ucoreOS_lab6 实验报告
所有的实验报告将会在 Github 同步更新,更多内容请移步至Github:https://github.com/AngelKitty/review_the_national_post-graduate_entrance_examination/blob/master/books_and_notes/professional_courses/operating_system/sources/ucore_os_lab/docs/lab_report/
练习0:填写已有实验
lab6 会依赖 lab1~lab5 ,我们需要把做的 lab1~lab5 的代码填到 lab6 中缺失的位置上面。练习 0 就是一个工具的利用。这里我使用的是 Linux 下的系统已预装好的 Meld Diff Viewer 工具。和 lab5 操作流程一样,我们只需要将已经完成的 lab1~lab5 与待完成的 lab6 (由于 lab6 是基于 lab1~lab5 基础上完成的,所以这里只需要导入 lab5 )分别导入进来,然后点击 compare 就行了。
然后软件就会自动分析两份代码的不同,然后就一个个比较比较复制过去就行了,在软件里面是可以支持打开对比复制了,点击 Copy Right 即可。当然 bin 目录和 obj 目录下都是 make 生成的,就不用复制了,其他需要修改的地方主要有以下六个文件,通过对比复制完成即可:
proc.c
default_pmm.c
pmm.c
swap_fifo.c
vmm.c
trap.c
根据试验要求,我们需要对部分代码进行改进,这里讲需要改进的地方的代码和说明罗列如下:
- PCT 中增加了三个与 stride 调度算法相关的成员变量,以及增加了对应的初始化过程;
- 新增了斜堆数据结构的实现;
- 新增了默认的调度算法
Round Robin的实现,具体为调用sched_class_*等一系列函数之后,进一步调用调度器sched_class中封装的函数,默认该调度器为Round Robin调度器,这是在default_sched.*中定义的; - 新增了 set_priority,get_time 的系统调用;
proc_struct 结构体
我们在原来的实验基础上,新增了 9 行代码:
int exit_code; //退出码(发送到父进程)
uint32_t wait_state; //等待状态
struct proc_struct *cptr, *yptr, *optr; //进程间的一些关系
struct run_queue *rq; //运行队列中包含进程
list_entry_t run_link; //该进程的调度链表结构,该结构内部的连接组成了 运行队列 列表
int time_slice; //该进程剩余的时间片,只对当前进程有效
skew_heap_entry_t lab6_run_pool; //该进程在优先队列中的节点,仅在 LAB6 使用
uint32_t lab6_stride; //该进程的调度步进值,仅在 LAB6 使用
uint32_t lab6_priority; //该进程的调度优先级,仅在 LAB6 使用
所以改进后的 proc_struct 结构体如下:
struct proc_struct { //进程控制块
enum proc_state state; //进程状态
int pid; //进程ID
int runs; //运行时间
uintptr_t kstack; //内核栈位置
volatile bool need_resched; //是否需要调度,只对当前进程有效
struct proc_struct *parent; //父进程
struct mm_struct *mm; //进程的虚拟内存
struct context context; //进程上下文
struct trapframe *tf; //当前中断帧的指针
uintptr_t cr3; //当前页表地址
uint32_t flags; //进程
char name[PROC_NAME_LEN + 1]; //进程名字
list_entry_t list_link; //进程链表
list_entry_t hash_link; //进程哈希表
int exit_code; //退出码(发送到父进程)
uint32_t wait_state; //等待状态
struct proc_struct *cptr, *yptr, *optr; //进程间的一些关系
struct run_queue *rq; //运行队列中包含进程
list_entry_t run_link; //该进程的调度链表结构,该结构内部的连接组成了 运行队列 列表
int time_slice; //该进程剩余的时间片,只对当前进程有效
skew_heap_entry_t lab6_run_pool; //该进程在优先队列中的节点,仅在 LAB6 使用
uint32_t lab6_stride; //该进程的调度步进值,仅在 LAB6 使用
uint32_t lab6_priority; //该进程的调度优先级,仅在 LAB6 使用
};
alloc_proc() 函数
我们在原来的实验基础上,新增了 6 行代码:
proc->rq = NULL; //初始化运行队列为空
list_init(&(proc->run_link));//初始化运行队列的指针
proc->time_slice = 0; //初始化时间片
proc->lab6_run_pool.left = proc->lab6_run_pool.right = proc->lab6_run_pool.parent = NULL;//初始化各类指针为空,包括父进程等待
proc->lab6_stride = 0;//设置步长为0
proc->lab6_priority = 0;//设置优先级为0
所以改进后的 alloc_proc 函数如下:
// alloc_proc - alloc a proc_struct and init all fields of proc_struct
static struct proc_struct *alloc_proc(void) {
struct proc_struct *proc = kmalloc(sizeof(struct proc_struct));
if (proc != NULL) {
proc->state = PROC_UNINIT; //设置进程为未初始化状态
proc->pid = -1; //未初始化的的进程id为-1
proc->runs = 0; //初始化时间片
proc->kstack = 0; //内存栈的地址
proc->need_resched = 0; //是否需要调度设为不需要
proc->parent = NULL; //父节点设为空
proc->mm = NULL; //虚拟内存设为空
memset(&(proc->context), 0, sizeof(struct context));//上下文的初始化
proc->tf = NULL; //中断帧指针置为空
proc->cr3 = boot_cr3; //页目录设为内核页目录表的基址
proc->flags = 0; //标志位
memset(proc->name, 0, PROC_NAME_LEN);//进程名
proc->wait_state = 0;//PCB 进程控制块中新增的条目,初始化进程等待状态
proc->cptr = proc->optr = proc->yptr = NULL;//进程相关指针初始化
proc->rq = NULL;//初始化运行队列为空
list_init(&(proc->run_link));
proc->time_slice = 0;//初始化时间片
proc->lab6_run_pool.left = proc->lab6_run_pool.right = proc->lab6_run_pool.parent = NULL;//初始化指针为空
proc->lab6_stride = 0;//设置步长为 0
proc->lab6_priority = 0;//设置优先级为 0
}
return proc;
}
trap_dispatch() 函数
我们在原来的实验基础上,新增了 1 行代码:
run_timer_list(); //更新定时器,并根据参数调用调度算法
这里主要是将时间片设置为需要调度,说明当前进程的时间片已经用完了。
所以改进后的 trap_dispatch 函数如下:
static void trap_dispatch(struct trapframe *tf) {
......
......
ticks ++;
assert(current != NULL);
run_timer_list(); //更新定时器,并根据参数调用调度算法
break;
......
