NCCL(Nvidia Collective multi-GPU Communication Library) Nvidia英伟达的Multi-GPU多卡通信框架NCCL 学习;PCIe 速率调研;
为了了解,上来先看几篇中文博客进行简单了解:
- 如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?(较为优秀的文章)
- 使用NCCL进行NVIDIA GPU卡之间的通信(GPU卡通信模式测试)
- nvidia-nccl 学习笔记 (主要是一些接口介绍)
- https://developer.nvidia.com/nccl (官方网站)
- https://github.com/NVIDIA/nccl (官方仓库)
- https://www.cnblogs.com/xuyaowen/p/heterogeneous-system-architecture.html GPU 相关架构
- https://www.nvidia.cn/data-center/nvlink/ (NVLink)
- https://docs.nvidia.com/deeplearning/sdk/nccl-developer-guide/docs/overview.html (nccl doc)
内容摘录:
- 通信性能(应该主要侧重延迟)是pcie switch > 同 root complex (一个cpu接几个卡) > 不同root complex(跨cpu 走qpi)。ib的gpu direct rdma比跨cpu要快,所以甚至单机八卡要按cpu分成两组,每组一个switch,下面四个卡,一个ib,不通过cpu的qpi通信,而是通过ib通信。- 摘自评论
- 对于多个GPU卡之间相互通信,硬件层面上的实现有Nvlink、PCIe switch(不经过CPU)、Infiniband、以及PCIe Host Bridge(通常就是借助CPU进行交换)这4种方式。而NCCL是Nvidia在软件层面对这些通信方式的封装。
保持更新,更多内容,请参考cnblogs.com/xuyaowen;
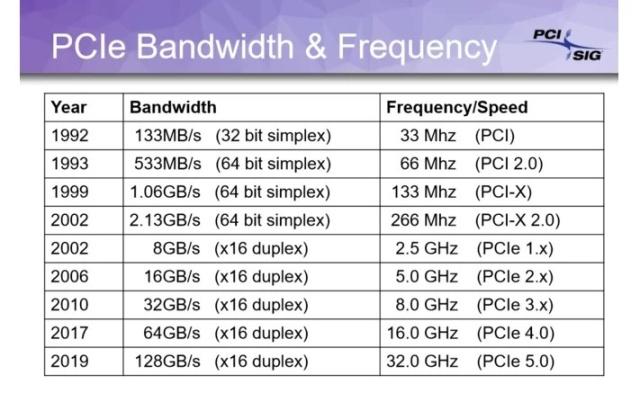
z390 芯片组资料:
https://ark.intel.com/content/www/cn/zh/ark/products/133293/intel-z390-chipset.html
P2P 显卡通信性能测试:
cuda/samples/1_Utilities/p2pBandwidthLatencyTest
nvidia 驱动安装:
https://www.cnblogs.com/xuyaowen/p/nvidia-driver-cuda-installation.html
nccl 编译安装过程:
git clone git@github.com:NVIDIA/nccl.git
cd nccl
make -j src.build (进行编译)
cd build
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/yourname/nccl/build/lib # 添加环境变量;也可以配置环境变量.bashrc;
export C_INCLUDE_PATH=/home/yourname/nccl/build/include (设置 C 头文件路径)
export CPLUS_INCLUDE_PATH=/home/yourname/nccl/build/include (设置C++头文件路径)
测试是否安装成功:
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests
make CUDA_HOME=/path/to/cuda NCCL_HOME=/path/to/nccl (具体编译,可以参考官方文档)
./build/all_reduce_perf -b 8 -e 256M -f 2 -g <ngpus>
才是
NCCL(Nvidia Collective multi-GPU Communication Library) Nvidia英伟达的Multi-GPU多卡通信框架NCCL 学习;PCIe 速率调研;的更多相关文章
- 基于英伟达Jetson TX1的GPU处理平台
基于英伟达Jetson TX1 GPU的HDMI图像输入的深度学习套件 [309] 本平台基于英伟达的Jetson TX1视觉计算的全功能开发板,配合本公司研发的HDMI输入图像采集板:Jetson ...
- 英伟达GPU 嵌入式开发平台
英伟达GPU 嵌入式开发平台 1. JETSON TX1 开发者组件 JETSON TX1 开发者组件是视觉计算的全功能 开发平台,旨在让您能够快速地安装和运行. 该组件带有 Lin ...
- 玩深度学习选哪块英伟达 GPU?有性价比排名还不够!
