LinkedList集合(JDK1.8)
简述
按照上篇笔记ArrayList集合继续进行介绍list的另一个常见子类LinkedList
?LinkedList介绍
1.数据结构

说明:linkedlist的底层数据结构是个双向链表结构,也意味着linkedlist在进行查询时效率会比ArrayList的慢,而插入和删除只是对指针进行移动,相对于ArrayList就会快很多
2.源码分析
2.1类的继承关系
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
2.2类的属性
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
// 实际元素个数
transient int size = 0;
// 头结点
transient Node<E> first;
// 尾结点
transient Node<E> last;
} private static class Node<E> {
E item; // 数据域
Node<E> next; // 后继
Node<E> prev; // 前驱 // 构造函数,赋值前驱后继
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
说明:linkedlist的结构中,一个头结点,一个尾节点,一个表示链表中实际元素个数的变量。注意,头结点、尾结点都有transient关键字修饰,这也意味着在序列化时该域是不会序列化的。
2.3构造函数
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
// 调用无参构造函数
this();
// 添加集合中所有的元素
addAll(c);
}
说明:会调用无参构造函数,并且会把集合中所有的元素添加到LinkedList中。
2.4核心函数
1.add函数
public boolean add(E e) {
// 添加到末尾
linkLast(e);
return true;
}
void linkLast(E e) {
// 保存尾结点,l为final类型,不可更改
final Node<E> l = last;
// 新生成结点的前驱为l,后继为null
final Node<E> newNode = new Node<>(l, e, null);
// 重新赋值尾结点
last = newNode;
if (l == null) // 尾结点为空
first = newNode; // 赋值头结点
else // 尾结点不为空
l.next = newNode; // 尾结点的后继为新生成的结点
// 大小加1
size++;
// 结构性修改加1
modCount++;
}
举个栗子
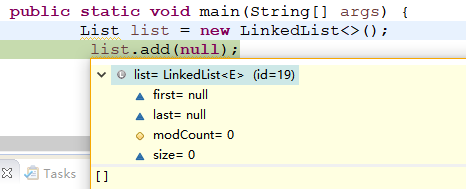
说明:初始化状态效果
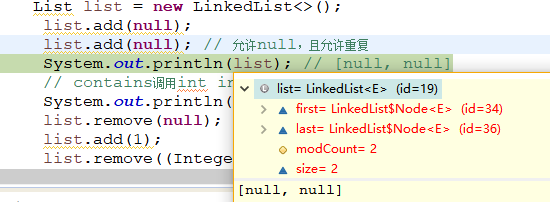
说明:linkedlist允许传入值是重复的,并且也允许为null
2.add(int index, E element)函数
// 插入元素
public void add(int index, E element) {
checkPositionIndex(index); // 检查是否越界
if (index == size) // 在链表末尾添加
linkLast(element);
else // 在链表中间添加
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
说明:通过先判断index的合法性,然后再与size进行比较,如果等于size的话,就相当于直接调用了addlast方法,若不是,则进行中间插入操作。
3.addAll函数
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
// 添加一个集合
public boolean addAll(int index, Collection<? extends E> c) {
// 检查插入的的位置是否合法
checkPositionIndex(index);
// 将集合转化为数组
Object[] a = c.toArray();
// 保存集合大小
int numNew = a.length;
if (numNew == 0) // 集合为空,直接返回
return false;
Node<E> pred, succ; // 前驱,后继
if (index == size) { // 如果插入位置为链表末尾,则后继为null,前驱为尾结点
succ = null;
pred = last;
} else { // 插入位置为其他某个位置
succ = node(index); // 寻找到该结点
pred = succ.prev; // 保存该结点的前驱
}
for (Object o : a) { // 遍历数组
@SuppressWarnings("unchecked") E e = (E) o; // 向下转型
// 生成新结点
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null) // 表示在第一个元素之前插入(索引为0的结点)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) { // 表示在最后一个元素之后插入
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
// 修改实际元素个数
size += numNew;
// 结构性修改加1
modCount++;
return true;
}
说明:addAll有两个重载函数,addAll(Collection<? extends E>)型和addAll(int, Collection<? extends E>)型,我们平时习惯调用的addAll(Collection<? extends E>)型会转化为addAll(int, Collection<? extends E>)型。
