4.2 Context-Free Grammars
4.2 Context-Free Grammars
Grammars were introduced in Section 2.2 to systematically describe the syntax of programming language constructs like expressions and statements. Using a syntactic variable stmt to denote statements and variable expr to denote expressions, the production
|
stmt→if ( expr ) stmt else stmt |
(4.4) |
specifies the structure of this form of conditional statement. Other productions then define precisely what an expr is and what else a stmt can be.
This section reviews the definition of a context-free grammar and introduces terminology for talking ab out parsing. In particular, the notion of derivations is very helpful for discussing the order in which productions are applied during parsing.
4.2.1 The Formal Definition of a Context-Free Grammar
From Section 2.2, a context-free grammar (grammar for short) consists of terminals, nonterminals, a start symbol, and productions.
1. Terminals are the basic symbols from which strings are formed. The term “token name” is a synonym for “terminal” and frequently we will use the word “token” for terminal when it is clear that we are talking ab out just the token name. We assume that the terminals are the first components of the tokens output by the lexical analyzer. In (4.4), the terminals are the keywords if and else and the symbols “(“ and “).”
2. Nonterminals are syntactic variables that denote sets of strings. In (4.4), stmt and expr are nonterminals. The sets of strings denoted by nonterminals help define the language generated by the grammar. Nonterminals impose a hierarchical structure on the language that is key to syntax analysis and translation.
3. In a grammar, one nonterminal is distinguished as the start symbol, and the set of strings it denotes is the language generated by the grammar. Conventionally, the productions for the start symbol are listed first.
4. The productions of a grammar specify the manner in which the terminals and nonterminals can be combined to form strings. Each production consists of:
a) A nonterminal called the head or left side of the production; this production defines some of the strings denoted by the head.
b) The symbol →. Sometimes ::= has been used in place of the arrow.
c) A body or right side consisting of zero or more terminals and nonterminals. The components of the body describe one way in which strings of the nonterminal at the head can be constructed.
Example 4.5: The grammar in Fig. 4.2 defines simple arithmetic expressions. In this grammar, the terminal symbols are
id + - * / ( )
The nonterminal symbols are expression, term and factor, and expression is the start symbol □
|
expression |
→ |
expression + term |
|
expression |
→ |
expression - term |
|
expression |
→ |
term |
|
term |
→ |
term * factor |
|
term |
→ |
term / factor |
|
term |
→ |
factor |
|
factor |
→ |
( expression ) |
|
factor |
→ |
id |
|
Figure 4.2: Grammar for simple arithmetic expressions |
||
4.2.2 Notational Conventions
To avoid always having to state that “these are the terminals,” “these are the nonterminals,” and so on, the following notational conventions for grammars will be used throughout the remainder of this book.
1. These symbols are terminals:
a) Lowercase letters early in the alphabet, such as a, b, c.
b) Operator symbols such as +, *, and so on.
c) Punctuation symbols such as parentheses, comma, and so on.
d) The digits 0, 1, …, 9.
e) Boldface strings such as id or if, each of which represents a single terminal symbol.
2. These symbols are nonterminals:
a) Uppercase letters early in the alphabet, such as A, B, C.
b) The letter S, which, when it appears, is usually the start symbol.
c) Lowercase, italic names such as expr or stmt.
d) When discussing programming constructs, uppercase letters may be used to represent nonterminals for the constructs. For example, nonterminals for expressions, terms, and factors are often represented by E, T, and F, respectively.
3. Uppercase letters late in the alphabet, such as X, Y, Z, represent grammar symbols; that is, either nonterminals or terminals.
4. Lowercase letters late in the alphabet, chiefly u, v, …, z , represent (possibly empty) strings of terminals.
5. Lowercase Greek letters, α, β, γ for example, represent (possibly empty) strings of grammar symbols. Thus, a generic production can be written as A → α, where A is the head and the body.
