ElasticSearch搜索服务技术
ElasticSearch
基于的lucene开发的搜索服务技术;天生支持分布式;
Es的结构
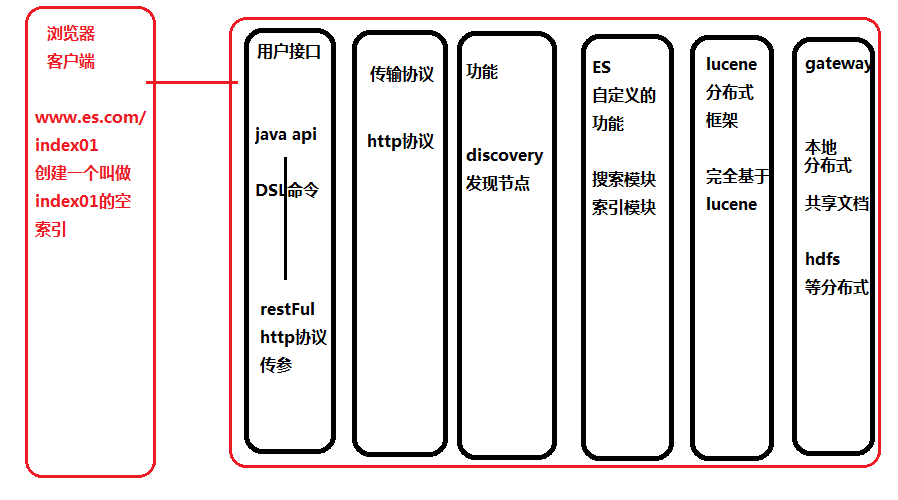
- gatway:存储层,所有的数据可以存储在本地(多个es节点形成分布式存储),hdfs输出位置,共享文件等
- 分布式lucene框架:把lucene缺少的分布式支持,做成一个基于lucene的框架
- ES自定义功能:ES自己的功能实现,例如关闭,打开索引,设置索引的读写权限等
- 功能插件:实现集群的管理,形成各种自定义插件,discovery自动发现功能
- 传输协议:支持http协议,支持thrift(AVRO)
- 用户接口: java api DSL操作命令基于http协议,发起的restFul传参操作ES
ElasticSearch存储应用概念
索引index:lucene中提到的索引文件,这个整体看来类似数据库中的某个库
类型Type: 在一个索引中,可以有不同结构的document存在,一批一批的相似结构,把同一批结构相同的document定义为一个类型(field结构相同);类似于数据库的表格
映射mapping: 不同类型中的各种field的属性(String int,分词计算器指定谁,长度,特性等等),都可以在mapping映射中体现;类似数据库的schema(结构)
文档document:搜索的数据基本单位,一个数据整体,document.类似数据库中一行数据记录row,类似java中的一个pojo对象
域属性field:类似于数据库中的一个列column
ELK家族:es衍生了一系列的开源软件,统称 Elastic Stack,包括分布式搜索引擎es,日志采集logstash,可视化平台分析kibana
ES的安装
https://www.cnblogs.com/nanlinghan/p/10084639.html
ES的配置
https://www.cnblogs.com/nanlinghan/p/10084647.html
java API 连接操作ES
代码没有实现连接集群名称不是ealasticsearch的settings
1 依赖pom的jar包,与lucene测试分开有冲突
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.5.2</version>
</dependency>
2 测试案例
• 连接es
创建一个连接对象TransportClient
3 操作步骤
• 索引的操作
新增
删除
• 文档的操作
新建文档
curl 命令传递的是请求体中的json字符串,es解析json创建不同结构不同类型的document对象,代码中把对象转化的json字符串,添加的请求体中,完成document的创建
{"id":10,
"name":"**",
"age":18
}
jackson 将pojo对象;easymall中的逻辑 es层,就是将数据库数据获取(持久层封装的就是pojo类对象),存入到es中需要转化成json
添加jackson-bind的依赖
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.8</version>
</dependency>
创建一个对象pojo
User对象
Integer id
String name;
Integer age
package com.jt.es.test; import java.io.IOException;
import java.net.InetAddress; import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.admin.indices.mapping.put.PutMappingRequest;
import org.elasticsearch.action.get.GetRequestBuilder;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.IndicesAdminClient;
import org.elasticsearch.client.Requests;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.Operator;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Before;
import org.junit.Test; import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.jt.es.pojo.User; public class ESTest {
private TransportClient client;
//测试连接对象
@Before
public void initial() throws Exception{
//自定义Settings
//默认的empty中有一个就是集群名称 elasticsearch
client=
new PreBuiltTransportClient(Settings.EMPTY);
//传递ip和端口 9300,client可以调用多次add方法将集群其他可连接的
//节点同时传递
client.addTransportAddress(
new InetSocketTransportAddress(
InetAddress.getByName("10.9.100.26"),9300));
