数据库系列(五)之 mysql的伸缩性
这篇文章,主要讲述mysql的伸缩性。在国内mysql一直都是使用得最多的数据库,在国外也排名前三。mysql是一款开源的、性能较高的数据库。
伸缩性是指在软件设计中,软件(数据库、应用程序)通过特定的配置或升级,可以进行横向或纵向扩展,来达到软件适应越来越多用户访问的目的。数据库达到一定瓶颈,需要考虑伸缩性,这是大部分软件设计人员避免不了的事情。
在移动互联网时代,人人可用手机访问你的APP、网站应用,没有数据库的伸缩,不可能支持那么多的用户量的访问。还有一种场景,数据存储量极大的也考虑伸缩性,如防伪查询、地图软件等。
这里以最流行的数据库mysql为例子,讨论伸缩性。
数据库纵向扩展
在云时代以前,一般的企业部署应用都是一台机器里有应用+数据库。

这种做法在20世纪一直流行至今,很多内部应用也一直这样运行着十多年。在互联网应用中,数据量稍大的话很快达到瓶颈。
为何很快达到瓶颈?
第一,应用软件与数据库在同一台机器,应用与数据库都需要使用到机器的CPU、内存、磁盘IO、磁盘容量。它们两个无时无刻都在争抢。
第二,价钱达到瓶颈。在第一种情况下,你很容易提高系统的访问速度,提高机器(或VM)的配置。一开始提高很容易,但是提高到一个标准后机器的价格不是一般企业能承受得了。(大约在32核256GB内存)
那么在这种情况下怎么提高扩展性呢?
答案是分离应用与数据库。应用部署在一台机器,数据库部署在另外的机器。
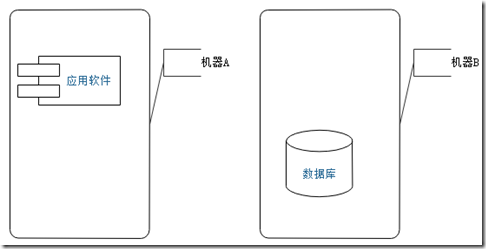
再下一步怎么扩展呢?这里不讨论应用的伸缩性。应用的伸缩性大致是部署多个实例,实例上层装个反代或负载均衡。下面着重讨论数据库的伸缩性。
Mysql数据库的伸缩性
对于伸缩性,有三种方式:数据分片、应用拆分、数据备份。Mysql也一样,首先是数据备份。
主从
数据备份这里体现的是添加主从的方式。即将数据库分成两个数据库,用于读写分离,一般主库用于写,从库用于读。
当数据进入时,会先从把数据插入主库,然后把相应的数据操作记录到日志上。从库会从主动检查主库日志,并且把新添加的数据同步到从库。流程如下图所示。
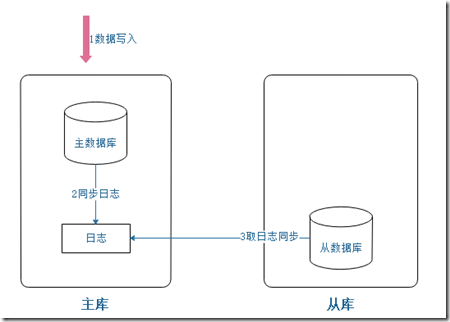
也可以在主库进行读写,从库进行读。这是主库的读操作不会太频繁,主要读压力会给予从库。 也有一种是从库主要用来备份,不做任何对外处理,即读写压力都在主库,这种只是纯备份。
上面无论是主写从读,还是主写读从读,都会给数据库减压。不知道你发现没有,主库进行写操作的时候,把数据备份到从库需要一个时间段。而如果在你写入主库时,马上有人访问从库,这个数据如果还在‘备份阶段’,那么会查找不到此数据。这个是分布式系统的一致性问题。
主从的数据库是弱一致性,也叫最终一致性。即数据最终都会保持一致,在写数据时有那么一瞬间数据会不一致。这种有上面解决办法吗?一是尽快保持主从库都在同一个局域网中,快速备份数据,尽量减少不一致。二是在程序层面,提供一个缓存层,即在主库写入数据后,再写入缓存(根据实际可以是几秒钟、几分钟)。再用户读时,先读缓存,再读数据库。
在主从上,可以一主多从,多主多从,这些都根据实际业务情况而定。值得注意的是多主的时候,数据延迟要保证带来的侵害性。
数据分区