6. A set of productions A → α1, A → α2, …, A → αk with a common head A (call them A-productions), may be written A → α1 | α2 | … | αk. Call α1, α2, …, αk the alternatives for A.
7. Unless stated otherwise, the head of the first production is the start symbol.
Example 4.6: Using these conventions, the grammar of Example 4.5 can be rewritten concisely as
E → E + T | E - T | T
T → T * F | T / F | F
F → ( E ) | id
The notational conventions tell us that E, T, and F are nonterminals, with E the start symbol. The remaining symbols are terminals. □
4.2.3 Derivations
The construction of a parse tree can be made precise by taking a derivational view, in which productions are treated as rewriting rules. Beginning with the start symbol, each rewriting step replaces a nonterminal by the body of one of its productions. This derivational view corresponds to the top-down construction of a parse tree, but the precision a order by derivations will be especially helpful when bottom-up parsing is discussed. As we shall see, bottom-up parsing is related to a class of derivations known as “rightmost” derivations, in which the rightmost nonterminal is rewritten at each step.
For example, consider the following grammar, with a single nonterminal E, which adds a production E → - E to the grammar (4.3):
|
E → E + E | E * E | - E | ( E ) | id |
(4.7) |
The production E → - E signifies that if E denotes an expression, then - E must also denote an expression. The replacement of a single E by - E will be described by writing
E ⇒ - E
which is read, “E derives - E .” The production E → ( E ) can be applied to replace any instance of E in any string of grammar symbols by (E ), e.g., E * E ⇒ (E ) * E or E * E ⇒ E * (E). We can take a single E and repeatedly apply productions in any order to get a sequence of replacements. For example,
E ⇒ - E ⇒ - (E) ⇒ - (id)
We call such a sequence of replacements a derivation of - (id) from E. This derivation provides a proof that the string - (id) is one particular instance of an expression.
For a general definition of derivation, consider a nonterminal A in the middle of a sequence of grammar symbols, as in αAβ, where α and β are arbitrary strings of grammar symbols. Suppose A → γ is a production. Then, we write αAβ⇒αγβ. The symbol ⇒ means, “derives in one step.” When a sequence of derivation steps α1 ⇒ α2 ⇒ … ⇒ αn rewrites α1 to αn, we say α1 derives αn. Often, we wish to say, “derives in zero or more steps.” For this purpose, we can use the symbol *⇒. Thus,
1. α *⇒ α, for any string α, and
2. If α *⇒ β and β⇒ γ, then α *⇒ γ.
Likewise, +⇒ means, “derives in one or more steps.”
If S *⇒ α, where S is the start symbol of a grammar G, we say that is a sentential form of G. Note that a sentential form may contain both terminals and nonterminals, and may be empty. A sentence of G is a sentential form with no nonterminals. The language generated by a grammar is its set of sentences. Thus, a string of terminals ω is in L(G), the language generated by G, if and only if ω is a sentence of G (or S *⇒ ω ). A language that can be generated by a grammar is said to be a context-free language. If two grammars generate the same language, the grammars are said to be equivalent.
The string, - (id + id) is a sentence of grammar (4.7) because there is a derivation
|
E ⇒ - E ⇒ - (E ) ⇒ - (E + E ) ⇒ - (id + E) ⇒ - (id + id) |
(4.8) |
The strings E, - E, - (E), … , - (id + id) are all sentential forms of this grammar. We write E *⇒ - (id + id) to indicate that - (id + id) can be derived from E.
At each step in a derivation, there are two choices to be made. We need to choose which nonterminal to replace, and having made this choice, we must pick a production with that nonterminal as head. For example, the following alternative derivation of - (id + id) differs from derivation (4.8) in the last two steps:
|
E ⇒ - E ⇒ - (E ) ⇒ - (E + E ) ⇒ - (E + id) ⇒ - (id + id) |
(4.9) |
Each nonterminal is replaced by the same body in the two derivations, but the order of replacements is different.
