多厉害!
是时候给你说说 爬虫框架了 使用框架来爬取数据 会节省我们更多时间 很快就能抓取到我们想要抓取的内容 框架集合了许多操作 比如请求,数据解析,存储等等 都可以由框架完成 有些小伙伴就要问了 你他妈的 ...
- python_爬虫一之爬取糗事百科上的段子
目标 抓取糗事百科上的段子 实现每按一次回车显示一个段子 输入想要看的页数,按 'Q' 或者 'q' 退出 实现思路 目标网址:糗事百科 使用requests抓取页面 requests官方教程 使用 ...
- [爬虫]用python的requests模块爬取糗事百科段子
虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更 ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
随机推荐
- js:如何在iframe重载前执行特定动作
问题说明: 点击左侧菜单时,右侧页面中的iframe加载菜单内容,在iframe加载的页面A中使用了websocket.点击其它菜单时,无法主动关闭websocket, 可能会造成websocket链 ...
- 恋恋山城 Jean de Florette (1986) 男人的野心 / 弗洛莱特的若望 / 让·德·弗罗莱特 / 水源 下一部 甘泉,玛侬
<让·德·弗洛莱特>电影剧本 文/[法]马赛尔·巴涅尔译/苏原 编者按:<让·德·弗洛莱特>和<甘泉,玛侬>是根据法国著名作家马赛尔·巴涅尔的同名小说改编的电影.马 ...
- 【ARM-Linux开发】Linux模块机制浅析
Linux模块机制浅析 Linux允许用户通过插入模块,实现干预内核的目的.一直以来,对linux的模块机制都不够清晰,因此本文对内核模块的加载机制进行简单地分析. 模块的Hello World! ...
- 20190726_安装CentOS7minimal版本后需要做的优化和配置
20190726_安装CentOS7minimal版本后需要做的优化和配置 CentOS系统镜像下载地址:https://www.centos.org/ CentOS的Minimal(最小化安装版本) ...
- git revert commitid
是生成一个和commitid的提交完全相反的提交.类似倒转.
- idea springboot启动报SLF4J:Failed to load class “org.slf4j.impl.StaticLoggerBinder”
<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artif ...
- 学java必须知道的那些queue
队列是我们学java必须接触到的知识,很多内容都和它相关,但是你真的了解它们的概念和使用方法吗?在本文,你可以获取关于queue的一切信息,希望我能够帮助你在java的学习道路上乘风破浪. 概念 队列 ...
- maven系列:archetype项目模板_create-from-project
主要介绍create-from-project插件在命令行下的使用. [第一步:生成模板项目] 新建一个maven项目,比如叫 :groupId=com.abc.demo,artifactId=com ...
- Wampserver图标黄色解决
本文章是参考了该网址https://jingyan.baidu.com/article/48b37f8d0a02811a6564887b.html 安装了Wampserver后,并对httped.co ...
- linux端口映射
参考文章: http://jingyan.baidu.com/article/ed15cb1b2a332e1be36981ed.html http://www.myhack58.com/Article ...