Python机器学习入门(1)之导学+无监督学习
Python Scikit-learn
*一组简单有效的工具集
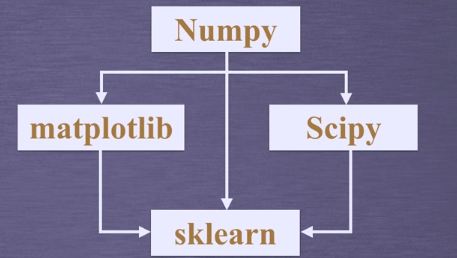
*依赖Python的NumPy,SciPy和matplotlib库
*开源 可复用
sklearn库的安装
DOS窗口中输入
pip install **
NumPy(开源科学计算库),SciPy(集成多种数学算法和函数模块)和matplotlib(提供大量绘图工具)库基础上开发的,因此需要先装这些依赖库
安装顺序
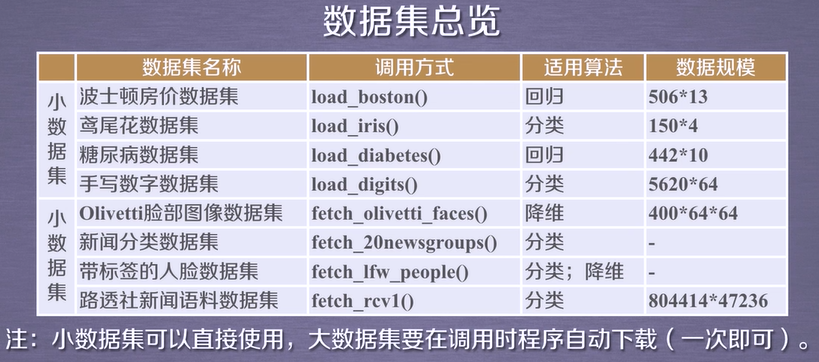
SKlearn库中的标准数据集及基本功能
波士顿房价数据集

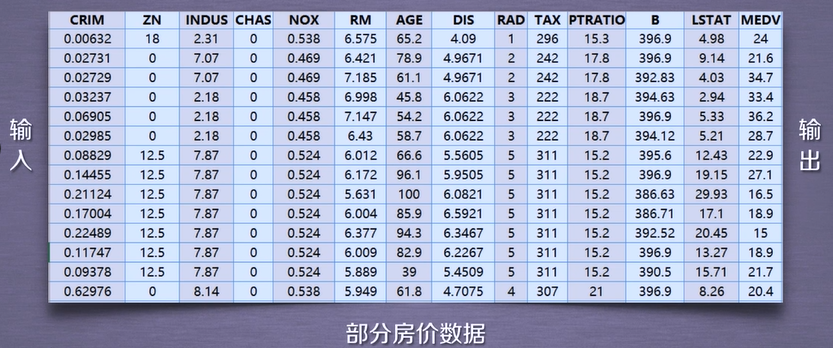
使用sklearn.datasets.load_boston即可加载相关数据集
return_X_y:表示是否返回target(即价格),默认为False,只返回data(即属性)。

鸢尾花数据集

使用sklearn.datasets.load_iris即可加载相关数据集
参数:return_X_y:若为True,则以(data,target)形式返回数据;默认为False,表示以字典形式返回数据全部信息(包括data和target)
手写数字数据集


使用sklearn.datasets.load_digits即可加载相关数据集
return_X_y:若为True,则以(data,target)的形式返回数据;默认为False,表示以字典形式返回数据全部信息包括(data和target)
n_calss:表示返回数据的类别数,如:n_class=5,则返回0到4的样本数据
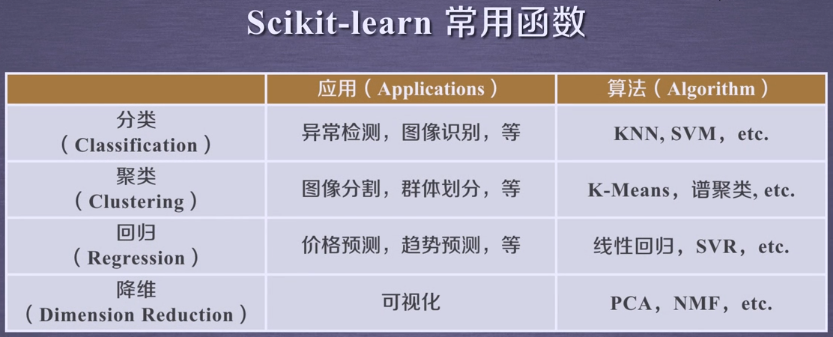
sklearn库的基本功能
sklearn库共分为六大部分,分别用于完成
分类任务

