Redis Cluster 的数据分片机制
上一篇《分布式数据缓存中的一致性哈希算法》
文章中讲述了一致性哈希算法的基本原理和实现,今天就以 Redis Cluster 为例,详细讲解一下分布式数据缓存中的数据分片,上线下线时数据迁移以及请求重定向等操作。
Redis 集群简介

Redis Cluster 是 Redis 的分布式解决方案,在 3.0 版本正式推出,有效地解决了 Redis 分布式方面的需求。
Redis Cluster 一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群,其中三个为主节点,三个为从节点。三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后,顶替主节点。
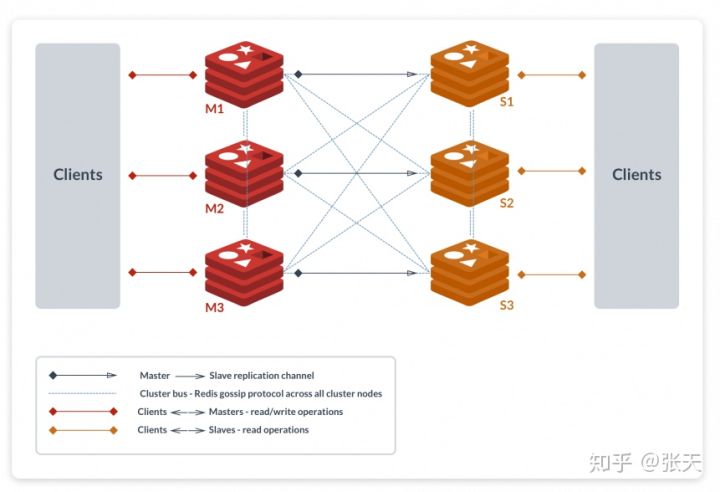
图片来源 redislabs
如上图所示,该集群中包含 6 个 Redis 节点,3主3从,分别为M1,M2,M3,S1,S2,S3。除了主从 Redis 节点之间进行数据复制外,所有 Redis 节点之间采用 Gossip 协议进行通信,交换维护节点元数据信息。
一般来说,主 Redis 节点会处理 Clients 的读写操作,而从节点只处理读操作。
数据分片策略
分布式数据存储方案中最为重要的一点就是数据分片,也就是所谓的 Sharding。
为了使得集群能够水平扩展,首要解决的问题就是如何将整个数据集按照一定的规则分配到多个节点上,常用的数据分片的方法有:范围分片,哈希分片,一致性哈希算法,哈希槽等。
范围分片假设数据集是有序,将顺序相临近的数据放在一起,可以很好的支持遍历操作。范围分片的缺点是面对顺序写时,会存在热点。比如日志类型的写入,一般日志的顺序都是和时间相关的,时间是单调递增的,因此写入的热点永远在最后一个分片。
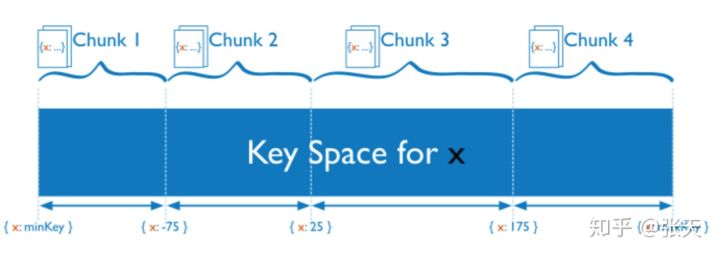
对于关系型的数据库,因为经常性的需要表扫描或者索引扫描,基本上都会使用范围的分片策略。
哈希分片和一致性哈希算法在上一篇文章中已经学习过了,感兴趣的同学可以去了解一下《分布式数据缓存中的一致性哈希算法》。我们接下来主要来看Redis 的虚拟哈希槽策略。
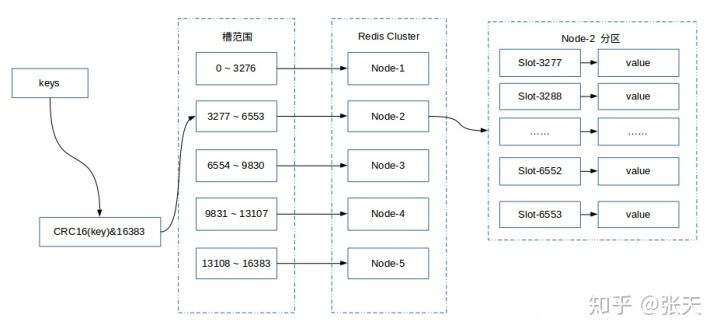
Redis Cluster 采用虚拟哈希槽分区,所有的键根据哈希函数映射到 0 ~ 16383 整数槽内,计算公式:slot = CRC16(key) & 16383。每一个节点负责维护一部分槽以及槽所映射的键值数据。
Redis 虚拟槽分区的特点:
- 解耦数据和节点之间的关系,简化了节点扩容和收缩难度。
- 节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据
- 支持节点、槽和键之间的映射查询,用于数据路由,在线集群伸缩等场景。
Redis 集群提供了灵活的节点扩容和收缩方案。在不影响集群对外服务的情况下,可以为集群添加节点进行扩容也可以下线部分节点进行缩容。可以说,槽是 Redis 集群管理数据的基本单位,集群伸缩就是槽和数据在节点之间的移动。
下面我们就先来看一下 Redis 集群伸缩的原理。然后再了解当 Redis 节点数据迁移过程中或者故障恢复时如何保证集群可用。
扩容集群
为了让读者更好的理解上线节点时的扩容操作,我们通过 Redis Cluster 的命令来模拟整个过程。
