(转)全文检索技术学习(三)——Lucene支持中文分词
http://blog.csdn.net/yerenyuan_pku/article/details/72591778
分析器(Analyzer)的执行过程
如下图是语汇单元的生成过程: 
从一个Reader字符流开始,创建一个基于Reader的Tokenizer分词器,经过三个TokenFilter生成语汇单元Token。
要看分析器的分析效果,只需要看TokenStream中的内容就可以了。每个分析器都有一个方法tokenStream,返回的是一个TokenStream对象。
标准分析器的分词效果
之前我们创建索引库的时候,就用到了官方推荐的标准分析器——org.apache.lucene.analysis.standard.StandardAnalyzer。现在我们就来看看其分词效果,可在LuenceFirst单元测试类中编写如下方法:
public class LuenceFirst {
// 查看分析器的分词效果
@Test
public void testAnanlyzer() throws IOException {
// 1、创建一个分析器对象
Analyzer analyzer = new StandardAnalyzer(); // 官方推荐的标准分析器
// 2、从分析器对象中获得tokenStream对象
// 参数1:域的名称,可以为null,或者是""
// 参数2:要分析的文本
TokenStream tokenStream = analyzer.tokenStream("", "The Spring Framework provides a comprehensive programming and configuration model.");
// 3、设置一个引用(相当于指针),这个引用可以是多种类型,可以是关键词的引用,偏移量的引用等等
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); // charTermAttribute对象代表当前的关键词
// 偏移量(其实就是关键词在文档中出现的位置,拿到这个位置有什么用呢?因为我们将来可能要对该关键词进行高亮显示,进行高亮显示要知道这个关键词在哪?)
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
// 4、调用tokenStream的reset方法,不调用该方法,会抛出一个异常
tokenStream.reset();
// 5、使用while循环来遍历单词列表
while (tokenStream.incrementToken()) {
System.out.println("start→" + offsetAttribute.startOffset()); // 关键词起始位置
// 6、打印单词
System.out.println(charTermAttribute);
System.out.println("end→" + offsetAttribute.endOffset()); // 关键词结束位置
}
// 7、关闭tokenStream对象
tokenStream.close();
}
}- 运行以上方法,Eclipse控制台打印:

从上图中我们可以清楚地看到当前的关键词,以及该关键词的起始位置和结束位置。
中文分析器分析
Lucene自带中文分词器
Lucene自带的中文分词器有:
- StandardAnalyzer
单字分词,就是按照中文一个字一个字地进行分词。如:“我爱中国”,效果:“我”、“爱”、“中”、“国”。 - CJKAnalyzer
二分法分词,按两个字进行切分。如:“我是中国人”,效果:“我是”、“是中”、“中国”、“国人”。
上边这两个分词器一看就无法满足需求。 - SmartChineseAnalyzer
对中文支持较好,但扩展性差,扩展词库,禁用词库和同义词库等不好处理。
现在我们来看看第三个中文分析器的分析效果,相比前两个中文分析器,SmartChineseAnalyzer绝对要胜出一筹。为了观看其分析效果,我们可将LuenceFirst单元测试类中的testAnanlyzer方法改造为:
public class LuenceFirst {
// 查看分析器的分词效果
@Test
public void testAnanlyzer() throws IOException {
// 1、创建一个分析器对象
Analyzer analyzer = new SmartChineseAnalyzer(); // 智能中文分析器
// 2、从分析器对象中获得tokenStream对象
// 参数1:域的名称,可以为null,或者是""
// 参数2:要分析的文本
TokenStream tokenStream = analyzer.tokenStream("", "数据库中存储的数据是结构化数据,即行数据java,可以用二维表结构来逻辑表达实现的数据。");
// 3、设置一个引用(相当于指针),这个引用可以是多种类型,可以是关键词的引用,偏移量的引用等等
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); // charTermAttribute对象代表当前的关键词
// 偏移量(其实就是关键词在文档中出现的位置,拿到这个位置有什么用呢?因为我们将来可能要对该关键词进行高亮显示,进行高亮显示要知道这个关键词在哪?)
