SQL Server里PIVOT运算符的”红颜祸水“
在今天的文章里我想讨论下SQL Server里一个特别的T-SQL语言结构——自SQL Server 2005引入的PIVOT运算符。我经常引用这个与语言结构是SQL Server里最危险的一个——很快你就会知道为什么。在我们进入特定问题和陷阱前,首先我想给你下使用SQL Server里的PIVOT能实现什么的一个基本概述。
概述
SQL Server里PIVOT运算符背后的基本思想是在T-SQL查询期间,你可以旋转行为列。运算符本身是SQL Server 2005后引入的,主要用在基于建立在实体属性值模型(Entity Attribute Value model (EAV))原则上的数据库。EAM模型背后的想法是你可以扩展数据库实体,而不需要进行数据库架构的修改。因此EAV模型存储实体的所有属性以键/值对存储在一个表里。我们来看下面一个简单的键/值对模型的表。
CREATE TABLE EAVTable
(
RecordID INT NOT NULL,
Element CHAR(100) NOT NULL,
Value SQL_VARIANT NOT NULL,
PRIMARY KEY (RecordID, Element)
)
GO -- Insert some records
INSERT INTO EAVTable (RecordID, Element, Value) VALUES
(1, 'FirstName', 'Woody'),
(1, 'LastName', 'Tu'),
(1, 'City', 'Linhai'),
(1, 'Country', 'China'),
(2, 'FirstName', 'Bill'),
(2, 'LastName', 'Gates'),
(2, 'City', 'Seattle'),
(2, 'Country', 'USA')
GO
如你所见,我们插入2个数据库实体到表里,每个实体包含多个属性。在表里每个属性只是额外的记录。如果你像扩展实体更多的属性,你只插入额外的记录到表里,而没有必要进行数据库架构修改——这就是开放数据库架构的“威力”……
查询这样的EAV表显然很困难,因为你处理的是平键/值对的数据结构。因此你要旋转表内容,行旋转为列。你可以进行用自带的PIVOT运算符进行这个旋转,或者通过传统的CASE表达式进行纯手工来实现。在我们进入PIVOT细节前,我想给你展示下通过手工使用T-SQL和一些CASE表达式来实现。如果你手工进行旋转,你的T-SQL查询需要实现3个阶段:
- 分组阶段(Grouping Phase)
- 摊开阶段(Spreading Phase)
- 聚合阶段(Aggregation Phase)
在分组阶段(Grouping Phase)我们压缩我们的EAV表为不同的数据库实体。在这里我们在RecordID列进行一个GROUP BY。在第2阶段的,摊开阶段(Spreading Phase),我们使用多个CASE表达式来旋转行为列。最后在聚合阶段(Aggregation Phase)我们使用MAX表达式来为每个行和列返回不同值。我们来看下列T-SQL代码。
-- Pivot the data with a handwritten T-SQL statement.
-- Make sure you have an index defined on the grouping column.
SELECT
RecordID,
-- Spreading and aggregation phase
MAX(CASE WHEN Element = 'FirstName' THEN Value END) AS 'FirstName',
MAX(CASE WHEN Element = 'LastName' THEN Value END) AS 'LastName',
MAX(CASE WHEN Element = 'City' THEN Value END) AS 'City',
MAX(CASE WHEN Element = 'Country' THEN Value END) AS 'Country'
FROM EAVTable
GROUP BY RecordID -- Grouping phase
GO
从代码里可以看到,很容易区分每个阶段,还有它们如何映射到T-SQL查询。下图给你展示了查询结果,最后我们把行转为了列。
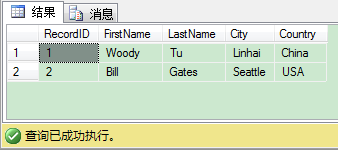
PIVOT运算符
自SQL Server 2005起(差不多10年前了!),微软在T-SQL里引入PIVOT运算符。使用那个运算符你可以进行同样的转换(行到列),只要一个原生运算符即可。听起来很简单,很有前景,不是么?下列代码显示了使用原生PIVOT运算符进行同样的转换。
-- Perform the same query with the native PIVOT operator.
