Redis缓存策略
常用策略有“求留余数法”和“一致性HASH算法”
redis存储的是key,value键值对
一、求留余数法
使用HASH表数据长度对HASHCODE求余数,余数作为索引,使用该余数,直接设置或访问缓存。
计算key的HashCode
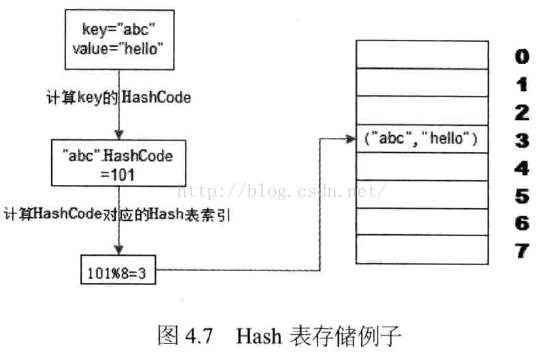
缺点:增加服务器,由于除数不一样了,之前缓存的数据都没办法访问了,即不支持热部署【扩展】
二、一致性HASH算法
一致性HASH算法通过一个叫做一致性HASH环的数据结构,实现KEY到缓存服务器的HASH映射。
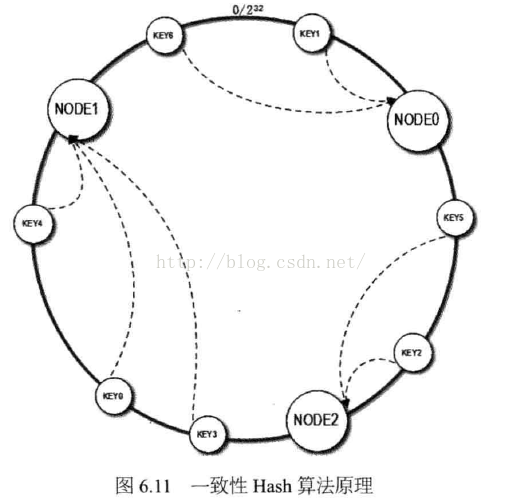
算法过程如下:
先构造一个0到232的整数环,然后将服务器节点的Hash值,放在该环上(可以理解为将你的ip做hash,将ip的HashCode放在环上)。然后根据需要缓存的数据的Key,计算Key的HashCode,然后在环上,顺时针查找距离这个Key的Hash值最近的缓存服务器的节点,然后将Value,存储到该服务器节点上。
这是当缓存服务器集群需要扩容的时候,只需要将新加入的节点的HashCode,放入一致性Hash环中,由于Key是顺时针查找距离最近的节点,因此,新加入的节点只影响整个环中的一小段。
请参见上图,如果我们新加入的服务器节点Node3,在Node1和Node2之间,如下图:
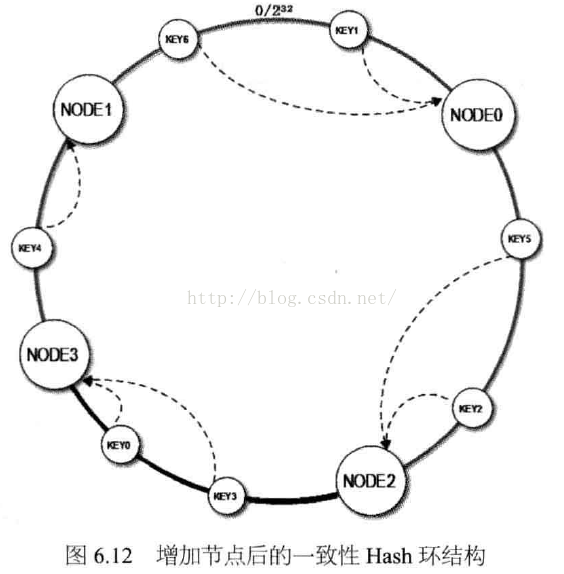
那么受影响的区域,只是Node2到Node3之间(顺时针)的缓存,此区间的缓存数据,加入节点之前是缓存在Node1上的,现在需要重新缓存到Node3上面。
具体应用中,这个长度为232的整数环,通常使用二叉查找树实现,Hash查找过程实际上是在二叉树中查找不小于查找树的最小值。当然,这个二叉树的最右边的叶子节点和最左边的叶子节点相连接,构成环。
通过上面的一致性Hash算法,就解决了分布式缓存集群中扩容的问题。然而上面的方法,仍然有问题。我们已经说过,上面的架构,只影响了Node2到Node3之间的区域(顺时针),那么Node3,也只是分摊了Node1节点的压力,而Node0和Node2的访问压力,并没有变化。也就是说:我们加入了硬件投入,却起到了很小的效果。
一致性Hash算法的进化版
所以说,我们还需要对上面的做法,进行改进。
上述问题是,一致性Hash算法带来的负载均衡不均衡。我们可以通过增加虚拟层来实现。
我们将每台缓存服务器,虚拟为一组虚拟缓存服务器,将虚拟服务器的Hash值,放置在Hash环上,Key在环上先找到虚拟服务器节点,再得到物理服务器的信息。
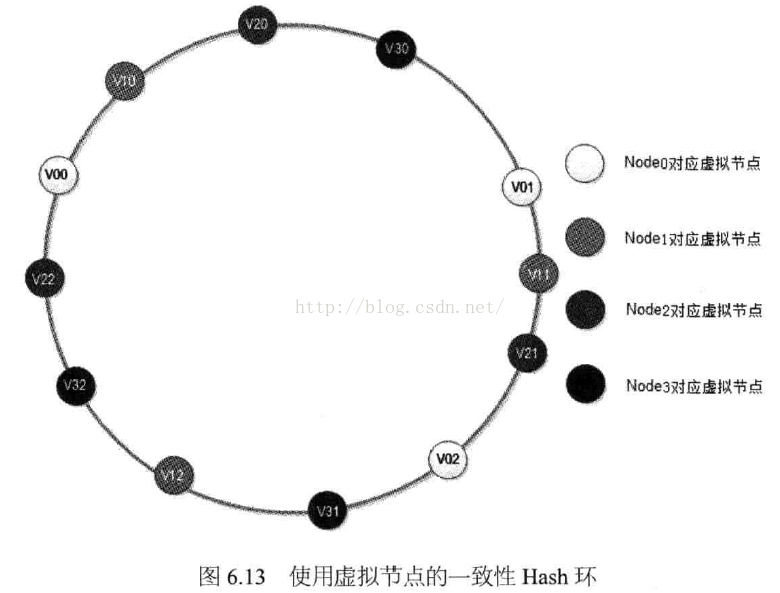
这样,一台服务器节点,被环中多个虚拟节点所代表,且多个节点均匀分配。很显然,每个物理节点对应的虚拟节点越多,各个物理节点之间的负载越均衡,新加入物理服务器对原有的物理服务器的影响越保持一致。
Redis缓存策略的更多相关文章
- redis 缓存策略
redis 缓存策略配置项:maxmemory <bytes>maxmemory-policy noeviction 触发时机:每次执行命令(processCommand)的时候会检测 w ...
