Quartz学习笔记:集群部署&高可用
Quartz学习笔记:集群部署&高可用
集群部署
一个Quartz集群中的每个节点是一个独立的Quartz应用,它又管理着其他的节点。这就意味着你必须对每个节点分别启动或停止。Quartz集群中,独立的Quartz节点并不与另一其的节点或是管理节点通信,而是通过同一个数据库表来感知到另一Quartz应用的。
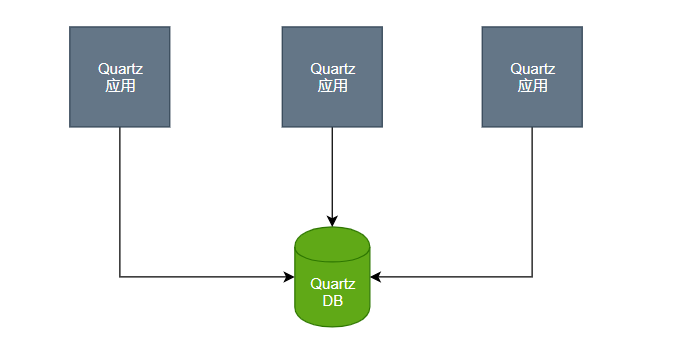
因为Quartz集群依赖于数据库,所以必须首先创建Quartz数据库表,Quartz发布包中包括了所有被支持的数据库平台的SQL脚本。这些SQL脚本存放于<quartz_home>/docs/dbTables 目录下。不同版本,表个数可能不同。

集群配置
创建完表结构之后,我们需要配置Quartz,以让其感知自己是集群的一份子。定义quartz.properties配置文件默认放在应用classpath路径下,其他路径只能自己手动加载properties。下面是集群配置参考:
#集群中应用采用相同的Scheduler实例
org.quartz.scheduler.instanceName: wenqyScheduler #集群节点的ID必须唯一,可由quartz自动生成
org.quartz.scheduler.instanceId: AUTO #通知Scheduler实例要它参与到一个集群当中
org.quartz.jobStore.isClustered: true #需持久化存储
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate #数据源
org.quartz.jobStore.dataSource=myDS #quartz表前缀
org.quartz.jobStore.tablePrefix=QRTZ_ #数据源配置
org.quartz.dataSource.myDS.driver: com.mysql.jdbc.Driver
org.quartz.dataSource.myDS.URL: jdbc:mysql://localhost:3306/ncdb
org.quartz.dataSource.myDS.user: root
org.quartz.dataSource.myDS.password: 123456
org.quartz.dataSource.myDS.maxConnections: 5
org.quartz.dataSource.myDS.validationQuery: select 0
同一集群下,instanceName必须相同,instanceId可自动生成,isClustered为true,持久化存储,指定数据库类型对应的驱动类和数据源连接。
集群高可用
数据行锁避免重复执行
Quartz究竟是如何保证集群情况下trgger处理的信息同步?
下面跟着源码一步一步分析,QuartzSchedulerThread包含有决定何时下一个Job将被触发的处理循环,主要逻辑在其run()方法中:
public void run() {
boolean lastAcquireFailed = false;
while (!halted.get()) {
......
int availThreadCount = qsRsrcs.getThreadPool().blockForAvailableThreads();
if(availThreadCount > 0) {
......
//调度器在trigger队列中寻找30秒内一定数目的trigger(需要保证集群节点的系统时间一致)
triggers = qsRsrcs.getJobStore().acquireNextTriggers(
now + idleWaitTime, Math.min(availThreadCount, qsRsrcs.getMaxBatchSize()), qsRsrcs.getBatchTimeWindow());
......
//触发trigger
List<TriggerFiredResult> res = qsRsrcs.getJobStore().triggersFired(triggers);
......
