{转}用ADMM求解大型机器学习问题
从等式约束的最小化问题说起:  上面问题的拉格朗日表达式为:
上面问题的拉格朗日表达式为: 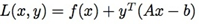 也就是前面的最小化问题可以写为: minxmaxyL(x,y) 。 它对应的对偶问题为: maxyminxL(x,y) 。 下面是用来求解此对偶问题的对偶上升迭代方法:
也就是前面的最小化问题可以写为: minxmaxyL(x,y) 。 它对应的对偶问题为: maxyminxL(x,y) 。 下面是用来求解此对偶问题的对偶上升迭代方法: 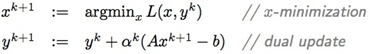 这个方法在满足一些比较强的假设下可以证明收敛。
这个方法在满足一些比较强的假设下可以证明收敛。
为了弱化对偶上升方法的强假设性,一些研究者在上世纪60年代提出使用扩展拉格朗日表达式(augmented Lagrangian)代替原来的拉格朗日表达式: 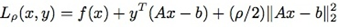 其中ρ>0。对应上面的对偶上升方法,得到下面的乘子法(method of multipliers):
其中ρ>0。对应上面的对偶上升方法,得到下面的乘子法(method of multipliers): 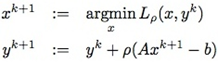
注意,乘子法里把第二个式子里的αk改成了扩展拉格朗日表达式中引入的ρ。这不是一个随意行为,而是有理论依据的。利用L(x,y)可以导出上面最小化问题对应的原始和对偶可行性条件分别为(∂L∂y=0,∂L∂x=0): 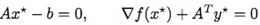 既然xk+1 最小化 Lρ(x,yk),有:
既然xk+1 最小化 Lρ(x,yk),有: 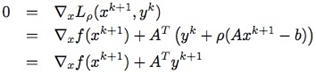 上面最后一个等式就是利用了yk+1=yk+ρ(Axk+1−b)。从上面可知,这种yk+1的取法使得(xk+1,yk+1)满足对偶可行条件∂L∂x=0。而原始可行条件在迭代过程中逐渐成立。
上面最后一个等式就是利用了yk+1=yk+ρ(Axk+1−b)。从上面可知,这种yk+1的取法使得(xk+1,yk+1)满足对偶可行条件∂L∂x=0。而原始可行条件在迭代过程中逐渐成立。
乘子法弱化了对偶上升法的收敛条件,但由于在x-minimization步引入了二次项而导致无法把x分开进行求解(详见[1])。而接下来要讲的最小化Lρ(xk+1,z,yk): 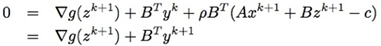 其中用到了z对应的对偶可行性式子: ∂L∂z=∇g(z)+BTy=0
其中用到了z对应的对偶可行性式子: ∂L∂z=∇g(z)+BTy=0
定义新变量u=1ρy,那么(3.2-3.4)中的迭代可以变为以下形式: 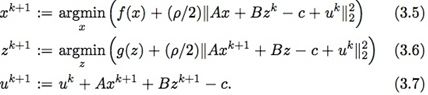 在真正求解时通常会使用所谓的over-relaxation方法,也即在z和u中使用下面的表达式代替其中的Axk+1: αkAxk+1−(1−αk)(Bzk−c), 其中αk为relaxation因子。有实验表明αk∈[1.5,1.8]可以改进收敛性([2])。
在真正求解时通常会使用所谓的over-relaxation方法,也即在z和u中使用下面的表达式代替其中的Axk+1: αkAxk+1−(1−αk)(Bzk−c), 其中αk为relaxation因子。有实验表明αk∈[1.5,1.8]可以改进收敛性([2])。
下面让我们看看ADMM怎么被用来求解大型的机器学习模型。所谓的大型,要不就是样本数太多,或者样本的维数太高。下面我们只考虑第一种情况,关于第二种情况感兴趣的读者可以参见最后的参考文献[1, 2]。样本数太多无法一次全部导入内存,常见的处理方式是使用分布式系统,把样本分块,使得每块样本能导入到一台机器的内存中。当然,我们要的是一个最终模型,它的训练过程利用了所有的样本数据。常见的机器学习模型如下: minimize x∑Jj=1fj(x)+g(x), 其中x为模型参数,fj(x)对应第j个样本的损失函数,而g(x)为惩罚系数,如g(x)=||x||1。