回归任务

聚类任务

降维任务

模型选择
数据预处理
无监督学习:
目标:利用无标签的数据学习数据的分布或数据与数据间的关系被称作无监督学习
*有监督学习和无监督学习的最大区别在于数据是否有标签
无监督学习最常用的场景是 聚类 和 降维
聚类:
根据数据的“相似性”将数据分为多类的过程。
评估不同样本之间的“相似性”,通常使用的方法就是计算两个样本之间的“距离”。使用不同的
方法计算样本间的距离会关系到聚类结果的好坏。
欧氏距离:
欧氏距离是最常用的一种距离度量方法,源于欧式空间中两点的距离。


曼哈顿距离:
曼哈顿距离也称作“城市街区距离”,类似于在城市之中驾车行驶,从一个十字路口到
另一个十字路口的距离。

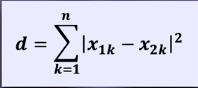
马氏距离:
马氏距离表示数据的协方差距离,是一种尺度无关的度量方式。也就是说马氏距离会
先将样本点的各个属性标准化,在计算样本间的距离。


夹角余弦:
余弦相似度用向量空间中的两个向量夹角的余弦值作为衡量两个样本差异的大小。
余弦值越接近1,说明两个向量夹角也接近0度,表明两个向量越相似。



以同样的数据集应用于不同的算法,可能会得到不同的结果,算法所耗费的时间也不尽相同,
这是由算法的特性决定的。
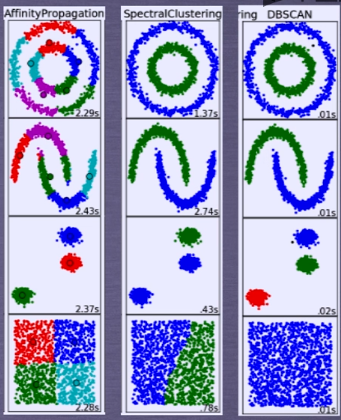
调用sklearn库的标准函数对不同数据集执行的聚类结果。
sklearn.cluster
sklearn.cluster模块提供的各聚类算法函数可以使用不同的数据形式作为输入:
>标准数据输入格式:[样本个数,特征个数]定义的矩阵形式。
>相似性矩阵输入形式:即由[样本数目]定义的矩阵形式,矩阵中每一个元素为
两个样本的相似度,如果DBSCAN,AffinityPropagation(近邻传播算法)接受
这种输入。如果以余弦相似度为例,则对角线元素全为1.矩阵中每个元素的取值
范围为[0,1]。

降维:
降维,就是在保持数据所具有的代表性特性或者分布的情况下,将高维数据转化为
低维数据的过程。
*数据可视化
*精简数据

聚类和分类都是无监督学习的典型任务,任务之间存在关联,比如某些高维数据
的分类可以通过降维处理更好的获得,学术界研究表明代表性的分类算法如k-means
与降维算法如NMF之间存在等价性。
*降维过程也可以被理解成为对数据集的组成成分进行分解(decomposition)的过程,
因此sklearn为降维模块命名为decomposition,在对降维算法调用需要使用sklearn.decomposition模块

K-means方法及应用
k-means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。
*随机选择k个点作为初始的聚类中心。
*对于剩下的点,根据其与聚类中心的距离,将其归入最近的簇。
*对每个簇,计算所有点的均值作为新的聚类中心。
重复2、3 知道聚类中心不再发生改变。