......
}
练习1: 使用 Round Robin 调度算法(不需要编码)
Round Robin 调度算法的调度思想是让所有 runnable 态的进程分时轮流使用 CPU 时间。Round Robin 调度器维护当前 runnable 进程的有序运行队列。当前进程的时间片用完之后,调度器将当前进程放置到运行队列的尾部,再从其头部取出进程进行调度。
在这个理解的基础上,我们来分析算法的具体实现。
这里 Round Robin 调度算法的主要实现在 default_sched.c 之中,源码如下:
/*
file_path = kern/schedule/default_sched.c
*/
//RR_init函数:这个函数被封装为 sched_init 函数,用于调度算法的初始化,使用grep命令可以知道,该函数仅在 ucore 入口的 init.c 里面被调用进行初始化
static void RR_init(struct run_queue *rq) { //初始化进程队列
list_init(&(rq->run_list));//初始化运行队列
rq->proc_num = 0;//初始化进程数为 0
}
//RR_enqueue函数:该函数的功能为将指定的进程的状态置成 RUNNABLE,并且放入调用算法中的可执行队列中,被封装成 sched_class_enqueue 函数,可以发现这个函数仅在 wakeup_proc 和 schedule 函数中被调用,前者为将某个不是 RUNNABLE 的进程加入可执行队列,而后者是将正在执行的进程换出到可执行队列中去
static void RR_enqueue(struct run_queue *rq, struct proc_struct *proc) {//将进程加入就绪队列
assert(list_empty(&(proc->run_link)));//进程控制块指针非空
list_add_before(&(rq->run_list), &(proc->run_link));//把进程的进程控制块指针放入到 rq 队列末尾
if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice) {//进程控制块的时间片为 0 或者进程的时间片大于分配给进程的最大时间片
proc->time_slice = rq->max_time_slice;//修改时间片
}
proc->rq = rq;//加入进程池
rq->proc_num ++;//就绪进程数加一
}
//RR_dequeue 函数:该函数的功能为将某个在队列中的进程取出,其封装函数 sched_class_dequeue 仅在 schedule 中被调用,表示将调度算法选择的进程从等待的可执行的进程队列中取出进行执行
static void RR_dequeue(struct run_queue *rq, struct proc_struct *proc) {//将进程从就绪队列中移除
assert(!list_empty(&(proc->run_link)) && proc->rq == rq);//进程控制块指针非空并且进程在就绪队列中
list_del_init(&(proc->run_link));//将进程控制块指针从就绪队列中删除
rq->proc_num --;//就绪进程数减一
}
//RR_pick_next 函数:该函数的封装函数同样仅在 schedule 中被调用,功能为选择要执行的下个进程
static struct proc_struct *RR_pick_next(struct run_queue *rq) {//选择下一调度进程
list_entry_t *le = list_next(&(rq->run_list));//选取就绪进程队列 rq 中的队头队列元素
if (le != &(rq->run_list)) {//取得就绪进程
return le2proc(le, run_link);//返回进程控制块指针
}
return NULL;
}
//RR_proc_tick 函数:该函数表示每次时钟中断的时候应当调用的调度算法的功能,仅在进行时间中断的 ISR 中调用
static void RR_proc_tick(struct run_queue *rq, struct proc_struct *proc) {//时间片
if (proc->time_slice > 0) {//到达时间片
proc->time_slice --;//执行进程的时间片 time_slice 减一
}
if (proc->time_slice == 0) {//时间片为 0
proc->need_resched = 1;//设置此进程成员变量 need_resched 标识为 1,进程需要调度
}
}
//sched_class 定义一个 c 语言类的实现,提供调度算法的切换接口
struct sched_class default_sched_class = {
.name = "RR_scheduler",
.init = RR_init,
.enqueue = RR_enqueue,
.dequeue = RR_dequeue,
.pick_next = RR_pick_next,
.proc_tick = RR_proc_tick,
};
现在我们来逐个函数的分析,从而了解 Round Robin 调度算法的原理。
首先是 RR_init 函数,函数完成了对进程队列的初始化。
//RR_init函数:这个函数被封装为 sched_init 函数,用于调度算法的初始化,使用grep命令可以知道,该函数仅在 ucore 入口的 init.c 里面被调用进行初始化
static void RR_init(struct run_queue *rq) { //初始化进程队列
list_init(&(rq->run_list));//初始化运行队列
rq->proc_num = 0;//初始化进程数为 0
}
其中的 run_queue 结构体如下:
struct run_queue {
list_entry_t run_list;//其运行队列的哨兵结构,可以看作是队列头和尾
unsigned int proc_num;//内部进程总数
int max_time_slice;//每个进程一轮占用的最多时间片
// For LAB6 ONLY
skew_heap_entry_t *lab6_run_pool;//优先队列形式的进程容器
};
而 run_queue 结构体中的 skew_heap_entry 结构体如下:
struct skew_heap_entry {
struct skew_heap_entry *parent, *left, *right;//树形结构的进程容器
};
typedef struct skew_heap_entry skew_heap_entry_t;
然后是 RR_enqueue 函数,首先,它把进程的进程控制块指针放入到 rq 队列末尾,且如果进程控制块的时间片为 0,则需要把它重置为 max_time_slice。这表示如果进程在当前的执行时间片已经用完,需要等到下一次有机会运行时,才能再执行一段时间。然后在依次调整 rq 和 rq 的进程数目加一。
//RR_enqueue函数:该函数的功能为将指定的进程的状态置成 RUNNABLE,并且放入调用算法中的可执行队列中,被封装成 sched_class_enqueue 函数,可以发现这个函数仅在 wakeup_proc 和 schedule 函数中被调用,前者为将某个不是 RUNNABLE 的进程加入可执行队列,而后者是将正在执行的进程换出到可执行队列中去
static void RR_enqueue(struct run_queue *rq, struct proc_struct *proc) {//将进程加入就绪队列
assert(list_empty(&(proc->run_link)));//进程控制块指针非空
list_add_before(&(rq->run_list), &(proc->run_link));//把进程的进程控制块指针放入到 rq 队列末尾
if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice) {//进程控制块的时间片为 0 或者进程的时间片大于分配给进程的最大时间片
proc->time_slice = rq->max_time_slice;//修改时间片
}
proc->rq = rq;//加入进程池
rq->proc_num ++;//就绪进程数加一
}
然后是 RR_dequeue 函数,它简单的把就绪进程队列 rq 的进程控制块指针的队列元素删除,然后使就绪进程个数的proc_num减一。
//RR_dequeue 函数:该函数的功能为将某个在队列中的进程取出,其封装函数 sched_class_dequeue 仅在 schedule 中被调用,表示将调度算法选择的进程从等待的可执行的进程队列中取出进行执行
static void RR_dequeue(struct run_queue *rq, struct proc_struct *proc) {//将进程从就绪队列中移除
assert(!list_empty(&(proc->run_link)) && proc->rq == rq);//进程控制块指针非空并且进程在就绪队列中
list_del_init(&(proc->run_link));//将进程控制块指针从就绪队列中删除
rq->proc_num --;//就绪进程数减一
