hadoop的安装和配置
hadoop安装
在Apache Hadoop主页的下载页面https://hadoop.apache.org/releases.html选择版本进行下载:
下载下来的是压缩包:

将压缩包使用Xftp上传hadoop-1的/usr目录下:
执行命令:
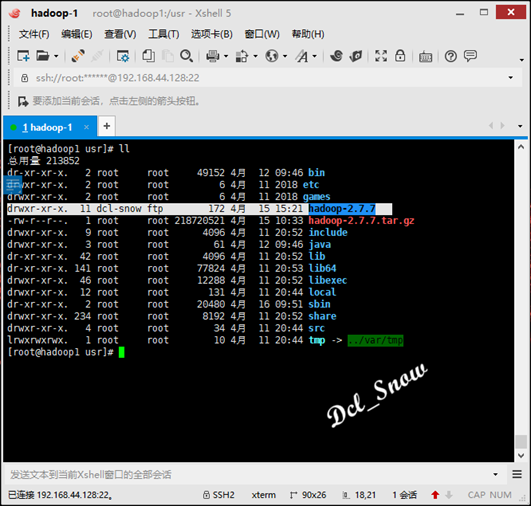
1 # tar -zxvf hadoop-2.7.7.tar.gz
解压完成后会在/usr目录下生成hadoop-2.7.7目录:
然后设置环境变量:
1 # vim /etc/profile
在profile文件末尾添加:
1 export HADOOP_HOME=/usr/hadoop-2.7.7
2 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
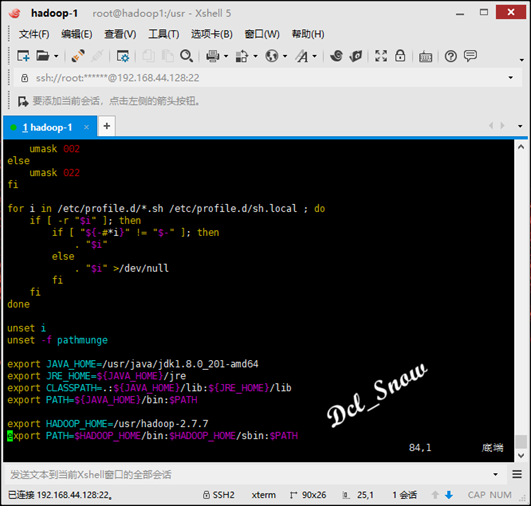
保存文件,然后执行:
1 # source /etc/profile
此时即可直接使用hadoop命令:
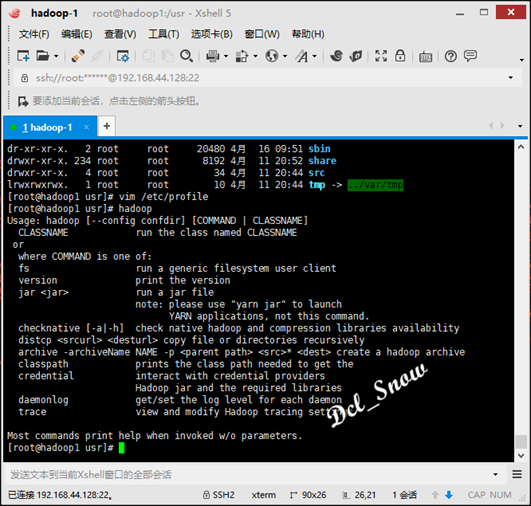
启动hadoop有三种安装模式:本地模式、伪分布式模式、分布式模式。
本地模式
本地模式只需要修改/usr/hadoop-2.7.7/etc/hadoop/hadoop-env.sh文件,设置JAVA_HOME即可。
在hadoop-1上面进行本地模式配置,在终端使用vim打开该文件:
1 # vim hadoop-2.7.7/etc/hadoop/hadoop-env.sh
