Java集合(2):LinkedList
一.LinkedList介绍
LinkedList也和ArrayList一样实现了List接口,但是它执行插入和删除操作时比ArrayList更加高效,因为它是基于链表的。基于链表也决定了它在随机访问方面要比ArrayList逊色一点。
除此之外,LinkedList还提供了一些可以使其作为栈、队列、双端队列的方法。这些方法中有些彼此之间只是名称的区别,以使得这些名字在特定的上下文中显得更加的合适。
1.LinkedList的继承关系
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
LinkedList的类图关系如下:
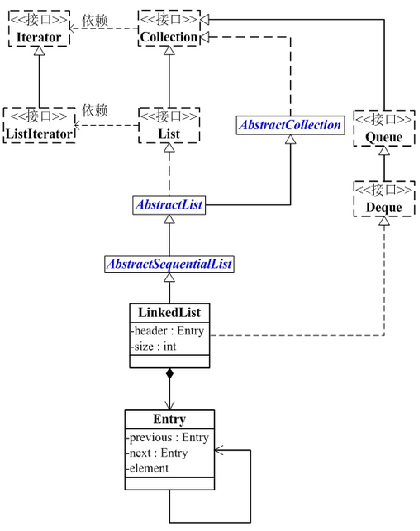
- LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
- LinkedList 实现 List 接口,能对它进行队列操作。
- LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
- LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
- LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
- LinkedList 是非同步的。
2.LinkedList数据结构原理
LinkedList底层的数据结构是基于双向循环链表的,且头结点中不存放数据

二.LinkedList源码解析
1.私有属性
LinkedList中之定义了两个属性:
private transient Entry<E> header = new Entry<E>(null, null, null);
private transient int size = 0;
header是双向链表的头节点,不包含数据,它是双向链表节点所对应的类Entry的实例。Entry中包含成员变量: previous, next, element。其中,previous是该节点的上一个节点,next是该节点的下一个节点,element是该节点所包含的值。
size是双向链表中节点实例的个数。
2.节点类即Entry类
private static class Entry<E> {
E element;
Entry<E> next;
Entry<E> previous;
Entry(E element, Entry<E> next, Entry<E> previous) {
this.element = element;
this.next = next;
this.previous = previous;
}
}
定义了存储的元素、前一个元素、后一个元素,这就是双向链表的节点的定义,每个节点只知道自己的前一个节点和后一个节点。
3.LinkedList的构造方法
public LinkedList() {
header.next = header.previous = header;
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
LinkedList提供了两个构造方法。
第一个构造方法不接受参数,将header实例的previous和next全部指向header实例(注意,这个是一个双向循环链表,如果不是循环链表,空链表的情况应该是header节点的前一节点和后一节点均为null),这样整个链表其实就只有header一个节点,用于表示一个空的链表。执行完构造函数后,header实例自身形成一个闭环。
第二个构造方法接收一个Collection参数c,调用第一个构造方法构造一个空的链表,之后通过addAll将c中的元素全部添加到链表中。
4.元素添加
// 将元素(E)添加到LinkedList中
public boolean add(E e) {
// 将节点(节点数据是e)添加到表头(header)之前。
// 即,将节点添加到双向链表的末端。
addBefore(e, header);
return true;
} public void add(int index, E element) {
addBefore(element, (index==size ? header : entry(index)));
} private Entry<E> addBefore(E e, Entry<E> entry) {
Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
size++;
modCount++;
return newEntry;
}
addBefore(E e,Entry<E> entry)方法是个私有方法,所以无法在外部程序中调用(当然,这是一般情况,你可以通过反射上面的还是能调用到的)。
addBefore(E e,Entry<E> entry)先通过Entry的构造方法创建e的节点newEntry(包含了将其下一个节点设置为entry,上一个节点设置为entry.previous的操作,相当于修改newEntry的“指针”),之后修改插入位置后newEntry的前一节点的next引用和后一节点的previous引用,使链表节点间的引用关系保持正确。之后修改和size大小和记录modCount,然后返回新插入的节点。
总结,addBefore(E e,Entry<E> entry)实现在entry之前插入由e构造的新节点。而add(E e)实现在header节点之前插入由e构造的新节点。

另外,还有addFirst和addLast方法
public void addFirst(E e) {
addBefore(e, header.next);
}
public void addLast(E e) {
addBefore(e, header);
}
addFrist(E e)只需实现在header元素的下一个元素之前插入,即示意图中的一号之前。addLast(E e)只需在实现在header节点前(因为是循环链表,所以header的前一个节点就是链表的最后一个节点)插入节点(插入后在2号节点之后)。
5.删除数据remove()
LinkedList中删除数据的方法有很多。remove(),remove(int index),remove(Object o), removeFirst(),removeLast(),removeFirstOccurrence(),removeLastOccurence()等。几个remove方法最终都是调用了一个私有方法:remove(Entry<E> e),只是其他简单逻辑上的区别。下面分析remove(Entry<E> e)方法。
private E remove(Entry<E> e) {
if (e == header)
throw new NoSuchElementException();
// 保留将被移除的节点e的内容
E result = e.element;
// 将前一节点的next引用赋值为e的下一节点
e.previous.next = e.next;
// 将e的下一节点的previous赋值为e的上一节点
e.next.previous = e.previous;