}
接下来是 RR_pick_next 函数,即选取函数。它选取就绪进程队列 rq 中的队头队列元素,并把队列元素转换成进程控制块指针,即置为当前占用 CPU 的程序。
//RR_pick_next 函数:该函数的封装函数同样仅在 schedule 中被调用,功能为选择要执行的下个进程
static struct proc_struct *RR_pick_next(struct run_queue *rq) {//选择下一调度进程
list_entry_t *le = list_next(&(rq->run_list));//选取就绪进程队列 rq 中的队头队列元素
if (le != &(rq->run_list)) {//取得就绪进程
return le2proc(le, run_link);//返回进程控制块指针
}
return NULL;
}
最后是 RR_proc_tick,它每一次时间片到时的时候,当前执行进程的时间片 time_slice 便减一。如果 time_slice 降到零,则设置此进程成员变量 need_resched 标识为 1,这样在下一次中断来后执行 trap 函数时,会由于当前进程程成员变量 need_resched 标识为 1 而执行 schedule 函数,从而把当前执行进程放回就绪队列末尾,而从就绪队列头取出在就绪队列上等待时间最久的那个就绪进程执行。
//RR_proc_tick 函数:该函数表示每次时钟中断的时候应当调用的调度算法的功能,仅在进行时间中断的 ISR 中调用
static void RR_proc_tick(struct run_queue *rq, struct proc_struct *proc) {//时间片
if (proc->time_slice > 0) {//到达时间片
proc->time_slice --;//执行进程的时间片 time_slice 减一
}
if (proc->time_slice == 0) {//时间片为 0
proc->need_resched = 1;//设置此进程成员变量 need_resched 标识为 1,进程需要调度
}
}
sched_class 定义一个 c 语言类的实现,提供调度算法的切换接口。
struct sched_class default_sched_class = {
.name = "RR_scheduler",
.init = RR_init,
.enqueue = RR_enqueue,
.dequeue = RR_dequeue,
.pick_next = RR_pick_next,
.proc_tick = RR_proc_tick,
};
请理解并分析 sched_calss 中各个函数指针的用法,并结合 Round Robin 调度算法描述 ucore 的调度执行过程;
首先我们可以查看一下 sched_class 类中的内容:
struct sched_class {
const char *name;// 调度器的名字
void (*init) (struct run_queue *rq);// 初始化运行队列
void (*enqueue) (struct run_queue *rq, struct proc_struct *p);// 将进程 p 插入队列 rq
void (*dequeue) (struct run_queue *rq, struct proc_struct *p);// 将进程 p 从队列 rq 中删除
struct proc_struct* (*pick_next) (struct run_queue *rq);// 返回运行队列中下一个可执行的进程
void (*proc_tick)(struct run_queue* rq, struct proc_struct* p);// timetick 处理函数
};
接下来我们结合具体算法来描述一下 ucore 调度执行过程:
- 在ucore中调用调度器的主体函数(不包括 init,proc_tick)的代码仅存在在 wakeup_proc 和 schedule,前者的作用在于将某一个指定进程放入可执行进程队列中,后者在于将当前执行的进程放入可执行队列中,然后将队列中选择的下一个执行的进程取出执行;
- 当需要将某一个进程加入就绪进程队列中,则需要将这个进程的能够使用的时间片进行初始化,然后将其插入到使用链表组织的队列的对尾;这就是具体的 Round-Robin enqueue 函数的实现;
- 当需要将某一个进程从就绪队列中取出的时候,只需要将其直接删除即可;
- 当需要取出执行的下一个进程的时候,只需要将就绪队列的队头取出即可;
- 每当出现一个时钟中断,则会将当前执行的进程的剩余可执行时间减 1,一旦减到了 0,则将其标记为可以被调度的,这样在 ISR 中的后续部分就会调用 schedule 函数将这个进程切换出去;
请在实验报告中简要说明如何设计实现”多级反馈队列调度算法“,给出概要设计,鼓励给出详细设计;
设计如下:
- 在 proc_struct 中添加总共 N 个多级反馈队列的入口,每个队列都有着各自的优先级,编号越大的队列优先级约低,并且优先级越低的队列上时间片的长度越大,为其上一个优先级队列的两倍;并且在 PCB 中记录当前进程所处的队列的优先级;
- 处理调度算法初始化的时候需要同时对 N 个队列进行初始化;
- 在处理将进程加入到就绪进程集合的时候,观察这个进程的时间片有没有使用完,如果使用完了,就将所在队列的优先级调低,加入到优先级低 1 级的队列中去,如果没有使用完时间片,则加入到当前优先级的队列中去;
- 在同一个优先级的队列内使用时间片轮转算法;
- 在选择下一个执行的进程的时候,有限考虑高优先级的队列中是否存在任务,如果不存在才转而寻找较低优先级的队列;(有可能导致饥饿)
- 从就绪进程集合中删除某一个进程就只需要在对应队列中删除即可;
- 处理时间中断的函数不需要改变;
至此完成了多级反馈队列调度算法的具体设计;
练习2: 实现 Stride Scheduling 调度算法(需要编码)
首先,根据实验指导书的要求,先用 default_sched_stride_c 覆盖 default_sched.c,即覆盖掉 Round Robin 调度算法的实现。
覆盖掉之后需要在该框架上实现 Stride Scheduling 调度算法。
关于 Stride Scheduling 调度算法,经过查阅资料和实验指导书,我们可以简单的把思想归结如下:
- 1、为每个 runnable 的进程设置一个当前状态 stride,表示该进程当前的调度权。另外定义其对应的 pass 值,表示对应进程在调度后,stride 需要进行的累加值。
- 2、每次需要调度时,从当前 runnable 态的进程中选择 stride 最小的进程调度。对于获得调度的进程 P,将对应的 stride 加上其对应的步长 pass(只与进程的优先权有关系)。
- 3、在一段固定的时间之后,回到步骤 2,重新调度当前 stride 最小的进程。
接下来针对代码我们逐步分析,首先完整代码如下:
* 实现思路:
由于在 ucore 中使用面向对象编程的思想,将所有与调度算法相关的函数封装在了调度器 sched_class 中,因此其实可以不需要覆盖掉 default_sched.c,只需要将 default_sched_stride_c 改名成 default_sched_stride.c,然后注释掉 default_sched.c 中的 sched_class 的定义,这样由于 default_sched_stride.c 中也有 sched_class 的定义,其他代码在调用调度器的接口的时候就直接调用了新实现的 Stride Scheduling 算法实现的函数了;
--------------------------------------------------------------------------------------------
/*
file_path = kern/schedule/default_sched.c
*/
/*code*/
#include <defs.h>
#include <list.h>
#include <proc.h>
#include <assert.h>
#include <default_sched.h>
#define USE_SKEW_HEAP 1
/* You should define the BigStride constant here*/
/* LAB6: YOUR CODE */
#define BIG_STRIDE 0x7FFFFFFF /* ??? */
/* The compare function for two skew_heap_node_t's and the
* corresponding procs*/
//proc_stride_comp_f:优先队列的比较函数,主要思路就是通过步数相减,然后根据其正负比较大小关系
static int proc_stride_comp_f(void *a, void *b)
{
struct proc_struct *p = le2proc(a, lab6_run_pool);//通过进程控制块指针取得进程 a
struct proc_struct *q = le2proc(b, lab6_run_pool);//通过进程控制块指针取得进程 b
int32_t c = p->lab6_stride - q->lab6_stride;//步数相减,通过正负比较大小关系
if (c > 0) return 1;