- 转:Redis 缓存策略
转:http://api.crap.cn/index.do#/web/article/detail/web/ARTICLE/7754a002-6400-442d-8dc8-e76e72d948ac 目 ...
- Redis缓存策略设计及常见问题
Redis缓存设计及常见问题 缓存能够有效地加速应用的读写速度,同时也可以降低后端负载,对日常应用的开发至关重要.下面会介绍缓存使用技巧和设计方案,包含如下内容:缓存的收益和成本分析.缓存更新策略的选 ...
- mysql+redis缓存策略常见的错误
什么时候应该更新缓存 应该是从数据库读取数据后,再更新缓存,从缓存读取到数据,就不需要再重新写缓存了,一个常见的错误是,每次访问接口都更新缓存,这样的话,如果接口一直有流量,那么db中的数据,就一直没 ...
- 在Window系统中使用Redis缓存策略
Redis是一个用的比较广泛的Key/Value的内存数据库,新浪微博.Github.StackOverflow 等大型应用中都用其作为缓存,Redis的官网为http://redis.io/. 最近 ...
- Redis的缓存策略和主键失效机制
作为缓存系统都要定期清理无效数据,就需要一个主键失效和淘汰策略. >>EXPIRE主键失效机制 在Redis当中,有生存期的key被称为volatile,在创建缓存时,要为给定的key设置 ...
- 浅谈一下缓存策略以及memcached 、redis区别
缓存策略三要素:缓存命中率 缓存更新策略 最大缓存容量.衡量一个缓存方案的好坏标准是:缓存命中率.缓存命中率越高,缓存方法设计的越好. 三者之间的关系为:当缓存到达最大的缓存容量时,会触发缓存更 ...
- redis 缓存用户账单策略
最近项目要求分页展示用户账单列表,为提高响应使用redis做缓存,用到的缓存策略和大家分享一下. 需求描述:展示用户账单基本信息以时间倒序排序,筛选条件账单类型(所有,订单收入.提现.充值...). ...
- 缓存策略:redis缓存之springCache
最近通过同学,突然知道服务器的缓存有很多猫腻,这里通过网上查询其他人的资料,进行记录: 缓存策略 比较简单的缓存策略: 1.失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放 ...
随机推荐
- ORA-29861: 域索引标记为 LOADING/FAILED/UNUSABLE
解决方法:select idx_name,idx_status from ctxsys.ctx_indexes;需要重建同步全文索引:alter index 索引名 rebuild online ...
- vue模板语法下
样式绑定 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <titl ...
- go语言设计模式之adapter
adapter.go package adapter import ( "fmt" ) type LegacyPrinter interface { Print(s string) ...
- AtCoder Regular Contest 99
传送门 C - Minimization 第一次可能有多种选择,我们枚举所有的选择,然后两边贪心取即可. Code #include <bits/stdc++.h> #define MP ...
- JavaWeb 增删改查功能
1.今天来写一个简单的增删改查功能,这个项目还是接着在昨天写的 --JavaWeb实现简单登录注册-- 来写的. 登录成功进来后对学生信息的增删改查 2.项目文件为: 3.好了,直接贴上今天新写的代码 ...
- nui-app 笔记
https://uniapp.dcloud.io
- 深入Pytorch微分传参
导数 这段代码揭示了多个变量的微分以及如何求解loss为向量的导数 m1 = Variable(torch.ones((3,2)), requires_grad=True) m2 = Variable ...
- 实时聊天-websocket与ajax的区别于联系
Ajax是什么? Ajax,即异步JavaScript和XML,是一种创建交互式网页应用的网页开发技术.通过在后台与服务器进行少量数据交换,Ajax可以使网页实现异步更新,这意味着可以在不重新加载整 ...
- python做中学(二)bool()函数的用法
定义: bool() 函数用于将给定参数转换为布尔类型,如果没有参数,返回 False. bool 是 int 的子类. 语法: 以下是 bool() 方法的语法: class bool([x] 参数 ...
- pytorch-argparse的用法
import argparse def parse(): parser = argparse.ArgumentParser() parser.add_argument('--scales',help= ...