社区发现(Community Detection)算法
作者: peghoty
出处: http://blog.csdn.net/peghoty/article/details/9286905
社区发现(Community Detection)算法用来发现网络中的社区结构,也可以看做是一种聚类算法。
以下是我的一个 PPT 报告,分享给大家。




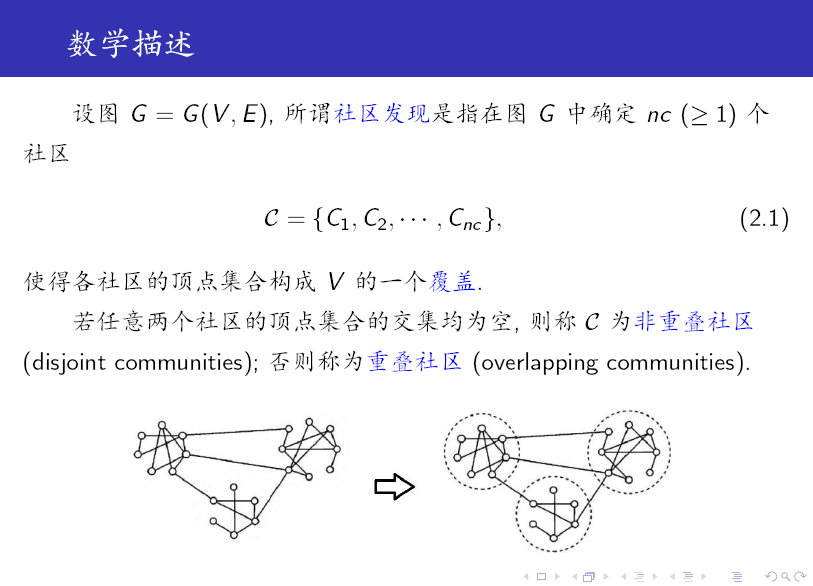
从上述定义可以看出:社区是一个比较含糊的概念,只给出了一个定性的刻画。
另外需要注意的是,社区是一个子图,包含顶点和边。
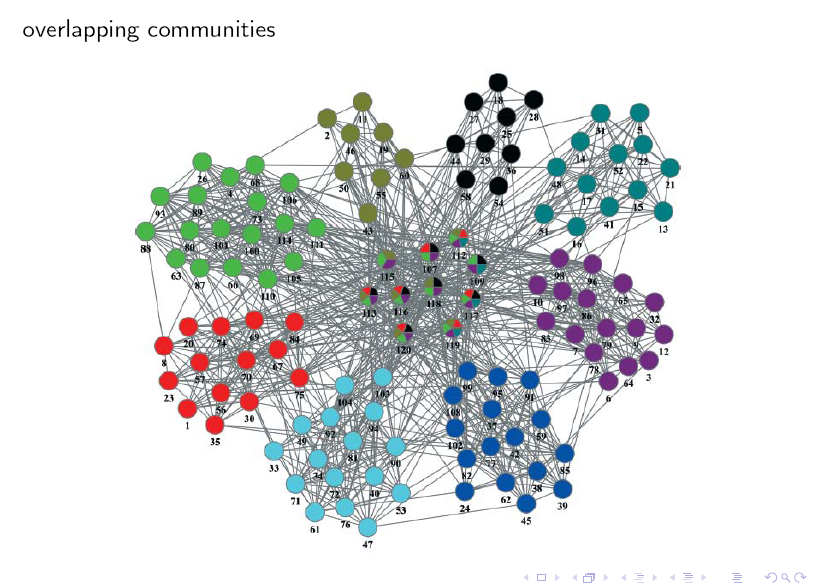
下面我们以新浪微博用户对应的网络图为例,来介绍相应的社区发现算法。

这里在相互关注的用户之间建立连接关系,主要是为了简化模型,此时对应的图为无向图。
当然,我们也可以采用单向关注来建边,此时将对应有向图。

这个定义看起来很拗口,但通过层层推导,可以得到如下 (4.2)的数学表达式。定义中的随机网络也称为Null Model,其构造方法为:
the null model used has so far been a random graph with the same number of nodes, the same number of edges and the same degree distribution as in the original graph, but with links among nodes randomly placed.