找到export JAVA_HOME=${JAVA_HOME}一行,将该行注释掉,然后添加一行:
1 export JAVA_HOME=/usr/java/jdk1.8.0_201-amd64

本地模式即配置完成。
由于本地模式没有HDFS,所以只能使用本地数据测试MapReduce程序。
在/home目录下创建temp目录,在temp目录中创建一个test.txt文件:
1 # mkdir /home/temp
2 # vim /home/temp/test.txt
在test.txt文件中写入如下测试内容:
1 this is a example
2 hello world hello bob hello everyone
执行命令进入MapReduce示例程序目录:
1 # cd /usr/hadoop-2.7.7/share/hadoop/mapreduce
查看目录下的内容,执行命令:
1 # ls -l
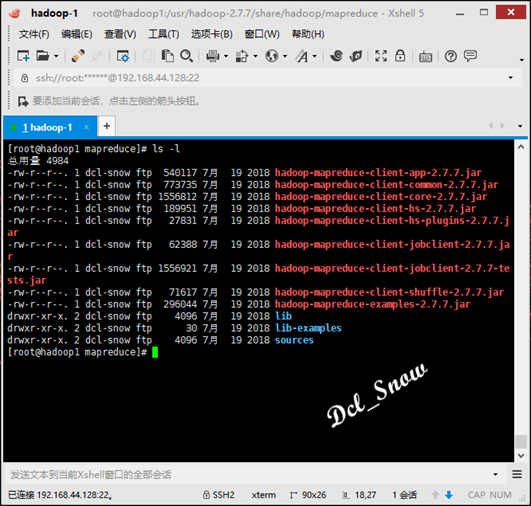
其中hadoop-mapreduce-examples-2.7.7.jar就是要来用测试的jar包,测试执行如下:
1 # hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount /home/temp/test.txt /home/temp/mcl
测试结果会生成在/home/temp/mcl目录下,执行命令查看结果:
1 # cat /home/temp/mcl/part-r-00000
可以看到每个单词的统计结果数据。
伪分布式模式