从mysql5.1开始,支持表级别的数据分区。此数据分区无需在应用代码做任何修改,只需要在mysql中配置即可。此分区方式是物理级别的分区,它会把同一个表通过指定的算法分离存储到不同位置,最终达到提高表的量级的目的。更深一层说,一个表的数据通过物理分区分离到数个不同的物理区域,每个分区都是独立的。表分区有4种方式,与下面讨论的分表算法一致。
分库分表
再进一步,就是分库分表了。先讨论一下分库。
分库很简单,把不同的表分到不同的库,或者把相同的表不同的数据分到不同的库。
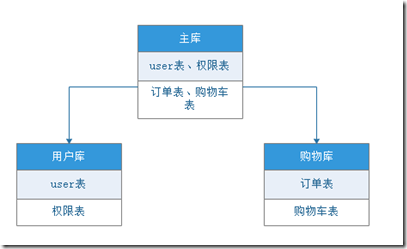
第一,不同的表分到不同的库。
把主库里的表分离出来,分到各个不同业务逻辑上的库。例如主库上分别有:user表、权限表、订单表、购物车表。把库物理分离表,分成用户库:user表、权限表。购物车库:订单表、购物车表。这种分离根据业务拆分很简便,代码修改很少,但是单个表的数据量大时会到瓶颈。如下图展示。
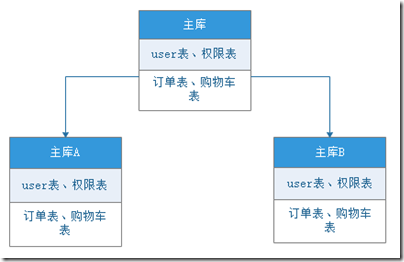
第二,相同的表不同的数据分到不同的库。
这种与分表挂钩,即把数据分离到不同的库,不同库的表都一致。例如主库上分别有:user表、权限表、订单表、购物车表。现在分两个库:库A与库B。库AB的表与主库一致,但数据分离。如库A保存北京用户的数据,库B保存广州用户的数据。如下图展示。
分表详解
上述讲述分库的两种方式时,第二种方式涉及到分表。分表的算法为:中间表、求余取模、范围方式、一致性hash。
中间表方式
首先插入数据时,在中间库中保存此条数据id与数据库的映射关系,再插入到对应的库中。如插入用户信息,数据有:用户id、用户名称。首先把数据插入到对应的数据库,如插入到主库A,数据有:用户id、用户名称。然后把数据插入到中间表中,数据有:用户id、数据库ip、数据库名称。
那么在查询时,首先根据用户id查询中间表得到数据库相关信息(数据库A),再查询相应的数据库A得到用户数据:用户名称。如下图展示。

这种方式好处在于容易分表。如果加库修改中间映射表即可。缺点在于多了一次数据库的读写操作。
求余取模方式
求余取模即根据分区键(或主键等),对分区键进行统一的求余,余数为对应的数据库。这种方式也是使用得最广的方式,因为简单,并且一般企业一开始数据库数量会定好,长时间无需添加库。
如目前有4台数据库,那么被除数时4。对分区键进行hash取整(如果s是整数则无需取hash),余数是0则在数据库A,余数是1则在数据库B,余数是2则在数据库C,余数是3则在数据库D。如下图所示。
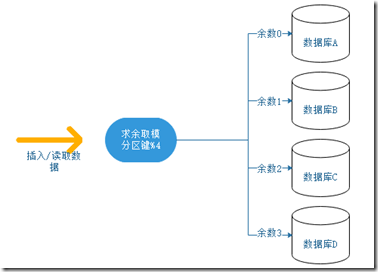
这种方式的有点在于简单,读写数据只需求余取模即可,较中间表方式性能较高。但是如果需要添加数据库的话,比较麻烦,需要迁移数据。
例如如果要添加数据库,只能是4的整数倍。现在是4,那么被除数变成8,数据库也变成8台。如下图所示。

切分后,还需要迁移数据。如
0%4=0,1%4=1,2%4=2,3%4=3,4%4=0,5%4=1,6%4=2,7%4=3。
0%8=0,1%8=1,2%8=2,3%8=3,4%8=4,5%8=5,6%8=6,7%8=7。
所以,需要把余数处以8等于4-7之间的,迁移到对应的库E-F。
范围方式