注意,(4.2) 是针对无向图的,因此这里的 m 表示无向边的条数,即若节点 i 和节点 j 有边相连,则节点 (i, j) 对 m 只贡献一条边。

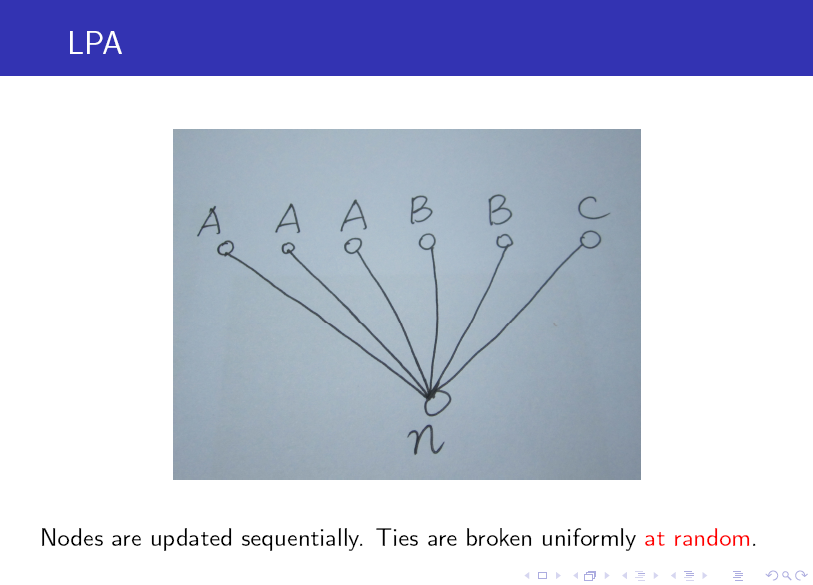
标签传播算法(LPA)的做法比较简单:
第一步: 为所有节点指定一个唯一的标签;
第二步: 逐轮刷新所有节点的标签,直到达到收敛要求为止。对于每一轮刷新,节点标签刷新的规则如下:
对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋给当前节点。当个数最多的标签不唯一时,随机选一个。
注:算法中的记号 N_n^k 表示节点 n 的邻居中标签为 k 的所有节点构成的集合。

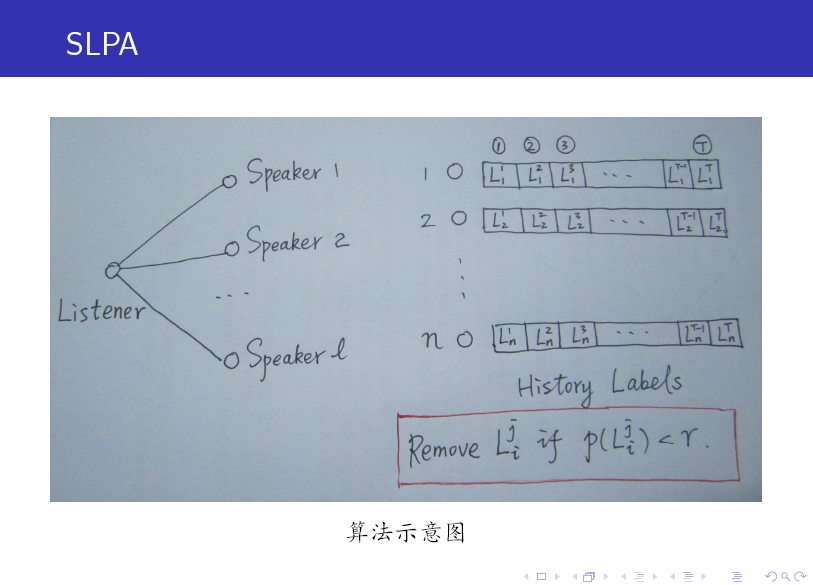
SLPA 中引入了 Listener 和 Speaker 两个比较形象的概念,你可以这么来理解:在刷新节点标签的过程中,任意选取一个节点作为 listener,则其所有邻居节点就是它的 speaker 了,speaker 通常不止一个,一大群 speaker 在七嘴八舌时,listener 到底该听谁的呢?这时我们就需要制定一个规则。
在 LPA 中,我们以出现次数最多的标签来做决断,其实这就是一种规则。只不过在 SLPA 框架里,规则的选取比较多罢了(可以由用户指定)。
当然,与 LPA 相比,SLPA 最大的特点在于:它会记录每一个节点在刷新迭代过程中的历史标签序列(例如迭代 T 次,则每个节点将保存一个长度为 T 的序列,如上图所示),当迭代停止后,对每一个节点历史标签序列中各(互异)标签出现的频率做统计,按照某一给定的阀值过滤掉那些出现频率小的标签,剩下的即为该节点的标签(通常有多个)。
SLPA 后来被作者改名为 GANXiS,且软件包仍在不断更新中......



