SQL中Group By 的使用
1、概述
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
2、原始表
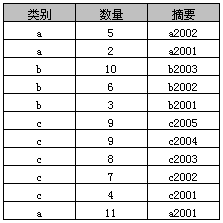
3、简单Group By
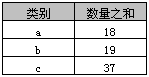
示例1
select 类别, sum(数量) as 数量之和
from A
group by 类别
返回结果如下表,实际上就是分类汇总。
4、Group By 和 Order By
示例2
select 类别, sum(数量) AS 数量之和
from A
group by 类别
order by sum(数量) desc
返回结果如下表
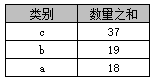
在Access中不可以使用“order by 数量之和 desc”,但在SQL Server中则可以。
5、Group By中Select指定的字段限制
示例3
select 类别, sum(数量) as 数量之和, 摘要
from A
group by 类别
order by 类别 desc
示例3执行后会提示下错误,如下图。这就是需要注意的一点,在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。

6、Group By All
示例4
select 类别, 摘要, sum(数量) as 数量之和
from A
group by all 类别, 摘要
示例4中则可以指定“摘要”字段,其原因在于“多列分组”中包含了“摘要字段”,其执行结果如下表
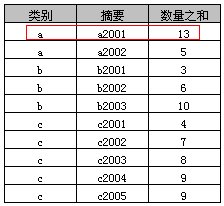
“多列分组”实际上就是就是按照多列(类别+摘要)合并后的值进行分组,示例4中可以看到“a, a2001, 13”为“a, a2001, 11”和“a, a2001, 2”两条记录的合并。
SQL Server中虽然支持“group by all”,但Microsoft SQL Server 的未来版本中将删除 GROUP BY ALL,避免在新的开发工作中使用 GROUP BY ALL。Access中是不支持“Group By All”的,但Access中同样支持多列分组,上述SQL Server中的SQL在Access可以写成
select 类别, 摘要, sum(数量) AS 数量之和
from A
group by 类别, 摘要
7、Group By与聚合函数
在示例3中提到group by语句中select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中,常见的聚合函数如下表:
| 函数 | 作用 | 支持性 |
|---|---|---|
| sum(列名) | 求和 | |
| max(列名) | 最大值 | |
| min(列名) | 最小值 | |
| avg(列名) | 平均值 | |
| first(列名) | 第一条记录 | 仅Access支持 |
| last(列名) | 最后一条记录 | 仅Access支持 |
| count(列名) | 统计记录数 | 注意和count(*)的区别 |
示例5:求各组平均值
select 类别, avg(数量) AS 平均值 from A group by 类别;
示例6:求各组记录数目
select 类别, count(*) AS 记录数 from A group by 类别;
示例7:求各组记录数目
8、Having与Where的区别
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
示例8
select 类别, sum(数量) as 数量之和 from A
group by 类别
having sum(数量) > 18
示例9:Having和Where的联合使用方法
select 类别, SUM(数量)from A
where 数量 gt;8
group by 类别
having SUM(数量) gt; 10
9、Compute 和 Compute By
select * from A where 数量 > 8
执行结果:

示例10:Compute
select *
from A
where 数量>8
compute max(数量),min(数量),avg(数量)
执行结果如下:

compute子句能够观察“查询结果”的数据细节或统计各列数据(如例10中max、min和avg),返回结果由select列表和compute统计结果组成。
示例11:Compute By
select *
from A
where 数量>8
order by 类别
compute max(数量),min(数量),avg(数量) by 类别
执行结果如下:
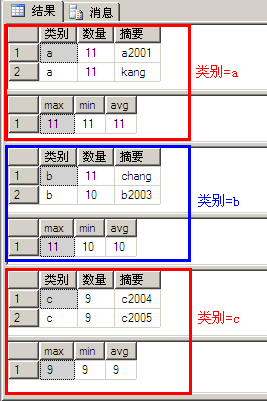
示例11与示例10相比多了“order by 类别”和“... by 类别”,示例10的执行结果实际是按照分组(a、b、c)进行了显示,每组都是由改组数据列表和改组数统计结果组成,另外:
- compute子句必须与order by子句用一起使用
- compute...by与group by相比,group by 只能得到各组数据的统计结果,而不能看到各组数据
在实际开发中compute与compute by的作用并不是很大,SQL Server支持compute和compute by,而Access并不支持
SQL中Group By 的使用的更多相关文章
- MYSQL:SQL中Group By的使用
SQL中Group By的使用 1.概述 2.原始表 3.简单Group By 4.Group By 和 Order By 5.Group By中Select指定的字段限制 6.Group By ...
- 转载:SQL中Group By 的常见使用方法
SQL中Group By 的常见使用方法 转载源:http://www.cnblogs.com/wang-meng/p/5373057.html 前言今天逛java吧看到了一个面试题, 于是有了今天 ...
- sql中group by用来干嘛的
sql中group by用来干嘛的 一.总结 一句话总结: 1.group by用来分类汇总的,by后面接要分的类 2.group by既然是分类汇总,那就要和聚合函数结合使用,因为要汇总啊 3.ha ...
- sql中group by 和having 用法解析
--sql中的group by 用法解析:-- Group By语句从英文的字面意义上理解就是“根据(by)一定的规则进行分组(Group)”.--它的作用是通过一定的规则将一个数据集划分成若干个小的 ...
- sql中group by
某图书馆收藏有书籍具有不同的出版年份,管理员需要做一下统计工作: (1)每一年书籍的数目,如: 2000年有10本书, 2001年有5本书... (2)每一种书籍的数目,如: 西游记有10本, 三国演 ...
- SQL中group by后面的having中不能使用别名
如下图中,SQL中需要对group by的结果使用having进行过滤,不能使用select中定义的别名,需要使用查询字段的原始名.否则会报错,列明未定义. 下图未错误演示: 修改后,正确的SQL语句 ...
- SQL中Group By的使用
1.概述 2.原始表 3.简单Group By 4.Group By 和 Order By 5.Group By中Select指定的字段限制 6.Group By All 7.Group By与聚合函 ...
- [数据库]SQL中Group By 的常见使用方法.
前言今天逛java吧看到了一个面试题, 于是有了今天这个文章, 回顾下Group By的用法.题目如下:Select name from table group by name having coun ...
- 【转】SQL中Group By的使用
1.概述 2.原始表 3.简单Group By 4.Group By 和 Order By 5.Group By中Select指定的字段限制 6.Group By All 7.Group By与聚合函 ...
随机推荐
- openStack镜像制作
参考链接: https://www.ibm.com/developerworks/community/wikis/home?lang=en#!/wiki/OpenStack/page/Creating ...
- Maven实战(二)构建简单Maven项目
上一节讲了maven的安装和配置,这一节我们来学习一下创建一个简单的Maven项目 1. 用Maven 命令创建一个简单的Maven项目 在cmd中运行如下命令: mvn archetype:gene ...
- IMS Global Learning Tools Interoperability™ Implementation Guide
Final Version 1.1 Date Issued: 13 March 2012 Latest version: http://www.imsglobal ...
- php函数的引用返回
<?php function &test(){ static $b = 1; $b += 2; return $b; } $a = &test(); $a =8; $c = te ...
- APP分发渠道的竞争分析
一. 最近几年,手机APP市场发展非常迅速,随着手机的硬件水平的不断升级,大量资本涌入,越来越多的开发者从桌面平台开发转移到移动平台开发,面对数以万计的手机APP,如何推广自己的APP成了难题,APP ...
- html中的块元素(Block)和内联元素(Inline)(转)
我们首先要了解,所有的html元素,都要么是块元素(block).要么是内联元素(inline).下面了解一下块元素.内联元素各自的特点: 块元素(block)的特点: 1.总是在新行上开始:2.高度 ...
- socket编程相关的结构体和字节序转换、IP、PORT转换函数
注意:结构体之间不能直接进行强制转换, 必须先转换成指针类型才可以进行结构体间的类型转换, 这里需要明确的定义就是什么才叫强制转换. 强制转换是将内存中一段代码以另一种不同类型的方式进行解读, 因此转 ...
- Repeater展示表格
1.可以不用table展示数据 <asp:Repeater ID="Repeater1" runat="server"> <ItemTempl ...
- NetBios 的结构体详解(网络控制块NCB)
对之前网络基础编程用到控制块NCB进行介绍(补充): 在Win32环境下,使用VC++6.0进行NetBIOS程序开发时, 需要用到nb30.h文件和netapi32.lib静态链接库.前者定义了Ne ...
- css样式表 格式与布局
1 样式表 内联样式表 内嵌样式表 外部样式表 2 选择器 标签选择器 <style type="text\css" class 选择器 以.开头 ID选择器 以#开 ...