else if (c == 0) return 0;
else return -1;
}
/*
* stride_init initializes the run-queue rq with correct assignment for
* member variables, including:
*
* - run_list: should be a empty list after initialization.
* - lab6_run_pool: NULL
* - proc_num: 0
* - max_time_slice: no need here, the variable would be assigned by the caller.
*
* hint: see proj13.1/libs/list.h for routines of the list structures.
*/
//stride_init:进行调度算法初始化的函数,在本 stride 调度算法的实现中使用了斜堆来实现优先队列,因此需要对相应的成员变量进行初始化
static void stride_init(struct run_queue *rq) {
/* LAB6: YOUR CODE */
list_init(&(rq->run_list));//初始化调度器类
rq->lab6_run_pool = NULL;//对斜堆进行初始化,表示有限队列为空
rq->proc_num = 0;//设置运行队列为空
}
/*
* stride_enqueue inserts the process ``proc'' into the run-queue
* ``rq''. The procedure should verify/initialize the relevant members
* of ``proc'', and then put the ``lab6_run_pool'' node into the
* queue(since we use priority queue here). The procedure should also
* update the meta date in ``rq'' structure.
*
* proc->time_slice denotes the time slices allocation for the
* process, which should set to rq->max_time_slice.
*
* hint: see proj13.1/libs/skew_heap.h for routines of the priority
* queue structures.
*/
//stride_enqeue:在将指定进程加入就绪队列的时候,需要调用斜堆的插入函数将其插入到斜堆中,然后对时间片等信息进行更新
static void stride_enqueue(struct run_queue *rq, struct proc_struct *proc) {
/* LAB6: YOUR CODE */
#if USE_SKEW_HEAP
rq->lab6_run_pool = skew_heap_insert(rq->lab6_run_pool, &(proc->lab6_run_pool), proc_stride_comp_f);//将新的进程插入到表示就绪队列的斜堆中,该函数的返回结果是斜堆的新的根
#else
assert(list_empty(&(proc->run_link)));
list_add_before(&(rq->run_list), &(proc->run_link));
#endif
if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice) {
proc->time_slice = rq->max_time_slice;//将该进程剩余时间置为时间片大小
}
proc->rq = rq;//更新进程的就绪队列
rq->proc_num ++;//维护就绪队列中进程的数量加一
}
/*
* stride_dequeue removes the process ``proc'' from the run-queue
* ``rq'', the operation would be finished by the skew_heap_remove
* operations. Remember to update the ``rq'' structure.
*
* hint: see proj13.1/libs/skew_heap.h for routines of the priority
* queue structures.
*/
//stride_dequeue:将指定进程从就绪队列中删除,只需要将该进程从斜堆中删除掉即可
static void stride_dequeue(struct run_queue *rq, struct proc_struct *proc) {
/* LAB6: YOUR CODE */
#if USE_SKEW_HEAP
rq->lab6_run_pool = skew_heap_remove(rq->lab6_run_pool, &(proc->lab6_run_pool), proc_stride_comp_f);//删除斜堆中的指定进程
#else
assert(!list_empty(&(proc->run_link)) && proc->rq == rq);
list_del_init(&(proc->run_link));
#endif
rq->proc_num --;//维护就绪队列中的进程总数
}
/*
* stride_pick_next pick the element from the ``run-queue'', with the
* minimum value of stride, and returns the corresponding process
* pointer. The process pointer would be calculated by macro le2proc,
* see proj13.1/kern/process/proc.h for definition. Return NULL if
* there is no process in the queue.
*
* When one proc structure is selected, remember to update the stride
* property of the proc. (stride += BIG_STRIDE / priority)
*
* hint: see proj13.1/libs/skew_heap.h for routines of the priority
* queue structures.
*/
//stride_pick_next: 选择下一个要执行的进程,根据stride算法,只需要选择stride值最小的进程,即斜堆的根节点对应的进程即可
static struct proc_struct *stride_pick_next(struct run_queue *rq) {
/* LAB6: YOUR CODE */
#if USE_SKEW_HEAP
if (rq->lab6_run_pool == NULL) return NULL;
struct proc_struct *p = le2proc(rq->lab6_run_pool, lab6_run_pool);//选择 stride 值最小的进程
#else
list_entry_t *le = list_next(&(rq->run_list));
if (le == &rq->run_list)
return NULL;
struct proc_struct *p = le2proc(le, run_link);
le = list_next(le);
while (le != &rq->run_list)
{
struct proc_struct *q = le2proc(le, run_link);
if ((int32_t)(p->lab6_stride - q->lab6_stride) > 0)
p = q;
le = list_next(le);
}
#endif
if (p->lab6_priority == 0)//优先级为 0
p->lab6_stride += BIG_STRIDE;//步长设置为最大值
else p->lab6_stride += BIG_STRIDE / p->lab6_priority;//步长设置为优先级的倒数,更新该进程的 stride 值
return p;
}
/*
* stride_proc_tick works with the tick event of current process. You
* should check whether the time slices for current process is
* exhausted and update the proc struct ``proc''. proc->time_slice
* denotes the time slices left for current
* process. proc->need_resched is the flag variable for process
* switching.