范围方式是最好理解的方式。范围方式即取得分区键,对分区键进行范围处理,如果指定到某个范围区域,则数据指向到对应得数据库。如范围1-1000W到数据库A,范围1001W-2000W到数据库B,范围2001W-3000W到数据库C。如下图所示。
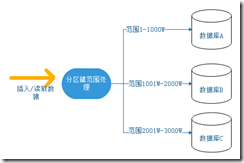
此方式好处在于简单处理,增加数据库也不需要迁移数据。缺点在于数据太过于离散,可能最终导致查询慢,即所谓的热点问题。如一用户小明1月份购买了一个商品,插入了一条订单数据在库A,在下一个月,已经到了数据库E了,下个月购买的订单数据在库E。当这两条数据有联合查询或更新时,性能较低。
一致性hash方式
在算法层面,一致性hash方式是目前最理想的方式。在hash取模时带来数据迁移问题,在范围方式带来热点数据问题,在中间表带来性能事务问题。有没有一种方式时这些方式的折中呢?一致性hash算法。
一致性hash算法是求出服务器节点的hash值,将其配置在0~232的圆。然后采用同样的方法求出存储数据的hash值,并映射到相同的圆上。顺时针到最近的服务器,那么此数据存储在这个服务器中。
例如有数据库A、B、C。数据1,2,3,4通过hash算法落在圆中。数据保存在顺时针最近的服务器。如数据1、5保存在服务器A,数据2保存在服务器B,数据3、4保存在服务器C。如下图所示。

如果加一台服务器D,则通过算法看此服务器加在圆中的那里。如果在服务器A于C之间,则保存在服务器A的数据有一部分需要迁移到服务器D。如下图所示,数据5被迁移到服务器D。

总结
综上,数据库的伸缩性首先是主从,然后是分区,最后是分库分表。其中主从是数据库软件支持的操作,应用程序修改得不多。分区是数据库表的分区,应用程序也无需改动,表通过算法分区到不同的物理分区。最后是分表分库,这2种通常是一并使用。分表分库包含了4种常见算法方式:中间表、求余取模、范围方式、一致性hash。
可以关注本人的公众号,多年经验的原创文章共享给大家。

数据库系列(五)之 mysql的伸缩性的更多相关文章
- log4net保存到数据库系列五、新增数据库字段
园子里面有很多关于log4net保存到数据库的帖子,但是要动手操作还是比较不易,从头开始学习log4net数据库日志一.WebConfig中配置log4net 一.WebConfig中配置log4ne ...
- 菜鸟学数据库(五)——MySQL必备命令
今天跟大家分享一下MySQL从连接到具体操作的一系列常用命令.可能有的人觉得现在有很多可视化的工具,没必要再学习那些具体的命令了,但是我不这么认为,不可否认那些工具的确让我们的工作更加方便快捷,但是如 ...
- mysql系列五、mysql中having的用法
HAVING 子句对 GROUP BY 子句设置条件的方式与 WHERE 和 SELECT 的交互方式类似.WHERE 搜索条件在进行分组操作之前应用:而HAVING 搜索条件在进行分组操作之后应用. ...
- shell编程系列25--shell操作数据库实战之备份MySQL数据,并通过FTP将其传输到远端主机
shell编程系列25--shell操作数据库实战之备份MySQL数据,并通过FTP将其传输到远端主机 备份mysql中的库或者表 mysqldump 常用参数详解: -u 用户名 -p 密码 -h ...