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
// 4、调用tokenStream的reset方法,不调用该方法,会抛出一个异常
tokenStream.reset();
// 5、使用while循环来遍历单词列表
while (tokenStream.incrementToken()) {
System.out.println("start→" + offsetAttribute.startOffset()); // 关键词起始位置
// 6、打印单词
System.out.println(charTermAttribute);
System.out.println("end→" + offsetAttribute.endOffset()); // 关键词结束位置
}
// 7、关闭tokenStream对象
tokenStream.close();
}
}- 1
- 2
运行以上方法,Eclipse控制台打印: 
虽然SmartChineseAnalyzer分析器对中文支持较好,但扩展性差,扩展词库,禁用词库和同义词库等不好处理。故实际开发中我们也是弃用的,取而代之的是第三方中文分析器。
第三方中文分析器
第三方中文分析器有:
- paoding:庖丁解牛最新版在https://code.google.com/p/paoding/ ,其最多只支持Lucene3.0,且最新提交的代码在2008-06-03,在svn中最新也是2010年提交,已经过时,不予考虑。
- mmseg4j:最新版已从https://code.google.com/p/mmseg4j/移至https://github.com/chenlb/mmseg4j-solr,支持Lucene4.10,且在github中最新提交代码是2014年6月,从09年~14年一共有18个版本,也就是一年几乎有3个大小版本,有较大的活跃度,用了mmseg算法。
- IK-analyzer:最新版在https://code.google.com/p/ik-analyzer/上,支持Lucene4.10,从2006年12月推出1.0版开始,IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开始,IK发展为面向Java的公用分词组件,独立于Lucene项,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。但是也就在2012年12月后没有再更新了。
- ansj_seg:最新版本在[https://github.com/NLPchina/ansj_seg tags](https://github.com/NLPchina/ansj_seg tags),仅有1.1版本,从2012年到2014年更新了大小6次,但是作者本人在2014年10月10日说明:“可能我以后没有精力来维护ansj_seg了”,现在由”nlp_china”管理。2014年11月有更新。并未说明是否支持Lucene,是一个由CRF(条件随机场)算法所做的分词算法。
- imdict-chinese-analyzer:最新版在https://code.google.com/p/imdict-chinese-analyzer/,最新更新也在2009年5月,可下载源码,不支持Lucene4.10。它是利用HMM(隐马尔科夫链)算法。
- Jcseg:最新版本在git.oschina.net/lionsoul/jcseg,支持Lucene 4.10,作者有较高的活跃度。其利用的是mmseg算法。
但在这里,我使用的是IK-analyzer,所以下面的讲解也是围绕着该中文分析器来进行的。下面是我下载的IK-analyzer: 
解压缩之后,其目录结构是: 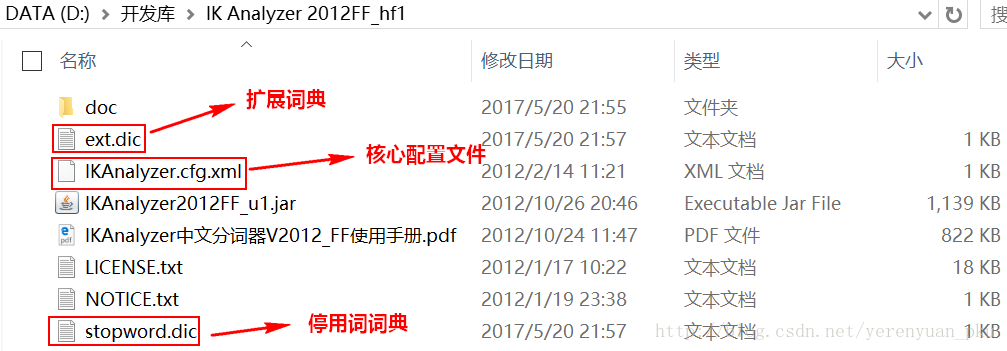
IK-analyzer中文分析器的使用
IK-analyzer中文分析器的使用步骤:
- 把IKAnalyzer2012FF_u1.jar包添加到工程中。
- 把配置文件和扩展词典和停用词词典添加到classpath下。
注意:扩展词典和停用词词典这两个文件的字符集一定要保证是UTF-8字符集,注意是无BOM的UTF-8编码,严禁使用Windows的记事本编辑。