//释放trigger
for (int i = 0; i < triggers.size(); i++) {
qsRsrcs.getJobStore().releaseAcquiredTrigger(triggers.get(i));
}
}
}
由此可知,QuartzScheduler调度线程不断获取trigger,触发trigger,释放trigger。下面分析trigger的获取过程,qsRsrcs.getJobStore()返回对象是JobStore,集群环境配置如下:
<!-- JobStore 配置 -->
<prop key="org.quartz.jobStore.class">org.quartz.impl.jdbcjobstore.JobStoreTX</prop>
JobStoreTX继承自JobStoreSupport,而JobStoreSupport的acquireNextTriggers、triggersFired、releaseAcquiredTrigger方法负责具体trigger相关操作,都必须获得TRIGGER_ACCESS锁。核心逻辑在executeInNonManagedTXLock方法中:
protected <T> T executeInNonManagedTXLock(
String lockName,
TransactionCallback<T> txCallback, final TransactionValidator<T> txValidator) throws JobPersistenceException {
boolean transOwner = false;
Connection conn = null;
try {
if (lockName != null) {
if (getLockHandler().requiresConnection()) {
conn = getNonManagedTXConnection();
} //获取锁
transOwner = getLockHandler().obtainLock(conn, lockName);
} if (conn == null) {
conn = getNonManagedTXConnection();
} final T result = txCallback.execute(conn);
try {
commitConnection(conn);
} catch (JobPersistenceException e) {
rollbackConnection(conn);
if (txValidator == null || !retryExecuteInNonManagedTXLock(lockName, new TransactionCallback<Boolean>() {
@Override
public Boolean execute(Connection conn) throws JobPersistenceException {
return txValidator.validate(conn, result);
}
})) {
throw e;
}
} Long sigTime = clearAndGetSignalSchedulingChangeOnTxCompletion();
if(sigTime != null && sigTime >= 0) {
signalSchedulingChangeImmediately(sigTime);
} return result;
} catch (JobPersistenceException e) {
rollbackConnection(conn);
throw e;
} catch (RuntimeException e) {
rollbackConnection(conn);
throw new JobPersistenceException("Unexpected runtime exception: "
+ e.getMessage(), e);
} finally {
try {
releaseLock(lockName, transOwner); //释放锁
} finally {
cleanupConnection(conn);
}
}
}
一个调度器实例在执行涉及到分布式问题的数据库操作前,首先要获取QUARTZ_LOCKS表中对应的行级锁,获取锁后即可执行其他表中的数据库操作,随着操作事务的提交,行级锁被释放,供其他调度实例获取。集群中的每一个调度器实例都遵循这样一种严格的操作规程。
getLockHandler()方法返回的对象类型是Semaphore,获取锁和释放锁的具体逻辑由该对象子类StdRowLockSemaphore 维护。从中很容易看出核心的锁机制是数据库锁。
public class StdRowLockSemaphore extends DBSemaphore {
public static final String SELECT_FOR_LOCK = "SELECT * FROM {0}LOCKS WHERE SCHED_NAME = {1} AND LOCK_NAME = ? FOR UPDATE";
public static final String INSERT_LOCK = "INSERT INTO {0}LOCKS(SCHED_NAME, LOCK_NAME) VALUES ({1}, ?)";
...