*/
//stride_proc_tick:每次时钟中断需要调用的函数,仅在进行时间中断的ISR中调用
static void stride_proc_tick(struct run_queue *rq, struct proc_struct *proc) {
/* LAB6: YOUR CODE */
if (proc->time_slice > 0) {//到达时间片
proc->time_slice --;//执行进程的时间片 time_slice 减一
}
if (proc->time_slice == 0) {//时间片为 0
proc->need_resched = 1;//设置此进程成员变量 need_resched 标识为 1,进程需要调度
}
}
//sched_class 定义一个 c 语言类的实现,提供调度算法的切换接口
struct sched_class default_sched_class = {
.name = "stride_scheduler",
.init = stride_init,
.enqueue = stride_enqueue,
.dequeue = stride_dequeue,
.pick_next = stride_pick_next,
.proc_tick = stride_proc_tick,
};
相比于 RR 调度,Stride Scheduling 函数定义了一个比较器 proc_stride_comp_f。优先队列的比较函数 proc_stride_comp_f 的实现,主要思路就是通过步数相减,然后根据其正负比较大小关系。
//proc_stride_comp_f:优先队列的比较函数,主要思路就是通过步数相减,然后根据其正负比较大小关系
static int proc_stride_comp_f(void *a, void *b)
{
struct proc_struct *p = le2proc(a, lab6_run_pool);//通过进程控制块指针取得进程 a
struct proc_struct *q = le2proc(b, lab6_run_pool);//通过进程控制块指针取得进程 b
int32_t c = p->lab6_stride - q->lab6_stride;//步数相减,通过正负比较大小关系
if (c > 0) return 1;
else if (c == 0) return 0;
else return -1;
}
同样的,我们来逐个函数的分析,从而了解 Stride Scheduling 调度算法的原理。
首先是 stride_init 函数,开始初始化运行队列,并初始化当前的运行队,然后设置当前运行队列内进程数目为0。
//stride_init:进行调度算法初始化的函数,在本 stride 调度算法的实现中使用了斜堆来实现优先队列,因此需要对相应的成员变量进行初始化
static void stride_init(struct run_queue *rq) {
/* LAB6: YOUR CODE */
list_init(&(rq->run_list));//初始化调度器类
rq->lab6_run_pool = NULL;//对斜堆进行初始化,表示有限队列为空
rq->proc_num = 0;//设置运行队列为空
}
然后是入队函数 stride_enqueue,根据之前对该调度算法的分析,这里函数主要是初始化刚进入运行队列的进程 proc 的 stride 属性,然后比较队头元素与当前进程的步数大小,选择步数最小的运行,即将其插入放入运行队列中去,这里并未放置在队列头部。最后初始化时间片,然后将运行队列进程数目加一。
//stride_enqeue:在将指定进程加入就绪队列的时候,需要调用斜堆的插入函数将其插入到斜堆中,然后对时间片等信息进行更新
static void stride_enqueue(struct run_queue *rq, struct proc_struct *proc) {
/* LAB6: YOUR CODE */
#if USE_SKEW_HEAP
rq->lab6_run_pool = skew_heap_insert(rq->lab6_run_pool, &(proc->lab6_run_pool), proc_stride_comp_f);//将新的进程插入到表示就绪队列的斜堆中,该函数的返回结果是斜堆的新的根
#else
assert(list_empty(&(proc->run_link)));
list_add_before(&(rq->run_list), &(proc->run_link));
#endif
if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice) {
proc->time_slice = rq->max_time_slice;//将该进程剩余时间置为时间片大小
}
proc->rq = rq;//更新进程的就绪队列
rq->proc_num ++;//维护就绪队列中进程的数量加一
}
里面有一个条件编译:
#if USE_SKEW_HEAP
rq->lab6_run_pool = skew_heap_insert(rq->lab6_run_pool, &(proc->lab6_run_pool), proc_stride_comp_f);//将新的进程插入到表示就绪队列的斜堆中,该函数的返回结果是斜堆的新的根
#else
assert(list_empty(&(proc->run_link)));
list_add_before(&(rq->run_list), &(proc->run_link));
#endif
在 ucore 中 USE_SKEW_HEAP 定义为 1 ,因此 #else 与 #endif 之间的代码将会被忽略。
其中的 skew_heap_insert 函数如下:
static inline skew_heap_entry_t *skew_heap_insert(skew_heap_entry_t *a, skew_heap_entry_t *b, compare_f comp)
{
skew_heap_init(b); //初始化进程b
return skew_heap_merge(a, b, comp);//返回a与b进程结合的结果
}
函数中的 skew_heap_init 函数如下:
static inline void skew_heap_init(skew_heap_entry_t *a)
{
a->left = a->right = a->parent = NULL; //初始化相关指针
}
函数中的 skew_heap_merge 函数如下:
static inline skew_heap_entry_t *skew_heap_merge(skew_heap_entry_t *a, skew_heap_entry_t *b, compare_f comp)
{
if (a == NULL) return b;
else if (b == NULL) return a;
skew_heap_entry_t *l, *r;
if (comp(a, b) == -1) //a进程的步长小于b进程
{
r = a->left; //a的左指针为r
l = skew_heap_merge(a->right, b, comp);
a->left = l;
a->right = r;
if (l) l->parent = a;