伪分布式模式是在单机上,模拟一个分布式的环境,具备Hadoop的所有功能。
配置文件路径:/usr/hadoop-2.7.7/etc/hadoop/
首先配置的文件是hadoop-env.sh,与本地模式一样,配置好JAVA_HOME参数即可。
然后配置的两个文件是hdfs-site.xml和core-site.xml,这两个文件作用是配置HDFS的一些属性。
在hdfs-site.xml文件中配置(数据冗余级别设置为1):
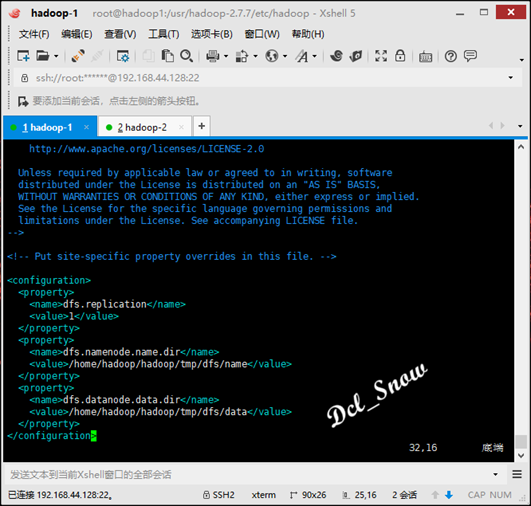
在core-site.xml文件中配置(namenode的地址和HDFS数据保存的目录,默认是Linux的tmp目录):
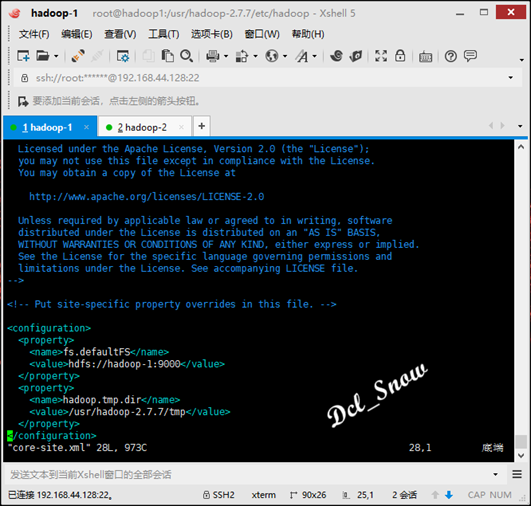
其中tmp目录要手动创建:
1 # mkdir /usr/hadoop-2.7.7/tmp
接下来配置的两个文件是mapred-site.xml和yarn-site.xml,这两个文件的作用是配置mapreduce使用yarn容器和yarn的一些属性。
现在目录中没有mapred-site.xml文件,但是有一个mapred-site.xml.template文件,所以在/usr/hadoop-2.7.7/etc/hadoop路径下执行命令:
1 # cp mapred-site.xml.template mapred-site.xml
然后在拷贝的mapred-site.xml文件中添加配置(ResourceManager的地址):
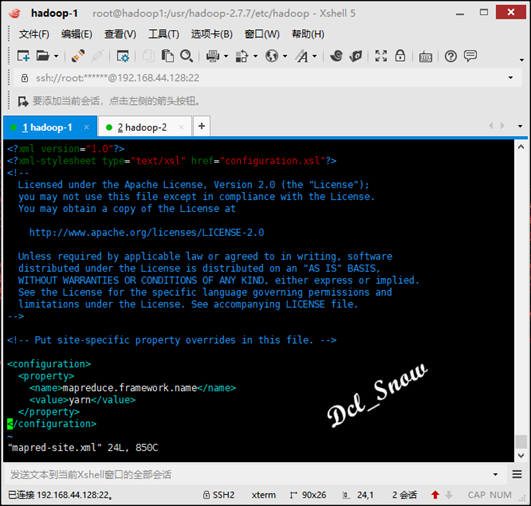