- mysql第五篇 : MySQL 之 视图、触发器、存储过程、函数、事物与数据库锁
第五篇 : MySQL 之 视图.触发器.存储过程.函数.事物与数据库锁 一.视图 视图是一个虚拟表(非真实存在的),其本质是‘根据SQL语句获取动态的数据集,并为其命名‘ ,用户使用时只需使用“名称 ...
- 五、使用druid管理数据库,mybatis连接mysql数据库
简介: 使用 mybatis 连接 mysql 数据库, 一套简单的增删改查流程, 前台用 bootstrap, bootstrap-table 框架, 最后用 druid 监控数据库连接情况 ...
- 【数据库】4.0 MySQL入门学习(四)——linux系统环境下MySQL安装
1.0 我的操作系统是CentOS Linux release 7.6.1810 (Core) 系统详细信息如下: Linux version 3.10.0-957.1.3.el7.x86_64 ( ...
- log4net保存到数据库系列四、完整代码配置log4net
园子里面有很多关于log4net保存到数据库的帖子,但是要动手操作还是比较不易,从头开始学习log4net数据库日志一.WebConfig中配置log4net 一.WebConfig中配置log4ne ...
- log4net保存到数据库系列三、代码中xml配置log4net
园子里面有很多关于log4net保存到数据库的帖子,但是要动手操作还是比较不易,从头开始学习log4net数据库日志一.WebConfig中配置log4net 一.WebConfig中配置log4ne ...
随机推荐
- Sentinel Dashboard 的 Docker 镜像使用
1.下载 docker 镜像:https://hub.docker.com/r/anjia0532/sentinel-docker 2.启动 docker 容器:docker run -p8080:8 ...
- angular 学习记录
3章3小结 路由传参的3种方式和路由快照,订阅, @相同路由的跳转(只是参数不同),并不会触发Oninit ,因为没有重新创建component @子路由 //此种情况 是当我路由地址是 ../Hom ...
- LoadRunner Controller集合点策略灰色问题 解决
1.脚本里已经添加了集合点,但是在Controller里集合点策略是灰色的无法点击 2.问题解决: 将下图的勾选项去掉即可(系统默认是勾选上的) 去掉勾选后可以选择了:
- 处理海量数据的grep、cut、awk、sed 命令
grep.cut.awk.sed 常常应用在查找日志.数据.输出结果等等,并对我们想要的数据进行提取. 通常grep,sed命令是对行进行提取,cut跟awk是对列进行提取 处理海量数据之grep命令 ...
- LG2598/BZOJ1412 「ZJOI2009」狼和羊的故事 最小割
问题描述 LG2598 BZOJ1412 题解 看到要把狼和羊两个物种分开 自然想到最小割. 发现\((x,y)\)可以向上下左右走以获得贡献,所以建边:\((x,y),(x-1,y)\),\((x, ...
- AWS云教育账号创建以及搭建数据库
注册过程繁琐,本文强调关键几点 首先拿到aws的二维码,进入之后填写相关个人信息,用学校邮箱注册,用学校邮箱注册!! 之后审核会有大约10分钟的过程,之后会收到确认邮件 点进去之后就可以设置自己的密码 ...
- 树莓派安装opencv3及其扩展库
https://www.cnblogs.com/Pyrokine/p/8921285.html 目标编译针对python的opencv以及扩展库 环境树莓派4和3B+都可以python3.7.3 py ...
- biopython处理中蜂基因组
1.安装包 pip install bcbio-gff pprint 2.显示中蜂的序列 from Bio import SeqIO genome_name = 'GCF_001442555.1_AC ...
- CSP考前复习
前言 因为loceaner太菜了,他什么东西都不会 所以他打算学一个东西就记录一下 不过因为他很菜,所以他不会写原理-- 而且,他希望在2019CSP之前不会断更 就酱紫,就是写给他自己的--因为他太 ...
- 前端Vue项目——登录页面实现
一.geetest滑动验证 geetest官方文档地址:https://docs.geetest.com/ 产品——极速验证:基于深度学习的人机识别应用.极验「行为验证」是一项可以帮助你的网站与APP ...