Boosting and AdaBoost
Boosting是一种从一些弱分类器中创建一个强分类器的集成技术(提升算法)。
它先由训练数据构建一个模型,然后创建第二个模型来尝试纠正第一个模型的错误。不断添加模型,直到训练集完美预测或已经添加到数量上限。
Bagging与Boosting的区别:取样方式不同。Bagging采用均匀取样,而Boosting根据错误率取样。Bagging的各个预测函数没有权重,而Boosting是由权重的,Bagging的各个预测函数可以并行生成,而Boosing的哥哥预测函数只能顺序生成。
AdaBoost算法的全称是自适应boosting(Adaptive Boosting),是一种用于二分类问题的算法,它用弱分类器的线性组合来构造强分类器。弱分类器的性能不用太好,仅比随机猜测强,依靠它们可以构造出一个非常准确的强分类器。
AdaBoost是为二分类开发的第一个真正成功的Boosting算法,同时也是理解Boosting的最佳起点。目前基于AdaBoost而构建的算法中最著名的就是随机梯度boosting。
AdaBoost常与短决策树一起使用。
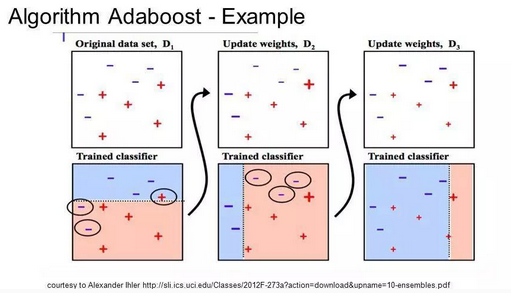
在创建第一棵树之后,每个训练实例在树上的性能都决定了下一棵树需要在这个训练实例上投入多少关注。
难以预测的训练数据会被赋予更多的权重,而易于预测的实例被赋予更少的权重。
模型按顺序依次创建,每个模型的更新都会影响序列中下一棵树的学习效果。
在建完所有树之后,算法对新数据进行预测,并且通过训练数据的准确程度来加权每棵树的性能。
因为算法极为注重错误纠正,所以一个没有异常值的整洁数据十分重要。
AdaBoost的实现是一个渐进的过程,从一个最基础的分类器开始,每次寻找一个最能解决当前错误样本的分类器。用加权取和(weighted sum)的方式把这个新分类器结合进已有的分类器中。
它的好处是自带了特征选择(feature selection),只使用在训练集中发现有效的特征(feature)。这样就降低了分类时需要计算的特征数量,也在一定程度上解决了高维数据难以理解的问题。
最经典的AdaBoost实现中,它的每一个弱分类器其实就是一个决策树。这就是之前为什么说决策树是各种算法的基石。
集成学习
AdaBoost算法是一种集成学习(ensemble learning)方法。集成学习是机器学习中的一类方法,它对多个机器学习模型进行组合形成一个精度更高的模型,参与组合的模型称为弱学习器(weak learner)。在预测时使用这些弱学习器模型联合起来进行预测;训练时需要用训练样本集依次训练出这些弱学习器。典型的集成学习算法是随机森林和boosting算法,而AdaBoost算法是boosting算法的一种实现版本。
Boosting and AdaBoost的更多相关文章
- boosting、adaboost
1.boosting Boosting方法是一种用来提高弱分类算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将他们组合成一个预测函数.他是一种框架算法,主要是通过对样本集的操作获 ...
- PRML读书会第十四章 Combining Models(committees,Boosting,AdaBoost,决策树,条件混合模型)
主讲人 网神 (新浪微博: @豆角茄子麻酱凉面) 网神(66707180) 18:57:18 大家好,今天我们讲一下第14章combining models,这一章是联合模型,通过将多个模型以某种形式 ...
