福大软工1816 · 第五次作业 - 结对作业2_map与unordered map的比较测试
测试代码:
#include <iostream>
using namespace std;
#include <string>
#include <windows.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <map>
const int maxval = 2000000 * 5;
#include <unordered_map>
void map_test()
{
printf("map_test\n");
map<int, int> mp;
clock_t startTime, endTime;
startTime = clock();
for (int i = 0; i < maxval; i++)
{
mp[rand() % maxval]++;
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("insert finish\n");
startTime = clock();
for (int i = 0; i < maxval; i++)
{
if (mp.find(rand()%maxval) == mp.end())
{
//printf("not found\n");
}
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("find finish\n");
startTime = clock();
for(auto it = mp.begin(); it!=mp.end(); it++)
{
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("travel finish\n");
printf("------------------------------------------------\n");
}
void hash_map_test()
{
printf("hash_map_test\n");
unordered_map<int, int> mp;
clock_t startTime, endTime;
startTime = clock();
for (int i = 0; i < maxval; i++)
{
mp[rand() % maxval] ++;
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("insert finish\n");
startTime = clock();
for (int i = 0; i < maxval; i++)
{
if (mp.find(rand() % maxval) == mp.end())
{
//printf("not found\n");
}
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("find finish\n");
startTime = clock();
for(auto it = mp.begin(); it!=mp.end(); it++)
{
}
endTime = clock();
printf("%lf\n", (double)(endTime - startTime) / CLOCKS_PER_SEC);
printf("travel finish\n");
printf("------------------------------------------------\n");
}
int main(int argc, char *argv[])
{
srand(0);
map_test();
Sleep(1000);
srand(0);
hash_map_test();
system("pause");
return 0;
}
详解:
map(使用红黑树)与unordered_map(hash_map)比较
map理论插入、查询时间复杂度O(logn)
unordered_map理论插入、查询时间复杂度O(1)
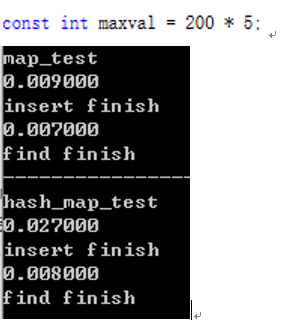
数据量较小时,可能是由于unordered_map(hash_map)初始大小较小,大小频繁到达阈值,多次重建导致插入所用时间稍大。(类似vector的重建过程)。
哈希函数也是有消耗的(应该是常数时间),这时候用于哈希的消耗大于对红黑树查找的消耗(O(logn)),所以unordered_map的查找时间会多余对map的查找时间。
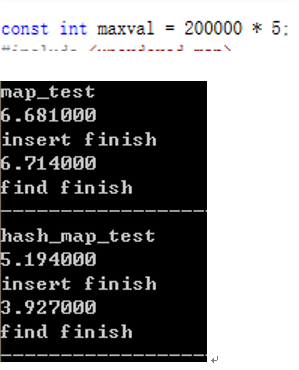
数据量较大时,重建次数减少,用于重建的开销小,unordered_map O(1)的优势开始显现
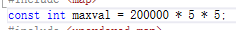
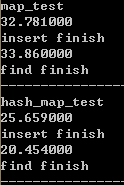
数据量更大,优势更明显
使用空间:


前半部分为map,后半部分为unordered_map
unordered_map占用的空间比map略多,但可以接受。
map和unordered_map内部实现应该都是采用达到阈值翻倍开辟空间的机制(16、32、64、128、256、512、1024……)浪费一定的空间是不可避免的。并且在开双倍空间时,若不能从当前开辟,会在其他位置开辟,开好后将数据移过去。数据的频繁移动也会消耗一定的时间,在数据量较小时尤为明显。
一种方法是手写定长开散列。这样做在数据量较小时有很好地效果(避免了数据频繁移动,真正趋近O(1))。但由于是定长的,在数据量较大时,数据重叠严重,散列效果急剧下降,时间复杂度趋近O(n)。
一种折中的方法是自己手写unordered_map(hash_map),将初始大小赋为一个较大的值。扩张可以模仿STL的双倍扩张,也可以自己采用其他方法。这样写出来的是最优的,但是实现起来极为麻烦。
综合利弊,我们组采用unordered_map。
附:使用Dev测试与VS2017测试效果相差极大???
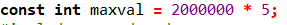
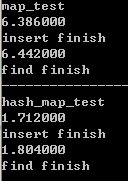
效率差了10倍???
原因:
Dev

VS2017

在Debug下,要记录断点等调试信息,的确慢。
Release:不对源代码进行调试,编译时对应用程序的速度进行优化,使得程序在代码大小和运行速度上都是最优的。
VS2017切到release后,还更快