在yarn-site.xml文件中配置(NodeManager运行MR任务的方式):
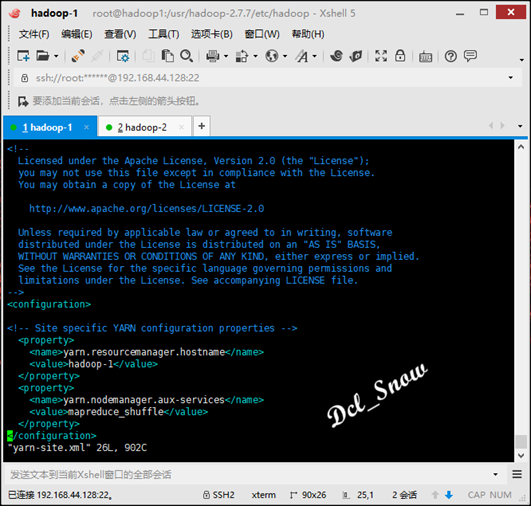
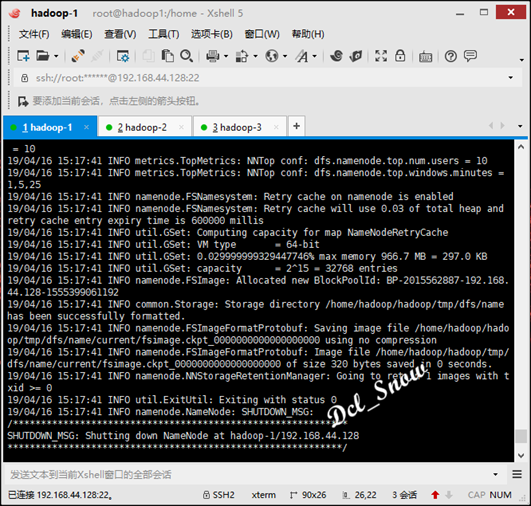
最后对namenode进行格式化,执行命令:
1 # hdfs namenode -format
只要看到信息中有一句关键:
common.Storage: Storage directory /usr/hadoop-2.7.7/tmp/dfs/name has been successfully formatted.
则格式化成功:
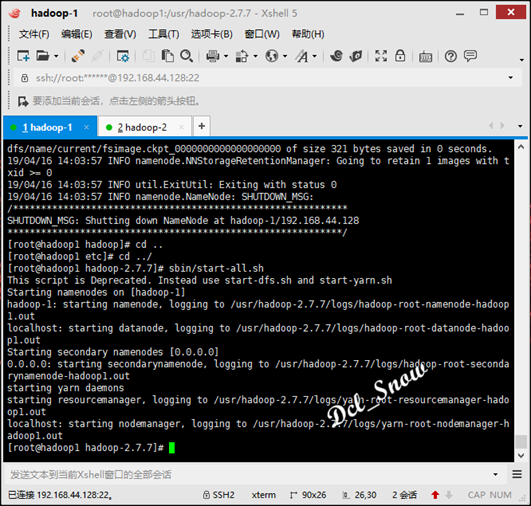
启动hadoop,执行/usr/hadoop-2.7.7/sbin目录下的启动脚本:
1 # start-all.sh
完成后信息无报错:
执行jps命令查看进程如下:
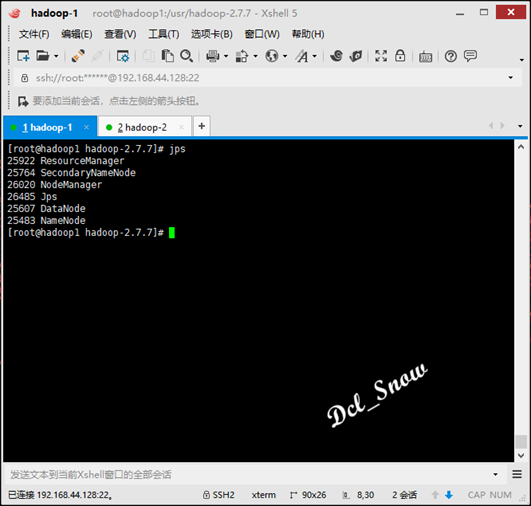
则启动完成。
打开浏览器,输入http://192.168.44.128:50070,即可打开hdfs的web页面:
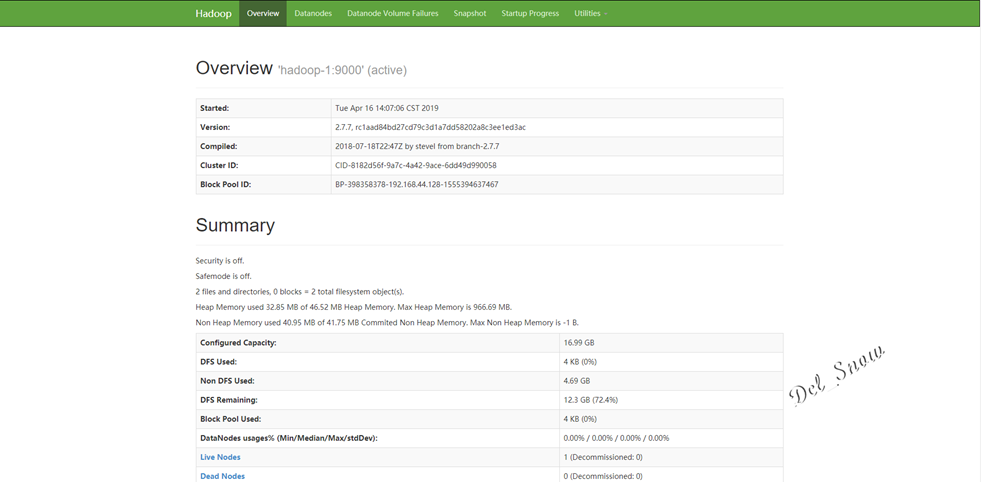
点击Datanodes可以看到数据节点为hadoop-1:
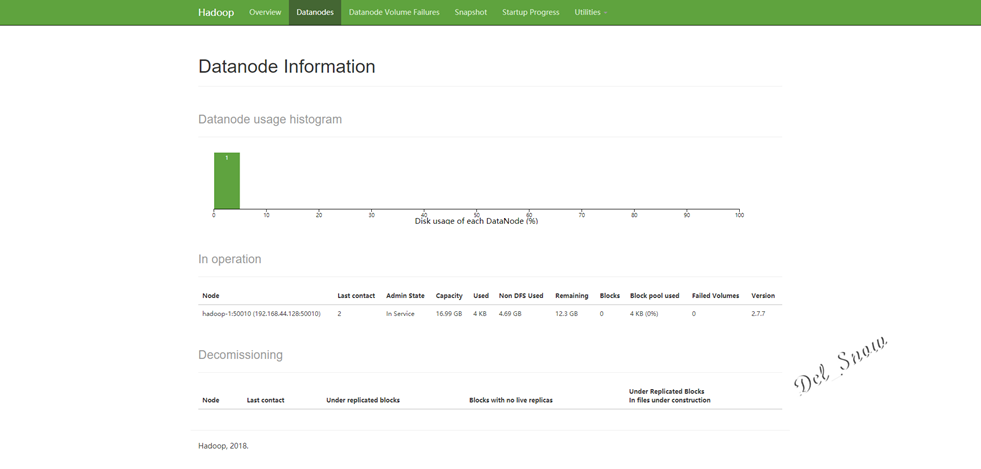
测试wordcount验证是否成功:
创建hadoop的wordCountInput用来上传test.txt文件,执行命令:
1 # hadoop fs -mkdir /wordCountInput
目录创建完成后,将/home/temp/test.txt文件上传该目录,执行命令:
1 # hadoop fs -put /home/temp/test.txt /wordCountInput
查看文件是否上传,执行命令:
1 # hadoop fs -ls /wordCountInput
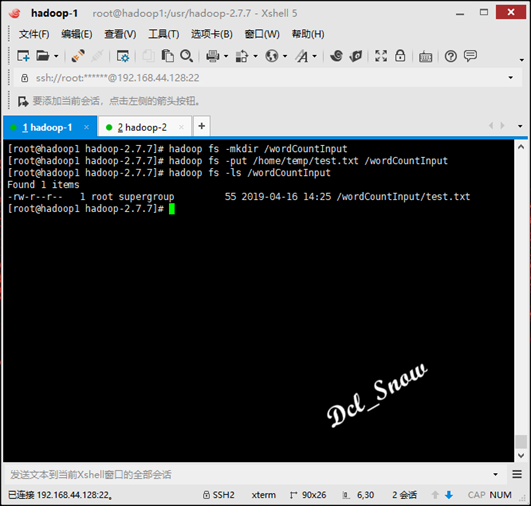
然后使用hadoop-mapreduce-examples-2.7.7.jar测试执行如下:
1 # hadoop jar /usr/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /wordCountInput/test.txt /wordCountOutput
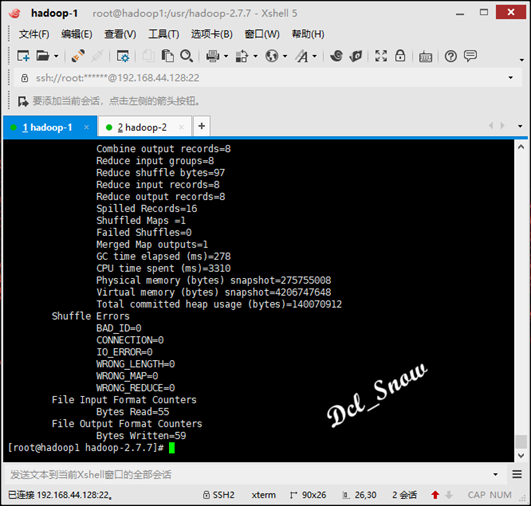
等待计算完成,查看wordCountOutput目录下的文件,执行命令:
1 # hadoop fs -ls /wordCountOutput
可以看到计算结果文件已经生成:
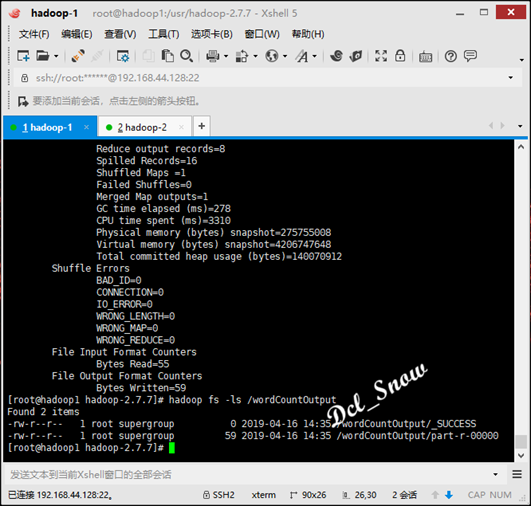
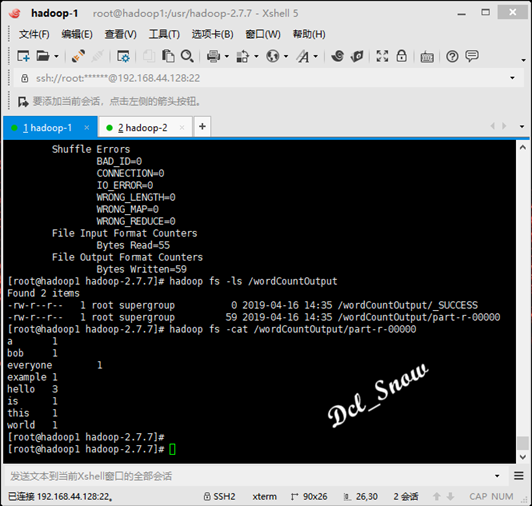
查看结果数据,执行命令:
1 # hadoop fs -cat /wordCountOutput/part-r-00000
test.txt文件中各个单词的统计数据如下:
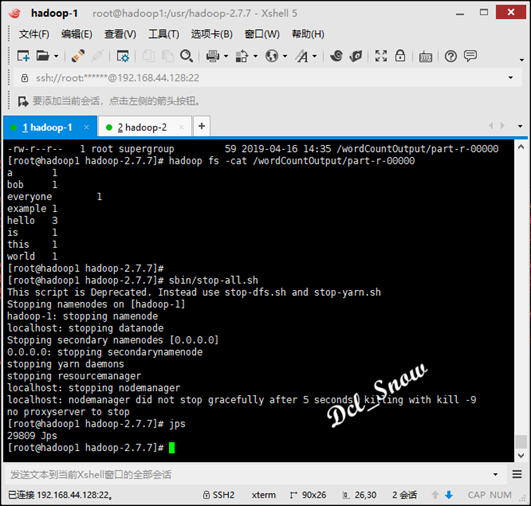
