Redis Python(一)
Infi-chu:
http://www.cnblogs.com/Infi-chu/
NoSQL(NoSQL=Not Only SQL),中文意思是非关系型数据库。
随着互联网Web2.0网站的兴起,传统的关系型数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
NoSQL的优点:
- 大数据量,高性能
- 灵活的数据模型
- 高可用
NoSQL的缺点:
- 没有正式的官方支持,出错之后后果十分可怕
- 并没有一定的标准,各种产品参差不齐
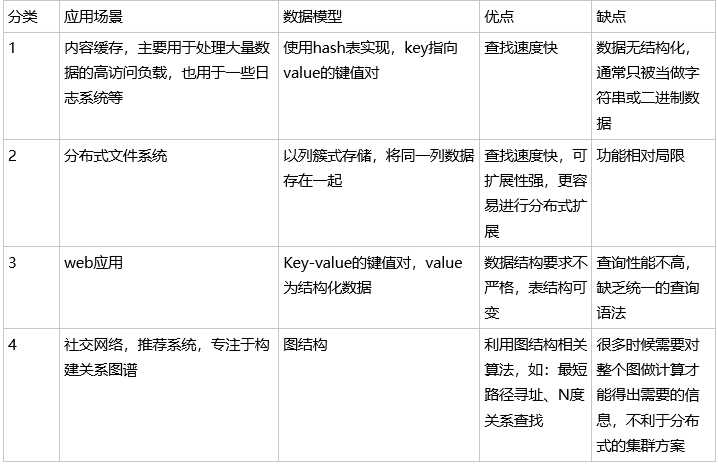
NoSQL数据库的四大分类:
- 键值存储数据库:主要使用一个哈希表,这个表中有一个特定的键和一个指针指向指定的数据,优点是简单、易部署。缺点是在查询和更新时的效率较低。如:Redis、Oracle BDB
- 列存储数据库:一般用来对应分布式存储的海量数据,键依旧存在,但指向了多个列。如:Hbase(大数据存储)、Cassandra
- 文档型数据库:与键值存储相似,该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可 以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。如:CouchDB, MongoDb。
- 图形数据库:使用灵活的图形模型,并能够扩展到多个服务器上。如InfoGrid、Neo4J、Infinite Graph。
对比:
Redis
redis是业界主流的key-value nosql 数据库之一。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis的优点:
- 快速
- 丰富的数据类型
- 多用户同时访问得到的都是最新的数据
- 多功能实用的工具
Python操作Redis
pip install redis
有用的一些操作
ps -ef | grep redis 查看进程状态 netstat -tulnp 查看端口号 redis -cli 本地连接Redis
Redis API(redis-py)使用可以分为5类:
- 连接方式
- 连接池
- 操作:String操作、Hash操作、List操作、Set操作、Sort Set操作
- 管道
- 发布订阅
一、连接方式
操作模式:
- 提供两个类:Redis和StrictRedis用于实现rRedis的命令,StrictRedis用于实现大部分的官方命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py
#import redis
#a=redis.Redis(host='192.168.1.1',port=6379)
#a.set('foo','Bar')
#print(r.get('foo'))
二、连接池
Redis-py使用connection pool来管理一个redis server的所有连接,避免每次建立、释放连接的开销。
在默认情况下,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
三、操作
1.String操作:
在内存中按照一个name对应一个value来存储,一 一对应的关系
#终端语法: #set name bob #存 #get name #取 #keys * #取出所有key值 #set name sam ex 3 #3秒后自动删除
1.String操作:
在内存中按照一个name对应一个value来存储,一 一对应的关系
#python语法:
#set(name,value,ex=None,px=None,nx=False,xx=False)
#在Redis中设置值,默认,不存在则创建,存在则修改
#参数:
# ex:过期时间(秒)
# px:过期时间(毫秒)
# nx:如果设置为True,只有name不存在时,当前set才执行
# xx:如果设置为True,只有name存在时,当前set操作才执行
#setnx(name,value)
#设置值,只有name不存在时,才执行
#setex(name,value,time)
#设置值,time为过期时间(秒)
#psetex(name,time_ms,value)
#设置值,time_ms过期时间(毫秒)
#mset(*args,**kwargs)
#批量设置值
#例子:mset(n1='a',n2='b')或mget({'n1':'a','n2':'b'})
#get(name)
#获取值
#mget(keys,*args)
#批量获取
#例子:mget('a1','a2')或r.mget(['a1','a2'])
#getset(name,value)
#设置新的值,并且同时得到原来的值
#getrange(key,start,end)
#获取子序列(根据字节获取,开始字节,结束字节)
#setrange(name,offset,value)
#修改字符串内容,从指定位置开始向后替代,超出则为添加
#offset,字符串索引,字节(1个汉字为3个字节)
#value,要设置的值
#setbit(name,offset,value)
#对name对应的值的二进制表示的位进行操作
#name:name
#offset:位的索引(将值变为二进制后再进行索引)
#value:只能是0或1
#getbit(name,offset)
#获取name对应的值的二进制表示表示中的某位的值
#bitcount(key,start=None,end=None)
#获取name对应的值的二进制表示中1的个数
#strlen(name)
#返回name对应值的字节长度
#incr(self,name,amount=1)
#自增,name对应的值,当name不存在时,则创建name=amount,否则自增
#amount为自增数
#incrbyfloat(self,name,amount=1.0)
#浮点型
#decr(self,name,amount=1)