假设把J个样本分成N份,每份可以导入内存。此时我们把上面的问题重写为下面的形式: 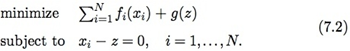 除了把目标函数分成N块,还额外加了N个等式约束,使得利用每块样本计算出来的模型参数xi都相等。那么,ADMM中的求解步骤(3.2)-(3.4)变为:
除了把目标函数分成N块,还额外加了N个等式约束,使得利用每块样本计算出来的模型参数xi都相等。那么,ADMM中的求解步骤(3.2)-(3.4)变为: 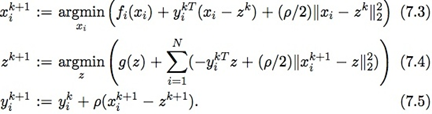 例如求解L1惩罚的LR模型,其迭代步骤如下(u=1ρy,g(z)=λ||z||1):
例如求解L1惩罚的LR模型,其迭代步骤如下(u=1ρy,g(z)=λ||z||1): 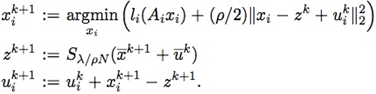 其中x¯≐1N∑Nixi,y¯的定义类似。
其中x¯≐1N∑Nixi,y¯的定义类似。
在分布式情况下,为了计算方便通常会把u的更新步骤挪在最前面,这样u和x的更新可以放在一块: 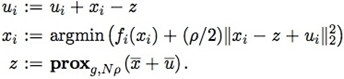
ADMM的框架确实很牛逼,把一个大问题分成可分布式同时求解的多个小问题。理论上,ADMM的框架可以解决大部分实际中的大尺度问题。我自己全部实现了一遍这个框架,主要用于求解LR问题,下面说说我碰到的一些问题: 1. 收敛不够快,往往需要迭代几十步。整体速度主要依赖于xi更新时所使用的优化方法,个人建议使用liblinear里算法,但是不能直接拿来就用,需要做一些调整。 2. 停止准则和ρ的选取:停止准则主要考量的是xi和z之间的差异和它们本身的变动情况,但这些值又受ρ的取值的影响。它们之间如何权衡并无定法。个人建议使用模型在测试集上的效果来确定是否停止迭代。 3. 不适合MapReduce框架实现:需要保证对数据的分割自始至终都一致;用MPI实现的话相对于其他算法又未必有什么优势(如L-BFGS、OwLQN等)。 4. relaxation步骤要谨慎:α的取值依赖于具体的问题,很多时候的确可以加快收敛速度,但对有些问题甚至可能带来不收敛的后果。用的时候不论是用x -> z -> u的更新步骤,还是用u -> x -> z的更新步骤,在u步使用的x_hat要和在z步使用的相同(使用旧的z),而不是使用z步刚更新的z重算。 5. warm start 和子问题求解逐渐精确的策略可以降低xi更新时的耗时,但也使得算法更加复杂,需要设定的参数也增加了。
[References] [1] S. Boyd. Alternating Direction Method of Multipliers (Slides).
[2] S. Boyd et al. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers, 2010
{转}用ADMM求解大型机器学习问题的更多相关文章
- 用ADMM求解大型机器学习问题
[本文链接:http://www.cnblogs.com/breezedeus/p/3496819.html,转载请注明出处] 从等式约束的最小化问题说起: ...
- 协同ADMM求解考虑碳排放约束直流潮流问题的对偶问题(A Distributed Dual Consensus ADMM Based on Partition for DC-DOPF with Carbon Emission Trading)
协同ADMM求解考虑碳排放约束直流潮流问题的对偶问题 (A Distributed Dual Consensus ADMM Based on Partition for DC-DOPF with Ca ...