下面我们来看看IK-analyzer这个第三方中文分析器的分析效果。现在随着互联网的日趋发展,网络用语层出不穷,例如“高富帅”,“白富美”等等,像这样的网络用语是不需要进行分词的,而是当作一个整体的关键词, 这样像这种不用分词的网络用语就应该存储在扩展词典中。为了清楚地观看IK-analyzer这个第三方中文分析器的分析效果,在扩展词典添加“高富帅”。如下: 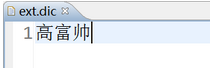
接着将LuenceFirst单元测试类中的testAnanlyzer方法改造为:
public class LuenceFirst {
// 查看分析器的分词效果
@Test
public void testAnanlyzer() throws IOException {
// 1、创建一个分析器对象
Analyzer analyzer = new IKAnalyzer(); // 智能中文分析器
// 2、从分析器对象中获得tokenStream对象
// 参数1:域的名称,可以为null,或者是""
// 参数2:要分析的文本
TokenStream tokenStream = analyzer.tokenStream("", "数据库中存储的数据是结构化数据高富帅,即行数据java,可以用二维表结构来逻辑表达实现的数据。");
// 3、设置一个引用(相当于指针),这个引用可以是多种类型,可以是关键词的引用,偏移量的引用等等
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); // charTermAttribute对象代表当前的关键词
// 偏移量(其实就是关键词在文档中出现的位置,拿到这个位置有什么用呢?因为我们将来可能要对该关键词进行高亮显示,进行高亮显示要知道这个关键词在哪?)
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
// 4、调用tokenStream的reset方法,不调用该方法,会抛出一个异常
tokenStream.reset();
// 5、使用while循环来遍历单词列表
while (tokenStream.incrementToken()) {
System.out.println("start→" + offsetAttribute.startOffset()); // 关键词起始位置
// 6、打印单词
System.out.println(charTermAttribute);
System.out.println("end→" + offsetAttribute.endOffset()); // 关键词结束位置
}
// 7、关闭tokenStream对象
tokenStream.close();
}
}- 1
运行以上方法,Eclipse控制台打印: 
从上图可清楚地看出“高富帅”并没有分词,这正是我们所期望的结果。
除此之外,对于一些敏感的词,如“习”,像这样的敏感词汇就不应该出现在单词列表中,所以可将这种敏感词汇存储在停用词词典中,如下: 
接着将LuenceFirst单元测试类中的testAnanlyzer方法改造为:
public class LuenceFirst {
// 查看分析器的分词效果
@Test
public void testAnanlyzer() throws IOException {
// 1、创建一个分析器对象
Analyzer analyzer = new IKAnalyzer(); // 智能中文分析器
// 2、从分析器对象中获得tokenStream对象
// 参数1:域的名称,可以为null,或者是""
// 参数2:要分析的文本
TokenStream tokenStream = analyzer.tokenStream("", "数据库中存储的数据是结构化数据高富帅,即行数据java,可以用二维表结构来逻辑表达实现的数据。");
// 3、设置一个引用(相当于指针),这个引用可以是多种类型,可以是关键词的引用,偏移量的引用等等
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class); // charTermAttribute对象代表当前的关键词
// 偏移量(其实就是关键词在文档中出现的位置,拿到这个位置有什么用呢?因为我们将来可能要对该关键词进行高亮显示,进行高亮显示要知道这个关键词在哪?)