-- The grouping column is not specified explicitly, it's the remaining column
-- that is not referenced in the spreading and aggregation elements.
SELECT
RecordID,
FirstName,
LastName,
City,
Country
FROM EAVTable
PIVOT(MAX(Value) FOR Element IN (FirstName, LastName, City, Country)) AS t
GO
当你执行那个查询时,你会收到和刚才图片一样的结果。但当你看PIVOT运算符语法时,和手动方法相比,你会看到一个很大的区别:
你只能指定分摊和聚合元素!不能明确定义分组元素!
分组元素是你在PIVOT运算符里没有引用的剩下列。在我们的例子里,我们没有在PIVOT运算符里没有引用RecordID列,因此这个列在分组阶段(Grouping Phase)被使用。如果我们随后修改数据库架构,这会带来有趣的副作用,例如对基本表增加额外列:
-- Add a new column to the table
ALTER TABLE EAVTable ADD SomeData CHAR(1)
GO
然后我们对其赋值:
UPDATE dbo.EAVTable SET SomeData=LEFT(CAST(Value AS VARCHAR(1)),1)
现在当你执行用PIVOIT运算符的同个查询时(在那somedata列都有非NULL值),你会拿回完全不同的结果,因为排序阶段现在是在RecordID和SomeData列(我们刚加的)上。
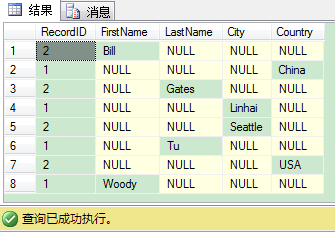
相比如果我们重新执行我们刚开始写的手工T-SQL查询会发生什么。它还是返回同样正确的结果。这是在SQL Server里,PIVOT运算符的其中一个最大的副作用:分组元素不能明确定义。为了克服这个问题,最佳实践是使用只返回需要列的表表达式。使用这个方法,如果你随后修改表架构还是没有问题,因从表表达式默认情况下额外的列还是没有返回。我们来看下列的代码:
-- Use a table expression to state explicitly which columns you want to
-- return from the base table. Therefore you can always control on which
-- columns the PIVOT operator is performing the grouping.
SELECT
RecordID,
FirstName,
LastName,
City,
Country
FROM
(
-- Table Expression
SELECT RecordID, Element, Value FROM EAVTable
) AS t
PIVOT(MAX(Value) FOR Element IN (FirstName, LastName, City, Country)) AS t1
GO
从代码里可以看到,我通过一个表表达式输送给PIVOT运算符。而且在表表达式里,你从表里只选择需要的列。这就意味着以后你可以修改表架构也会破坏PIVOT查询的结果。
小结
我希望这篇文章已向你展示了在SQL Server里,为什么PIVOT运算符是非常危险的。这个语法本身带来了非常高效的代码,但作为副作用你不能直接指定分组元素。因次你应该确保使用一个表表达式来定义输送给PIVOT运算符的列来保证给出结果的确定性。
用PIVOT运算符你有什么经历?你是否喜欢它?如果你不喜欢它,你想要什么改变?
感谢关注!
参考文章:
SQL Server里PIVOT运算符的”红颜祸水“的更多相关文章
- SQL server 2005 PIVOT运算符的使用
原文:SQL server 2005 PIVOT运算符的使用 PIVOT,UNPIVOT运算符是SQL server 2005支持的新功能之一,主要用来实现行到列的转换.本文主要介绍PIVOT运算符的 ...
- SQL Server里ORDER BY的歧义性
在今天的文章里,我想谈下SQL Server里非常有争议和复杂的话题:ORDER BY子句的歧义性. 视图与ORDER BY 我们用一个非常简单的SELECT语句开始. -- A very simpl ...