#自减,name对应的值,当name不存在时,则创建name=amount,否则自减
#append(key,value)
#在Redis中,name对应的值后面追加的内容
2.Hash操作
与python中的字典类似,可以存储一组关联性较强的数据,一对一组的关系,组中也有对应关系
#hset(name,key,value)
#name对应的hash中设置一个键值对(有则修改,无则创建)
#name:name
#key:name对应的值中的键
#value:name对应的值中的值
#hmset(name,mapping)
#在name对应的hash中批量设置键值对
#例子:r.hmset('a',{'b1':'q','b2':'w'})
#hget(name,key)
#在name对应的组中,根据key获取value
#hmget(name,keys,*args)
#在name对应的组中,获取多个key的值
#hgetall(name)
#获取name对应的组中所有的键值
#hlen(name)
#获取name对应的组中键值对的个数
#hkeys(name)
#获取name对应的组中,所有的key的值
#hvals(name)
#获取name对应的组中,所有的value的值
#hexists(name,key)
#检查name对应的组中,是否存在当前传入的key
#hdel(name,*keys)
#将name对应的组中,指定的key的键值对删除
#hincrby(name,key,amount=1)
#自增name对应的组中,指定key的值,不存在则创建key=amount
#hincrbyfloat(name, key, amount=1.0)
#浮点自增
#hscan(name,cursor=0,match=None,count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
# 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
3.list操作
一个name对应一个list
#lpush(name,values)
#在name对应的list中添加元素,每个新的元素都添加到列表的最左边
# rpush(name, values) 表示从右向左操作
#lpushx(name,value)
#在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
# rpushx(name, value) 表示从右向左操作
#llen(name)
#name对应的list元素个数
#linsert(name,where,refvalue,value)
# 在name对应的列表的某一个值前或后插入一个新值
# 参数:
# name,redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据
#r.lrem(name,value,num)
# 在name对应的list中删除指定的值
# 参数:
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值
# num=2,从前到后,删除2个
# num=-2,从后向前,删除2个
#lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
# rpop(name) 表示从右向左操作
#lindex(name, index)
#在name对应的列表中根据索引获取列表元素
#lrange(name, start, end)
# 在name对应的列表分片获取数据
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
#ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
#rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
# 参数:
# src,要取数据的列表的name
# dst,要添加数据的列表的name
#blpop(keys, timeout)
# 将多个列表排列,按照从左到右去pop对应列表的元素
# 参数:
# keys,redis的name的集合
# timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
# r.brpop(keys, timeout),从右向左获取数据
#brpoplpush(src, dst, timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
# 参数:
# src,取出并要移除元素的列表对应的name
# dst,要插入元素的列表对应的name
# timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
4.set集合操作
set集合就是不允许重复的列表
#sadd(name,values)
# name对应的集合中添加元素
#scard(name)
#获取name对应的集合中元素个数
#sdiff(keys, *args)
#在第一个name对应的集合中且不在其他name对应的集合的元素集合
#sdiffstore(dest, keys, *args)
# 获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
#sinter(keys, *args)
# 获取多一个name对应集合的并集
#sinterstore(dest, keys, *args)
# 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
#sismember(name, value)
# 检查value是否是name对应的集合的成员
#smembers(name)
# 获取name对应的集合的所有成员
#smove(src, dst, value)