实验目的:
通过聚类,了解1999年各个省份的消费水平在国内的情况
技术路线:sklearn.cluster.Kmeans
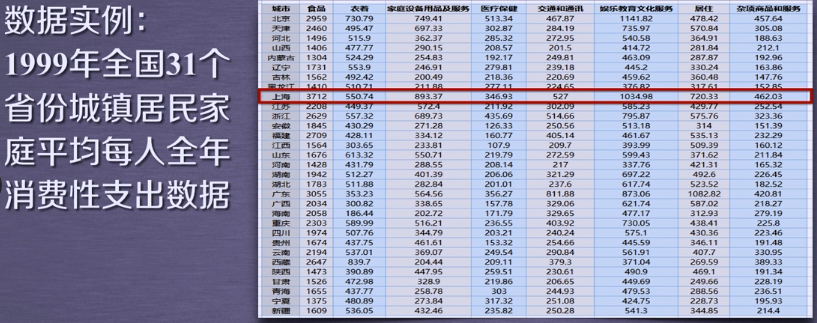
实现过程:
*使用算法:K-means聚类算法
*实现过程:
数据集文件获取:微信公众号:逍遥的豆子 回复:机器学习 即可获得博主机器学习博客所有代码及数据集
import numpy as np
from sklearn.cluster import KMeans def loadData(filePath):
fr = open(filePath,'r+') #r+:读写打开一个文本文件
lines = fr.readlines() #.read()每次读取整个文件,通常将文件内容放到一个字符串变量中
retData = []#reData存储各项消费信息 .readlines()一次读取整个文件 .readline()每次读一行
retCityName = [] #用来存储城市名称
for line in lines:
items = line.strip().split(",")
retCityName.append(items[0])
retData.append([float(items[i])for i in range(1,len(items))])
for i in range(1,len(items)):
return retData,retCityName
#加载数据,创建K-means算法实例,并进行训练,获得标签:
if __name__=='__main__':
data,cityName = loadData('city.txt') #利用loadData方法读取数据
km = KMeans(n_clusters=3) #创建实例
lable = km.fit_predict(data) #调用Kmeans()fit_predict()方法进行计算
expenses = np.sum(km.cluster_centers_,axis=1)
#print(wxpenses)
CityCluster = [[],[],[]] #将城市按label分成设定的簇
for i in range(len(cityName)): #将每个簇的城市输出
CityCluster[lable[i]].append(cityName[i]) #将每个簇的平均花费输出
for i in range(len(CityCluster)):
print("Expenses:%.2f" % expenses[i])
print(CityCluster[i])
运行效果:

调用KMeans方法所需参数:
*n_clusters: 用于指定聚类中心的个数
*init:初始聚类中心的初始化方法
*max_iter :最大迭代次数
*一般调用时只用给出n_clusters即可,init默认是K-means++,max_iter默认是300
其它参数:
*data :加载的数据
*label : 聚类后各数据所属的标签
*axis : 按行求和
*fit_predict():计算簇中心以及为簇分配序号
DBSCAN方法及应用
DBSCAN密度聚类
DBSCAN算法是一种基于密度的聚类算法:
*聚类的时候不需要预先指定簇的个数
*最终的簇的个数不定
DBSCAN算法将数据点分为三类:
*核心点:在半径Eps内含有超过MinPts数目的点
*边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内
*噪音点:既不是核心点也不是边界点的点
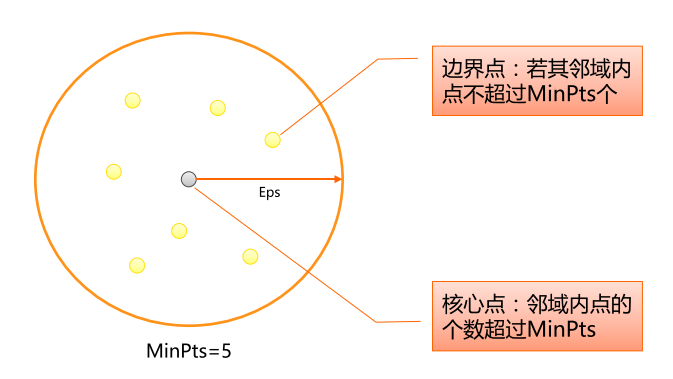
DBSCAN算法流程:
1.将所有点标记为核心点、边界点或噪声点;
2.删除噪声点;
3.为距离在Eps之内的所有核心点之间赋予一条边;
4.每组连通的核心点形成一个簇;
5.将每个边界点指派到一个与之关联的核心点的簇中(哪一个核心点的半径范围内)。
举例:有如下13个样本点,使用DBSCAN进行聚类

