CNN结构:场景分割与Relation Network
参考第一个回答:如何评价DeepMind最新提出的RelationNetWork
参考链接:Relation Network笔记 ,暂时还没有应用到场景中
LiFeifei阿姨的课程:CV与ML课程在线
- 论文:A simple neural network module for relational reasoning
- github代码: https://github.com/siddk/relation-network
摘抄一段:
Visual reasoning是个非常重要的问题,由于ResNet等大杀器出现,visual recognition任务本身快要被解决,所以计算机视觉的研究方向逐渐往认知过程的更上游走,即逻辑推理。
于是出现了去年比较火的Visual question answering(VQA):给张图,你可以问任意问题,人工智能系统都需要给出正确答案。这是我之前做的一个简单的VQA demo (Demo for Visual Question Answering)。VQA任务的典型数据库是COCO-VQA(Introducing the 2nd VQA Challenge!),今年出了第二代。大家做了半天,各种lstm, attention-based model, stacked LSTM等等,发现其实跟BOW+IMG的baseline差不了太多;VQA还是被当成个分类问题,离真正人类级别的reasoning还很远。这里大家逐渐意识到了两个问题,第一个是网络本身的问题,即现有的卷积网络并不能很好的表达因果推断;第二个问题是,直接在自然图片上进行问答系统的研究太难了,很难debug整个系统,于是有了下面两个解决方向:
针对第一个问题,研究者开始在网络设计中explicitly加入reasoning or memory module. 比如说,去年有篇比较有意思的CVPR'16论文,Neural Module Networks( https://arxiv.org/pdf/1511.02799.pdf) , 很好地提出了一个可以让网络进行compositional reasoning的模块,概念挺漂亮。可惜的是调参能力一般,performance离我那个iBOWIMG的baseline也差得不远(参见https://arxiv.org/pdf/1512.02167.pdf)。
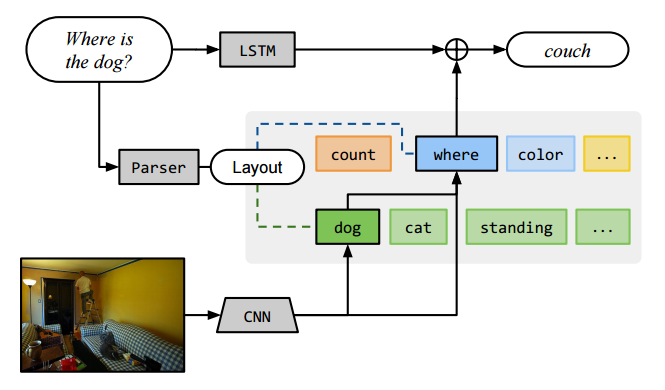
另外,我觉得这篇论文也有一稿多投的嫌疑,因为这几乎一模一样的模型在作者另外一篇Learning to compose neural networks for question answering (https://arxiv.org/pdf/1601.01705.pdf)拿了NAACL'16的best paper 。作者Jacob我也认识,我就不多吐槽了,还好他不会看中文。。。