# 将某个成员从一个集合中移动到另外一个集合
#spop(name)
# 从集合的右侧(尾部)移除一个成员,并将其返回
#srandmember(name, numbers)
# 从name对应的集合中随机获取 numbers 个元素
#srem(name, values)
# 在name对应的集合中删除某些值
#sunion(keys, *args)
# 获取多一个name对应的集合的并集
#sunionstore(dest,keys, *args)
# 获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
#sscan(name, cursor=0, match=None, count=None)
#sscan_iter(name, match=None, count=None)
# 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
#zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素
# 如:
# zadd('zz', 'n1', 1, 'n2', 2)
# 或
# zadd('zz', n1=11, n2=22)
#zcard(name)
# 获取name对应的有序集合元素的数量
#zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数
#zincrby(name, value, amount)
# 自增name对应的有序集合的 name 对应的分数
#r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素
# 参数:
# name,redis的name
# start,有序集合索引起始位置(非分数)
# end,有序集合索引结束位置(非分数)
# desc,排序规则,默认按照分数从小到大排序
# withscores,是否获取元素的分数,默认只获取元素的值
# score_cast_func,对分数进行数据转换的函数
# 更多:
# 从大到小排序
# zrevrange(name, start, end, withscores=False, score_cast_func=float)
# 按照分数范围获取name对应的有序集合的元素
# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)
# 从大到小排序
# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
#zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始)
# 更多:
# zrevrank(name, value),从大到小排序
#zrem(name, values)
# 删除name对应的有序集合中值是values的成员
# 如:zrem('zz', ['s1', 's2'])
#zremrangebyrank(name, min, max)
# 根据排行范围删除
#zremrangebyscore(name, min, max)
# 根据分数范围删除
#zscore(name, value)
# 获取name对应有序集合中 value 对应的分数
#zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX
#zunionstore(dest, keys, aggregate=None)
# 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX
#zscan(name, cursor=0, match=None, count=None, score_cast_func=float)
#zscan_iter(name, match=None, count=None,score_cast_func=float)
# 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
5.其他操作
#delete(*names)
# 根据删除redis中的任意数据类型
#exists(name)
# 检测redis的name是否存在
#keys(pattern='*')
# 根据模型获取redis的name
# 更多:
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
#expire(name ,time)
# 为某个redis的某个name设置超时时间
#rename(src, dst)
# 对redis的name重命名为
#move(name, db))
# 将redis的某个值移动到指定的db下
#randomkey()
# 随机获取一个redis的name(不删除)
#type(name)
# 获取name对应值的类型
#scan(cursor=0, match=None, count=None)
#scan_iter(match=None, count=None)
# 同字符串操作,用于增量迭代获取key
四、管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
五、发布订阅
让多人可以知道某一个东西的内容
Redis Python(一)的更多相关文章
- Ubuntu上面安装Redis Python
Ubuntu上面安装Redis Python 1,下载redis源码https://redis.io/download,下载地址:http://124.205.69.169/files/A092000 ...
- 监控redis python脚本
#!/bin/env python #-*- coding:utf- -*- import json import time import socket import os import re imp ...
