此文是我之前的笔记整理而来,以索引为入口进行探讨相关数据库知识(又做了修改以让人更好消化)。SQL Server接触不久的朋友可以只看以下蓝色字体字,简单有用节省时间;如果是数据库基础不错的朋友,可以全看,欢迎探讨。
全文章节:
1.聚集索引和非聚集索引
2.索引的结构
3.索引包含列和书签查找
1.聚集索引和非聚集索引
索引分为聚集索引和非聚集索引
1.1 聚集索引
表的数据是存储在数据页中(数据页的PageType标记为1),SqlServer一页是8k,存满一页就开辟下一页存储。如果表有聚集索引,那么一笔一笔物理数据就是按聚集索引字段的大小升/降排序存储在页中。当对聚集索引字段更新或中间插入/删除数据时,都会导致表数据移动(造成性能一定影响),因为它要保持升/降排序。
注意,主键只是默认是聚集索引,它也可以设置为非聚集索引,也可以在非主键字段上设置为聚集索引,全表只能有一个聚集索引。
一个优秀的聚集索引字段一般包含以下4个特性:
(A).自增长
总是在末尾增加记录,减少分页和索引碎片。
(B).不被更改
减少数据移动。
(C).唯一性
唯一性是任何索引最理想的特性,可以明确索引键值在排序中的位置。
更重要的是,索引键指唯一的话,它在每条记录里才可以正确指向源数据行RID。如果聚集索引键值不唯一,SqlServer就需要内部生成uniquifier 列组合当作聚集键保证“键值”唯一性;如果非聚集索引键值不唯一,就会增加RID列(聚集索引键或者堆表中的行指针)保证“键值”唯一性。
思考(可略过):索引“键值”在非叶子节点也有保证唯一性,原因应该是为了明确索引记录在非叶子节点中的位置。比如有个非聚集索引字段Name2,表中有很多Name2='a'的记录,导致Name2='a'在非叶子节点上有多条索引记录(节点),这时候再insert一笔Name2=‘a'的记录时,就可以根据非叶子节点的RID和新增记录的RID很快确定要insert到哪个索引记录(节点)上,如果没有非叶子节点的RID,那得遍历到所有Name2='a'的叶子节点才能确定位置。另外,当我们select * from Table1 where Name2<='a'时,返回的数据是按非聚集索引Name2和RID排序的,很好理解返回的数据就是按这边索引存储的顺序排序的。这是这条sql查询时有用到Name2索引的结果,如果数据库查询计划因“临界点”问题选择直接表数据扫描,那返回的数据默认就是按表数据的顺序排序的。
为了“键值”唯一性,对于聚集索引,uniquifier 列只在索引值重复时增加。对于非聚集索引,如果创建索引时没定义唯一,RID会在所有记录增加,就算索引值是唯一的;如果创建索引时定义唯一,RID只在叶子层增加,用于查找源数据行,即书签查找操作。
(D).字段长度小
聚集索引键长度越小,一页索引页就可以容纳更多索引记录,进而减少索引B树结构的深度。例如,一个百万记录的表有一个int聚集索引,可能只需要3层的B树结构。如果把聚集索引定义在更宽的列(比如uniqueidentifier列需要16 字节),那么索引的深度会增加到4层。任何聚集索引查找需要4个I/O操作(确切的说是4个逻辑读),原先只要3个I/O操作。
同样,非聚集索引里会包含聚集索引键值,聚集索引键长度越小非聚集索引记录也就越小,一页索引页就可以容纳更多索引记录。
1.2 非聚集索引
也是存储在页中(PageType标记为2的页,叫索引页)。比如表T建立了一个非聚集索引Index_A,那么表T有100条数据的话,那么索引Index_A也就有100条数据(准确的说是100条叶子节点数据,索引是B树结构,如果树的高度大于0,那么就有根节点页或中间节点页数据,这时索引数据就超过100条),如果表T还有非聚集索引Index_B,那么Index_B也是至少100条数据,所以索引建越多开销越大。