- 决策树与树集成模型(bootstrap, 决策树(信息熵,信息增益, 信息增益率, 基尼系数),回归树, Bagging, 随机森林, Boosting, Adaboost, GBDT, XGboost)
1.bootstrap 在原始数据的范围内作有放回的再抽样M个, 样本容量仍为n,原始数据中每个观察单位每次被抽到的概率相等, 为1/n , 所得样本称为Bootstrap样本.于是可得到参数θ的 ...
- bagging,random forest,boosting(adaboost、GBDT),XGBoost小结
Bagging 从原始样本集中抽取训练集.每轮从原始样本集中使用Bootstraping(有放回)的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中).共进行 ...
- aggregation(2):adaptive Boosting (AdaBoost)
给你这些水果图片,告诉你哪些是苹果.那么现在,让你总结一下哪些是苹果? 1)苹果都是圆的.我们发现,有些苹果不是圆的.有些水果是圆的但不是苹果, 2)其中到这些违反"苹果都是圆的" ...
- adaboost原理与实践
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器).其算法本身是通过改变数据分布来实现的,它根据 ...
- 一个关于AdaBoost算法的简单证明
下载本文PDF格式(Academia.edu) 本文给出了机器学习中AdaBoost算法的一个简单初等证明,需要使用的数学工具为微积分-1. Adaboost is a powerful algori ...
- adaboost原理和实现
上两篇说了决策树到集成学习的大概,这节我们通过adaboost来具体了解一下集成学习的简单做法. 集成学习有bagging和boosting两种不同的思路,bagging的代表是随机森林,boosti ...
- A Gentle Introduction to the Gradient Boosting Algorithm for Machine Learning
A Gentle Introduction to the Gradient Boosting Algorithm for Machine Learning by Jason Brownlee on S ...
随机推荐
- 洛谷--P3808 【模板】AC自动机(“假的“简单版)
如果你想要做出这道题,你需要先了解两个知识点: 1.字典树的构造 2.KMP算法(也就是fail指针的构造) 对于字典树,可以看看这个大佬: https://www.cnblogs.com/TheRo ...
- 快速排序(Quick Sort)C语言
已知数组 src 如下: [5, 3, 7, 6, 4, 1, 0, 2, 9, 10, 8] 快速排序1 在数组 src[low, high] 中,取 src[low] 作为 关键字(key) . ...
- spark streaming与storm比较
- zbar android sdk源码编译
zbar,解析条码和二维码的又一利器,zbar代码是用c语言编写的,如果想在Android下使用zbar类库,就需要使用NDK将zbar编译成.so加载使用,zbar编译好的Android SDK可以 ...
- Kubernetes(K8s)基础知识(docker容器技术)
今天谈谈K8s基础知识关键词: 一个目标:容器操作:两地三中心:四层服务发现:五种Pod共享资源:六个CNI常用插件:七层负载均衡:八种隔离维度:九个网络模型原则:十类IP地址:百级产品线:千级物理机 ...
- java基本结构
前言 Java文件的运行过程: 1,javac.exe:编译器 2,java.exe:解释器 微软shell下运行实例: C:\Users\Administrator>cd D:\文档\JAVA ...
- SpringBoot + sqlserver+mybatis
一.maven引入 <dependency> <groupId>com.microsoft.sqlserver</groupId> <artifactId&g ...
- thrift简单示例 (go语言)
这个thrift的简单示例来自于官网 (http://thrift.apache.org/tutorial/go), 因为官方提供的例子简单易懂, 所以没有必要额外考虑新的例子. 关于安装的教程, 可 ...
- thrift中的概念
Thrift的网络栈 Apache Thrift的网络栈的简单表示如下: +-------------------------------------------+ | Server | | (sin ...
- 教你如何配置linux用户实现禁止ssh登陆机器但可用sftp登录!
构想和目标最近有个这样的诉求:基于对线上服务器的保密和安全,不希望开发人员直接登录线上服务器,因为登录服务器的权限太多难以管控,如直接修改代码.系统配置,并且也直接连上mysql.因此希望能限制开发人 ...