}
关于更多数据库锁的资料还请查看我得另一篇文章:https://www.cnblogs.com/MrSaver/p/11917345.html
故障切换
当集群一个节点在执行一个或多个作业期间失败时发生故障切换(Fail Over)。当节点出现故障时,其他节点会检测到该状况并识别数据库中在故障节点内正在进行的作业。任何标记为恢复的作业(在JobDetail上都具有“请求恢复(requests recovery)”属性)将被剩余的节点重新执行,已达到失效任务 转移。没有标记为恢复的作业将在下一次相关的Triggers触发时简单地被释放以执行。
1、每个节点Scheduler实例由集群管理线程ClusterManager周期性(配置文件中检测周期属性clusterCheckinInterval默认值是 15000 (即15 秒))定时检测CHECKIN数据库,遍历集群各兄弟节点的实例状态,检测集群各个兄弟节点的健康情况。
2、当集群中一个节点的Scheduler实例执行CHECKIN时,它会查看是否有其他节点的Scheduler实例在到达它们所预期的时间还未CHECKIN。若检测到有节点在预期时间未CHECKIN,则认为该节点故障。判断节点是否故障与节点Scheduler实例最后CHECKIN的时间有关,而判断条件:
LAST_CHECKIN_TIME + Max(检测周期,检测节点现在距上次最后CHECKIN的时间) + 7500ms < currentTime。
3、集群管理线程检测到故障节点,就会更新触发器状态,状态更新如下:

4、集群管理线程删除故障节点的实例状态(qrtz_scheduler_state表),即重置了所有故障节点触发任务一般。原先故障任务和正常任务一样就交由调度处理线程处理了。
负载均衡
负载平衡自动发生,群集的每个节点都尽可能快地触发Jobs。当Triggers的触发时间发生时,获取它的第一个节点(通过在其上放置一个锁定)是将触发它的节点。 哪个节点运行它或多或少是随机的。
集群下任务的调度存在一定的随机性,谁先拥有触发器行锁TRIGGER_ACCESS,谁就先可能触发任务。当某一个机子的调度线程拿到该锁(别的机子只能等待)时:
1、 acquireNextTriggers获取待触发队列,查询Trigger表的判断条件:
NEXT_FIRE_TIME < now + idleWaitTime + timeWindow and TRIGGER_STATE = 'WAITING
然后更新触发器状态为ACQUIRE。
2、触发待触发队列,修改 Trigger 表中的 NEXT_FIRE_TIME 字段,也就是下次触发时间,计算下次触发时间的方法与具体的触发器实现有关,如Cron表达式触发器,计算触发时间与Cron表达式有关。触发待触发队列后及时释放触发器行锁。
3、这样,别的机子拿到该锁,也查询 Trigger 表,但是由于任务触发器的下次触发时间或者状态已经修改,所以不会被查找出来。这时拿到的任务就可能是别的触发任务。这样就实现了多个节点的应用在某一时刻对任务只进行一次调度。对于重复任务每次都不一定是相同的节点,它或多或少会随机节点运行它。
参考资料
- http://wenqy.com/2018/05/05/quartz%e7%ae%a1%e4%b8%ad%e7%aa%a5%e8%b1%b9%e4%b9%8b%e9%9b%86%e7%be%a4%e9%ab%98%e5%8f%af%e7%94%a8.html
- http://wenqy.com/2018/04/03/quartz%e7%ae%a1%e4%b8%ad%e7%aa%a5%e8%b1%b9%e4%b9%8b%e9%9b%86%e7%be%a4%e7%ae%a1%e7%90%86.html
- https://tech.meituan.com/2014/08/31/mt-crm-quartz.html
Quartz学习笔记:集群部署&高可用的更多相关文章
- kubernetes集群部署高可用Postgresql的Stolon方案
目录 前言 ....前言 本文选用Stolon的方式搭建Postgresql高可用方案,主要为Harbor提供高可用数据库,Harbor搭建可查看kubernetes搭建Harbor无坑及Harbor ...
- Dubbo入门到精通学习笔记(十五):Redis集群的安装(Redis3+CentOS)、Redis集群的高可用测试(含Jedis客户端的使用)、Redis集群的扩展测试
文章目录 Redis集群的安装(Redis3+CentOS) 参考文档 Redis 集群介绍.特性.规范等(可看提供的参考文档+视频解说) Redis 集群的安装(Redis3.0.3 + CentO ...
- 15套java架构师、集群、高可用、高可扩展、高性能、高并发、性能优化、Spring boot、Redis、ActiveMQ、Nginx、Mycat、Netty、Jvm大型分布式项目实战视频教程
* { font-family: "Microsoft YaHei" !important } h1 { color: #FF0 } 15套java架构师.集群.高可用.高可扩展. ...