}
//创建索引
@Test
public void createIndex(){
//利用连接客户端client,获取索引的管理对象indexAdminClient
IndicesAdminClient indexClient = client.admin().indices();
CreateIndexResponse cResponse = indexClient.prepareCreate("index05").get();
//返回json {"acknowledged":true,"shards_acknowledged":true}
System.out.println(cResponse.isAcknowledged());
System.out.println(cResponse.isShardsAcked());
}
//删除
@Test
public void deleteIndex(){
//利用连接客户端client,获取索引的管理对象indexAdminClient
IndicesAdminClient indexClient = client.admin().indices();
indexClient.prepareDelete("index05").get();//
} //新建文档
@Test
public void createDoc() throws Exception{
//准备json字符串
User user=new User();
user.setId(1);
user.setName("王首富");
user.setAge(18);
ObjectMapper mapper=new ObjectMapper();
String userJson=mapper.writeValueAsString(user);
//连接对象创建 index05,user类型,1的document
IndexResponse response = client.prepareIndex("index05", "user","1").
setSource(userJson).execute().actionGet();
System.out.println(response.toString());
} //获取document
@Test
public void getDoc(){
GetRequestBuilder response = client.prepareGet("index05", "user", "1");
System.out.println(response.get().getSourceAsString()); } //matchquery
@Test
public void query(){
//封装查询对象query
MatchQueryBuilder query = QueryBuilders.matchQuery("title", "java编程思想hadoop")
.operator(Operator.OR);//查询结果必须包含条件中的所有分词
//客户端调用查询对象获取查询结果
// page rows
int page=1;
int rows=5;
int start= (page-1)*rows;
SearchResponse response = client.prepareSearch("book").
setQuery(query).setFrom(start).setSize(rows).get();
//获取响应结果中的数据,hits中
SearchHits hits = response.getHits();
System.out.println("共搜索到:"+hits.totalHits);
for (SearchHit hit : hits) {
//获取响应结果中的source
System.out.println("title:"+hit.getSource().get("title"));
System.out.println("content:"+hit.getSource().get("content"));
}
}
}
ES集群
集群分布式和高可用在ES中都是默认配置和计算
• 集群的分布式,es的所有数据默认5个分片,每个分片默认一个副本(总共每个分片有2分,一份值主分片,一份是从分片)
• 集群配置完成后,启动所有集群节点,分片和副本的数据将会自动计算分配到不同的节点存储,只有从少到多的移动,没有从多到少的移动
• 分片默认5片,副本默认1片,自动根据集群节点数量最优的分配,分片越多,节点越多,副本越多的时候,整个集群的分布式性能越高,高可用能力越高
ElasticSearch搜索服务技术的更多相关文章
- 基于Elasticsearch搜索平台设计
背景 随着公司业务的高速发展以及数据爆炸式的增长,当前公司各产线都有关于搜索方面的需求,但是以前的搜索服务系统由于架构与业务上的设计,不能很好的满足各个业务线的期望,主要体现下面三个问题: 不能支持对 ...
- 从零搭建ES搜索服务(一)基本概念及环境搭建
一.前言 本系列文章最终目标是为了快速搭建一个简易可用的搜索服务.方案并不一定是最优,但实现难度较低. 二.背景 近期公司在重构老系统,需求是要求知识库支持全文检索. 我们知道普通的数据库 like ...
- 手动从零使用ELK构建一套搜索服务
前言 这两天需要对接一个新的搜索业务,由于测试机器还没到位,所以就自己创造条件,通过在Windows上安装VM虚拟机,模拟整套环境,从而能快速进入核心业务的开发测试状态中. 系统环境安装配置 虚拟机V ...