// 上面两条语句的执行已经导致了无法在链表中访问到e节点,而下面解除了e节点对前后节点的引用
e.next = e.previous = null;
// 将被移除的节点的内容设为null
e.element = null;
// 修改size大小
size--;
modCount++;
// 返回移除节点e的内容
return result;
}
清空预删除节点:
e.next = e.previous = null;
e.element = null;
交给gc完成资源回收,删除操作结束。
与ArrayList比较而言,LinkedList的删除动作不需要“移动”很多数据,从而效率更高。
6.clear()和clone()方法
(1).clear()
public void clear() {
Entry<E> e = header.next;
// e可以理解为一个移动的“指针”,因为是循环链表,所以回到header的时候说明已经没有节点了
while (e != header) {
// 保留e的下一个节点的引用
Entry<E> next = e.next;
// 接触节点e对前后节点的引用
e.next = e.previous = null;
// 将节点e的内容置空
e.element = null;
// 将e移动到下一个节点
e = next;
}
// 将header构造成一个循环链表,同构造方法构造一个空的LinkedList
header.next = header.previous = header;
// 修改size
size = 0;
modCount++;
}
(2).clone()
public Object clone() {
LinkedList<E> clone = null;
try {
clone = (LinkedList<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
clone.header = new Entry<E>(null, null, null);
clone.header.next = clone.header.previous = clone.header;
clone.size = 0;
clone.modCount = 0;
for (Entry<E> e = header.next; e != header; e = e.next)
clone.add(e.element);
return clone;
}
调用父类的clone()方法初始化对象链表clone,将clone构造成一个空的双向循环链表,之后将header的下一个节点开始将逐个节点添加到clone中。最后返回克隆的clone对象。
7.toArray()方法
(1).toArray()
public Object[] toArray() {
Object[] result = new Object[size];
int i = 0;
for (Entry<E> e = header.next; e != header; e = e.next)
result[i++] = e.element;
return result;
}
创建大小和LinkedList相等的数组result,遍历链表,将每个节点的元素element复制到数组中,返回数组。
(2).toArray(T[] a)
public <T> T[] toArray(T[] a) {
if (a.length < size)
a = (T[])java.lang.reflect.Array.newInstance(
a.getClass().getComponentType(), size);
int i = 0;
Object[] result = a;
for (Entry<E> e = header.next; e != header; e = e.next)
result[i++] = e.element;
if (a.length > size)
a[size] = null;
return a;
}
先判断出入的数组a的大小是否足够,若大小不够则拓展。这里用到了发射的方法,重新实例化了一个大小为size的数组。之后将数组a赋值给数组result,遍历链表向result中添加的元素。最后判断数组a的长度是否大于size,若大于则将size位置的内容设置为null。返回a。
从代码中可以看出,数组a的length小于等于size时,a中所有元素被覆盖,被拓展来的空间存储的内容都是null;若数组a的length的length大于size,则0至size-1位置的内容被覆盖,size位置的元素被设置为null,size之后的元素不变。
8.遍历数据:Iterator()
除了Entry,LinkedList还有一个内部类:ListItr。
ListItr实现了ListIterator接口,可知它是一个迭代器,通过它可以遍历修改LinkedList。
在LinkedList中提供了获取ListItr对象的方法:listIterator(int index)。
下面详细分析ListItr。
private class ListItr implements ListIterator<E> {
// 最近一次返回的节点,也是当前持有的节点
private Entry<E> lastReturned = header;
// 对下一个元素的引用
private Entry<E> next;
// 下一个节点的index
private int nextIndex;
private int expectedModCount = modCount;
// 构造方法,接收一个index参数,返回一个ListItr对象
ListItr(int index) {
// 如果index小于0或大于size,抛出IndexOutOfBoundsException异常
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+size);
// 判断遍历方向
if (index < (size >> 1)) {
// next赋值为第一个节点
next = header.next;
// 获取指定位置的节点
for (nextIndex=0; nextIndex<index; nextIndex++)
next = next.next;
} else {
// else中的处理和if块中的处理一致,只是遍历方向不同
next = header;
for (nextIndex=size; nextIndex>index; nextIndex--)
next = next.previous;
}
}
// 根据nextIndex是否等于size判断时候还有下一个节点(也可以理解为是否遍历完了LinkedList)
public boolean hasNext() {
return nextIndex != size;
}
// 获取下一个元素
public E next() {
checkForComodification();
// 如果nextIndex==size,则已经遍历完链表,即没有下一个节点了(实际上是有的,因为是循环链表,任何一个节点都会有上一个和下一个节点,这里的没有下一个节点只是说所有节点都已经遍历完了)
if (nextIndex == size)