停止进程执行命令:
1 # stop-all.sh
等下stop完成,执行jps命令可以看到进程已经全部关闭:
完全分布式模式
是真正的分布式环境,具备生产条件。
完全分布式模式与伪分布式模式的区别就在于配置文件配置内容不同,namenode与datanode分别部署在不同的服务器上。
以下使用hadoop-1、hadoop-2和hadoop-3三台服务器搭建一个完全分布式集群,其中hadoop-1为namenode节点,其余两台为datanode节点。
在hadoop-1服务器上:
首先配置hadoop-env.sh文件,配置好JAVA_HOME参数。
然后配置hdfs-site.xml文件,将冗余级别改为3:
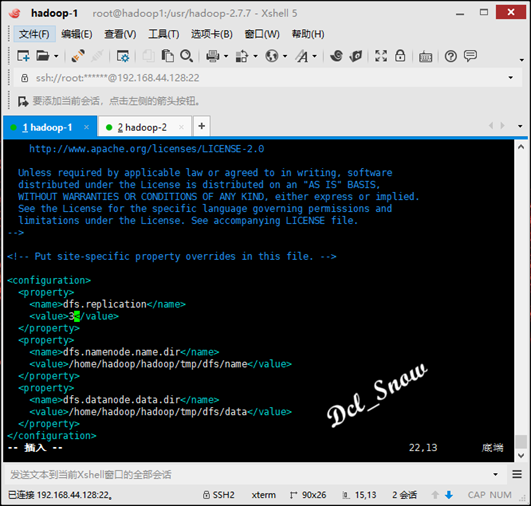
接下来core-site.xml文件,内容不需要修改:
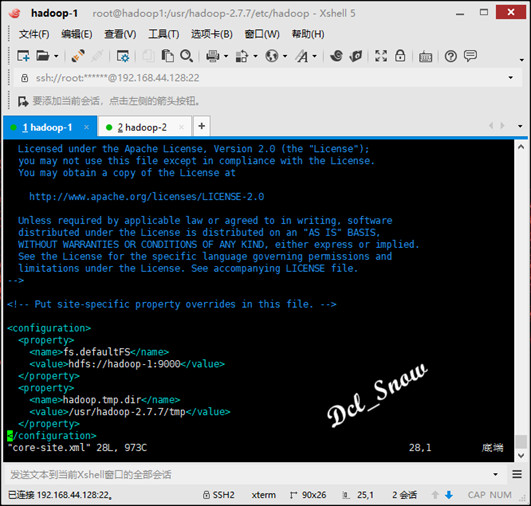
接下来mapred-site.xml文件,内容不需要修改:
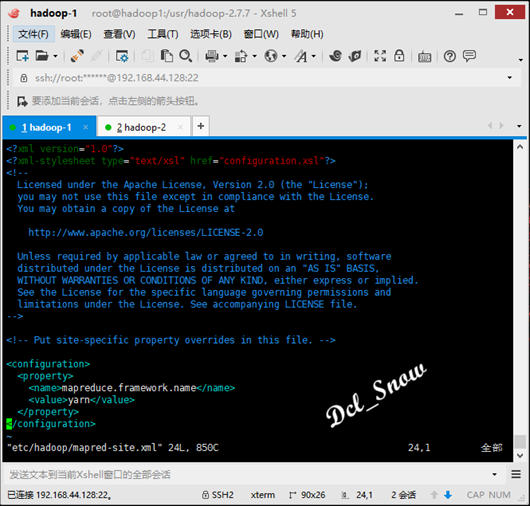
接下来yarn-site.xml 文件,内容不需要修改:
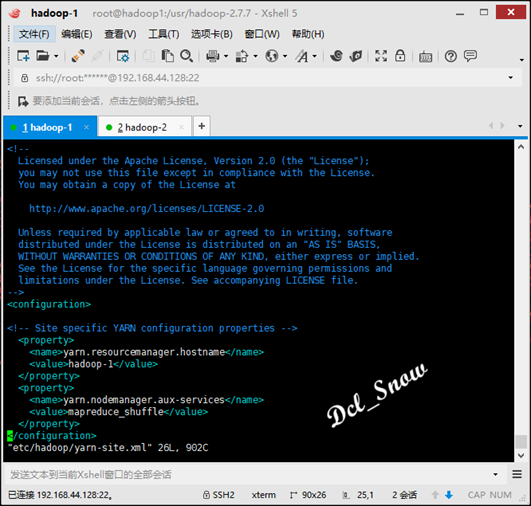
最后slaves文件中的localhost,改成hadoop-2和hadoop-3:

修改完成之后,将以上文件全部拷贝到hadoop-2和hadoop-3的相应目录下无需做其他修改。
hadoop重置
因为之前搭建伪分布式模式时,格式化过hadoop-1的namenode,所以此处需要进行重置。