return a;
}
else
{
r = b->left;
l = skew_heap_merge(a, b->right, comp);
b->left = l;
b->right = r;
if (l) l->parent = b;
return b;
}
}
然后是出队函数 stride_dequeue,即完成将一个进程从队列中移除的功能,这里使用了优先队列。最后运行队列数目减一。
//stride_dequeue:将指定进程从就绪队列中删除,只需要将该进程从斜堆中删除掉即可
static void stride_dequeue(struct run_queue *rq, struct proc_struct *proc) {
/* LAB6: YOUR CODE */
#if USE_SKEW_HEAP
rq->lab6_run_pool = skew_heap_remove(rq->lab6_run_pool, &(proc->lab6_run_pool), proc_stride_comp_f);//删除斜堆中的指定进程
#else
assert(!list_empty(&(proc->run_link)) && proc->rq == rq);
list_del_init(&(proc->run_link));
#endif
rq->proc_num --;//维护就绪队列中的进程总数
}
里面的代码比较简单,只有一个主要函数 :skew_heap_remove。该函数实现过程如下:
static inline skew_heap_entry_t *skew_heap_remove(skew_heap_entry_t *a, skew_heap_entry_t *b, compare_f comp)
{
skew_heap_entry_t *p = b->parent;
skew_heap_entry_t *rep = skew_heap_merge(b->left, b->right, comp);
if (rep) rep->parent = p;
if (p)
{
if (p->left == b)
p->left = rep;
else p->right = rep;
return a;
}
else return rep;
}
接下来就是进程的选择调度函数 stride_pick_next。观察代码,它的核心是先扫描整个运行队列,返回其中 stride 值最小的对应进程,然后更新对应进程的 stride 值,将步长设置为优先级的倒数,如果为 0 则设置为最大的步长。
//stride_pick_next: 选择下一个要执行的进程,根据stride算法,只需要选择stride值最小的进程,即斜堆的根节点对应的进程即可
static struct proc_struct *stride_pick_next(struct run_queue *rq) {
/* LAB6: YOUR CODE */
#if USE_SKEW_HEAP
if (rq->lab6_run_pool == NULL) return NULL;
struct proc_struct *p = le2proc(rq->lab6_run_pool, lab6_run_pool);//选择 stride 值最小的进程
#else
list_entry_t *le = list_next(&(rq->run_list));
if (le == &rq->run_list)
return NULL;
struct proc_struct *p = le2proc(le, run_link);
le = list_next(le);
while (le != &rq->run_list)
{
struct proc_struct *q = le2proc(le, run_link);
if ((int32_t)(p->lab6_stride - q->lab6_stride) > 0)
p = q;
le = list_next(le);
}
#endif
if (p->lab6_priority == 0)//优先级为 0
p->lab6_stride += BIG_STRIDE;//步长设置为最大值
else p->lab6_stride += BIG_STRIDE / p->lab6_priority;//步长设置为优先级的倒数,更新该进程的 stride 值
return p;
}
最后是时间片函数 stride_proc_tick,主要工作是检测当前进程是否已用完分配的时间片。如果时间片用完,应该正确设置进程结构的相关标记来引起进程切换。这里和之前实现的 Round Robin 调度算法一样。
//stride_proc_tick:每次时钟中断需要调用的函数,仅在进行时间中断的ISR中调用
static void stride_proc_tick(struct run_queue *rq, struct proc_struct *proc) {
/* LAB6: YOUR CODE */
if (proc->time_slice > 0) {//到达时间片
proc->time_slice --;//执行进程的时间片 time_slice 减一
}
if (proc->time_slice == 0) {//时间片为 0
proc->need_resched = 1;//设置此进程成员变量 need_resched 标识为 1,进程需要调度
}
}
sched_class 定义一个 c 语言类的实现,提供调度算法的切换接口。
struct sched_class default_sched_class = {
.name = "stride_scheduler",
.init = stride_init,
.enqueue = stride_enqueue,
.dequeue = stride_dequeue,
.pick_next = stride_pick_next,
.proc_tick = stride_proc_tick,
};
如何证明STRIDE_MAX – STRIDE_MIN <= PASS_MAX?
假如该命题不成立,则可以知道就绪队列在上一次找出用于执行的进程的时候,假如选择的进程是 P,那么存在另外一个就绪的进程 P',并且有 P' 的 stride 比 P 严格地小,这也就说明上一次调度出了问题,这和 stride 算法的设计是相违背的;因此通过反证法证明了上述命题的成立;
在 ucore 中,目前 Stride 是采用无符号的32位整数表示。则 BigStride 应该取多少,才能保证比较的正确性?
需要保证
注:BIG_STRIDE 的值是怎么来的?
Stride 调度算法的思路是每次找 stride 步进值最小的进程,每个进程每次执行完以后,都要在 stride步进 += pass步长,其中步长是和优先级成反比的因此步长可以反映出进程的优先级。但是随着每次调度,步长不断增加,有可能会有溢出的风险。
因此,需要设置一个步长的最大值,使得他们哪怕溢出,还是能够进行比较。
在 ucore 中,BIG_STRIDE 的值是采用无符号 32 位整数表示,而 stride 也是无符号 32 位整数。也就是说,最大值只能为 。
如果一个 进程的 stride 已经为 时,那么再加上 pass 步长一定会溢出,然后又从 0 开始算,这样,整个调度算法的比较就没有意义了。
这说明,我们必须得约定一个最大的步长,使得两个进程的步进值哪怕其中一个溢出或者都溢出还能够进行比较。