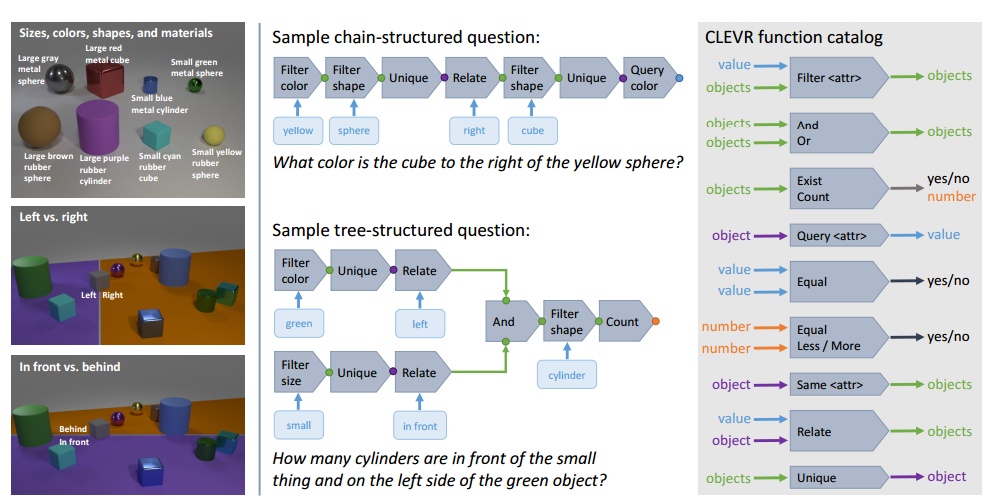
针对第二个问题,研究者开始通过graphics合成图片的办法来建立绝对可控的VQA数据库,这样就可以更好的分析模型的行为。Facebook AI Research几个研究者(Larry Zitnick和Ross Girshick)带着Feifei的学生Justin Johnson实习去年暑假搞了个合成的VQA数据库CLEVR(CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning)。CLEVR有100,000图片,~1,000,000个问题答案对。里面的每张图片都是通过Blender渲染生成,里面的物体基本属性是three object shapes (cube, sphere, cylinder), two absolute sizes (small and large), two materials (shiny, matte), four relationships (left, right, behind, in front)。然后问题也是通过从90个问题模板里面采样生成。 通过各种组合可以生成海量而且可控的问题答案,如下图所示。然后在这篇论文中,作者测试了一些VQA常用的baselines, BOW+IMG, LSTM啥的,表现都一般。那个暑假正好我也在FAIR实习,跟Larry和田总
一起做项目。Larry是非常喜欢这种Neural module network和programming sytax的路子。跟Justin和Ross以及组里其他成员去Lake Tahoe那边hiking的时候也聊起了这个数据库,他们说你那个simple baseline for visual question answering在这个数据库上不管用了啊=,=!。另外,八卦下,Justin是Stanford的跳水运动员,Ross是户外运动达人,所以整个hiking过程中我费了牛劲,也再没见过这两位,望其项背而不得=,=!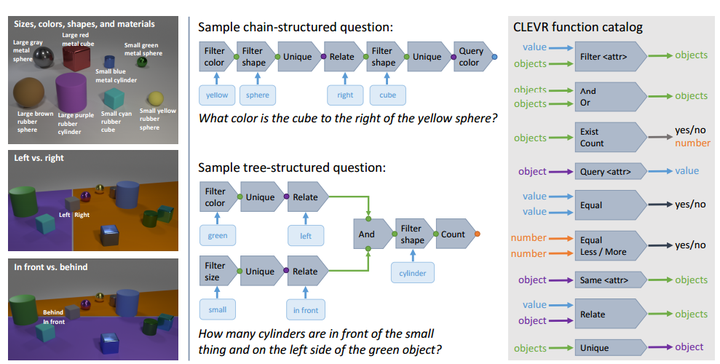
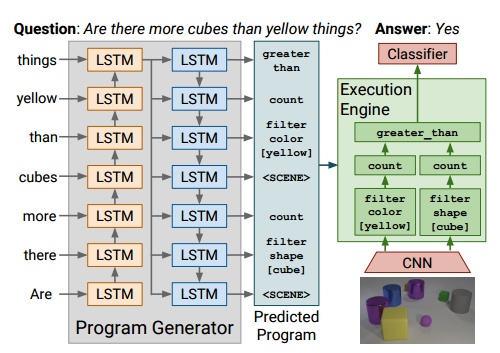
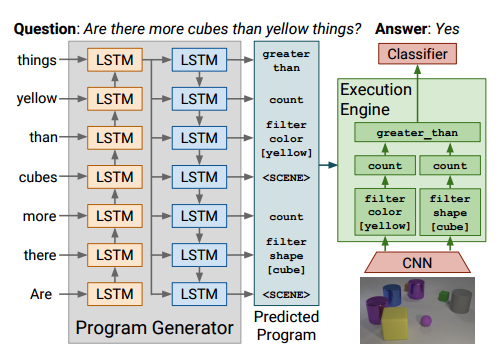
后来,这篇CLEVR数据库的论文被CVPR'17收了。然后,同一堆作者再马不停蹄再交了篇ICCV'17 submission: Inferring and executing programs for visual reasoning (https://arxiv.org/pdf/1705.03633.pdf)。这篇论文也搞了个compositional model for visual question answering的模型。