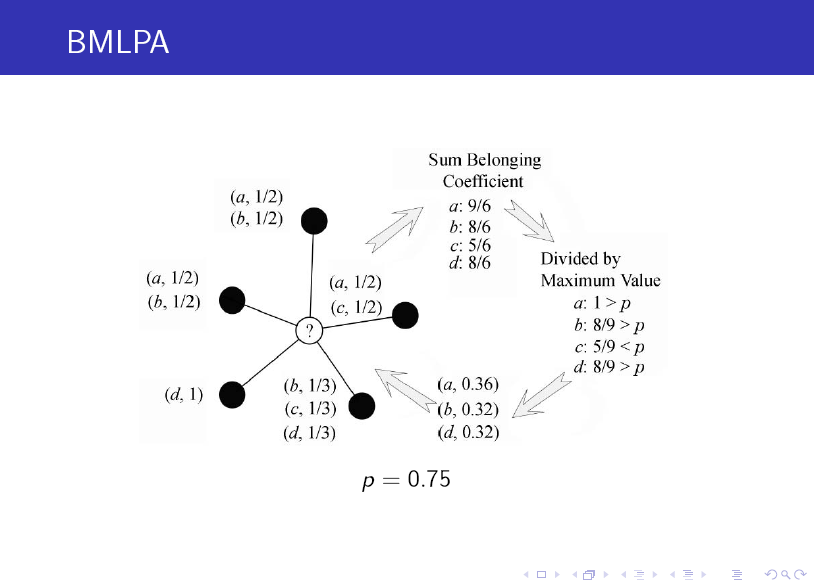
这里对上面的图做个简单介绍:带问号的节点是待确定标签的节点,黑色实心点为其邻居节点,它们的标签是已知的,注意标签均是由二元数对的序列构成的,序列中每一个元素的第一个分量表示其标签,第二个分量表示该节点属于该标签对应社区的可能性(或者说概率,叫做 belonging coefficent),因此对于每个节点,其概率之和等于 1。
我们按照以下步骤来确定带问号节点的标签:
1. 获取邻居节点中所有的互异(distinct) 标签列表,并累加相应的 belonging coefficent 值。
2. 对 belonging coefficent 值列表做归一化,即将列表中每个标签的 belonging coefficent 值除以 C1 (C1 为列表中 belonging coefficent 值的最大值)。
3. 过滤。若列表中归一化后的 belonging coefficent 值(已经介于 0,1 之间)小于某一阀值 p (事先指定的参数),则将对应的二元组从列表中删除。
4. 再一次做归一化。由于过滤后,剩余列表中的各 belonging coefficent 值之和不一定等于 1,因此,需要将每个 belonging coefficent 值除以 C2 (C2 表示各 belonging coefficent 值之和)。