首先要删除/usr/hadoop-2.7.7/logs目录中的所有文件
1 # rm -r *
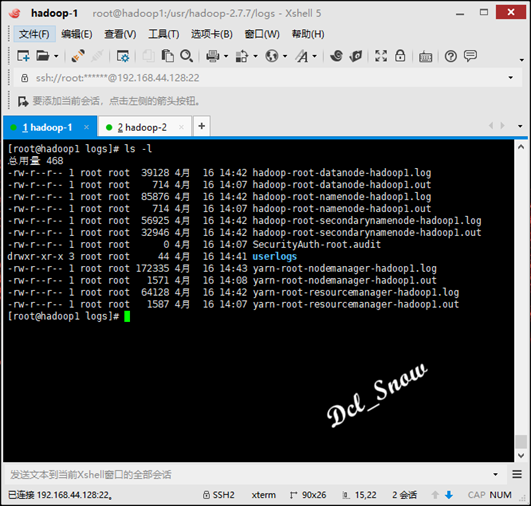
然后重新格式化namenode:
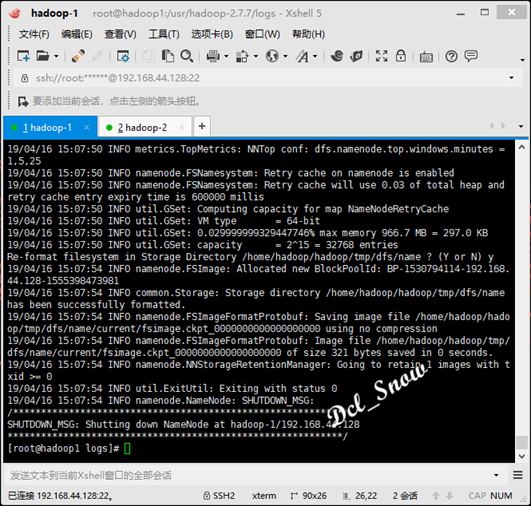
然后执行启动:
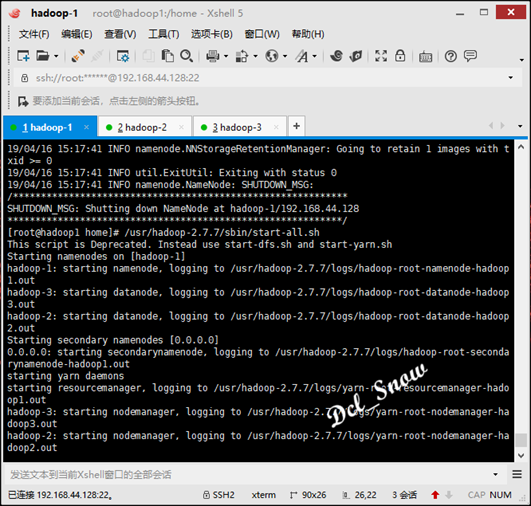
然后使用命令jps,查看三台服务器的进程如下:
hadoop-1:
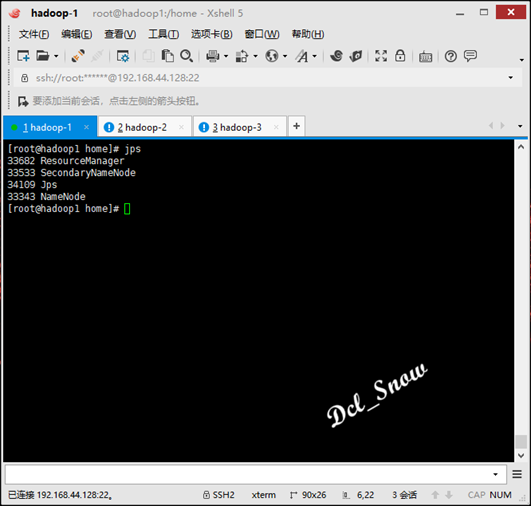
hadoop-2:
hadoop-3:
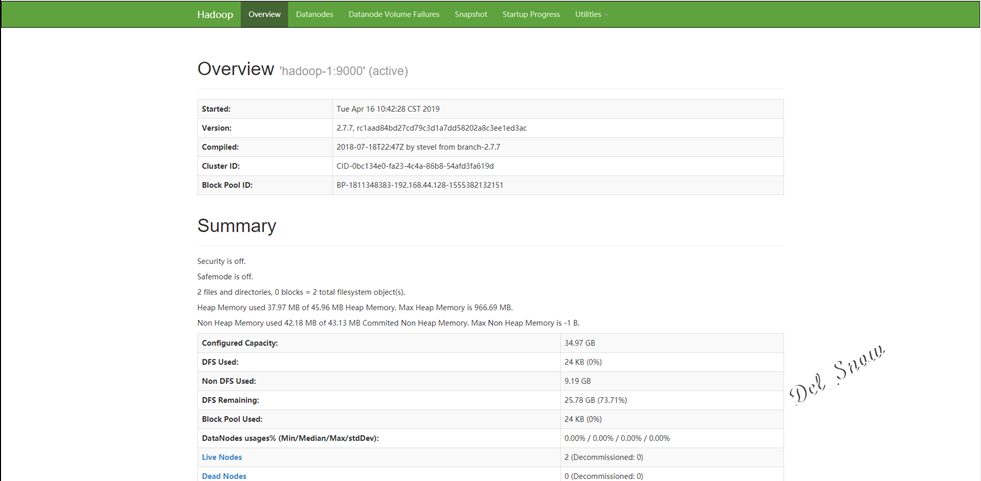
打开浏览器,输入http://192.168.44.128:50070,即可打开hdfs的web页面:
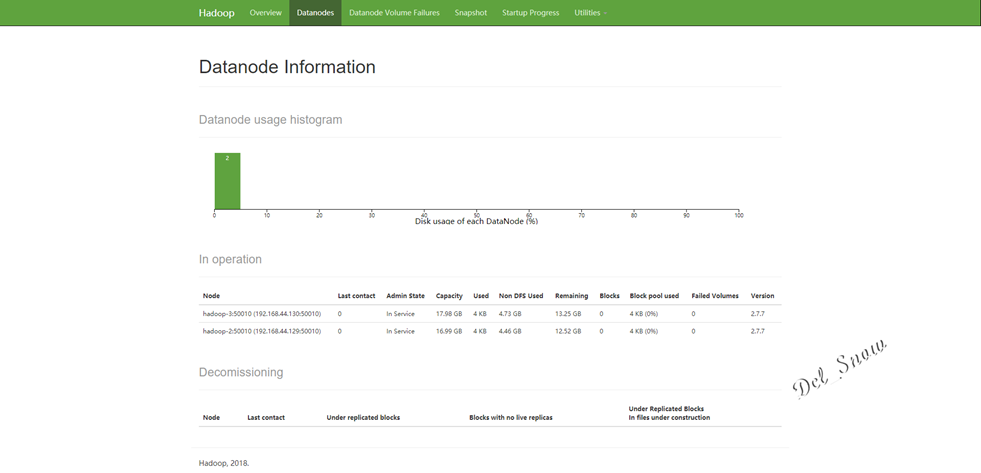
点击Datanodes可以看到数据节点为hadoop-2和hadoop-3:
本地模式一般情况下不用,开发可以使用伪分布式模式或者资源充足情况下使用完全分布式模式。
文中的配置文件参数都是最简化的配置,实际情况应该按照需求进行配置。
hadoop的安装和配置的更多相关文章
- hadoop的安装和配置(三)完全分布式模式
博主会用三篇文章为大家详细说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 完全分布式模式: 前面已经说了本地模式和伪分布模式,这两种在hadoop的应用中并不用于实际,因为几乎没人会 ...