更新索引字段、插入一条数据、删除一条数据都会造成索引的维护从而造成性能的一定影响。在不同情况下,性能影响是不同的。比如当你有一个聚集索引,插入的数据又都是在末尾,这样几乎是不会造成数据移动,影响较小;如果插入的数据在中间位置,一般会导致数据移动,而且可能产生分页和页碎片,影响就会稍大一点(如果插入到的中间页有足够的剩余空间容纳插入的数据,而且位置是在页末,也是不会造成数据移动)
2.索引的结构
都说SqlServer的索引是B树结构(这边假定你对B树结构有一定了解),那它到底长什么个模样呢,可以用Sql语句来查看它的逻辑呈现。
新建查询执行语法: DBCC IND(Test,OrderBo,-1) --其中Test库的OrderBo表有1万笔数据,有聚集索引Id主键字段
(不妨自己动手建个表,有聚集索引字段,插入1万表数据,然后执行这个语法看看,会收获很多,百闻不如一见)
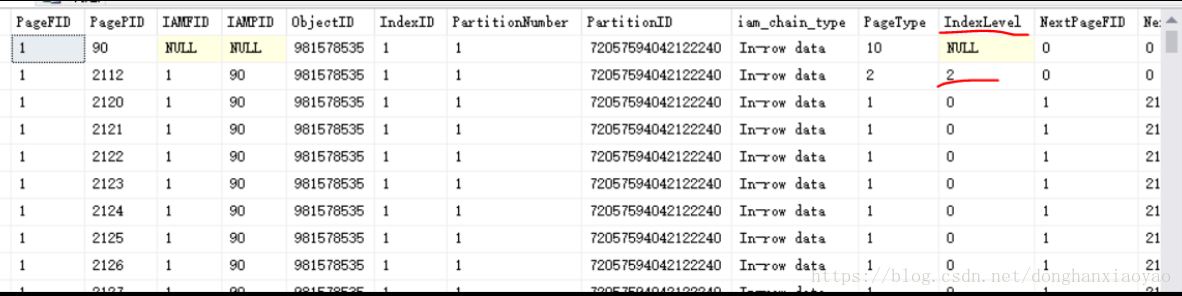
执行结果:
如上图,看到一个IndexLevel=2的索引页2112(这边它就是B树的根节点,IndexLevel最大的就是根节点,往下就是子级、子子级...只有一个根页作为B树结构的访问入口点),说明一定还有IndexLevel=1的索引页和IndexLevel=0的叶子页。由于这边是聚集索引,因此当IndexLevel=0的叶子页就是数据页,存储的是一笔一笔的物理数据。如上图也可以看到,IndexLevel=0的行的PageType等于1,就是代表数据页,上面1.1章节讲到聚集索引时,也有提到PageType=1;而如果是非聚集索引,IndexLevel=0的叶子页,PageType是等于 2,仍然是索引页。
同样,我们用Sql命令DBCC PAGE看一看
-- DBCC TRACEON(3604,-1)
DBCC PAGE(Test,1,2112,3)
--根节点2112,可以查出它的两个子节点2280和2448,然后对这两个子节点再作DBCC PAGE查询
DBCC PAGE(Test,1,2280,3)
DBCC PAGE(Test,1,2448,3)
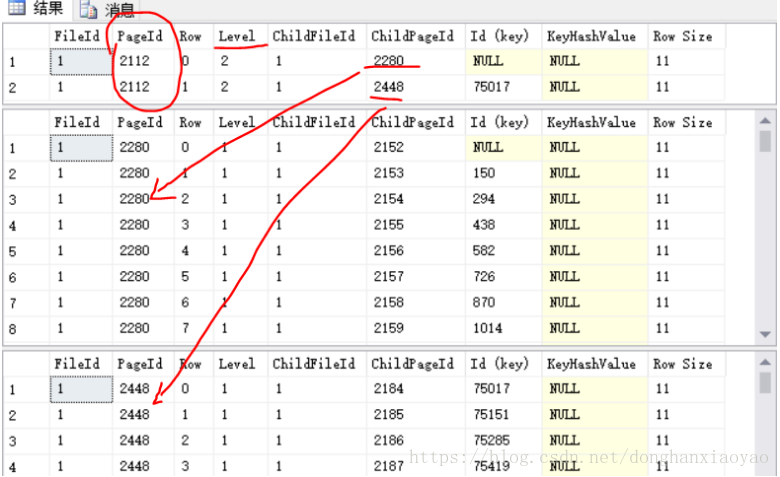
如上图,IndexLevel=2的2112页有两个IndexLevel=1的子节点2280和2448,子节点下又有子节点,每个节点负责不同的索引键值的区间(即上图的“Id(key)”栏位,第一行值是Null,表示最小值或倒序时的最大值)。这样的层级关系是不是就是一棵B树结构,其中IndexLevel其实就是B树结构中的高度Height。
SqlServer在索引中查找某一笔记录时,是从根节点往下找到叶子节点,因为所有数据地址都有存在叶子节点,这其实是B+树的特点之一(B树特点是如果查找的值在非叶子节点就找到,则就能直接返回,显然SqlServer不是这么做,要验证这一点你可以set statistics io on把统计开起来,然后select看下逻辑读的次数)。
既然一定会找到叶子节点,那么索引包含列只要在叶子节点记录就可以了,即非叶子节点没有记录包含列,“索引包含列”见下文第3章节。
B+树这个特点(所有数据地址都有存在叶子节点)也利于between value1 and value2 区间查询,只要找到value1和value2(在叶子节点),然后把中间串起来就是要的结果了。
SqlServer索引结构更像是B+树,最终是B树和B+树的混合版,数据结构都是人定的,不一定就是纯粹的B树或者单纯的B+树。