throw new NoSuchElementException();
// 设置最近一次返回的节点为next节点
lastReturned = next;
// 将next“向后移动一位”
next = next.next;
// index计数加1
nextIndex++;
// 返回lastReturned的元素
return lastReturned.element;
}
public boolean hasPrevious() {
return nextIndex != 0;
}
// 返回上一个节点,和next()方法相似
public E previous() {
if (nextIndex == 0)
throw new NoSuchElementException();
lastReturned = next = next.previous;
nextIndex--;
checkForComodification();
return lastReturned.element;
}
public int nextIndex() {
return nextIndex;
}
public int previousIndex() {
return nextIndex-1;
}
// 移除当前Iterator持有的节点
public void remove() {
checkForComodification();
Entry<E> lastNext = lastReturned.next;
try {
LinkedList.this.remove(lastReturned);
} catch (NoSuchElementException e) {
throw new IllegalStateException();
}
if (next==lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = header;
expectedModCount++;
}
// 修改当前节点的内容
public void set(E e) {
if (lastReturned == header)
throw new IllegalStateException();
checkForComodification();
lastReturned.element = e;
}
// 在当前持有节点后面插入新节点
public void add(E e) {
checkForComodification();
// 将最近一次返回节点修改为header
lastReturned = header;
addBefore(e, next);
nextIndex++;
expectedModCount++;
}
// 判断expectedModCount和modCount是否一致,以确保通过ListItr的修改操作正确的反映在LinkedList中
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
下面是一个ListItr的使用实例。
LinkedList<String> list = new LinkedList<String>();
list.add("First");
list.add("Second");
list.add("Thrid");
System.out.println(list);
ListIterator<String> itr = list.listIterator();
while (itr.hasNext()) {
System.out.println(itr.next());
}
try {
System.out.println(itr.next());// throw Exception
} catch (Exception e) {
// TODO: handle exception
}
itr = list.listIterator();
System.out.println(list);
System.out.println(itr.next());
itr.add("new node1");
System.out.println(list);
itr.add("new node2");
System.out.println(list);
System.out.println(itr.next());
itr.set("modify node");
System.out.println(list);
itr.remove();
System.out.println(list);
结果:
[First, Second, Thrid]
First
Second
Thrid
[First, Second, Thrid]
First
[First, new node1, Second, Thrid]
[First, new node1, new node2, Second, Thrid]
Second
[First, new node1, new node2, modify node, Thrid]
[First, new node1, new node2, Thrid]
LinkedList还有一个提供Iterator的方法:descendingIterator()。该方法返回一个DescendingIterator对象。DescendingIterator是LinkedList的一个内部类。
9.其他方法
LinkedList中还有许多其他方法,在此不一一介绍。
contains(Object o),element(),getFirst(),get(int index),getLast(),set(int index,E element), lastIndexOf(Object o),
offer(E e) 在链表尾部插入元素,offerFirst(E e) 在链表开头插入元素,offerLast(E e) 在链表末尾插入元素 这三个方法都调用了相应的add方法。
peek(),peekFirst(),peekLast() 调用了对应的get方法
poll(),pollFirst(),pollLast() poll相关的方法都是获取并移除某个元素。都是和remove操作相关。
pop(),push(E e) 弹出一个元素和压入一个元素,仅仅是调用了removeFirst()和addFirst()方法。
参考:http://www.cnblogs.com/ITtangtang/p/3948610.html#a9
http://www.cnblogs.com/hzmark/archive/2012/12/25/LinkedList.html
Java集合(2):LinkedList的更多相关文章
- 【Java集合】LinkedList详解前篇
[Java集合]LinkedList详解前篇 一.背景 最近在看一本<Redis深度历险>的书籍,书中第二节讲了Redis的5种数据结构,其中看到redis的list结构时,作者提到red ...
- Java集合:LinkedList源码解析
Java集合---LinkedList源码解析 一.源码解析1. LinkedList类定义2.LinkedList数据结构原理3.私有属性4.构造方法5.元素添加add()及原理6.删除数据re ...