- 【阿里云产品公测】高大上的搜索服务OpenSearch,你值得拥有!
[阿里云产品公测]高大上的搜索服务OpenSearch,你值得拥有! 作者:阿里云用户trcher 一.前言: 在OpenSearch没出来之前,就一直想给网站做个搜索功能,虽然网站本身自带搜索功 ...
- 开放搜索服务OpenSearch
开放搜索服务系统架构:从系统.平台到开放服务 搜索是各类网站和数据类APP的标配功能.目前开发者一般基于开源搜索系统,例如ElasticSearch.Solr.Sphinx等自己搭建搜索服务,系统定制 ...
- 从零搭建 ES 搜索服务(二)基础搜索
一.前言 上篇介绍了 ES 的基本概念及环境搭建,本篇将结合实际需求介绍整个实现过程及核心代码. 二.安装 ES ik 分析器插件 2.1 ik 分析器简介 GitHub 地址:https://git ...
- 踏得网互联网新技术垂直搜索服务和分享 - HTML5动效/特效/动画搜索
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/iefreer/article/details/34917729 当前主流搜索引擎在解决互联网技术创意 ...
- 百度谷歌雅虎三大搜索引擎比较和如何配置谷歌访问助手访问Google搜索服务
引言: 由于近期网上盛传”百度搜索引擎已死“的消息,引发个人对于搜索引擎的思考.百度作为最大的中文搜索引擎,确实有着很大声誉,再加上本地化的优势,正成为国人们的首选,但是作为一名技术开发人员,使用搜索 ...
- 搭建spring boot+elasticsearch+activemq服务
目前时间是:2017-01-24 本文不涉及activemq的安装 需求 activemq实时传递数据至服务 elasticsearch做索引 对外开放查询接口 完成全文检索 环境 jdk:1.8 s ...
随机推荐
- JBPM学习第6篇:通过Git导入项目
1.登记到工作台 切换到目录: $SERVER_HOME/bin/ for Unix environment: ./standalone.shfor Windows environment: ./st ...
- git基本命令集合
以下内容不适合初学者 括号中表示需要自己填写 v1.0 git add git commit -m git commit -a -m git commit -amend git clone git l ...
- 第8章 CSS3中的变形与动画(上)
变形--旋转 rotate() 旋转rotate()函数通过指定的角度参数使元素相对原点进行旋转.它主要在二维空间内进行操作,设置一个角度值,用来指定旋转的幅度.如果这个值为正值,元素相对原点中心顺时 ...
- Bzoj1835:[ZJOI2010]基站选址
Sol 设\(f[i][j]\)表示钦定\(i\)建基站,建了\(j\)个基站的最小代价 \(f[i][j]=max(f[l][j-1]+\Sigma_{t=l+1}^{i-1}\)不能影响到的村庄的 ...
- 原生js制作标题与内容保持4行的效果
在制作网页或移动端有时会用到一个效果,类似文章标题和文章描述的排列总是保持一样的行数,要么标题总是一行,多出的省略,要么标题内容1:3或2:2或3:1这样,今天练习这样的效果. 实现的原理:给标题和内 ...
- 安装配置postgreSQL+pgcli+pgadmin3
记录了postgreSQL数据库的完整的安装配置过程,以及postgreSQL的pgcli命令行智能提醒扩展,pgadmin3图形化管理客户端的配置安装.此postgresql是bigsql版安装详情 ...
- CSS浮动并清除浮动(造成的影响)
一.浮动 CSS浮动 CSS float浮动的深入研究.详解及拓展(一) CSS浮动属性Float详解 块级元素独占一行 块级元素,在页面中独占一行,自上而下排列,也就是传说中的流. 可以 ...
- Android Animation 知识点速记备忘思维导图
备注的大段文本,无法在图片中体现, 思维导图源文件放在附件中.使用 Xmind 8 制作. 附件:AndroidAnimation-xmind.zip
- python 测试:生成exe文件
任务: test.py print(input('请输入:')) 将test.py生成test.exe 解答: 安装: pip install pyinstaller 命令使用: (绝对地址)pyin ...
- 使用webBrowser下载文件
如果直接用webBrowser.Navigate("http://***.com/");会弹出文件下载的对话框. 而如果用webclient.UploadData()下载,对方网站 ...