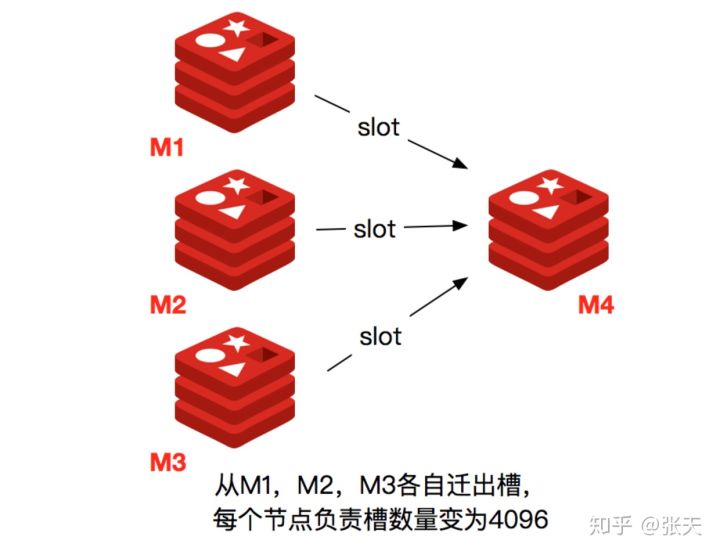
当一个 Redis 新节点运行并加入现有集群后,我们需要为其迁移槽和数据。首先要为新节点指定槽的迁移计划,确保迁移后每个节点负责相似数量的槽,从而保证这些节点的数据均匀。
- 首先启动一个 Redis 节点,记为 M4。
- 使用 cluster meet 命令,让新 Redis 节点加入到集群中。新节点刚开始都是主节点状态,由于没有负责的槽,所以不能接受任何读写操作,后续我们就给他迁移槽和填充数据。
- 对 M4 节点发送 cluster setslot { slot } importing { sourceNodeId} 命令,让目标节点准备导入槽的数据。
- 对源节点,也就是 M1,M2,M3 节点发送 cluster setslot { slot } migrating { targetNodeId} 命令,让源节点准备迁出槽的数据。
- 源节点执行 cluster getkeysinslot { slot } { count } 命令,获取 count 个属于槽 { slot } 的键,然后执行步骤六的操作进行迁移键值数据。
- 在源节点上执行 migrate { targetNodeIp} " " 0 { timeout } keys { key... } 命令,把获取的键通过 pipeline 机制批量迁移到目标节点,批量迁移版本的 migrate 命令在 Redis 3.0.6 以上版本提供。
- 重复执行步骤 5 和步骤 6 直到槽下所有的键值数据迁移到目标节点。
- 向集群内所有主节点发送 cluster setslot { slot } node { targetNodeId } 命令,通知槽分配给目标节点。为了保证槽节点映射变更及时传播,需要遍历发送给所有主节点更新被迁移的槽执行新节点。
收缩集群
收缩节点就是将 Redis 节点下线,整个流程需要如下操作流程。
- 首先需要确认下线节点是否有负责的槽,如果是,需要把槽迁移到其他节点,保证节点下线后整个集群槽节点映射的完整性。
- 当下线节点不再负责槽或者本身是从节点时,就可以通知集群内其他节点忘记下线节点,当所有的节点忘记改节点后可以正常关闭。
下线节点需要将节点自己负责的槽迁移到其他节点,原理与之前节点扩容的迁移槽过程一致。
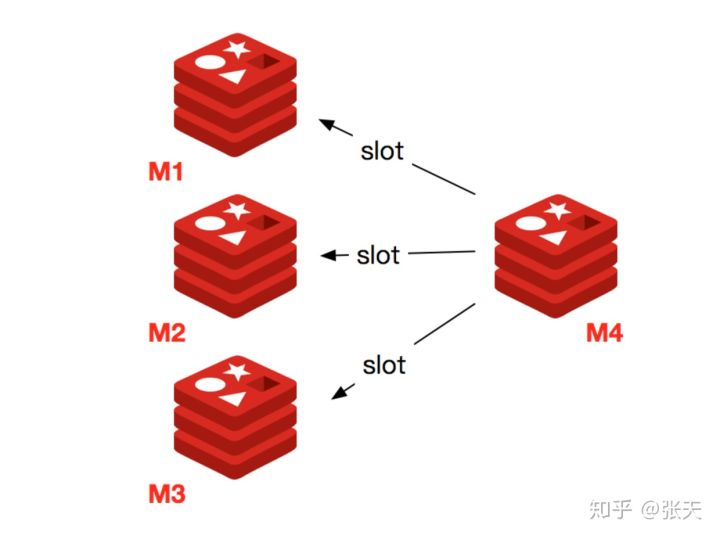
迁移完槽后,还需要通知集群内所有节点忘记下线的节点,也就是说让其他节点不再与要下线的节点进行 Gossip 消息交换。
Redis 集群使用 cluster forget { downNodeId } 命令来讲指定的节点加入到禁用列表中,在禁用列表内的节点不再发送 Gossip 消息。
客户端路由
在集群模式下,Redis 节点接收任何键相关命令时首先计算键对应的槽,在根据槽找出所对应的节点,如果节点是自身,则处理键命令;否则回复 MOVED 重定向错误,通知客户端请求正确的节点。这个过程称为 MOVED 重定向。
需要注意的是 Redis 计算槽时并非只简单的计算键值内容,当键值内容包括大括号时,则只计算括号内的内容。比如说,key 为 user:{10000}:books时,计算哈希值只计算10000。
MOVED 错误示例如下,键 x 所属的哈希槽 3999 ,以及负责处理这个槽的节点的 IP 和端口号 127.0.0.1:6381 。 客户端需要根据这个 IP 和端口号, 向所属的节点重新发送一次 GET 命令请求。