经过上述四步,列表中的标签即确定为带问号节点的标签。

这里,我们对 Fast Unfolding 算法做一个简要介绍,它分为以下两个阶段:
第一个阶段:首先将每个节点指定到唯一的一个社区,然后按顺序将节点在这些社区间进行移动。怎么移动呢?以上图中的节点 i 为例,它有三个邻居节点 j1, j2, j3,我们分别尝试将节点 i 移动到 j1, j2, j3 所在的社区,并计算相应的 modularity 变化值,哪个变化值最大就将节点 i 移动到相应的社区中去(当然,这里我们要求最大的 modularity 变化值要为正,如果变化值均为负,则节点 i 保持不动)。按照这个方法反复迭代,直到网络中任何节点的移动都不能再改善总的 modularity 值为止。
第二个阶段:将第一个阶段得到的社区视为新的“节点”(一个社区对应一个),重新构造子图,两个新“节点”之间边的权值为相应两个社区之间各边的权值的总和。
我们将上述两个阶段合起来称为一个 pass,显然,这个 pass 可以继续下去。
从上述描述我们可以看出,这种算法包含了一种 hierarchy 结构,正如对一个学校的所有初中生进行聚合一样,首先我们可以将他们按照班级来聚合,进一步还可以在此基础上按照年级来聚合,两次聚合都可以看做是一个社区发现结果,就看你想要聚合到什么层次与程度。

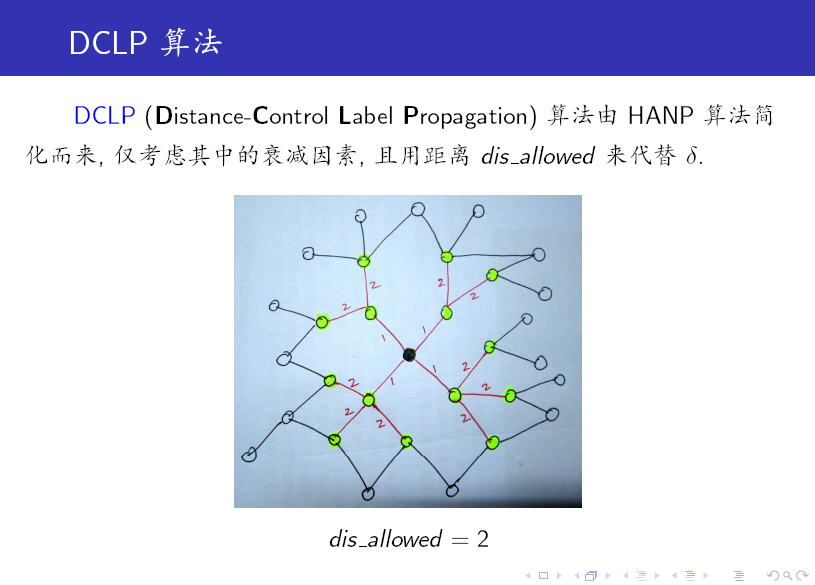
