python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel。
- 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据
- 使用语言:python
- 工具:PyCharm
- 涉及库:requests、re、openpyxl(高版本excel操作库)
实现代码

- # -*- coding: utf-8 -*-
- # @Author : yocichen
- # @Email : yocichen@126.com
- # @File : maoyan100.py
- # @Software: PyCharm
- # @Time : 2019
- # @UpdateTime : 2020/4/26
- import requests
- from requests import RequestException
- import re
- import openpyxl
- import traceback
- # Get page's html by requests module
- def get_one_page(url):
- try:
- headers = {
- 'user-agent': 'Mozilla / 5.0(Windows NT 10.0; WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 53.0.2785.104Safari / 537.36Core / 1.53.4882.400QQBrowser / 9.7.13059.400'
- }
- # Sometimes, the proxies need to be replaced.
- # You can get them by accessing https://www.kuaidaili.com/free/inha/
- proxies = {
- 'http': '60.190.250.120:8080'
- }
- # use headers to avoid 403 Forbidden Error(reject spider)
- response = requests.get(url, headers=headers, proxies=proxies)
- if response.status_code == 200 :
- return response.text
- return None
- except RequestException:
- traceback.print_exc()
- return None
- # Get useful info from html of a page by re module
- def parse_one_page(html):
- try:
- pattern = re.compile('<dd>.*?board-index.*?>(\d+)<.*?<a.*?title="(.*?)"'
- +'.*?data-src="(.*?)".*?</a>.*?star">[\\s]*(.*?)[\\n][\\s]*</p>.*?'
- +'releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?'
- +'fraction">(.*?)</i>.*?</dd>', re.S)
- items = re.findall(pattern, html)
- return items
- except Exception:
- traceback.print_exc()
- return []
- # Main call function
- def main(url):
- page_html = get_one_page(url)
- parse_res = parse_one_page(page_html)
- return parse_res
- # Write the useful info in excel(*.xlsx file)
- def write_excel_xlsx(items):
- wb = openpyxl.Workbook()
- ws = wb.active
- rows = len(items)
- cols = len(items[0])
- # First, write col's title.
- ws.cell(1, 1).value = '编号'
- ws.cell(1, 2).value = '片名'
- ws.cell(1, 3).value = '宣传图片'
- ws.cell(1, 4).value = '主演'
- ws.cell(1, 5).value = '上映时间'
- ws.cell(1, 6).value = '评分'
- # Write film's info
- for i in range(0, rows):
- for j in range(0, cols):
- if j != 5:
- ws.cell(i+2, j+1).value = items[i][j]
- else:
- ws.cell(i+2, j+1).value = items[i][j]+items[i][j+1]
- break
- # Save the work book as *.xlsx
- wb.save('maoyan_top100.xlsx')
- if __name__ == '__main__':
- print('spider working...')
- res = []
- url = 'https://maoyan.com/board/4?'
- for i in range(0, 10):
- if i == 0:
- res = main(url)
- else:
- newUrl = url+'offset='+str(i*10)
- res.extend(main(newUrl))
- print('writing into excel...')
- write_excel_xlsx(res)
- print('work done!\nNote: the data is in the current directory.')