模型有两个模块program generator, execution engine,第一个模块来预测问题里面的program, 第二个模块来执行这些预测出来的program, 然后进一步预测答案。这两个模块还是蛮新颖的,打破了以前做VQA就用CNN叠LSTM的简单粗暴套路。这模型受之前那个Neural Module Network也影响挺大,也更符合CLEVR本身数据的生成过程。结合CLEVR本身的生成program, 这两个模块其实是可以分开进行训练。
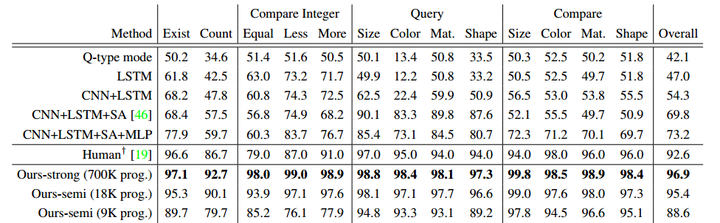
在Table 1里面(如下图所示),作者测试了两种办法, Ours-strong是把CLEVR数据库本身的700K的生成program全部拿来训练(注:这篇论文的作者本来就是CLEVR的作者),然后可以得到牛逼的96.9%, 已经秒杀人类的92.6%准确度。然后Ours-semi方法,用更少量的18K和9K的program进行训练,也可以得到95.4%和88.6%的准确度。
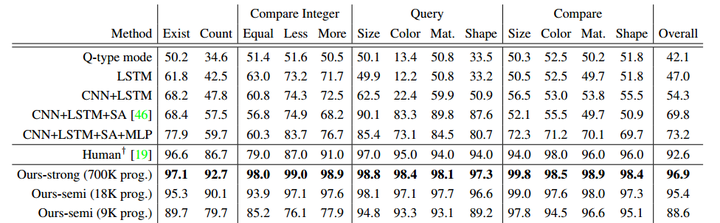
这个训练过程其实蛮tricky。训练过程给的除了question-answer pair, 还给了生成CLEVR数据库本身的program, 这跟其他方法比较就不是这么fair了。另外,我觉得这个训练过程,其实是在训练一个新的网络reverse-engineer之前CLEVR数据库本身的生成程序。并且,这个reverse-engineering的复杂度挺低,用9k program训练就可以达到88.6%就是个证明。换句话说,对于这种自动生成的数据库,用好了方法和模块结构,也许挺容易刷到高分。这就为接下来的Visual Relation Network埋下了伏笔。
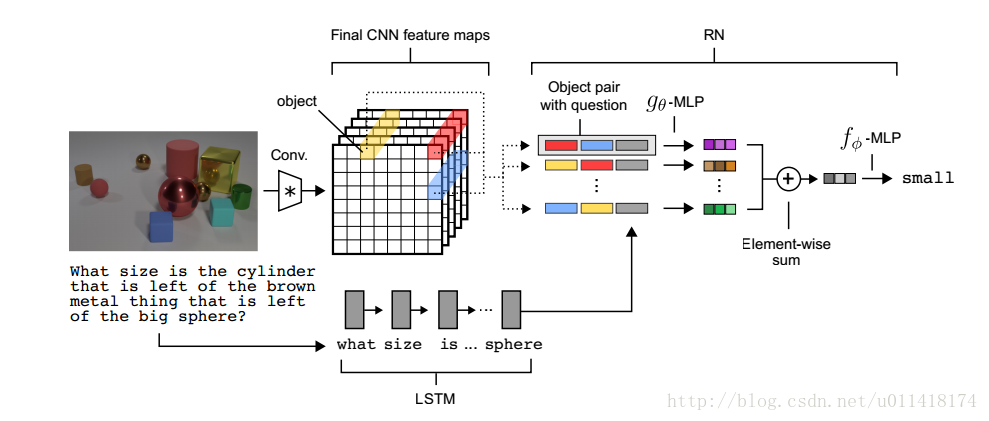
说了这么大堆东西,终于轮到DeepMind的Visual Relation Network module (https://arxiv.org/pdf/1706.01427.pdf)登场了。模型如下图所示,
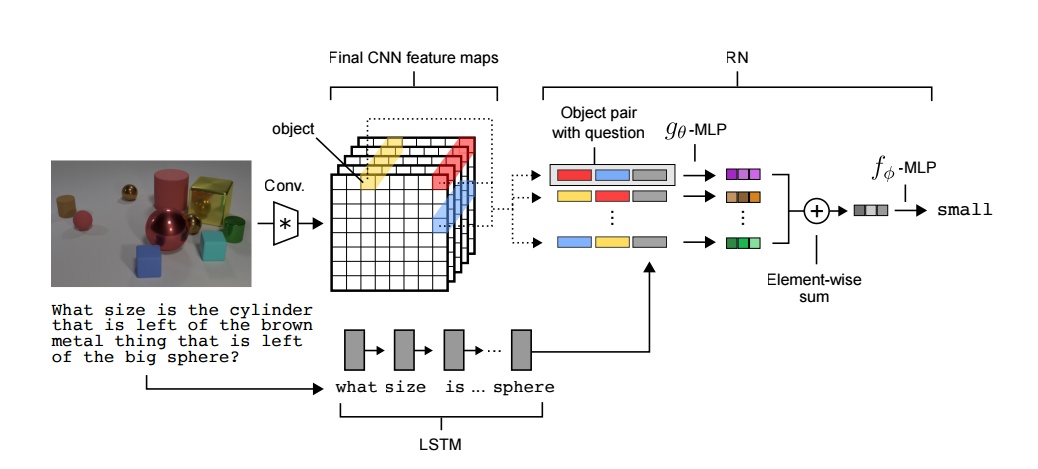
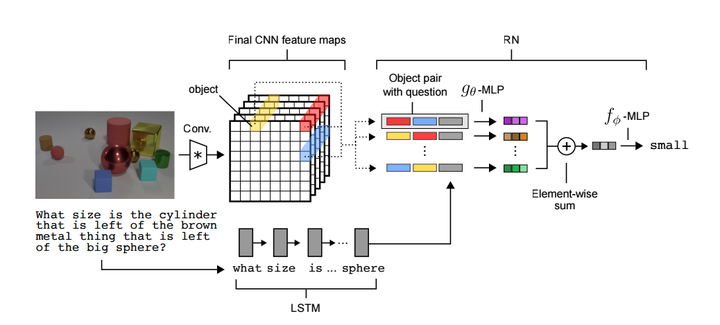
如标题所示,模型结构确实很简单:LSTM编码question, 然后跟两两配对的spatial cell的deep feature叠加,然后后面接一些FC layers最后softmax分类到某个答案词上面。总结起来就是这个非常简单的两两配对的learnable module:
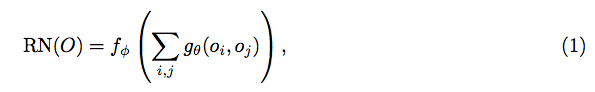
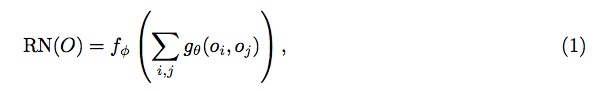