To understand how parsers work, we shall consider derivations in which the nonterminal to be replaced at each step is chosen as follows:
1. In leftmost derivations, the leftmost nonterminal in each sentential is always chosen. If α⇒β is a step in which the leftmost nonterminal in α is replaced, we write α lm⇒ β.
2. In rightmost derivations, the rightmost nonterminal is always chosen; we write α rm⇒ β in this case.
Derivation (4.8) is leftmost, so it can be rewritten as
E lm⇒ - E lm⇒ - (E) lm⇒ - (E + E) lm⇒ - (id + E) lm⇒ - (id + id)
Note that (4.9) is a rightmost derivation.
Using our notational conventions, every leftmost step can be written as ωAγ lm⇒ ωδγ, where ω consists of terminals only, A → δ is the production applied, and γ is a string of grammar symbols. To emphasize that α derives β by a leftmost derivation, we write α *lm⇒ β. If S *lm⇒ α, then we say that α is a left-sentential form of the grammar at hand.
Analogous definitions hold for rightmost derivations. Rightmost derivations are sometimes called canonical derivations.
4.2.4 Parse Trees and Derivations
A parse tree is a graphical representation of a derivation that alters out the order in which productions are applied to replace nonterminals. Each interior node of a parse tree represents the application of a production. The interior node is labeled with the nonterminal A in the head of the production; the children of the node are labeled, from left to right, by the symbols in the body of the production by which this A was replaced during the derivation.
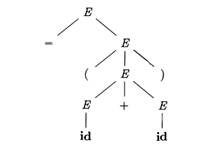
For example, the parse tree for - (id + id) in Fig. 4.3, results from the derivation (4.8) as well as derivation (4.9).
The leaves of a parse tree are labeled by nonterminals or terminals and, read from left to right, constitute a sentential form, called the yield or frontier of the tree.
To see the relationship between derivations and parse trees, consider any derivation α1 ⇒ α2 ⇒ … ⇒ αn, where α1 is a single nonterminal A. For each sentential form αi in the derivation, we can construct a parse tree whose yield is αi. The process is an induction on i.
BASIS: The tree for α1 = A is a single node labeled A.
|
|
|
Figure 4.3: Parse tree for - (id + id) |
INDUCTION: Suppose we already have constructed a parse tree with yield αi-1 = X1 X2 … Xk (note that according to our notational conventions, each grammar symbol Xi is either a nonterminal or a terminal). Suppose αi is derived from αi-1 by replacing Xj, a nonterminal, by β = Y1 Y2 … Ym. That is, at the ith step of the derivation, production Xj → β is applied to αi-1 to derive αi = X1 X2 … Xj-1 β Xj+1 … Xk.
To model this step of the derivation, find the jth non-ϵ leaf from the left in the current parse tree. This leaf is labeled Xj. Give this leaf m children, labeled Y1, Y2, …, Ym, from the left. As a special case, if m = 0, then β = ϵ, and we give the jth leaf one child labeled ϵ.
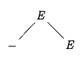
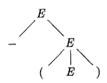
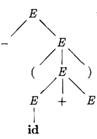
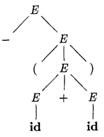
Example 4.10: The sequence of parse trees constructed from the derivation (4.8) is shown in Fig. 4.4. In the first step of the derivation, E ⇒ - E. To model this step, add two children, labeled - and E, to the root E of the initial tree. The result is the second tree.
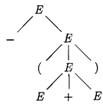
In the second step of the derivation - E ⇒ - (E). Consequently, add three children, labeled (, E, and ), to the leaf labeled E of the second tree, to obtain the third tree with yield - (E). Continuing in this fashion we obtain the complete parse tree as the sixth tree. □
Since a parse tree ignores variations in the order in which symbols in sentential forms are replaced, there is a many-to-one relationship between derivations and parse trees. For example, both derivations (4.8) and (4.9), are associated with the same final parse tree of Fig. 4.4.