- 死磕 java集合之LinkedList源码分析
问题 (1)LinkedList只是一个List吗? (2)LinkedList还有其它什么特性吗? (3)LinkedList为啥经常拿出来跟ArrayList比较? (4)我为什么把LinkedL ...
- Java 集合之LinkedList源码分析
1.介绍 链表是数据结构中一种很重要的数据结构,一个链表含有一个或者多个节点,每个节点处理保存自己的信息之外还需要保存上一个节点以及下一个节点的指针信息.通过链表的表头就可以访问整个链表的信息.Jav ...
- Java集合干货——LinkedList源码分析
前言 在上篇文章中我们对ArrayList对了详细的分析,今天我们来说一说LinkedList.他们之间有什么区别呢?最大的区别就是底层数据结构的实现不一样,ArrayList是数组实现的(具体看上一 ...
- Java集合(五)--LinkedList源码解读
首先看一下LinkedList基本源码,基于jdk1.8 public class LinkedList<E> extends AbstractSequentialList<E> ...
- Java集合:LinkedList (JDK1.8 源码解读)
LinkedList介绍 还是和ArrayList同样的套路,顾名思义,linked,那必然是基于链表实现的,链表是一种线性的储存结构,将储存的数据存放在一个存储单元里面,并且这个存储单元里面还维护了 ...
- java集合-链表LinkedList
1.简介 LinkedList 底层使用的是 双向链表的数据结构 2.类图(JDK 1.8) 下图是LinkedList实现的接口和继承的类关系图: public class LinkedList&l ...
- Java集合之LinkedList
一.LinkedList概述 1.初识LinkedList 上一篇中讲解了ArrayList,本篇文章讲解一下LinkedList的实现. LinkedList是基于链表实现的,所以先讲解一下什么是链 ...
- 源码小结:Java 集合ArrayList,LinkedList 源码
现在这篇主要讲List集合的三个子类: ArrayList 底层数据结构是数组.线程不安全 LinkedList 底层数据结构是链表.线程不安全 Vector 底层数据结构是数组.线程安全 Array ...
随机推荐
- Azkaban安装配置
描述: azkaban主要用于离线计算任务的调度 说明: 此处Azkaban选择版本为:3.52.0,部署方式为Cluster模式,即支持多Executor计算节点,目前默认安装方式选择在同一台机器上 ...
- 深入了解Go Playground
简介 2010年9月,我们介绍了Go Playground,这是一个完全由Go代码组成和返回程序运行结果的web服务器. 如果你是一位Go程序员,那你很可能已经通过阅读Go教程或执行Go文档中的示例程 ...
- 进程间通信之WM_COPYDATA方式反思,回顾和总结
许多Windows程序开发者喜欢使用WM_COPYDATA来实现一些进程间的简单通信(笔者也正在学习共享内存的一些知识来实现一些更高级的通信),这篇文章描述了笔者在使用这项技术时候的一些总结以及所遇到 ...
- 【vijos】1543 极值问题(数论+fib数)
https://vijos.org/p/1543 好神奇的一题.. 首先我竟然忘记n可以求根求出来,sad. 然后我打了表也发现n和m是fib数.. 严格证明(鬼知道为什么这样就能对啊,能代换怎么就能 ...
- VC++Debug避免F11步进不想要的函数中
It's often useful to avoid stepping into some common code like constructors or overloaded operators. ...
- js判断css动画效果是否结束
<!-- css样式 --> <style> .test{ width: 100px; height: 100px; transition: all 5s; backgroun ...
- vmware 虚拟机下 ubuntu 与主机共享锐捷
一直以来.想要学习 linux ,在 vm 虚拟机下安装了 ubuntu 系统. 可是这个系统并不能上网.原因就是 vm 虚拟机的虚拟网卡会和锐捷冲突.锐捷会检測到多网卡,断开网络,所以不得不禁用 v ...
- mac下面安装多个JDK
JDK8 GA之后,小伙伴们喜大普奔,纷纷跃跃欲试,想体验一下Java8的Lambda等新特性,可是目前Java企业级应用的主打版本还是JDK6, JDK7.因此,我需要在我的电脑上同时有JDK8,J ...
- idle命令行按ALT+P重复调出上个语句
idle命令行按ALT+P重复调出上个语句
- Fluent Ribbon 第六步 StartScreen
上一节,介绍了Toolbar的主要功能,说明了ToolBar的一些最基本用法,这一节,介绍Ribbon的一个重要功能startScreen, startScreen软件第一次启动,呈现的界面. 由于R ...