这样简单的模型,在CLEVR上达到了"惊人"的95.5%,比之前最好的CNN+LSTM+SA还要好差不多20%。这里作者并没有比较前面那篇ICCV submission里的96.9%,这是为什么了,作者解释说“ ...(ICCV method) uses additional supervisory signals on the functional programs used to generate the CLEVR questions" 。这种说法的确没任何问题,但这却能帮我们更好的理解模型。
这篇论文并没有给出任何解释模型为什么work, 以及内部到底学到了些什么东西(这是我自己很关注的一个问题)。我自己觉得这个relational module其实是implicitly学到了"the functional programs used to generate the CLEVR questions",也就是说,训练过后这个module可以很完美地reverse engineer那个CLEVR数据本身的生成过程。如果我是这篇论文的reviewer, 我会要求作者对模型进行可视化分析,可能里面的一些hidden units就是在做visual relation detection。
Relational module种explicitly表达两两物体关系的做法,跟之前DeepMind的那篇Spatial Transformer (https://arxiv.org/pdf/1506.02025.pdf)也有共通之处:CNN网络本身并不能很好地表达某些变换或者关系,所以需要一些特定的learnable的module结构来帮助表达和学习。可以预见这个relational module可以在很多结构化数据,如graph learning, structure learning等结构化数据上派上大用场。论文中也把模型在其他两个数据库任务bAbI model for language understanding(这个数据库其实早就被刷到100%了)和dynamic physical system reasonsing进行了测试,都取得了不错的效果。但是,这个module是真正解决了relationship detection的问题,还是仅仅只是利用short-cut来overfit数据库,还得等到人们在其他场合,如visual relationship detection(Visual Relationship Detection with Language Priors)等测试其有效性
作者:周博磊
链接:https://www.zhihu.com/question/60784169/answer/180518895
CNN结构:场景分割与Relation Network的更多相关文章
- CNN结构:用于检测的CNN结构进化-分离式方法
前言: 原文链接:基于CNN的目标检测发展过程 文章有大量修改,如有不适,请移步原文. 参考文章:图像的全局特征--用于目标检测 目标的检测和定位中一个很困难的问题是,如何从数以万计的候选 ...