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
// 4、调用tokenStream的reset方法,不调用该方法,会抛出一个异常
tokenStream.reset();
// 5、使用while循环来遍历单词列表
while (tokenStream.incrementToken()) {
System.out.println("start→" + offsetAttribute.startOffset()); // 关键词起始位置
// 6、打印单词
System.out.println(charTermAttribute);
System.out.println("end→" + offsetAttribute.endOffset()); // 关键词结束位置
}
// 7、关闭tokenStream对象
tokenStream.close();
}
}- 1
运行以上方法,Eclipse控制台打印: 
从上图可知,像“”这样的敏感词汇并没有出现在单词列表中。
分析器的应用场景
索引时使用Analyzer
输入关键字进行搜索,当需要让该关键字与文档域内容所包含的词进行匹配时需要对文档域内容进行分析,需要经过Analyzer分析器处理生成语汇单元(Token)。分析器分析的对象是文档中的Field域。当Field的属性tokenized(是否分词)为true时会对Field值进行分析,如下图: 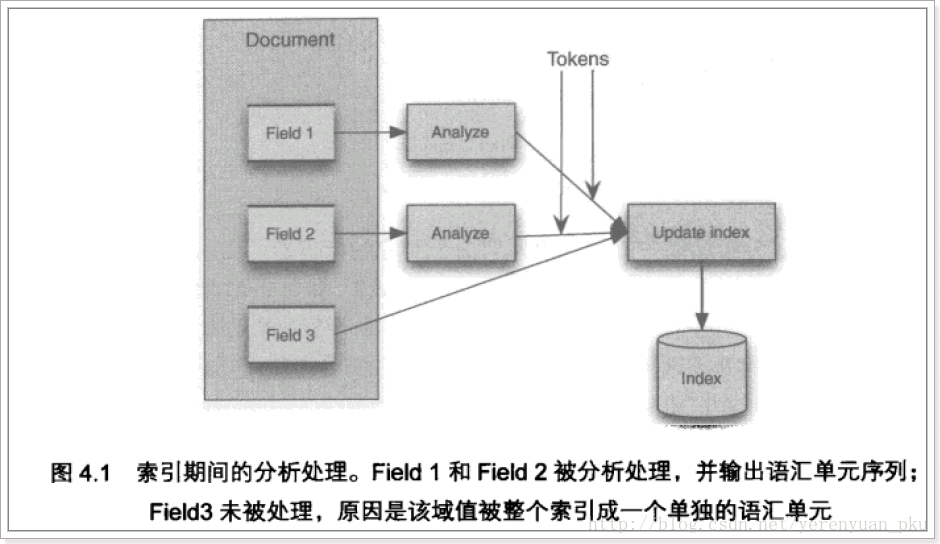
对于一些Field可以不用分析:
- 不作为查询条件的内容,比如文件路径
- 不是匹配内容中的词而匹配Field的整体内容,比如订单号、身份证号等
搜索时使用Analyzer
对搜索关键字进行分析和索引分析一样,使用Analyzer对搜索关键字进行分析、分词处理,使用分析后的每个词语进行搜索。比如:搜索关键字:spring web,经过分析器进行分词,得出:spring web,拿词去索引词典表查找 ,找到索引链接到Document,解析Document内容。
对于匹配整体Field域的查询可以在搜索时不分析,比如根据订单号、身份证号查询等。
注意:搜索使用的分析器要和索引使用的分析器最好保持一致。
- 顶
- 0
- 踩
(转)全文检索技术学习(三)——Lucene支持中文分词的更多相关文章
- (转)全文检索技术学习(一)——Lucene的介绍
http://blog.csdn.net/yerenyuan_pku/article/details/72582979 本文我将为大家讲解全文检索技术——Lucene,现在这个技术用到的比较多,我觉得 ...
- Windows下面安装和配置Solr 4.9(三)支持中文分词器
首先将下载解压后的solr-4.9.0的目录里面F:\tools\开发工具\Lucene\solr-4.9.0\contrib\analysis-extras\lucene-libs找到lucene- ...
- Lucene全文检索技术学习
---------------------------------------------------------------------------------------------------- ...
- Solr的学习使用之(三)IKAnalyzer中文分词器的配置
1.为什么要配置? 1.我们知道要使用Solr进行搜索,肯定要对词语进行分词,但是由于Solr的analysis包并没有带支持中文的包或者对中文的分词效果不好,需要自己添加中文分词器:目前呼声较高的是 ...