- 100个大型机器学习数据集汇总(CV/NLP/音频方向)
网站首页: 网址:数据集
- ADMM与one-pass multi-view learning
现在终于开始看论文了,机器学习基础部分的更新可能以后会慢一点了,当然还是那句话宁愿慢点,也做自己原创的,自己思考的东西.现在开辟一个新的模块----多视图学习相关论文笔记,就是分享大牛的paper,然 ...
- 对偶上升法到增广拉格朗日乘子法到ADMM
对偶上升法 增广拉格朗日乘子法 ADMM 交替方向乘子法(Alternating Direction Method of Multipliers,ADMM)是一种解决可分解凸优化问题的简单方法,尤其在 ...
- cuda并行编程之求解ConjugateGradient(共轭梯度迭代)丢失dll解决方式
在进行图像处理过程中,我们常常会用到梯度迭代求解大型线性方程组.今天在用cuda对神秘矩阵进行求解的时候.出现了缺少dll的情况: 报错例如以下图: watermark/2/text/aHR0cDov ...
- MapReduce: 一种简化的大规模集群数据处理法
(只有文字没有图,图请参考http://research.google.com/archive/mapreduce.html) MapReduce: 一种简化的大规模集群数据处理法 翻译:风里来雨里去 ...
- MATLAB学习笔记(七)——MATLAB解方程与函数极值
(一)线性方程组求解 包含n个未知数,由n个方程构成的线性方程组为: 其矩阵表示形式为: 其中 一.直接求解法 1.左除法 x=A\b; 如果A是奇异的,或者接近奇异的.MATLAB会发出警告信息的. ...
- [Reinforcement Learning] Value Function Approximation
为什么需要值函数近似? 之前我们提到过各种计算值函数的方法,比如对于 MDP 已知的问题可以使用 Bellman 期望方程求得值函数:对于 MDP 未知的情况,可以通过 MC 以及 TD 方法来获得值 ...
随机推荐
- scrapy(1)——scrapy介绍
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中.所谓网络爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这种说 ...
- TCP 接收窗口自动调节
https://technet.microsoft.com/zh-cn/magazine/2007.01.cableguy.aspx 欢迎来到 TechNet 杂志“网络专家”的第一部分.TechNe ...
- ASP.NET 使用MVC4的EF5 Code First 入门(一):创建数据库
一.基本流程 建立模型→建立控制器→EF框架自动生成视图的数据库 二.基本理论 1.约定优于配置(Convention Over Configuration) 设计不好的框架通常需要多个配置文件,每一 ...
- Thinkphp5使用validate实现验证功能
作为前端er,对于验证这块有着切身的体会,虽然逐渐得心应手,但始终没有一个内置的功能拿来就能用.tp5恰好提供一个.本文简单介绍并实现以下.主要是实现一下. 验证的实现基于tp5内置的对象valida ...
- python循环解码base64
第一次写博客,都不知道该如何下手,写的不是很好,还望各位大佬不要喷我. 先来介绍一下base64: Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打 ...
- 【转】how can i build fast
http://blog.csdn.net/pcliuguangtao/article/details/5830860
- RT-thread内核之小内存管理算法
一.动态内存管理 动态内存管理是一个真实的堆(Heap)内存管理模块,可以在当前资源满足的情况下,根据用户的需求分配任意大小的内存块.而当用户不需要再使用这些内存块时,又可以释放回堆中供其他应用分配 ...
- BZOJ 1452 Count(二维树状数组)
大水题. 建立100个二维树状数组,总复杂度就是O(qlognlogm). # include <cstdio> # include <cstring> # include & ...
- 【bzoj1821】[JSOI2010]Group 部落划分 Group Kruskal
题目描述 聪聪研究发现,荒岛野人总是过着群居的生活,但是,并不是整个荒岛上的所有野人都属于同一个部落,野人们总是拉帮结派形成属于自己的部落,不同的部落之间则经常发生争斗.只是,这一切都成为谜团了——聪 ...
- Java入门之:基本数据类型
Java基本数据类型 变量就是申请内存来存储值,也就是说,当创建变量的时候,需要在内存中申请空间.内存管理系统根据变量的类型为变量分配存储空间,分配的空间只能用来存储该类型的数据,如下图所示: 因此, ...