参数中的index表示在索引下标为index的结点(实际上是第index + 1个结点)的前面插入。在addAll函数中,addAll函数中还会调用到node函数,get函数也会调用到node函数,此函数是根据索引下标找到该结点并返回,具体代码如下
Node<E> node(int index) {
// 判断插入的位置在链表前半段或者是后半段
if (index < (size >> 1)) { // 插入位置在前半段
Node<E> x = first;
for (int i = 0; i < index; i++) // 从头结点开始正向遍历
x = x.next;
return x; // 返回该结点
} else { // 插入位置在后半段
Node<E> x = last;
for (int i = size - 1; i > index; i--) // 从尾结点开始反向遍历
x = x.prev;
return x; // 返回该结点
}
}
说明:在根据索引查找结点时,会有一个小优化,结点在前半段则从头开始遍历,在后半段则从尾开始遍历,这样就保证了只需要遍历最多一半结点就可以找到指定索引的结点。
4.indexOf函数
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
说明:indexOf操作非常简单,就是从头开始遍历整个链表,如果没有就反-1,有就返回当前下标
举个栗子

5.remove函数
public E remove() {
return removeFirst();
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
E unlink(Node<E> x) {
// 保存结点的元素
final E element = x.item;
// 保存x的后继
final Node<E> next = x.next;
// 保存x的前驱
final Node<E> prev = x.prev;
if (prev == null) { // 前驱为空,表示删除的结点为头结点
first = next; // 重新赋值头结点
} else { // 删除的结点不为头结点
prev.next = next; // 赋值前驱结点的后继
x.prev = null; // 结点的前驱为空,切断结点的前驱指针
}
if (next == null) { // 后继为空,表示删除的结点为尾结点
last = prev; // 重新赋值尾结点
} else { // 删除的结点不为尾结点
next.prev = prev; // 赋值后继结点的前驱
x.next = null; // 结点的后继为空,切断结点的后继指针
}
x.item = null; // 结点元素赋值为空
// 减少元素实际个数
size--;
// 结构性修改加1
modCount++;
// 返回结点的旧元素
return element;
}
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item; //获取删除节点的元素值(f是头结点)
final Node<E> next = f.next; //存储要删除节点指向的下一个节点地址
f.item = null;
f.next = null; // help GC //将要删除节点的指针以及值全部设置为null,等待 垃圾回收
first = next; //将头结点向下移动
if (next == null)
last = null; //如果要删除节点的下一个为null,则当前链表只有一个节点存在
else //如果不为null,则将前驱设置为null
next.prev = null;
size--;
modCount++;
return element;
}
说明:如果直接调无参的remove(),就会默认删除头节点,删除头节点非常简单,就是把头节点的值清空,next清空,然后把nextNode只为头节点,然后清空next的prev,最后size减1,如果是删除中间节点,调用remove(int index),首先判断Index对应的节点是否为头节点,即index是否为0,如果不是中间节点,就是x的prev指向x的next。
举个栗子


说明:当LinkedList集合在一边遍历一边进行remove操作时,且当集合元素个数大于2个时,则会发生如下错误:

小结:ArrayList和LinkedList有什么区别?
- ArrayList查询快是因为底层是由数组实现,通过下标定位数据快。写数据慢是因为复制数组耗时。LinkedList底层是双向链表,查询数据依次遍历慢。写数据只需修改指针引用。
- ArrayList和LinkedList都不是线程安全的,小并发量的情况下可以使用Vector,若并发量很多,且读多写少可以考虑使用CopyOnWriteArrayList。因为CopyOnWriteArrayList底层使用ReentrantLock锁,比使用synchronized关键字的Vector能更好的处理锁竞争的问题。
参考资料:【集合框架】JDK1.8源码分析之LinkedList(七)
LinkedList集合(JDK1.8)的更多相关文章
- Java 集合 JDK1.7的LinkedList
Java 集合 JDK1.7的LinkedList @author ixenos LinkedList LinkedList是List接口的双向链表实现,JDK1.7以前是双向循环链表,以后是双向非循 ...
- java基础30 List集合下的LinkedList集合
单例集合体系: ---------| collection 单例集合的根接口--------------| List 如果实现了list接口的集合类,具备的特点:有序,可重复 注:集合 ...