3.索引包含列和书签查找
谈到索引,这边再讲一个SqlServer2005开始增加的“索引包含列”功能,很实用。
比如,在大报表查询数据时,where条件用到索引字段Name2,但是要select的字段是Name1,这时候可以使用“索引包含列”把Name1包含在索引字段Name2中,大大提高查询性能。
语法: Create [UNIQUE] Nonclustered/Clustered Index IndexName On dbo.Table1(Name2) Include(Name1);
接下来分析为什么索引包含列可以大大提高性能。仍然使用DBCC PAGE命令,查看一个非聚集索引并有包含列的索引数据情况:

由上图可知,包含列Name1也存储在索引数据中。因此,当数据库用索引字段Name2定位到要查找的某一行时,就可以直接把Name1的值返回了,而不用再根据RID(上图是【HEAP RID(Key)】列)定位到数据页中去取值,即减少了书签查找。当查询只返回一条数据,只有一次书签查找时当然没什么,如果查询返回的数据很大,每一笔都要去数据页找数据取出来,1000笔就是1000次书签查找,可想而知性能消耗很大,这时候“索引包含列”价值就大大体现出来了。
关于一次书签查找,表有聚集索引(比如Id)时就是类似执行了一次 select Name1 from Table1 where Id=1 ,利用聚集索引键Id查找(查找方式就是索引Id的B树结构查找),而如果表没有聚集索引,则是根据数据行指针(由“文件号2byte:页号4byte:槽号2byte”组成)查找。聚集索引键和行指针一般统称为RID(Row ID)指针。从这里我们可以想到,如果你的表没有很好的聚集索引字段,建议自增长的Id字段做聚集索引主键(冗余出Id字段也行),它符合自增长、不被更改、唯一性、长度小的特性,是聚集索引的很好选择。
自增长Id绝大部分情况下是适用的,特殊的情况看具体需求而定吧。还有自增长Id要考虑一个缺陷,当对表大数据量的并发insert记录时,可以想象每个线程都是要insert到末尾那个页,就会发生竞争和等待。解决这种情况你可以用uniqueidentifier类型字段(16字节,我是不建议使用)或者哈希分区(就是一个表分成多个表,大数据处理中分库分表是正常的)等。但是我建议先优化你的insert效率(insert性能本身是很快的),测试每秒并发insert数是否满足生产环境,以保留简单稳定高效的自增长Id作法。
自增长Id不一定就是用数据库提供的自增长,你也可以自己写算法生成一个并发情况下也能唯一的Id(这时候一般长度是bitint,8字节整形),这种情况适合场景是分布式数据库中主从复制时Id栏位是要求一定不能出错的情况(主从复制的一般模式下,主库的Id是按主库增长,从库Id也是按从库自己的增长,如果遇到死锁等原因导致主从复制不同步时,那从库的Id就和主库的Id自增长就对不上号了)。如果自增长Id是冗余出的主键,那主从库Id对不上号也就无影响。
另外,上图最后一列【Row Size】还告诉我们,索引列或索引包含列的size不要太长,否则一页容不了几笔记录,这样大大增加了索引页数量,而且索引数据所占的空间也大大增加了。
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- SQL Server 内存数据库原理解析
前言 关系型数据库发展至今,细节上以做足文章,在寻求自身突破发展的过程中,内存与分布式数据库是当下最流行的主题,这与性能及扩展性在大数据时代的需求交相辉映.SQL Server作为传统的数据库也在最新 ...