- hadoop的安装和配置(二)伪分布模式
博主会用三篇文章为大家详细的说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 伪分布式模式: 这篇为大家带来hadoop的伪分布模式: 从最简单的方面来说,伪分布模式就是在本地模式上修 ...
- Ubuntu下伪分布式模式Hadoop的安装及配置
1.Hadoop运行模式Hadoop有三种运行模式,分别如下:单机(非分布式)模式伪分布式(用不同进程模仿分布式运行中的各类节点)模式完全分布式模式注:前两种可以在单机运行,最后一种用于真实的集群环境 ...
- Hadoop(2)-CentOS下的jdk和hadoop的安装与配置
准备工作 下载jdk8和hadoop2.7.2 使用sftp的方式传到hadoop100上的/opt/software目录中 配置环境 如果安装虚拟机时选择了open java,请先卸载 rpm -q ...
- Linux中Hadoop的安装与配置
一.准备 1,配通网络 ping www.baidu.com 之前安装虚拟机时配过 2,关闭防火墙 systemctl stop firewalld systemctl disable firewal ...
- ubuntu在虚拟机下的安装 ~~~ Hadoop的安装及配置 ~~~ Hdfs中eclipse的安装
前言 Hadoop是基于Java语言开发的,具有很好跨平台的特性.Hadoop的所要求系统环境适用于Windows,Linux,Mac系统,我们推荐选择使用Linux或Mac系统.而Linux系统则 ...
- Hadoop单机版安装,配置,运行
Hadoop是最近非常流行的东东啦,但是乍一看都觉得是集群的东东,其实在单机版上安装Hadoop也是可以的,并且安装好以后可以很方便的进行程序的调试,调试好程序以后再丢到集群中,放心的算吧,呵呵.. ...
- hadoop的安装和配置(一)本地模式
博主会用三篇文章来为大家详细的说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 本地模式: 思路走向 |--------------------| | ①:配置Java环境 | | ...
- Ubuntu16.04 下 hadoop的安装与配置(伪分布式环境)
一.准备 1.1创建hadoop用户 $ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell $ sudo pass ...
- Mac Hadoop的安装与配置
这里介绍Hadoop在mac下的安装与配置. 安装及配置Hadoop 首先安装Hadoop $ brew install Hadoop 配置ssh免密码登录 用dsa密钥认证来生成一对公钥和私钥: $ ...
随机推荐
- Vijos P1389婚礼上的小杉
背景 小杉的幻想来到了经典日剧<求婚大作战>的场景里……他正在婚礼上看幻灯片,一边看着可爱的新娘长泽雅美,一边想,如果能再来一次就好了(-.-干嘛幻想这么郁闷的场景……). 小杉身为新一代 ...
- ReactNative Android 研究
先从ReactRootView入手吧,它是一个FrameLayout mReactRootView.startReactApplication 这的start其实是会等到inital onMeasur ...
- magento导入数据的方法
导入演示数据 分两种情况处理. 如果你是用composer方式安装的 非常简单,二行命令搞定:在项目根目录下执行.我们的是在/var/www/magento2/下面. 安装演示数据 php bin/m ...
- EOJ Monthly 2018.4 (E.小迷妹在哪儿(贪心&排序&背包)
ultmaster 男神和小迷妹们玩起了捉迷藏的游戏. 小迷妹们都希望自己被 ultmaster 男神发现,因此她们都把自己位置告诉了 ultmaster 男神,因此 ultmaster 男神知道了自 ...
- Watir: 如何处理简单的网页弹出警告框?
以下是一个很经典的把Watir与AutoIt连接在一起的实例.如果我们对AutoIT了解的更多,处理类似的问题会更加简单.以下实例会判断页面上是否有某“删除”链接,一旦有该链接,就点击,然后点击弹出的 ...
- C++对象的复制——具有指针成员的类的对象的复制
//smartvessel@gmail.com class Table{ Name * p; size_t sz; publish: Table(size_t s = 15){p = new Name ...
- 877C
构造 想了好长时间... 答案是n+n/2 我们这么想,先把偶数位置炸一遍,所有坦克都在奇数位置,然后再把奇数炸一遍,坦克都到偶数去了,然后再炸一次偶数就都炸掉了... 好巧妙啊 奇偶讨论很重要 #i ...
- C++实现O(1)时间内删除链表结点
/* * 删除链表节点.cpp * * Created on: 2018年4月13日 * Author: soyo */ #include<iostream> using namespac ...
- 安装并配置JAVA环境
详见百度经验 http://jingyan.baidu.com/article/0202781175839b1bcc9ce529.html
- Java泛型简明教程
泛型是Java SE 5.0中引入的一项特征,自从这项语言特征出现多年来,我相信,几乎所有的Java程序员不仅听说过,而且使用过它.关于Java泛型的教程,免费的,不免费的,有很多.我遇到的最好的教材 ...