GET x
-MOVED 3999 127.0.0.1:6381
由于请求重定向会增加 IO 开销,这不是 Redis 集群高效的使用方式,而是要使用 Smart 集群客户端。Smart 客户端通过在内部维护 slot 到 Redis节点的映射关系,本地就可以实现键到节点的查找,从而保证 IO 效率的最大化,而 MOVED 重定向负责协助客户端更新映射关系。
Redis 集群支持在线迁移槽( slot ) 和数据来完成水平伸缩,当 slot 对应的数据从源节点到目标节点迁移过程中,客户端需要做到智能迁移,保证键命令可正常执行。例如当 slot 数据从源节点迁移到目标节点时,期间可能出现一部分数据在源节点,而另一部分在目标节点。

所以,综合上述情况,客户端命令执行流程如下所示:
- 客户端根据本地 slot 缓存发送命令到源节点,如果存在键对应则直接执行并返回结果给客户端。
- 如果节点返回 MOVED 错误,更新本地的 slot 到 Redis 节点的映射关系,然后重新发起请求。
- 如果数据正在迁移中,节点会回复 ASK 重定向异常。格式如下: ( error ) ASK { slot } { targetIP } : {targetPort}
- 客户端从 ASK 重定向异常提取出目标节点信息,发送 asking 命令到目标节点打开客户端连接标识,再执行键命令。
ASK 和 MOVED 虽然都是对客户端的重定向控制,但是有着本质区别。ASK 重定向说明集群正在进行 slot 数据迁移,客户端无法知道什么时候迁移完成,因此只能是临时性的重定向,客户端不会更新 slot 到 Redis 节点的映射缓存。但是 MOVED 重定向说明键对应的槽已经明确指定到新的节点,因此需要更新 slot 到 Redis 节点的映射缓存。
故障转移
当 Redis 集群内少量节点出现故障时通过自动故障转移保证集群可以正常对外提供服务。
当某一个 Redis 节点客观下线时,Redis 集群会从其从节点中通过选主选出一个替代它,从而保证集群的高可用性。这块内容并不是本文的核心内容,感兴趣的同学可以自己学习。
但是,有一点要注意。默认情况下,当集群 16384 个槽任何一个没有指派到节点时整个集群不可用。执行任何键命令返回 CLUSTERDOWN Hash slot not served 命令。当持有槽的主节点下线时,从故障发现到自动完成转移期间整个集群是不可用状态,对于大多数业务无法忍受这情况,因此建议将参数 cluster-require-full-coverage 配置为 no ,当主节点故障时只影响它负责槽的相关命令执行,不会影响其他主节点的可用性。
参考
- 《Redis 开发与运维》
- https://juejin.im/entry/593a498aac502e006ccd6656
- https://phachon.com/redis/redis-3.html
- http://kdf5000.com/2017/04/17/常见的几种Sharding策略/
Redis Cluster 的数据分片机制的更多相关文章
- Redis Cluster数据分片机制
复制粘贴自: https://www.e-learn.cn/content/redis/2344485, 点击链接访问原文 仅供个人学习参考之用, 如有侵权, 请联系删除! 高级开发不得不懂的Redi ...