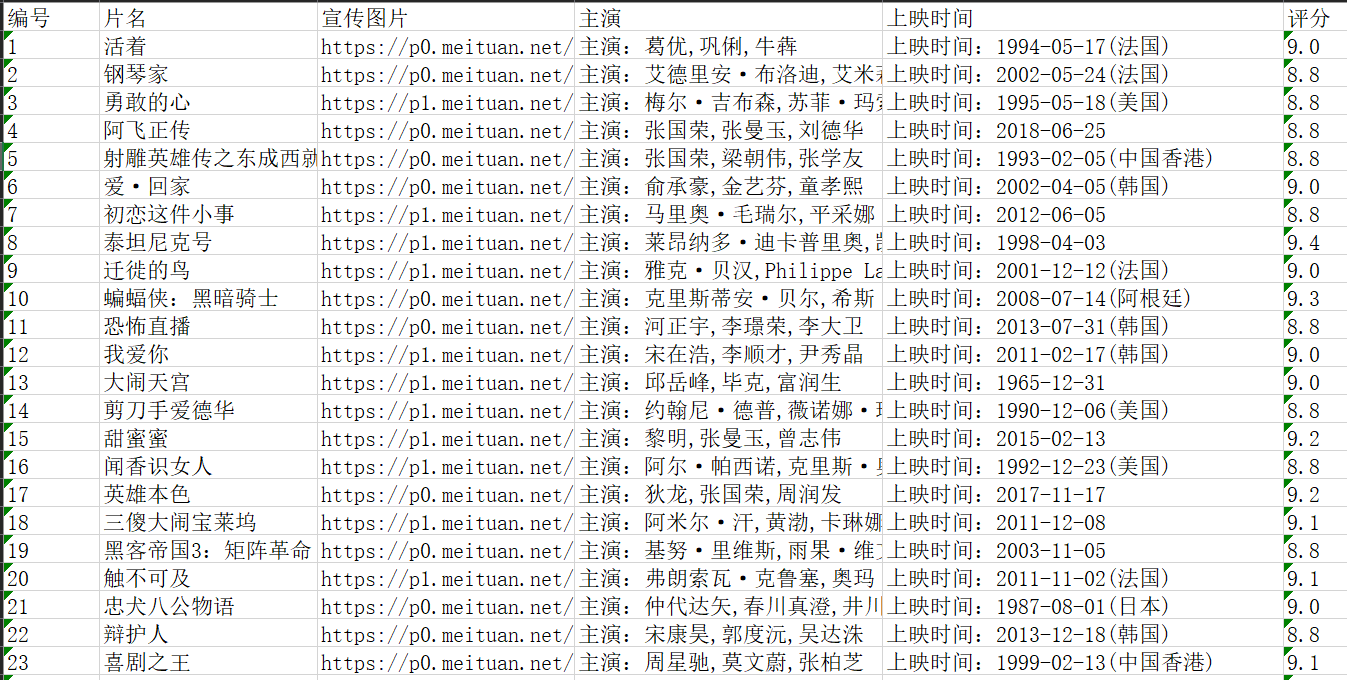
更新效果图:
后记
入门了一点后发现,如果使用正则表达式和requests库来实行进行数据爬取的话,分析HTML页面结构和正则表达式的构造是关键,剩下的工作不过是替换url罢了。
补充一个分析HTML构造正则的例子
审查元素我们会发现每一项都是<dd>****</dd>格式
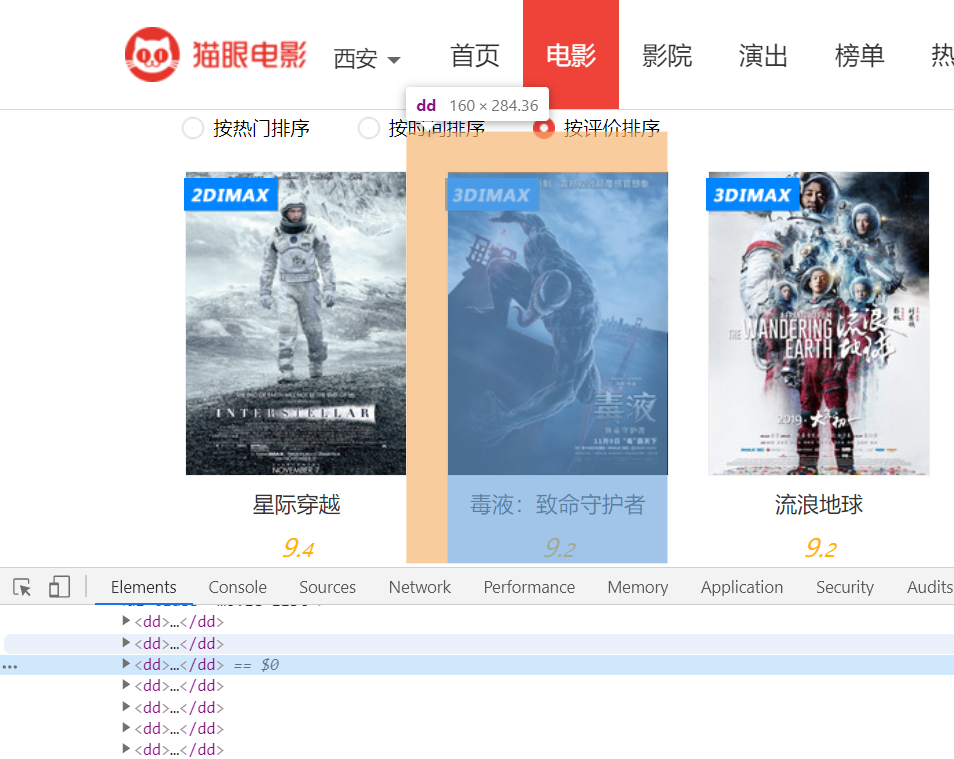
我想要获取电影名称和评分,先拿出HTML代码看一看

试着构造正则
'.*?<dd>.*?movie-item-title.*?title="(.*?)">.*?integer">(.*?)<.*?fraction">(.*?)<.*?</dd>' (随手写的,未经验证)
参考资料
【B站视频 2018年最新Python3.6网络爬虫实战】https://www.bilibili.com/video/av19057145/?p=14
【猫眼电影robots】https://maoyan.com/robots.txt (最好爬之前去看一下,那些可爬那些不允许爬)
python 爬取猫眼电影top100数据的更多相关文章
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- python爬取猫眼电影top100
最近想研究下python爬虫,于是就找了些练习项目试试手,熟悉一下,猫眼电影可能就是那种最简单的了. 1 看下猫眼电影的top100页面 分了10页,url为:https://maoyan.com/b ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- python应用-爬取猫眼电影top100
import requests import re import json import time from requests.exceptions import RequestException d ...
随机推荐
- 在我的新书里,尝试着用股票案例讲述Python爬虫大数据可视化等知识
我的新书,<基于股票大数据分析的Python入门实战>,预计将于2019年底在清华出版社出版. 如果大家对大数据分析有兴趣,又想学习Python,这本书是一本不错的选择.从知识体系上来看, ...
- UVa12105 越大越好