除了前面说的Debug与release导致效率差异外,编译器的不同也会导致效率差异。
学到了。
福大软工1816 · 第五次作业 - 结对作业2_map与unordered map的比较测试的更多相关文章
- 福大软工1816 · 第五次作业 - 结对作业2_EXE图片_备用
1_每日推荐界面.png 2_论文搜索界面.png 2_论文搜索界面_搜索功能.png 3_流行趋势_十大热词排名统计图.png 4_人物界面.png 5_我的收藏界面.png 6_设置界面.png ...
- 福大软工1816:Alpha事后诸葛
福大软工·第十一次作业-Alpha事后诸葛亮 组长博客链接 本次作业博客链接 项目Postmortem 模板 设想和目标 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描 ...
- 福大软工1816 · 课程计划预报(K班)
实践课安排 对应教学周序 时间 内容 3 09.22 业界交流讲座 6 10.13 团队选题报告答辩 7 10.20 UML设计 8 10.27 团队项目需求答辩 11 11.17 团队现场编程实战与 ...
- 福大软工1816:Beta总结
第三视角Beta答辩总结 博客链接以及团队信息 组长博客链接 成员信息(按拼音排序) 姓名 学号 备注 张扬 031602345 组长 陈加伟 031602204 郭俊彦 031602213 洪泽波 ...
- 福大软工1816:Alpha(10/10)
Alpha 冲刺 (10/10) 队名:第三视角 组长博客链接 本次作业链接 团队部分 团队燃尽图 工作情况汇报 张扬(组长) 过去两天完成了哪些任务: 文字/口头描述: 1.和愈明.韫月一起对接 2 ...
- 福大软工1816:Beta(1/7)
Beta 冲刺 (1/7) 队名:第三视角 组长博客链接 本次作业链接 团队部分 团队燃尽图 工作情况汇报 张扬(组长) 过去两天完成了哪些任务 文字/口头描述 答辩 组织会议 复习课本 展示GitH ...
- 福大软工1816:Alpha(3/10)
Alpha 冲刺 (3/10) 队名:第三视角 组长博客链接 本次作业链接 团队部分 团队燃尽图 工作情况汇报 张扬(组长) 过去两天完成了哪些任务: 文字/口头描述: 1.学习qqbot库: 2.实 ...
- 福大软工1816 ·软工之404NoteFound团队选题报告
目录 NABCD分析引用 N(Need,需求): A(Approach,做法): B(Benefit,好处): C(Competitors,竞争): D(Delivery,交付): 初期 中期 个人贡 ...
- 福大软工1816 - 404 Note Found选题报告
目录 NABCD分析引用 N(Need,需求): A(Approach,做法): B(Benefit,好处): C(Competitors,竞争): D(Delivery,交付): 初期 中期 个人贡 ...
随机推荐
- jQuery表单验证的几种方法
1.jQuery的框架的验证:validate框架 Jquery Validate 验证规则 (1)required:true 必输字段(2)remote:”check.PHP” 使用ajax方法调用 ...
- Mysql是否开启binlog日志&开启方法
运行sql show variables like 'log_bin'; 如果Value 为 OFF 则为开启日志文件 如何开启mysql日志? 找到my,cnf 中 [mysqld] 添加如下 ...
- C语言之二叉树
规定:根节点的值大于左节点但小于右节点的值,所以二叉树的值插入是唯一的,最后形成的树只跟根节点有关 定义节点: struct tree_node { TypeElem elem; stru ...
- Python学习笔记三:数据类型
数据类型 整数int 32位机器,-2**31~2**31-1,即-2147483648~2147483647(4亿多) 64位机器,-2**63~2**63-1,非常大了. 长整型long 没有位数 ...
- spring boot 数据库连接
server: port: 8080 spring: datasource: url: jdbc:mysql://localhost:3306/jdjk?serverTimezone=Asia/Sha ...
- SpringBoot学习:整合shiro(验证码功能和登录次数限制功能)
项目下载地址:http://download.csdn.NET/detail/aqsunkai/9805821 (一)验证码 首先login.jsp里增加了获取验证码图片的标签: <body s ...
- python简单的socket 服务器和客户端
服务器端代码 if "__main__" == __name__: try: sock = socket.socket(socket.AF_INET, socket.SOCK_ST ...
- 阿里云服务器Linux系统安装配置ElasticSearch搜索引擎
近几篇ElasticSearch系列: 1.阿里云服务器Linux系统安装配置ElasticSearch搜索引擎 2.Linux系统中ElasticSearch搜索引擎安装配置Head插件 3.Ela ...
- Selenium(Python) ddt数据驱动
首先, 添加ddt模块: import unittestfrom time import sleep from ddt import ddt, data, unpack# 导入ddt模块from se ...
- APP功能性测试-1
疑难点 根据软件说明()或用户需求()验证App的各个功能实现 根据需求,提炼App的用户使用场景,验证功能 根据测试指标,验证功能 根据被测试功能点的特性采用特定的方法进行测试(场景,边界值,,,) ...