In what follows, we shall frequently parse by producing a leftmost or a rightmost derivation, since there is a one-to-one relationship between parse trees and either leftmost or rightmost derivations. Both leftmost and rightmost derivations pick a particular order for replacing symbols in sentential forms, so they too alter out variations in the order. It is not hard to show that every parse tree has associated with it a unique leftmost and a unique rightmost derivation.
|
|
E |
⇒ |
|
⇒ |
|
|
⇒ |
|
⇒ |
|
⇒ |
|
|
Figure 4.4: Sequence of parse trees for derivation (4.8) |
|||||
4.2.5 Ambiguity
From Section 2.2.4, a grammar that produces more than one parse tree for some sentence is said to be ambiguous. Put another way, an ambiguous grammar is one that produces more than one leftmost derivation or more than one rightmost derivation for the same sentence.
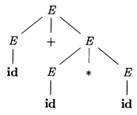
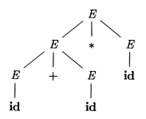
Example 4.11: The arithmetic expression grammar (4.3) permits two distinct leftmost derivations for the sentence id + id * id:
|
E |
⇒ E + E ⇒ id + E ⇒ id + E * E ⇒ id + id * E ⇒ id + id * id |
E |
⇒ E * E ⇒ E + E * E ⇒ id + E * E ⇒ id + id * E ⇒ id + id * id |
The corresponding parse trees app ear in Fig. 4.5.
Note that the parse tree of Fig. 4.5(a) reflects the commonly assumed precedence of + and *, while the tree of Fig. 4.5(b) does not. That is, it is customary to treat operator * as having higher precedence than +, corresponding to the fact that we would normally evaluate an expression like a + b * c as a + (b * c), rather than as (a + b) * c. □
For most parsers, it is desirable that the grammar be made unambiguous, for if it is not, we cannot uniquely determine which parse tree to select for a sentence. In other cases, it is convenient to use carefully chosen ambiguous grammars, together with disambiguating rules that “throw away” undesirable parse trees, leaving only one tree for each sentence.
|
|
|
|
(a) |
(b) |
|
Figure 4.5: Two parse trees for id+id*id |
|
4.2.6 Verifying the Language Generated by a Grammar
Although compiler designers rarely do so for a complete programming-language grammar, it is useful to be able to reason that a given set of productions generates a particular language. Troublesome constructs can be studied by writing a concise, abstract grammar and studying the language that it generates. We shall construct such a grammar for conditional statements below.
A proof that a grammar G generates a language L has two parts: show that every string generated by G is in L, and conversely that every string in L can indeed be generated by G.
Example 4.12: Consider the following grammar:
S → ( S ) S |ϵ (4.13)
It may not be initially apparent, but this simple grammar generates all strings of balanced parentheses, and only such strings. To see why, we shall show first that every sentence derivable from S is balanced, and then that every balanced string is derivable from S. To show that every sentence derivable from S is balanced, we use an inductive proof on the number of steps n in a derivation.
BASIS: The basis is n = 1. The only string of terminals derivable from S in one step is the empty string, which surely is balanced.
INDUCTION: Now assume that all derivations of fewer than n steps produce balanced sentences, and consider a leftmost derivation of exactly n steps. Such a derivation must be of the form
S lm⇒ ( S )S *lm⇒ (x)S lm⇒ (x)y
The derivations of x and y from S take fewer than n steps, so by the inductive hypothesis x and y are balanced. Therefore, the string (x)y must be balanced. That is, it has an equal number of left and right parentheses, and every prefix has at least as many left parentheses as right.
Having thus shown that any string derivable from S is balanced, we must next show that every balanced string is derivable from S. To do so, use induction on the length of a string.
BASIS: If the string is of length 0, it must be *, which is balanced.