- Java 之 LinkedList 集合
一.LinkedList 概述 java.util.LinkedList 集合数据存储的结构是链表结构. 特点:增删快,查询慢 LinkedList 是一个双向链表,如下图 注意:该集合实现不是同步 ...
- Java—增强for循环与for循环的区别/泛型通配符/LinkedList集合
增强for循环 增强for循环是JDK1.5以后出来的一个高级for循环,专门用来遍历数组和集合的. 它的内部原理其实是个Iterator迭代器,所以在遍历的过程中,不能对集合中的元素进行增删操作. ...
- IT第二十一天 - Collections、ArrayList集合、LinkedList集合、Set集合、HashMap集合、集合的操作注意【修20130828】
NIIT第二十一天 上午 集合 1. 集合Collection存储数据的形式是单个存储的,而Map存储是按照键值对来存储的,键值对:即键+值同时存储的,类似align="center&quo ...
- LinkedList集合
LinkedList集合特点: 1,有序,允许重复(有序指与添加顺序一致) 2,有下标,可以通过下标获取元素,以及将元素插入指定位置 3,底层使用的数据结构是链表以及堆栈结构,线程不安全 4,链表内存 ...
- 用LinkedList集合演示栈和队列的操作
在数据结构中,栈和队列是两种重要的线性数据结构.它们的主要不同在于:栈中存储的元素,是先进后出:队列中存储的元素是先进先出.我们接下来通过LinkedList集合来演示栈和队列的操作. import ...
- HashMap,Hashset,ArrayList以及LinkedList集合的区别,以及各自的用法
基础内容 容器就是一种装其他各种对象的器皿.java.util包 容器:Set, List, Map ,数组.只有这四种容器. Collection(集合) 一个一个往里装,Map 一对一对往里装. ...
- 在C语言中模仿java的LinkedList集合的使用(不要错过哦)
在C语言中,多个数据的储存通常会用到数组.但是C语言的数组有个缺陷,就是固定长度,超过数组的最大长度就会溢出.怎样实现N个数储存起来而不被溢出呢. 学过java的都知道,java.util包里有一个L ...
随机推荐
- Managed C++ wtypes.h DATE 转化为 .net的 DateTime
http://stackoverflow.com/questions/570224/how-do-i-convert-from-mfcs-coledatetime-to-c-sharp-datetim ...
- [Swift]有用的Binary Heap Type类
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★➤微信公众号:山青咏芝(shanqingyongzhi)➤博客园地址:山青咏芝(https://www.cnblogs. ...
- python 合集set,交集,并集,差集,对称差集别搞混
有集合 x与y x = {1,2,3,4,5}y = {4,5,6,7,8} x和y的交集为 {4,5} x和y的对称差集{1, 2, 3, 6, 7, 8} x和y的并集{1, 2, 3, 4, 5 ...
- python 中site-packages 和 dist-packages的区别
dist-packages is a Debian-specific convention that is also present in its derivatives, like Ubuntu. ...
- Ubuntu 18.04 LTS 安装过程
电脑: acer 1. F12开启boot menu,如果没开启,F2进去开启 2. 早点插优盘,否则进入F12的时候检测不出来,选择U盘启动,先不安装试用,进入桌面后有安装文件再安装,想直接安应该也 ...
- hdu 2818 Building Block 种类并查集
在进行并的时候不能瞎jb并,比如(x, y)就必须把x并给y ,即fa[x] = y #include <iostream> #include <string> #includ ...
- iOS bounds vs frame
斯坦福iOS开发课程的白胡子大叔的PPT解释得淋漓尽致!
- websocket实现单聊
server# @File: ws from flask import Flask, request, render_template from geventwebsocket.handler imp ...
- excel之实验数据处理线性拟合
实验前准备:设计表格项,通过设计公式,从而输入原始数据后直接得到最终的结果数据,学习常用的VBA公式及处理:Cn-$B$4,其中的$B$4表示绝对单元格位置;SUM(Xm:Yn)求范围内的和. 针对实 ...
- python_面向对象(6)
第1章 递归函数 1.1 概述 1.2 练习 1.3 二分查找 第2章 面向对象•类 2.1 类的介绍 2.2 书写格式 2.3 类的属性 2.4 self介绍 2.5 类属性补充 2.6 调用查看静 ...