- AI:IPPR的数学表示-CNN结构进化(Alex、ZF、Inception、Res、InceptionRes)
前言: 文章:CNN的结构分析-------: 文章:历年ImageNet冠军模型网络结构解析-------: 文章:GoogleLeNet系列解读-------: 文章:DNN结构演进Histor ...
- CNN结构演变总结(二)轻量化模型
CNN结构演变总结(一)经典模型 导言: 上一篇介绍了经典模型中的结构演变,介绍了设计原理,作用,效果等.在本文,将对轻量化模型进行总结分析. 轻量化模型主要围绕减少计算量,减少参数,降低实际运行时间 ...
- CNN结构演变总结(一)经典模型
导言: 自2012年AlexNet在ImageNet比赛上获得冠军,卷积神经网络逐渐取代传统算法成为了处理计算机视觉任务的核心. 在这几年,研究人员从提升特征提取能力,改进回传梯度更新效果 ...
- CNN结构演变总结(三)设计原则
CNN结构演变总结(一)经典模型 CNN结构演变总结(二)轻量化模型 前言: 前两篇对一些经典模型和轻量化模型关于结构设计方面的一些创新进行了总结,在本文将对前面的一些结构设计的原则,作用进行总结. ...
- Learning to Compare: Relation Network 源码调试
CVPR 2018 的一篇少样本学习论文 Learning to Compare: Relation Network for Few-Shot Learning 源码地址:https://github ...
- CNN结构:图片风格分类效果已成(StyleAI)
CNN结构:图片风格分类效果已成.可以在色彩空间对图片风格进行分类,并进行目标分类. StyleAI构架:FasterRCnn + RandomTrees 为何不使用MaskRCNN? MaskRCN ...
- Learning to Compare: Relation Network for Few-Shot Learning 论文笔记
主要原理: 和Siamese Neural Networks一样,将分类问题转换成两个输入的相似性问题. 和Siamese Neural Networks不同的是: Relation Network中 ...
- 转-------CNN图像相似度匹配 2-channel network
基于2-channel network的图片相似度判别 原文地址:http://blog.csdn.net/hjimce/article/details/50098483 作者:hjimce 一.相 ...
随机推荐
- [Java Sprint] Spring Configuration Using Java
There is no applicationContext.xml file. Too much XML Namespaces helped Enter Java Configuration Cre ...
- win7下 sublime text2操作快捷键 - leafu
Ctrl+L 选择整行(按住-继续选择下行) Ctrl+KK 从光标处删除至行尾 ...
- WebSphere报错指南
看了下面的文章,泥坑会叫我标题党,没错我就是啊. 1.was日志路径 ${WebSphere根路径}/AppServer/profiles/AppSrv01/logs/,比如说我的路径就是/opt/I ...
- 鸟哥的Linux私房菜-----1、Linux是什么与怎样学习Linux
- web 开发之js---js获取select标签选中的值
var obj = document.getElementByIdx_x(”testSelect”); //定位id var index = obj.selectedIndex; // 选中索引 va ...
- 在弱网传输的情况下,是怎么做到节约流量的(面试小问题,Android篇)
立即毕业了,在毕业之际.我辞掉了曾经的实习工作,主要是工作内容不太感兴趣.近期在找工作.主要是找Java和Android方面的工作.自以为学得不错.可是面试屡屡受挫. 先提一下问到的一些问题吧. 第一 ...
- 洛谷P2668 斗地主==codevs 4610 斗地主[NOIP 2015 day1 T3]
P2668 斗地主 326通过 2.6K提交 题目提供者洛谷OnlineJudge 标签搜索/枚举NOIp提高组2015 难度提高+/省选- 提交该题 讨论 题解 记录 最新讨论 出现未知错误是说梗啊 ...
- hdu 4990 Reading comprehension(等比数列法)
题目链接:pid=4990" style="color:rgb(255,153,0); text-decoration:none; font-family:Arial; line- ...
- 蓝桥 PREV-34 历届试题 矩阵翻硬币
历届试题 矩阵翻硬币 时间限制:1.0s 内存限制:256.0MB 问题描述 小明先把硬币摆成了一个 n 行 m 列的矩阵. 随后,小明对每一个硬币分别进行一次 Q 操作. 对第 ...
- [RK3288][Android6.0] 系统按键驱动流程分析【转】
本文转载自:http://blog.csdn.net/kris_fei/article/details/77894406 Rockchip的按键驱动位于 kernel/drivers/input/ke ...