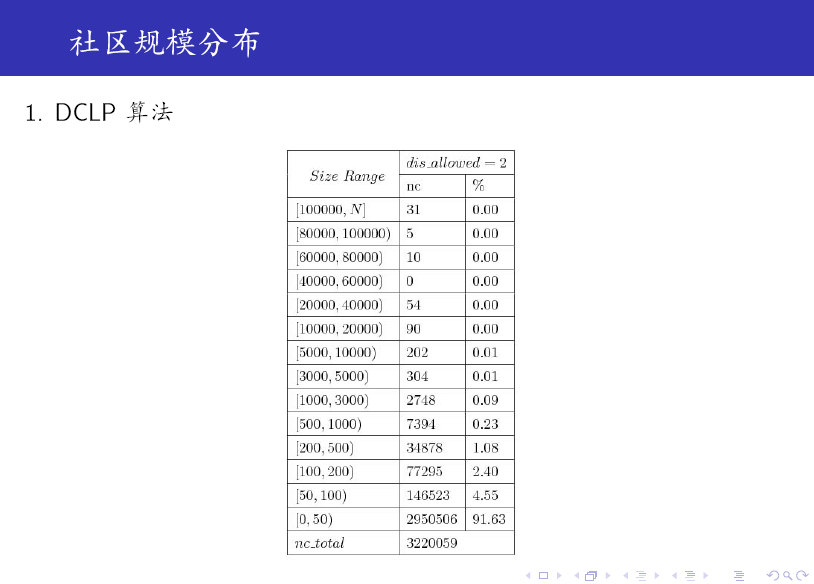
DCLP 算法是 LPA 的一个变种,它引入了一个参数来限制每一个标签的传播范围,这样可有效控制 Monster (非常大的 community,远大于其他 community)的产生。




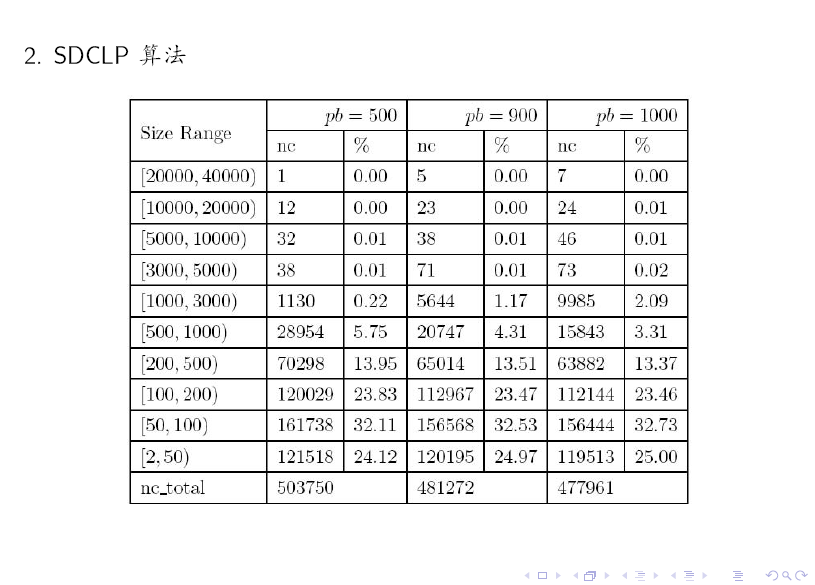
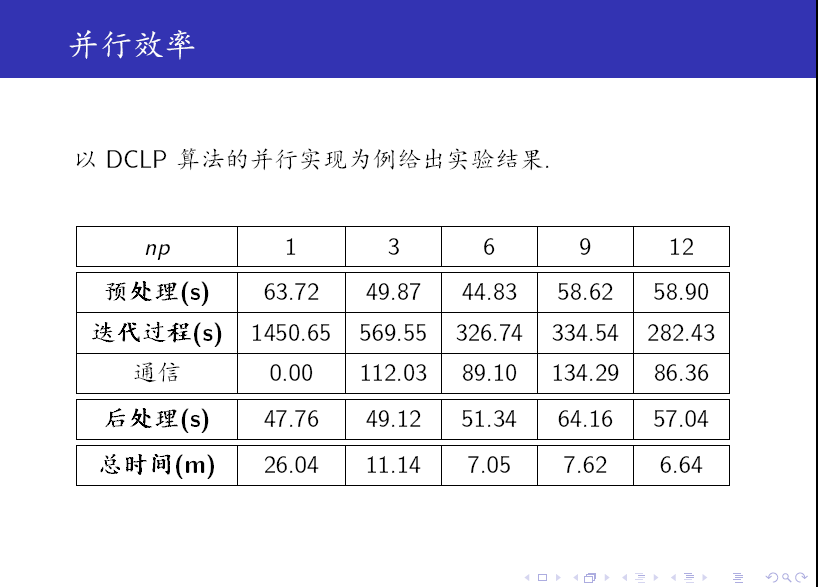
最后,我们给出一些实验结果。

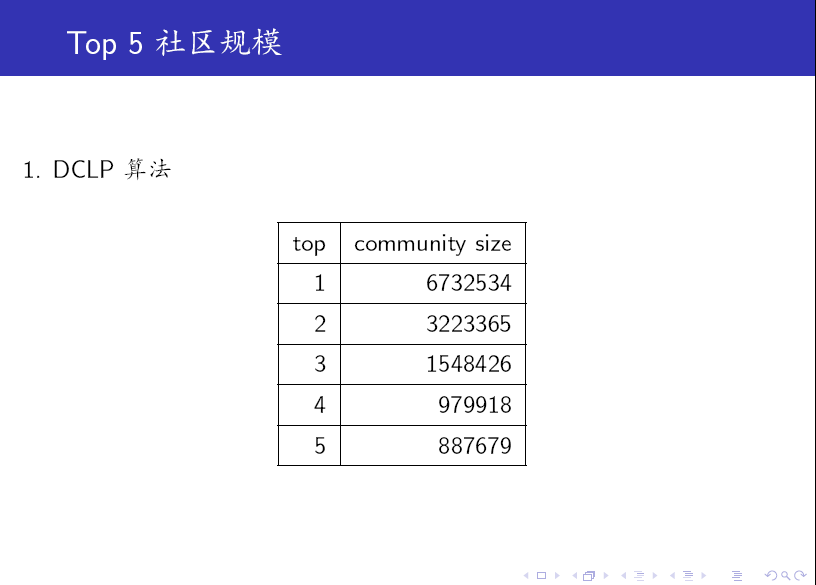
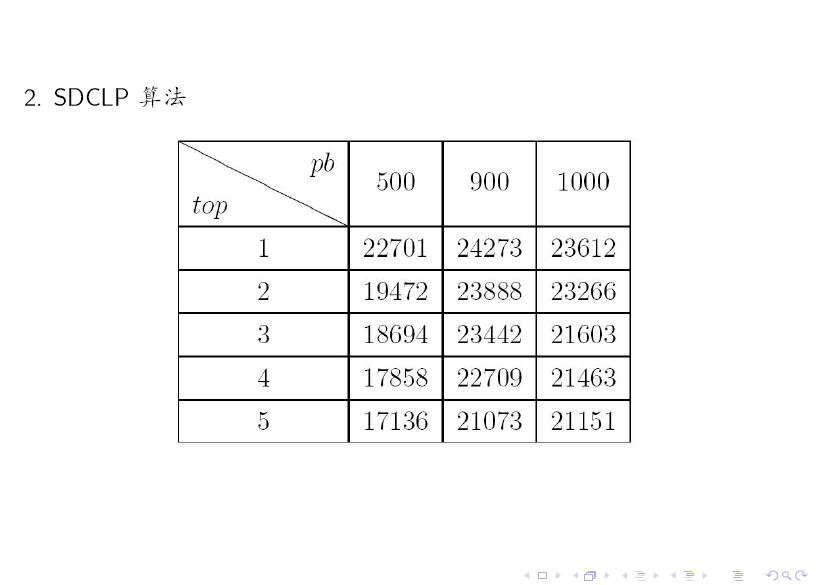
对比上述两个表格可知:SDCLP 算法得到的 top 5 社区更为均匀。

社区发现(Community Detection)算法的更多相关文章
- 社区发现(Community Detection)算法 [转]
作者: peghoty 出处: http://blog.csdn.net/peghoty/article/details/9286905 社区发现(Community Detection)算法用来发现 ...
- 社区发现(Community Detection)算法(转)
作者: peghoty 出处: http://blog.csdn.net/peghoty/article/details/9286905 社区发现(Community Detection)算法用来发现 ...
- 网络科学 - 社区发现 Community structure and detection及其几个实现工具
首先什么是社区(Community structure)呢?其实并不是指一个网络相互连接的部分,而是一个网络中链接“紧密的部分”,至于怎么定义紧密就有很多方法了. 社区发现算法可以参考下面的博客:博客 ...
- Top Leaders社区发现算法(top leaders community detection approach in information networks)
一.概念 复杂网络:现实生活中各种系统都可以看做成复杂网络,复杂网络构成包括节点和边,节点是网络中的基本组成单元,节点之间的联系或者关系是网络中的边.例如 电力网络:基站代表节点,基站之间是否互通表示 ...
- LabelRank非重叠社区发现算法介绍及代码实现(A Stabilized Label Propagation Algorithm for Community Detection in Networks)
最近在研究基于标签传播的社区分类,LabelRank算法基于标签传播和马尔科夫随机游走思路上改装的算法,引用率较高,打算将代码实现,便于加深理解. 这个算法和Label Propagation 算法不 ...