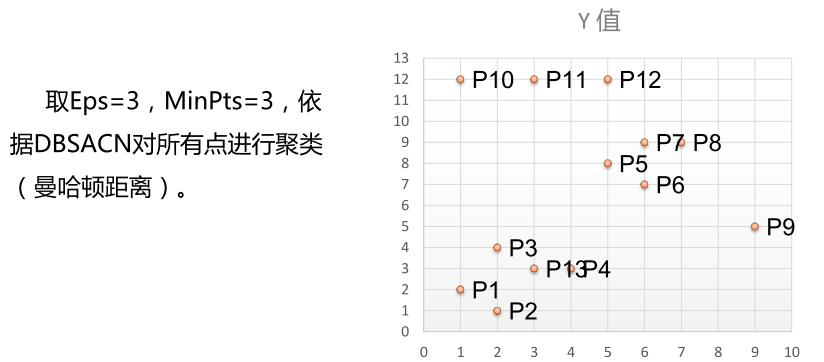
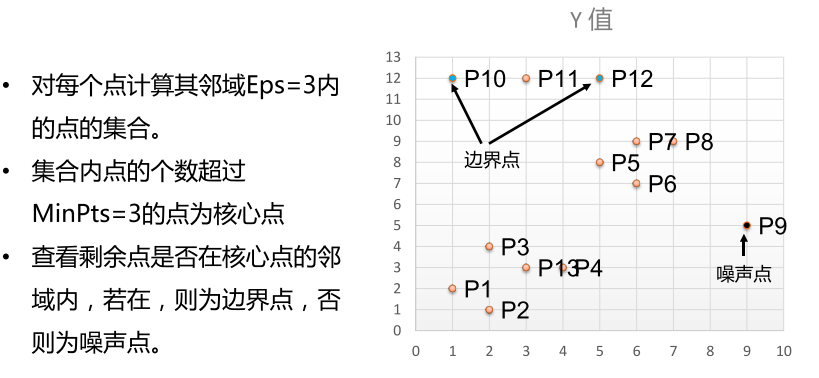

DBSCAN的应用实例
数据介绍:
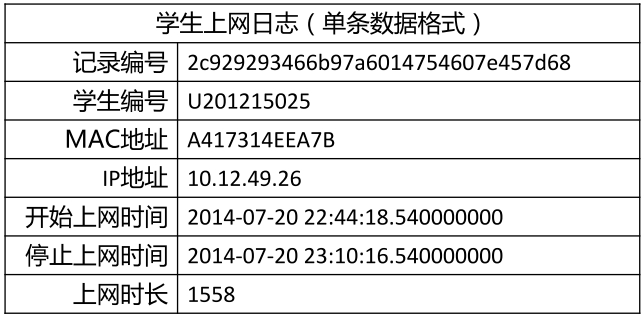
现有大学校园网的日志数据,290条大学生的校园网使用情况数据,数据包括用户ID,设备的MAC地址,
IP地址,开始上网时间,停止上网时间,上网时长,校园网套餐等。利用已有数据,分析学生上网的模式。
实验目的:通过DBSCAN聚类,分析学生上网时间和上网时长的模式。
技术路线:sklearn.cluster.DBSCAN
数据实例:
数据集文件获取:微信公众号:逍遥的豆子 回复:机器学习 即可获得博主机器学习博客所有代码及数据集
实验过程:
*使用算法:DBSCAN聚类算法
*实现过程:

具体代码:
import numpy as np
import sklearn.cluster as skc
from sklearn import metrics
import matplotlib.pyplot as pyplot
import matplotlib.pyplot as plt mac2id = dict()
onlinetimes = []
f = open('TestData.txt',encoding='UTF-8')
for line in f:
#读取每条数据中的mac地址,开始上网时间,上网时长
mac = line.split(',')[2]
onlinetime = int(line.split(',')[6])
starttime = int(line.split(',')[4].split(' ')[1].split(':')[0])
#mac2id是一个字典:key是mac地址 value是对应mac地址的上网时长以及开始上网时间
if mac not in mac2id:
mac2id[mac] = len(onlinetimes)
onlinetimes.append((starttime,onlinetime))
else:
onlinetimes[mac2id[mac]] = [(starttime,onlinetime)]
real_X = np.array(onlinetimes).reshape((-1,2)) #调用DBSCAN方法进行训练,labels为每个数据的簇标签
X = real_X[:,0:1]
db = skc.DBSCAN(eps = 0.01,min_samples = 20).fit(X)
labels = db.labels_ #打印数据被记上的标签,计算标签为-1,即噪声数据的比例
print('labels:')
print(labels)
raito = len(labels[labels[:] == -1])/len(labels)
print('Noise raito:',format(raito,'.2%')) #计算簇的个数并打印,评价聚类效果
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
print('Estimated number of clusters:%d'% n_clusters_)
print('Silhouette Coefficient:0.3f'% metrics.silhouette_score(X,labels)) #打印各簇标号以及各簇内数据
for i in range(n_clusters_):
print('Cluster',i,':')
print(list(X[labels == i].flatten()))
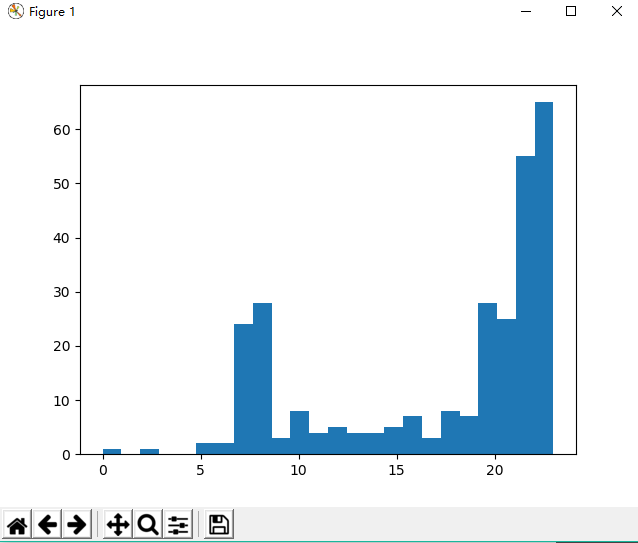
plt.hist(X,24)
plt.show()
代码运行结果:

DBSCAN主要参数:
*eps :两个样本被看作邻居节点的最大距离
*min_samples : 簇的样本数
*metric:距离的计算方式
例:sklearn.cluster.DBSCAN(eps = 0.5,min_samples = 5,metric = 'educlidean')
降维
降维之PCA:
主成分分析(PCA):
*(Principal Component Analysis)是最常用的一种降维方法,通常用于高维数据集的探索
与可视化,还可以用作数据压缩和预处理等。
*PCA可以把具有相关性的高维变量合成为线性无关的低维变量,称为主成分。主成分能够
尽可能保留原始数据的信息。
涉及到的相关术语:
方差:是各个样本和样本均值的差的平方和的均值,用来度量一组数据的分散程度。
协方差:用于度量两个变量之间的线性相关程度,若两个变量的协方差为0,则可认为
二者线性无关。