- 高级开发不得不懂的Redis Cluster数据分片机制
Redis 集群简介 Redis Cluster 是 Redis 的分布式解决方案,在 3.0 版本正式推出,有效地解决了 Redis 分布式方面的需求. Redis Cluster 一般由多个节点组 ...
- redis(6)--redis集群之分片机制(redis-cluster)
Redis-Cluster 即使是使用哨兵,此时的Redis集群的每个数据库依然存有集群中的所有数据,从而导致集群的总数据存储量受限于可用存储内存最小的节点,形成了木桶效应.而因为Redis是基于内存 ...
- Redis Cluster架构和设计机制简单介绍
之前另一篇文章也介绍了 Redis Cluster (link,在文章的后半部分) 今天看到这一篇,简单说一下(http://hot66hot.iteye.com/blog/2050676) 作者的目 ...
- redis cluster异地数据迁移,扩容,缩容
由于项目的服务器分布在重庆,上海,台北,休斯顿,所以需要做异地容灾需求.当前的mysql,redis cluster,elastic search都在重庆的如果重庆停电了,整个应用都不能用了. 现在考 ...
- 开源|如何开发一个高性能的redis cluster proxy?
文|曹佳俊 网易智慧企业资深服务端开发工程师 背 景 redis cluster简介 Redis cluster是redis官方提供集群方案,设计上采用非中心化的架构,节点之间通过gossip协 ...
- 在 Istio 中实现 Redis 集群的数据分片、读写分离和流量镜像
Redis 是一个高性能的 key-value 存储系统,被广泛用于微服务架构中.如果我们想要使用 Redis 集群模式提供的高级特性,则需要对客户端代码进行改动,这带来了应用升级和维护的一些困难.利 ...
- Redis cluster集群模式的原理
redis cluster redis cluster是Redis的分布式解决方案,在3.0版本推出后有效地解决了redis分布式方面的需求 自动将数据进行分片,每个master上放一部分数据 提供内 ...
- Redis Cluster集群知识学习总结
Redis集群解决方案有两个: 1) Twemproxy: 这是Twitter推出的解决方案,简单的说就是上层加个代理负责分发,属于client端集群方案,目前很多应用者都在采用的解决方案.Twem ...
随机推荐
- Unittest框架的从零到壹(一)
前言 Python中有非常多的单元测试框架,如unittest.pytest.nose.doctest等,Python2.1及其以后的版本已经将unittest作为一个标准模块放入Python开发包中 ...
- 查看k8s中etcd数据
#查看etcd pod kubectl get pod -n kube-system | grep etcd #进入etcd pod kubectl exec -it -n kube-system e ...
- PHP与Python进行数据交互
最近,决定在一个项目用tp5进行APP接口开发,用Python做数据分析,然后这就面临一个问题:PHP和Python如何进行数据交互? 思路 我解决此问题的方法是利用了PHP的passthru函数来调 ...
- react 组件间通信,父子间通信
一.父组件传值给子组件 父组件向下传值是使用了props属性,在父组件定义的子组件上定义传给子组件的名字和值,然后在子组件通过this.props.xxx调用就可以了. 二.子组件传值给父组件 子组件 ...
- Oracle数据库索引
Oracle数据库索引 在关系数据库中,索引是一种与表有关的数据库结构,它可以使对应于表的SQL语句执行得更快.索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容. 对于数据库来说,索 ...
- webpackd学习的意义
高速发展的前端技术,与浏览器支持的不相匹配.导致前端必须把前端比较先进的技术进行一层编码从而使得浏览器可以加载. 比如前端框架Vue,Angular,React.Less,Sass.TypeScrip ...
- python json序列化与反序列化操作
python json序列化与反序列化操作 # dumps() dict-->str 序列化 # loads() str---dict 反序列化 result1 = json.dumps({'a ...
- P1055 ISBN号码
题目描述 每一本正式出版的图书都有一个ISBN号码与之对应,ISBN码包括99位数字.11位识别码和33位分隔符,其规定格式如x-xxx-xxxxx-x,其中符号-就是分隔符(键盘上的减号),最后一位 ...
- 【Android - 自定义View】之自定义可下拉刷新或上拉加载的ListView
首先来介绍一下这个自定义View: (1)这个自定义View的名称叫做 RefreshableListView ,继承自ListView类: (2)在这个自定义View中,用户可以设置是否支持下拉刷新 ...
- CentOS 7上利用systemctl添加自定义系统服务
Centos 7 之 systemctl CentOS 7继承了RHEL 7的新的特性,例如强大的systemctl,而systemctl的使用也使得以往系统服务的/etc/init.d的启动脚本的方 ...