首先 因为 步长 和 优先级成反比 可以得到一条:pass = BIG_STRIDE / priority <= BIG_STRIDE
进而得到:pass_max <= BIG_STRIDE
最大步长 - 最小步长 一定小于等于步长:max_stride - min_stride <= pass_max
所以得出:max_stride - min_stride <= BIG_STRIDE
前面说了 ucore 中 BIG_STRIDE 用的无符号 32 位整数,最大值只能为
而又因为是无符号的,因此,最小只能为 0,而且我们需要把 32 位无符号整数进行比较,需要保证任意两个进程 stride 的差值在 32 位有符号数能够表示的范围之内,故 BIG_STRIDE 为 。
最终的实验结果如下图所示:
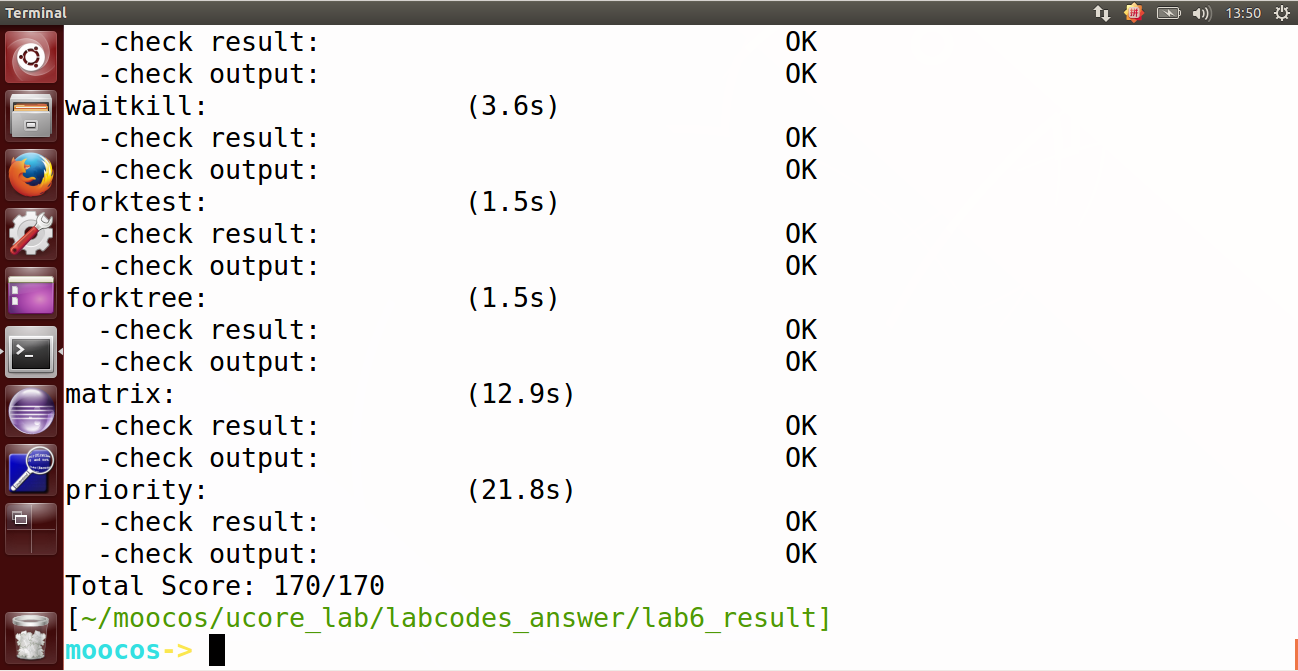
如果 make grade 无法满分,尝试注释掉 tools/grade.sh 的 221 行到 233 行(在前面加上“#”)。
这里我们选用古老的编辑器 Vim,具体操作过程如下:
- 1、首先按 esc 进入命令行模式下,按下
:221跳转至 221 行; - 2、按下 Ctrl + v,进入列(也叫区块)模式;
- 3、在行首使用上下键选择需要注释的多行(221~233 行);
- 4、按下键盘(大写)“I”键,进入插入模式;
- 5、然后输入注释符(“//”、“#”等);
- 6、最后按下“Esc”键。
扩展练习
Challenge 1 :实现 Linux 的 CFS 调度算法
CFS 算法的基本思路就是尽量使得每个进程的运行时间相同,所以需要记录每个进程已经运行的时间:
struct proc_struct {
...
int fair_run_time; // FOR CFS ONLY: run time
};
每次调度的时候,选择已经运行时间最少的进程。所以,也就需要一个数据结构来快速获得最少运行时间的进程, CFS 算法选择的是红黑树,但是项目中的斜堆也可以实现,只是性能不及红黑树。CFS是对于优先级的实现方法就是让优先级低的进程的时间过得很快。
数据结构
首先需要在 run_queue 增加一个斜堆:
struct run_queue {
...
skew_heap_entry_t *fair_run_pool;
};
在 proc_struct 中增加三个成员:
- 虚拟运行时间
- 优先级系数:从 1 开始,数值越大,时间过得越快
- 斜堆
struct proc_struct {
...
int fair_run_time; // FOR CFS ONLY: run time
int fair_priority; // FOR CFS ONLY: priority
skew_heap_entry_t fair_run_pool; // FOR CFS ONLY: run pool
};
算法实现
proc_fair_comp_f
首先需要一个比较函数,同样根据 完全不需要考虑虚拟运行时溢出的问题。
static int proc_fair_comp_f(void *a, void *b)
{
struct proc_struct *p = le2proc(a, fair_run_pool);
struct proc_struct *q = le2proc(b, fair_run_pool);
int32_t c = p->fair_run_time - q->fair_run_time;
if (c > 0) return 1;
else if (c == 0) return 0;
else return -1;
}
fair_init
static void fair_init(struct run_queue *rq) {
rq->fair_run_pool = NULL;
rq->proc_num = 0;
}
fair_enqueue
和 Stride Scheduling 类型,但是不需要更新 stride。
static void fair_enqueue(struct run_queue *rq, struct proc_struct *proc) {
rq->fair_run_pool = skew_heap_insert(rq->fair_run_pool, &(proc->fair_run_pool), proc_fair_comp_f);
if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice)
proc->time_slice = rq->max_time_slice;
proc->rq = rq;
rq->proc_num ++;
}
fair_dequeue
static void fair_dequeue(struct run_queue *rq, struct proc_struct *proc) {
rq->fair_run_pool = skew_heap_remove(rq->fair_run_pool, &(proc->fair_run_pool), proc_fair_comp_f);
rq->proc_num --;
}
fair_pick_next
static struct proc_struct * fair_pick_next(struct run_queue *rq) {
if (rq->fair_run_pool == NULL)
return NULL;
skew_heap_entry_t *le = rq->fair_run_pool;
struct proc_struct * p = le2proc(le, fair_run_pool);
return p;
}
fair_proc_tick
需要更新虚拟运行时,增加的量为优先级系数。
static void
fair_proc_tick(struct run_queue *rq, struct proc_struct *proc) {
if (proc->time_slice > 0) {
proc->time_slice --;
proc->fair_run_time += proc->fair_priority;
}
if (proc->time_slice == 0) {
proc->need_resched = 1;
}
}
兼容调整
为了保证测试可以通过,需要将 Stride Scheduling 的优先级对应到 CFS 的优先级:
void lab6_set_priority(uint32_t priority)
{
...
// FOR CFS ONLY
current->fair_priority = 60 / current->lab6_priority + 1;
if (current->fair_priority < 1)
current->fair_priority = 1;
}
由于调度器需要通过虚拟运行时间确定下一个进程,如果虚拟运行时间最小的进程需要 yield,那么必须增加虚拟运行时间,例如可以增加一个时间片的运行时。
int do_yield(void) {
...
// FOR CFS ONLY
current->fair_run_time += current->rq->max_time_slice * current->fair_priority;
return 0;
}
遇到的问题:为什么 CFS 调度算法使用红黑树而不使用堆来获取最小运行时进程?