INDUCTION: First, observe that every balanced string has even length. Assume that every balanced string of length less than 2n is derivable from S, and consider a balanced string w of length 2n, n≥1. Surely ω begins with a left parenthesis. Let (x) be the shortest nonempty prefix of ω having an equal number of left and right parentheses. Then ω can be written as ω = (x)y where both x and y are balanced. Since x and y are of length less than 2n, they are derivable from S by the inductive hypothesis. Thus, we can find a derivation of the form
S ⇒ (S )S *⇒ (x)S *⇒ (x)y
proving that ω = (x)y is also derivable from S. □
4.2.7 Context-Free Grammars Versus Regular Expressions
Before leaving this section on grammars and their properties, we establish that grammars are a more powerful notation than regular expressions. Every construct that can be described by a regular expression can be described by a grammar, but not vice-versa. Alternatively, every regular language is a context-free language, but not vice-versa.
For example, the regular expression (a|b) * abb and the grammar
A0 → aA0 | bA0 | aA1
A1 → bA2
A2 → bA3
A3 → ϵ
describe the same language, the set of strings of a’s and b’s ending in abb.
We can construct mechanically a grammar to recognize the same language as a nondeterministic finite automaton (NFA). The grammar above was constructed from the NFA in Fig. 3.24 using the following construction:
1. For each state i of the NFA, create a nonterminal Ai.
2. If state i has a transition to state j on input a, add the production Ai →aAj. If state i goes to state j on input ϵ, add the production Ai → Aj.
3. If i is an accepting state, add Ai → ϵ.
4. If i is the start state, make Ai be the start symbol of the grammar.
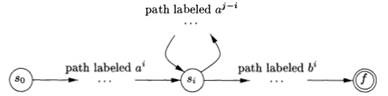
On the other hand, the language L = {an bn | n≥1} with an equal number of a’s and b’s is a prototypical example of a language that can be described by a grammar but not by a regular expression. To see why, Suppose L were the language defined by some regular expression. We could construct a DFA D with a finite number of states, say k, to accept L. Since D has only k states, for an input beginning with more than k a’s, D must enter some state twice, say si, as in Fig. 4.6. Suppose that the path from si back to itself is labeled with a sequence a j-i. Since ai bi is in the language, there must be a path labeled bi from si to an accepting state f. But, then there is also a path from the initial state s0 through si to f labeled aj bi, as shown in Fig. 4.6. Thus, D also accepts aj bi, which is not in the language, contradicting the assumption that L is the language accepted by D.
|
|
|
Figure 4.6: DFA D accepting both ai bi and aj bi. |
Colloquially, we say that “finite automata cannot count,” meaning that a finite automaton cannot accept a language like {an bn | n≥1} that would require it to keep count of the number of a’s before it sees the b’s. Likewise, “a grammar can count two items but not three,” as we shall see when we consider non-context-free language constructs in Section 4.3.5.
4.2 Context-Free Grammars的更多相关文章
- NLP--自然语言处理与机器学习会议
http://blog.csdn.net/ice110956/article/details/17090061 整理至11月中旬在重庆参加的自然语言处理与机器学习会议,第一讲为自然语言处理. 由基本理 ...
- (转)Understanding C parsers generated by GNU Bison
原文链接:https://www.cs.uic.edu/~spopuri/cparser.html Satya Kiran PopuriGraduate StudentUniversity of Il ...
- 4.8 Using Ambiguous Grammars
4.8 Using Ambiguous Grammars It is a fact that every ambiguous grammar fails to be LR and thus is no ...
- Javascript 的执行环境(execution context)和作用域(scope)及垃圾回收
执行环境有全局执行环境和函数执行环境之分,每次进入一个新执行环境,都会创建一个搜索变量和函数的作用域链.函数的局部环境不仅有权访问函数作用于中的变量,而且可以访问其外部环境,直到全局环境.全局执行环境 ...