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆
http://www.cnblogs.com/kissdodog/archive/2013/06/12/3132380.html
- SQL Server 索引碎片产生原理重建索引和重新组织索引
数据库存储本身是无序的,建立了聚集索引,会按照聚集索引物理顺序存入硬盘.既键值的逻辑顺序决定了表中相应行的物理顺序 多数情况下,数据库读取频率远高于写入频率,索引的存在 为了读取速度牺牲写入速度 页 ...
- [转帖]SQL Server 索引中include的魅力(具有包含性列的索引)
SQL Server 索引中include的魅力(具有包含性列的索引) http://www.cnblogs.com/gaizai/archive/2010/01/11/1644358.html 上个 ...
- SQL Server 索引中include
SQL Server 索引中include的魅力(具有包含性列的索引) http://www.cnblogs.com/gaizai/archive/2010/01/11/1644358.html 开文 ...
- sql server 索引总结一
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- SQL Server 数据加密功能解析
SQL Server 数据加密功能解析 转载自: 腾云阁 https://www.qcloud.com/community/article/194 数据加密是数据库被破解.物理介质被盗.备份被窃取的最 ...
- 【译】SQL Server索引进阶第八篇:唯一索引
原文:[译]SQL Server索引进阶第八篇:唯一索引 索引设计是数据库设计中比较重要的一个环节,对数据库的性能其中至关重要的作用,但是索引的设计却又不是那么容易的事情,性能也不是那么轻易就 ...
随机推荐
- 洛谷 P3146 248 题解
https://www.luogu.org/problemnew/show/P3146 区间dp,这次设计的状态和一般的有一定的差异. 这次我们定义$dp[i][j]$表示$[i,j]$的可以合并出来 ...
- 使用dockerfile构建nginx镜像
使用dockerfile构建nginx镜像 docker构建镜像的方法: commit.dockerfile 1.使用commit来构建镜像: commit是基于原有镜像基础上构建的镜像,使用此方 ...
- Linux中的FTP服务
FTP服务 文件传输协议 FTPFile Transfer Protocol 早期的三个应用级协议之一 基于C/S结构 双通道协议:数据和命令连接 数据传输格式:二进制(默认)和文本 两种模式:服务器 ...
- POJ 1949 Chores(DAG上的最长路 , DP)
题意: 给定n项任务, 每项任务的完成用时t和完成每项任务前需要的k项任务, 求把所有任务完成的最短时间,有当前时间多项任务都可完成, 那么可以同时进行. 分析: 这题关键就是每项任务都会有先决条件, ...
- SQLServer__问题记录
“备份集中的数据库备份与现有的xx数据库不同” 参考链接: http://www.cnblogs.com/huangfr/archive/2012/08/09/2629687.html RESTOR ...
- 洛谷P2527 [SHOI2001]Panda的烦恼
题目描述 panda是个数学怪人,他非常喜欢研究跟别人相反的事情.最近他正在研究筛法,众所周知,对一个范围内的整数,经过筛法处理以后,剩下的全部都是质数,不过panda对这些不感兴趣,他只对被筛掉 ...
- 【并查集】F.find the most comfortable road
https://www.bnuoj.com/v3/contest_show.php?cid=9146#problem/F [题意] 给定n个城市和m条带权边,q次查询,问某两个城市之间的所有路径中最大 ...
- Codevs 3409 搬礼物
时间限制: 1 s 空间限制: 64000 KB 题目等级 : 青铜 Bronze 题目描述 Description 小浣熊松松特别喜欢交朋友,今年松松生日,就有N个朋友给他送礼物.可是要把这些礼 ...
- WordPress 权限方案
每个主机和主机的情况可能有所差异,如下只是概括性地描述,并不一定适用于所有情况.它只适用于进行“常规设置”的情况(注:比如通过“suexec”方式来进行共享主机的,详情见下方) 通常,所有文件是由您的 ...
- HDU 4738 割边
Caocao's Bridges Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...