- SQL Server里的INTERSECT
在今天的文章里,我想讨论下SQL Server里的INTERSECT设置操作.INTERSECT设置操作彼此交叉2个记录集,返回2个集里列值一样的记录.下图演示了这个概念. INTERSECT与INN ...
- SQL Server里因丢失索引造成的死锁
在今天的文章里我想演示下SQL Server里在表上丢失索引如何引起死锁(deadlock)的.为了准备测试场景,下列代码会创建2个表,然后2个表都插入4条记录. -- Create a table ...
- SQL Server里Grouping Sets的威力
在SQL Server里,你有没有想进行跨越多个列/纬度的聚集操作,不使用SSAS许可(SQL Server分析服务).我不是说在生产里使用开发版,也不是说安装盗版SQL Server. 不可能的任务 ...
- SQL Server数据库PIVOT函数的使用详解(一)
http://database.51cto.com/art/201108/285250.htm SQL Server数据库中,PIVOT在帮助中这样描述滴:可以使用 PIVOT 和UNPIVOT 关系 ...
- 在SQL Server里如何处理死锁
在今天的文章里,我想谈下SQL Server里如何处理死锁.当2个查询彼此等待时会发生死锁,没有一个查询可以继续它们的操作.首先我想给你大致讲下SQL Server如何处理死锁.最后我会展示下SQL ...
- SQL Server里书签查找的性能伤害
在我的博客上,以前我经常谈到SQL Serverl里的书签查找,还有它们带来的很多问题.在今天的文章里,我想从性能角度进一步谈下书签查找,还有它们如何拉低你整个SQL Server性能. 书签查找—— ...
- SQL Server里如何处理死锁
在今天的文章里,我想谈下SQL Server里如何处理死锁.当2个查询彼此等待时会发生死锁,没有一个查询可以继续它们的操作.首先我想给你大致讲下SQL Server如何处理死锁.最后我会展示下SQL ...
随机推荐
- quartzScheduler_Worker-1] but has failed to stop it. This is very likely to create a memory leak解决
01-Jul-2016 07:24:20.218 INFO [main] org.apache.catalina.startup.Catalina.start Server startup in 80 ...
- Android文本输入框(EditText)切换密码的显示与隐藏
package cc.c; import android.app.Activity; import android.os.Bundle; import android.text.Selection; ...
- asp 时间倒数后按钮可用
<asp:Button runat="server" ID="btn" Text="免费获取验证码" onclick="bt ...
- 关于创建可执行的jar文件(assembly)
java利用maven生成一个jar包,如何自动生成清单属性文件(MANIFEST.MF),如何解决jar依赖问题? 办法很简单: 只需在pom.xml文件中配置如下plugin即可: <plu ...
- [论文笔记] Methodologies for Data Quality Assessment and Improvement (ACM Comput.Surv, 2009) (1)
Carlo Batini, Cinzia Cappiello, Chiara Francalanci, and Andrea Maurino. 2009. Methodologies for data ...
- 所有博客已经迁移到个人空间 blog.scjia.cc
所有博客已经迁移到个人空间 blog.scjia.cc
- 网友对twisted deferr的理解
事實上Deferred的確就像是一連串的動作,用callback的形式被串在一起,我們用deferred或許可以這樣寫 d.addCallback(洗菜)d.addCallback(切菜)d.addC ...
- vs.net 2005 C# WinForm GroupBOX 的BUG?尝试读取或写入受保护的内存。这通常指示其他内存已损坏
其实很久没有写程序了,国庆难得有空闲,写了个游戏辅助机器人,程序写好能用后本想把UI控件放到GroupBox里归下分类,美化下界面,结果一运行报“尝试读取或写入受保护的内存.这通常指示其他内存已损坏” ...
- log4j2配置
在eclipse使用log4j2的时候遇到个问题: 我已经把log4j2.xml放到/src目录下了,而且设置从trace开始都打印到终端,但是我的程序里trace, info都不打印,到了error ...
- POJ 2785 4 Values whose Sum is 0
4 Values whose Sum is 0 Time Limit: 15000MS Memory Limit: 228000K Total Submissions: 13069 Accep ...