- Redis & Python/Django 简单用户登陆
一.Redis key相关操作: 1.del key [key..] 删除一个或多个key,如果不存在则忽略 2.keys pattern keys模式匹配,符合glob风格通配符,glob风格的通配 ...
- Redis - Python操作Redis
目录 Python操作Redis 一. Redis安装和基本使用 二. Python操作Redis API使用 1.操作模式 2.连接池 3.Django配置Redis 4.操作 Python操作Re ...
- redis python 操作 Python操作Redis数据库
原文章于此:https://www.cnblogs.com/cnkai/p/7642787.html 有个人修改与改正 Python操作Redis数据库 连接数据库 StrictRedisfrom ...
- Redis Python(二)
Infi-chu: http://www.cnblogs.com/Infi-chu/ 一.NoSQL(Not only SQL)1.泛指非关系数据库2.不支持SQL语法3.存储结构与传统的关系型数据库 ...
- redis python操作
1.基于连接池方式实现对五个数据类型操作,每种数据类型2个操作 2.基于spring-data-redis 基于jedis来实现对五种数据类型操作,每种数据类型实现两个操作,包括事务 以上为基于jav ...
- redis -- python操作连接redis简单示例
1.先安装 redis,pyredis sudo pip install redis sudo pip install python-redis 2.示例: importredis >>& ...
- Redis Python开发指南
redis基本命令 String set setex psetex mset mget getset getrange setrange setbit getbi ...
随机推荐
- .NET Core C# 中级篇2-7 文件操作
.NET Core CSharp 中级篇2-7 本节内容为文件操作 简介 文件操作在我们C#里还是比较常见的,例如我们读取Excel.Txt文件的内容,在程序中,这些文件都是以流的方式读取进入我们内存 ...
- Slickflow.NET 开源工作流引擎高级开发(五) -- 引擎和外部事件的交互
前言:引擎组件的基本职责是负责流程流转,但是在流转过程中,除了对内部控制逻辑进行实现外,也不可避免的要去调用或者响应外部事件.本文主要描述外部事件的类型,以及调用方法过程. 1. 外部事件的类型 外部 ...
- ASP.NET MVC IOC依赖注入之Autofac系列(二)- WebForm当中应用
上一章主要介绍了Autofac在MVC当中的具体应用,本章将继续简单的介绍下Autofac在普通的WebForm当中的使用. PS:目前本人还不知道WebForm页面的构造函数要如何注入,以下在Web ...
- PostgreSQL update set from 两表联合更新,注意与其它数据库更新语法有差别
最近用PostgreSql数据库进行表关联更新时,发现与之前用的Sql Server 和My Sql语法有很大差别,稍微不注意,很容易出错. PostgreSql表更新时,两个表只允许一个表起别名,一 ...
- 2. 移动安全渗透测试-(Android安全基础)
2.1 Android系统架构 1.应用程序层 平时所见的一些java为主编写的App 2.应用程序框架层 应用框架层为应用开发者提供了用以访问核心功能的API框架 android.app:提供高层的 ...
- Gradle之FTP文件下载
Gradle之FTP文件下载 1.背景 项目上需要使用本地web,所以我们直接将web直接放入assets资源文件夹下.但是随着开发进行web包越来越大:所以我们想着从版本库里面去掉web将其忽略掉, ...
- 未能找到元数据文件**.dll解决办法
解决方案里有很多项目.生成时提示100多个错误,都是未能找到元数据文件**.dll. 那就清理一下解决方案,一个一个来吧. 生成GateWay.Utilities项目时,虽然提示成功了,却发现bin/ ...
- [Linux] 常见的并发模型
进程&线程(Apache) C10K问题异步非阻塞(Nginx,Libevent,NodeJS) 开发时复杂度高协程 (Golang Erlang lua) goroutine channel ...
- Golang防止多个进程重复执行
创建锁文件 lockFile := "./lock.pid" lock, err := os.Create(lockFile) if err != nil { log.Fatal( ...
- java8一些语法使用例子
package com.ladeng.jdk8; import com.google.common.collect.Lists;import java.util.*;import java.util. ...