查阅了网上的资料以及自己分析,得到如下结论:
- 堆基于数组,但是对于调度器来说进程数量不确定,无法使用定长数组实现的堆;
- ucore 中的 Stride Scheduling 调度算法使用了斜堆,但是斜堆没有维护平衡的要求,可能导致斜堆退化成为有序链表,影响性能。
综上所示,红黑树因为平衡性以及非连续所以是CFS算法最佳选择。
- 堆基于数组,但是对于调度器来说进程数量不确定,无法使用定长数组实现的堆;
- ucore 中的 Stride Scheduling 调度算法使用了斜堆,但是斜堆没有维护平衡的要求,可能导致斜堆退化成为有序链表,影响性能。
综上所示,红黑树因为平衡性以及非连续所以是CFS算法最佳选择。
Challenge 2 :在ucore上实现尽可能多的各种基本调度算法(FIFO, SJF,...),并设计各种测试用例,能够定量地分析出各种调度算法在各种指标上的差异,说明调度算法的适用范围。
待完成。。。
参考资料
- Stride Scheduling: Deterministic Proportional-Share Resource Management (1995)
- G53OPS : Process Scheduling
- Linux 2.6 Completely Fair Scheduler 内幕
- 斜堆 - 维基百科,自由的百科全书
ucoreOS_lab6 实验报告的更多相关文章
- ucoreOS_lab 1~8 实验报告导航
所有的实验已经全部完成,实验的源代码及报告都在 Github 上,欢迎大家批评指正,如果觉得对你有帮助的话,欢迎为此项目 star & watch & fork 三连,让更多的朋友们看 ...
- 北京电子科技学院(BESTI)实验报告5
北京电子科技学院(BESTI)实验报告5 课程: 信息安全系统设计基础 班级:1452.1453 姓名:(按贡献大小排名) 郑凯杰.周恩德 学号:(按贡献大小排名) 20145314.20145217 ...
- 北京电子科技学院(BESTI)实验报告4
北京电子科技学院(BESTI)实验报告4 课程: 信息安全系统设计基础 班级:1452.1453 姓名:(按贡献大小排名)周恩德 .郑凯杰 学号:(按贡献大小排名)20145217 .201453 指 ...
- 20145215&20145307信息安全系统设计基础实验报告
20145215&20145307信息安全系统设计基础实验报告 PART1 一.实验原理 交叉编译,简单地说,就是在一个平台上生成另一个平台上的可执行代码.同一个体系结构可以运行不同的操作系统 ...
- 北京电子科技学院(BESTI)实验报告1
北京电子科技学院(BESTI)实验报告1 课程: 信息安全系统设计基础 班级:1452.1453 姓名:(按贡献大小排名)郑凯杰 .周恩德 学号:(按贡献大小排名)20145314 .20145217 ...
- 北京电子科技学院(BESTI)实验报告3
北京电子科技学院(BESTI)实验报告3 课程: 信息安全系统设计基础 班级:1452.1453 姓名:(按贡献大小排名)周恩德 .郑凯杰 学号:(按贡献大小排名)20145217 .201453 指 ...
- 20145205 《Java程序设计》实验报告五:Java网络编程及安全
20145205 <Java程序设计>实验报告五:Java网络编程及安全 实验要求 1.掌握Socket程序的编写: 2.掌握密码技术的使用: 3.客户端中输入明文,利用DES算法加密,D ...
- 20145220&20145209&20145309信息安全系统设计基础实验报告(5)
20145220&20145209&20145309信息安全系统设计基础实验报告(5) 实验报告链接: http://www.cnblogs.com/zym0728/p/6132249 ...
- 20145220&20145209&20145309信息安全系统设计基础实验报告(3)
20145220&20145209&20145309信息安全系统设计基础实验报告(3) 实验报告链接: http://www.cnblogs.com/zym0728/p/6132243 ...
随机推荐
- 爬虫模拟有道字典进行翻译,还发现了一条好玩的js
08.14自我总结 爬虫模拟有道字典进行翻译 一.代码 import requests from lxml.html import etree # headers= { # 'User-Agent': ...
- Go-数据类型以及变量,常量
一.数据类型 1.字符串类型 string 2.数字类型 有符号整型: int: int 在32位机器上是int32 在64位机器是int64 int8: int8 表示数字范围是 正负2的7次方减1 ...
- 【React Native】进阶指南之一(特定平台、图片加载、动画使用)
一.特定平台代码 React Native提供了两种方法来区分平台: 使用Platform模块: 使用特定平台扩展名: 1.Platform模块 React Native提供了一个检测当前运行平台的模 ...
- Flutter学习一
包管理 依赖本地包 dependencies: pkg1: path: ../../code/pkg1 依赖git包 dependencies: pkg1: git: url: git://githu ...
- Jackson version is too old 2.xx
我使用的是IDEA,很简单. 切换到project,如果下面的module版本是2.65,上面的jackson.core.xx小于2.65就会报old,如果高于2.65就会报不兼容. 所以调整成相同的 ...
- NCCL(Nvidia Collective multi-GPU Communication Library) Nvidia英伟达的Multi-GPU多卡通信框架NCCL 学习;PCIe 速率调研;
为了了解,上来先看几篇中文博客进行简单了解: 如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?(较为优秀的文章) 使用NCCL进行NVIDIA GPU卡之间的通信(GPU卡通信模式 ...
- ubuntu 桌面版, ssh 连接时使用,x转发进行使用 gnome-terminal 时出现:Error calling StartServiceByName for org.gnome.Terminal: Timeout was reached 错误
当我按照这种情景使用时,出现了这种情况: 考虑着 gnome 桌面正在运行,可能是gnome-terminal 使用了工厂模式进行创建:查找gnome-terminal 文档,有如下解决方案: gno ...
- LEETCODE 1254 统计封闭岛屿的数目 Number of Closed Islands
地址 https://leetcode-cn.com/contest/weekly-contest-162/problems/number-of-closed-islands/ 有一个二维矩阵 gri ...
- 更新GitHub项目出现There is no tracking information for the current branch. Please specify which branch you want to merge with. 怎么解决
git pull命令用于从另一个存储库或本地分支获取并集成(整合).git pull命令的作用是:取回远程主机某个分支的更新,再与本地的指定分支合并,它的完整格式稍稍有点复杂. 如果当前分支只有一个追 ...
- CSP 2019 游记
Day -32 开坑. 没什么好说的,等个 5 天等初赛(应该叫第一轮认证)挂掉之后就能弃坑了. 今天开始停课,虽然每天只停半天,但是感觉还是特别的舒服~ 然而得等初赛过了才能全天停课-- 没关系,熬 ...