协方差矩阵:则是由变量的协方差值构成的矩阵(对称阵)
特征向量和特征值:特征向量:矩阵的特征向量是描述数据集结构的非零向量并满足如下公式
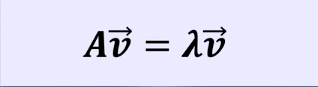
A是方阵,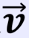 是特征向量,
是特征向量,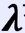 是特征值。
是特征值。
主成分分析原理:矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应的特征值大小
进行排序,最大的特征值就是第一主成分,其次是第二主成分,以此类推。
未完待续... ...
本文为博主学习笔记,转载需注明来源;
学习视频所属:中国大学MOOC 北京理工大学 嵩天 礼欣老师https://www.icourse163.org/course/BIT-1001873001
Python机器学习入门(1)之导学+无监督学习的更多相关文章
- python机器学习入门-(1)
机器学习入门项目 如果你和我一样是一个机器学习小白,这里我将会带你进行一个简单项目带你入门机器学习.开始吧! 1.项目介绍 这个项目是针对鸢尾花进行分类,数据集是含鸢尾花的三个亚属的分类信息,通过机器 ...
- Python & 机器学习入门指导
Getting started with Python & Machine Learning(阅者注:这是一篇关于机器学习的指导入门,作者大致描述了用Python来开始机器学习的优劣,以及如果 ...
- Python机器学习入门
# NumPy Python科学计算基础包 import numpy as np # 导入numpy库并起别名为npnumpy_array = np.array([[1,3,5],[2,4,6]])p ...
- 全面系统Python3入门+进阶-1-1 导学
python特点 结束
- 零起点PYTHON机器学习快速入门 PDF |网盘链接下载|
点击此处进入下载地址 提取码:2wg3 资料简介: 本书采用独创的黑箱模式,MBA案例教学机制,结合一线实战案例,介绍Sklearn人工智能模块库和常用的机器学习算法.书中配备大量图表说明,没有枯 ...
- python从入门到精通之30天快速学python视频教程
点击了解更多Python课程>>> python从入门到精通之30天快速学python视频教程 课程目录: python入门教程-1-Python编程语言历史及特性.mkv pyth ...
- [新手必备]Python 基础入门必学知识点笔记
Python 作为近几年越来越流行的语言,吸引了大量的学员开始学习,为了方便新手小白在学习过程中,更加快捷方便的查漏补缺.根据网上各种乱七八糟的资料以及实验楼的 Python 基础内容整理了一份极度适 ...
- python机器学习基本概念快速入门
//2019.08.01机器学习基础入门1-21.半监督学习的数据特征在于其数据集一部分带有一定的"标记"和或者"答案",而另一部分数据没有特定的标记,而更常见 ...
- 076 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 01 初识面向对象 01 Java面向对象导学
076 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 01 初识面向对象 01 Java面向对象导学 本文知识点:Java面向对象导学 说明:因为时间紧张,本人 ...
随机推荐
- go语言---reflect
go语言---reflect https://blog.csdn.net/cyk2396/article/details/78902953 一.reflect的使用: import ( "f ...
- 远程报错:这可能是由于credssp加密oracle修正
- hdu4292 Food 最大流模板题
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4292 题意:水和饮料,建图跑最大流模板. 我用的是学长的模板,最然我还没有仔细理解,不过这都不重要直接 ...
- bzoj 1778: [Usaco2010 Hol]Dotp 驱逐猪猡【dp+高斯消元】
算是比较经典的高斯消元应用了 设f[i]为i点答案,那么dp转移为f[u]=Σf[v]*(1-p/q)/d[v],意思是在u点爆炸可以从与u相连的v点转移过来 然后因为所有f都是未知数,高斯消元即可( ...
- P3626 [APIO2009]会议中心
传送门 好迷的思路-- 首先,如果只有第一问就是个贪心,排个序就行了 对于第二问,我们考虑这样的一种构造方式,每一次都判断加入一个区间是否会使答案变差,如果不会的话就将他加入别问我正确性我不会证 我们 ...
- Maven构建的生命周期
什么是构建生命周期 构建生命周期是一组阶段的序列(sequence of phases),每个阶段定义了目标被执行的顺序.这里的阶段是生命周期的一部分.举例说明,一个典型的 Maven 构建生命周期是 ...
- 洛谷 P1865 A % B Problem(求区间质数个数)
题目背景 题目名称是吸引你点进来的 实际上该题还是很水的 题目描述 区间质数个数 输入输出格式 输入格式: 一行两个整数 询问次数n,范围m 接下来n行,每行两个整数 l,r 表示区间 输出格式: 对 ...
- 区间DP UVA 1351 String Compression
题目传送门 /* 题意:给一个字符串,连续相同的段落可以合并,gogogo->3(go),问最小表示的长度 区间DP:dp[i][j]表示[i,j]的区间最小表示长度,那么dp[i][j] = ...
- 贪心 UVA 11729 Commando War
题目传送门 /* 贪心:按照执行时间长的优先来排序 */ #include <cstdio> #include <algorithm> #include <iostrea ...
- C# 生成 bmp 格式的图片
using System; using System.Collections.Generic; using System.Diagnostics; using System.Drawing; usin ...