本文來源地址:https://www.leiphone.com/news/201705/uo3MgYrFxgdyTRGR.html 与“传统” AI 算法相比,深度学习(DL)的计算性能要求,可以说完 ...
- 英伟达GPU虚拟化---申请英伟达测试License
此文基于全新的License 2.0系统,针对vGPU License的试用申请以及软件下载和License管理进行了详细的说明,方便今后我们申请测试License,快速验证GPU的功能. 试用步骤: ...
- Linux查看英伟达GPU信息
命令: nvidia-smi 结果:
- 学习笔记︱Nvidia DIGITS网页版深度学习框架——深度学习版SPSS
DIGITS: Deep Learning GPU Training System1,是由英伟达(NVIDIA)公司开发的第一个交互式深度学习GPU训练系统.目的在于整合现有的Deep Learnin ...
- MLHPC 2018 | Aluminum: An Asynchronous, GPU-Aware Communication Library Optimized for Large-Scale Training of Deep Neural Networks on HPC Systems
这篇文章主要介绍了一个名为Aluminum通信库,在这个库中主要针对Allreduce做了一些关于计算通信重叠以及针对延迟的优化,以加速分布式深度学习训练过程. 分布式训练的通信需求 通信何时发生 一 ...
- Aluminum: An Asynchronous, GPU-Aware Communication Library Optimized for Large-Scale Training of Deep Neural Networks on HPC Systems
本文发表在MLHPC 2018上,主要介绍了一个名为Aluminum通信库,这个库针对Allreduce做了一些关于计算通信重叠以及针对延迟的优化,以加速分布式深度学习训练过程. 分布式训练的通信需求 ...
- GPU 编程入门到精通(五)之 GPU 程序优化进阶
博主因为工作其中的须要,開始学习 GPU 上面的编程,主要涉及到的是基于 GPU 的深度学习方面的知识.鉴于之前没有接触过 GPU 编程.因此在这里特地学习一下 GPU 上面的编程. 有志同道合的小伙 ...
随机推荐
- C#的语法----程序结构(3)
练习2 对于学员成绩的评测 成绩>=90:A 成绩>=80&&成绩<90:B 成绩>=70&&成绩<80:C 成绩>=60& ...
- idea常用快捷键大全
Idea常用快捷键大全,拿小本本记下来,忘记了可以方便查找. 编写代码 Ctrl+Shift + Enter,语句完成. “!”,否定完成,输入表达式时按 “!”键. Ctrl+E,最近的文件. Ct ...
- 在Mac上安装JDK1.8及环境变量配置
今天我们来讲一讲,在Mac上的JDK安装. 第一步,打开终端输入 java -version 看看是否本地已经安装了JDK,如果未安装,OK,继续- 第二步,到官网下载JDK.勾选“Accept Li ...
- C#构造方法(构造函数)
构造方法特点: 一 ,与类同名 public class Product { public int ID { get; set; } public String NAME { get; set; } ...
- Nginx的安装及配置
1.概述 Nginx是开源免费的一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器.其特点是占有内存少,并发能力强,使用nginx网站用户有很多,如百 ...
- 43.QT-访问远程SQLite数据库
在上章42.QT-QSqlQuery类操作SQLite数据库(创建.查询.删除.修改)详解学习了如何操作SQLite,本章来学习如何访问远程SQLite 1.首先设置共享,映射(用来实现远程访问) 将 ...
- 百度地图在jsp页面加载大量轨迹导致地图卡顿
原画线方式: //存储大量点轨迹json数组:historyPathList for(var i=0;i<historyPathList.length-1;i++){ drawColorLine ...
- 码农-->工程师
微信公众号推送文章记录,侵删 一个猎人的比喻: 当土著拿到猎枪之后,他们射箭的技能退化严重,但因为食物更多了,厨艺有了长足的进展. 当你不再为一些问题担心之后,你就可以把注意力集中在另外一些问题上了. ...
- C#后台架构师成长之路-基础体系篇章大纲
如下基础知识点,如果不熟透,以后容易弄笑话..... 1. 常用数据类型:整型:int .浮点型:double.布尔型:bool.... 2. 变量命名规范.赋值基础语法.数据类型的转换.运算符和选择 ...
- Lua 5.1 学习笔记
1 简介 2 语法 2.1 语法约定 2.1.1 保留关键字 2.1.2 操作符 2.1.3 字符串定义 2.2 值与类型 2.2.1 强制转换 2.3 变量 2.3.1 索引 2.3.2 环境表 2 ...