- Lucene整理--中文分词
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/hai_cheng001/article/details/37511379 看lucene主页(htt ...
- Lucene的中文分词器IKAnalyzer
分词器对英文的支持是非常好的. 一般分词经过的流程: 1)切分关键词 2)去除停用词 3)把英文单词转为小写 但是老外写的分词器对中文分词一般都是单字分词,分词的效果不好. 国人林良益写的IK Ana ...
- IKAnalyzer结合Lucene实现中文分词
1.基本介绍 随着分词在信息检索领域应用的越来越广泛,分词这门技术对大家并不陌生.对于英文分词处理相对简单,经过拆分单词.排斥停止词.提取词干的过程基本就能实现英文分词,单对于中文分词而言,由于语义的 ...
- lucene之中文分词及其高亮显示(五)
中文分词:即换个分词器 Analyzer analyzer = new StandardAnalyzer();// 标准分词器 换成 SmartChineseAnalyzer analyze ...
- elasticsearch学习笔记-倒排索引以及中文分词
我们使用数据库的时候,如果查询条件太复杂,则会涉及到很多问题 1.无法维护,各种嵌套查询,各种复杂的查询,想要优化都无从下手 2.效率低下,一般语句复杂了之后,比如使用or,like %,,%查询之后 ...
随机推荐
- 用C# (.NET Core) 实现抽象工厂设计模式
用C# (.NET Core) 实现抽象工厂设计模式 本文的概念性内容来自深入浅出设计模式一书. 上一篇文章讲了简单工厂和工厂方法设计模式 http://www.cnblogs.com/cgzl/ ...
- C/C++一些库函数的实现
1. 写出String的具体实现 类的定义: #include <iostream> #include <cstring> using namespace std; class ...
- Xubuntu 计划从 19.04 版本开始停止提供 32 位安装镜像(XDE/LXQt的 Lubuntu 成为了目前唯一仍然提供 32 位安装镜像的 Ubuntu 桌面发行版)
Ubuntu 17.10 以及其他许多 *buntu 衍生品都已在今年早些时候停止提供 32 位安装镜像.但其中有一个依然坚持提供适用于 i386 架构的镜像,它就是 Xubuntu,但现在 Xubu ...
- Ubuntu 16.04 + github page + hexo 搭建博客
1. 安装nodejs: sudo apt-get install nodejs-legacy 2.安装nvm : wget -qO- https://raw.github.com/creatio ...
- TFLearn 在给定模型精度时候提前终止训练
拿来主义:看我的代码,我是在模型acc和验证数据集val_acc都达到99.8%时候才终止训练. import numpy as np import tflearn from tflearn.laye ...
- poj 3621(最优比率环)
Sightseeing Cows Farmer John has decided to reward his cows for their hard work by taking them on a ...
- 推理集 —— death
事故: 自杀: 他杀: 1. 跳楼 头向下死得比较快,没那么痛苦. 脚向下,不会立刻死亡,痛苦至极.死亡原因可能不是跳楼,而是失血过多而死 扑下去, 同头向下. 仰着跌下去,同头向下.. 跳楼最好头先 ...
- 10.06 WZZX Day1总结
今天迎来了WZZX的模拟.打开pdf的时候我特别震惊,出题的竟然是神仙KCZ!没错,就是那个活跃于各大OJ,在各大OJ排名靠前(LOJ Rank1),NOI2018 Rank16进队的kczno1!! ...
- Objective-C 对象的类型与动态结合
创建: 2018/01/21 更新: 2018/01/22 标题前增加 [Objective-C] 完成: 2018/01/24 更新: 2018/01/24 加红加粗属性方法的声明 [不直接获取内部 ...
- mac 修改用户权限
想安装thinkPHP 下载完以后 访问报403错误 于是百度找 也没找到原因 自己猜测是不是用户权限问题 就是下面目录为tp的用户权限 不是root 其他是root的都能访问 于是百度搜了权限如何修 ...