- 社区发现算法 - Fast Unfolding(Louvian)算法初探
1. 社团划分 0x1:社区是什么 在社交网络中,用户相当于每一个点,用户之间通过互相的关注关系构成了整个网络的结构. 在这样的网络中,有的用户之间的连接较为紧密,有的用户之间的连接关系较为稀疏.其中 ...
- GNN 相关资料记录;GCN 与 graph embedding 相关调研;社区发现算法相关;异构信息网络相关;
最近做了一些和gnn相关的工作,经常听到GCN 和 embedding 相关技术,感觉很是困惑,所以写下此博客,对相关知识进行索引和记录: 参考链接: https://www.toutiao.com/ ...
- 模块度与Louvain社区发现算法
Louvain算法是基于模块度的社区发现算法,该算法在效率和效果上都表现较好,并且能够发现层次性的社区结构,其优化目标是最大化整个社区网络的模块度. 模块度(Modularity) 模块度是评估一个社 ...
- 社区发现算法问题&&NetworkX&&Gephi
在做东西的时候用到了社区发现,因此了解了一下有关社区发现的一些问题 1,社区发现算法 (1)SCAN:一种基于密度的社团发现算法 Paper: <SCAN: A Structural Clust ...
随机推荐
- 在行列都排好序的矩阵中找数 【题目】 给定一个有N*M的整型矩阵matrix和一个整数K, matrix的每一行和每一 列都是排好序的。实现一个函数,判断K 是否在matrix中。 例如: 0 1 2 5 2 3 4 7 4 4 4 8 5 7 7 9 如果K为7,返回true;如果K为6,返 回false。 【要求】 时间复杂度为O(N+M),额外空间复杂度为O(1)。
从对角考虑 package my_basic.class_3; /** * 从对角开始 */ public class Code_09_FindNumInSortedMatrix { public s ...
- OpenCV2:直方图
一.简介 在一个单通道的灰度图像中,每个像素的值介于0(黑色)~255(白色)之间,灰色图像的直方图有256个条目(或称为容器)
- 洛谷 P2370 P2370 yyy2015c01的U盘
https://www.luogu.org/problemnew/show/P2370 二分+背包 #include <algorithm> #include <iostream&g ...
- windows下pycharm使用Anaconda安装包环境
转自: https://www.cnblogs.com/heitaoq/p/8632315.html
- hihoCode-1043-完全背包
我们定义:best(i,x)代表i件以前的物品已经决定好选择多少件,并且在剩余奖券x的情况下的最优解. 我们可以考虑最后一步,是否再次选择i物品,在不超过持有奖券总额的情况下.上面的第二个式子的k是大 ...
- 八:SQL之DQL数据查询语言单表操作
前言: DQL数据库查询语言是我们在开发中最常使用的SQL,这一章总结了单表操作部分的常用查询方式 主要操作有:查询所有字段.查询指定字段.查询指定记录.带IN的关键字查询,范围查询,陪查询.查询空值 ...
- Spring,Mybatis,Springmvc框架整合项目(第三部分)
一.静态资源不拦截 第二部分最后显示的几个页面其实都加载了css和js等文件,要不然不会显示的那么好看(假装好看吧),前面已经说了,我们在web.xml中配置了url的拦截形式是/,那么Dispatc ...
- PAT Basic 1014
1014 福尔摩斯的约会 大侦探福尔摩斯接到一张奇怪的字条:“我们约会吧! 3485djDkxh4hhGE 2984akDfkkkkggEdsb s&hgsfdk d&Hyscvnm” ...
- [LoadRunner]LR性能测试结果样例分析
R性能测试结果样例分析 测试结果分析 LoadRunner性能测试结果分析是个复杂的过程,通常可以从结果摘要.并发数.平均事务响应时间.每秒点击数.业务成功率.系统资源.网页细分图.Web服务器资源. ...
- Laya 屏幕适配
Laya 屏幕适配 @author ixenos 2019-03-20 21:44:52 1.最简单的方案:原比例,对照屏幕尺寸的最小比率缩放,有黑边 Laya.stage.scaleMode = S ...