- spring源码分析之<context:property-placeholder/>和<property-override/>
在一个spring xml配置文件中,NamespaceHandler是DefaultBeanDefinitionDocumentReader用来处理自定义命名空间的基础接口.其层次结构如下: < ...
- spring源码分析之context
重点类: 1.ApplicationContext是核心接口,它为一个应用提供了环境配置.当应用在运行时ApplicationContext是只读的,但你可以在该接口的实现中来支持reload功能. ...
- CSS——关于z-index及层叠上下文(stacking context)
以下内容根据CSS规范翻译. z-index 'z-index'Value: auto | <integer> | inheritInitial: autoApplies to: posi ...
- Tomcat启动报错org.springframework.web.context.ContextLoaderListener类配置错误——SHH框架
SHH框架工程,Tomcat启动报错org.springframework.web.context.ContextLoaderListener类配置错误 1.查看配置文件web.xml中是否配置.or ...
- mono for android Listview 里面按钮 view Button click 注册方法 并且传值给其他Activity 主要是context
需求:为Listview的Item里面的按钮Button添加一个事件,单击按钮时通过事件传值并跳转到新的页面. 环境:mono 效果: 布局代码 主布局 <?xml version=" ...
- Javascript的“上下文”(context)
一:JavaScript中的“上下文“指的是什么 百科中这样定义: 上下文是从英文context翻译过来,指的是一种环境. 在软件工程中,上下文是一种属性的有序序列,它们为驻留在环境内的对象定义环境. ...
随机推荐
- assert.notEqual()
浅测试,使用不等于比较运算符(!=)比较. const assert = require('assert'); assert.notEqual(1, 2); // OK assert.notEqual ...
- 去面试Python工程师,这几个基础问题一定要能回答,Python面试题No4
今天的面试题以基础为主,去面试Python工程师,这几个基础问题不能答错 第1题:列表和元组有什么不同? 列表和元组是Python中最常用的两种数据结构,字典是第三种. 相同点: 都是序列 都可以存储 ...
- 2. Java中的垃圾收集 - GC参考手册
标记-清除(Mark and Sweep)是最经典的垃圾收集算法.将理论用于生产实践时, 会有很多需要优化调整的地点, 以适应具体环境.下面通过一个简单的例子, 让我们一步步记录下来, 看看如何才能保 ...
- [bzoj1058][ZJOI2007][报表统计] (STL)
Description 小Q的妈妈是一个出纳,经常需要做一些统计报表的工作.今天是妈妈的生日,小Q希望可以帮妈妈分担一些工 作,作为她的生日礼物之一.经过仔细观察,小Q发现统计一张报表实际上是维护一个 ...
- <c:foreach> 标签获取循环次数
<c:forEach var="i" begin="1" end="9" varStatus="status"&g ...
- JQuery_九大选择器
JQuery_九大选择器-----https://blog.csdn.net/pseudonym_/article/details/76093261
- 《C语言程序设计(第四版)》阅读心得(四 文件操作)
第10章 对文件的输入输出 函数名 调用形式 功能 fopen fopen(“a1”,”r”); 打开一个文件 fclose fclose( fp ); 关闭数据文件 fgetc fgetc( fp ...
- noip模拟赛 星空
分析:非常神的一道题.迭代加深搜索+rand可以骗得20分.状压n的话只有24分,必须对问题进行一个转化. 在爆搜的过程中,可以利用差分来快速地对一个区间进行修改,把一般的差分改成异或型的差分: b[ ...
- bzoj 2588 Spoj 10628. Count on a tree (可持久化线段树)
Spoj 10628. Count on a tree Time Limit: 12 Sec Memory Limit: 128 MBSubmit: 7669 Solved: 1894[Submi ...
- [bzoj1500][NOI2005]维修数列[Treap][可持久化Treap]
非旋转式Treap1500 :) #include <bits/stdc++.h> #pragma GCC optimize(3) using namespace std; const i ...