题文:https://vjudge.net/problem/12364(或者见紫书) 题解: 因为题目中有两个限制条件,那么我们就顺着题目的意思来dp,设dp[i][j]表示目前还剩下的i个火柴,用这 ...
- js继承机制的实现
js继承机制的实现 1. 继承的概念 说明继承的最经典的例子:几何形状.实际上,几何形状只有两种,即椭圆形(是圆形的)和多边形(具有一定数量的边).圆是椭圆的一种,它只有一个焦点.三角形.矩形和五边形 ...
- 攻防世界(XCTF)逆向部分write up(一)
晚上做几个简单的ctf逆向睡的更好 logmein elf文件 ida看看main函数伪代码 void __fastcall __noreturn main(__int64 a1, char **a2 ...
- [LUOGU1868] 饥饿的奶牛 - dp二分
题目描述 有一条奶牛冲出了围栏,来到了一处圣地(对于奶牛来说),上面用牛语写着一段文字. 现用汉语翻译为: 有N个区间,每个区间x,y表示提供的x~y共y-x+1堆优质牧草.你可以选择任意区间但不能有 ...
- [Luogu3420][POI2005]SKA-Piggy Banks
题目描述 Byteazar the Dragon has NNN piggy banks. Each piggy bank can either be opened with its correspo ...
- 非阻塞IO模型
#include<stdio.h> #include<stdlib.h> #include<string.h> #include<unistd.h> # ...
- vue 父组件动态传值至子组件
1.进行数据监听,数据每次变化就初始化一次子组件,进行调取达到传递动态数据的目的普通的监听: watch:{ data: function(newValue,oldValue){ doSomeThin ...
- PHP代码审计基础-初级篇
对于php代码审计我也是从0开始学的,对学习过程进行整理输出沉淀如有不足欢迎提出共勉.对学习能力有较高要求,整个系列主要是在工作中快速精通php代码审计,整个学习周期5天 ,建议花一天时间熟悉php语 ...
- pycharm中常见错误提示
1.类中定义函方法 PyCharm 提示Method xxx may be 'static': 原因:该方法不涉及对该类属性的操作,编译器建议声明为@staticmethod