- 15套java架构师、集群、高可用、高可扩 展、高性能、高并发、性能优化Redis、ActiveMQ、Nginx、Mycat、Netty、Jvm大型分布式项目实战视频教程
* { font-family: "Microsoft YaHei" !important } h1 { color: #FF0 } 15套java架构师.集群.高可用.高可扩 展 ...
- Rabbitmq安装、集群与高可用配置
历史: RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然在同步消息通讯的世界里有很多 ...
- 11.Redis 哨兵集群实现高可用
作者:中华石杉 Redis 哨兵集群实现高可用 哨兵的介绍 sentinel,中文名是哨兵.哨兵是 redis 集群机构中非常重要的一个组件,主要有以下功能: 集群监控:负责监控 redis mast ...
- K8S集群Master高可用实践
K8S集群Master高可用实践 https://blog.51cto.com/ylw6006/2164981 本文将在前文基础上介绍k8s集群的高可用实践,一般来讲,k8s集群高可用主要包含以 ...
- 浅谈web应用的负载均衡、集群、高可用(HA)解决方案(转)
1.熟悉几个组件 1.1.apache —— 它是Apache软件基金会的一个开放源代码的跨平台的网页服务器,属于老牌的web服务器了,支持基于Ip或者域名的虚拟主机,支持代理服务器,支持安 ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
随机推荐
- signed Unsigned Compare
// signUnsignCompare.cpp : Defines the entry point for the console application. // #include "st ...
- C 语言项目中.h文件和.c文件的关系
http://blog.csdn.net/xingkong_678/article/details/38639847 关于两者以前的关系,要从N年以前说起了~ long long ago,once a ...
- Spring的三大核心思想:IOC(控制反转),DI(依赖注入),AOP(面向切面编程)
Spring核心思想,IoC与DI详解(如果还不明白,放弃java吧) 1.IoC是什么? IoC(Inversion of Control)控制反转,IoC是一种新的Java编程模式,目前很多 ...
- Wooden Signs Gym - 101128E (DP)
Problem E: Wooden Signs \[ Time Limit: 1 s \quad Memory Limit: 256 MiB \] 题意 给出一个\(n\),接下来\(n+1\)个数, ...
- round.606.div2
A. Happy Birthday, Polycarp! 这个题意我确实没有看懂. 沃日,我懂了,我感觉我似乎都能切掉这题. B. Make Them Odd 这个我也能看懂.
- Python列表生成式练习
''' 如果list中既包含字符串,又包含整数,由于非字符串类型没有lower()方法,所以列表生成式会报错 使用内建的isinstance函数可以判断一个变量是不是字符串: 返回True 或 Fal ...
- 使用Map文件查找崩溃信息
简介 编写整洁的应用程序是一回事.但是当用户告诉你你的软件已经崩溃时,你知道在添加其他功能之前最好先解决这个问题.如果你够幸运的话,用户会有一个崩溃地址.这将大大有助于解决这个问题.但是你怎么能用这个 ...
- gtibase rpm包制作
gitbase 是一个很不错的代码分析工具,我们可以直接使用sql来分析团队的代码,以下是rpm 包的制作 简单说明 rpm 包的制作使用了fpm 一个简单,方便可以跨平台的软件包制作工具 gitba ...
- minikube 安装试用
目前使用k8s 要么用的物理机搭建的环境,要么就是使用docker for mac 中kubernetes 的特性,为了本地调试方便,使用下minikube minukube 包含的特性 负载均衡器 ...
- 配送城市地址联动选择JQuery
记录一次使用jq实现3层地址联动选择流程!效果如图. 需要引入 jq.js.layer.js.layui.js.layui.css (icon图标) 二.选中后页面展示效果 三.页面展示HTML &l ...