去重合并两个有序链表之直接操作和Set集合操作
两者思路对比:
直接操作:因为传入的是两个有序的链表,所以说我就直接以其中一个链表为基准,与另外一个链表比较,只将比返回值链表的最后一个记录的值大的插入,不将等值的插入,理论时间复杂度为O(n)
Set操作:将所有的节点取出放入TreeSet有序集合中,最后生成一个链表返回,理论时间复杂度为O(2n)
直接操作步骤示意图:
以{1,3,5}{1,2,4,5,5,6}为例
- 先取个返回值链表的表头,并将该链表作为基准链表,比较第一个值小的为基准链表,相同就取第一个
返回值链表:1->null
基准链表:3->5->null
非基准链表:1->2->4->5->5->6->null - 继续下一步后的链表,这一步中,取两个链表中的小值尝试插入,但是发现与返回值链表末端值相同就丢弃
返回值链表:1->null
基准链表:3->5->null
非基准链表:2->4->5->5->6->null - 继续下一步后的链表,这一步中,取两个链表中的小值尝试插入,但是发现与返回值链表末端值不同就插入
返回值链表:1->2->null
基准链表:3->5->null
非基准链表:4->5->5->6->null - 继续下一步后的链表,这一步中,取两个链表中的小值尝试插入,但是发现与返回值链表末端值不同就插入
返回值链表:1->2->3->null
基准链表:5->null
非基准链表:4->5->5->6->null - 继续下一步后的链表,这一步中,取两个链表中的小值尝试插入,但是发现与返回值链表末端值不同就插入
返回值链表:1->2->3->4->null
基准链表:5->null
非基准链表:5->5->6->null - 继续下一步后的链表,这一步中,取两个链表中的小值尝试插入,但是发现与返回值链表末端值不同就插入
返回值链表:1->2->3->4->5->null
基准链表:null
非基准链表:5->5->6->null - 其中一个链表为null之后直接只遍历另外一个链,因为要去重,所以要遍历完,取非基准链表中的一个值尝试插入,但是发现与返回值链表末端值相同就丢弃
返回值链表:1->2->3->4->5->null
基准链表:null
非基准链表:5->6->null - 取非基准链表中的一个值尝试插入,但是发现与返回值链表末端值相同就丢弃
返回值链表:1->2->3->4->5->null
基准链表:null
非基准链表:6->null - 取非基准链表中的一个值尝试插入,但是发现与返回值链表末端值不同就保留,此时两个链表都为null则结束
返回值链表:1->2->3->4->5->6null
基准链表:null
非基准链表:null
对于Set操作的算法则不展开
自己写的比较的算法:
import java.util.*;
public class Main {
public static void main(String[] args) {
Node headOne = new Node(-1);
Node headTwo = new Node(-1);
Node p1 = headOne;
Node p2 = headTwo;
int[] one = new int[10000];
int[] two = new int[15000];
Random rm = new Random();
for (int i = 0; i < 10000; i++){
one[i] = rm.nextInt(500);
}
for (int i = 0; i < 15000; i++){
two[i] = rm.nextInt(500);
}
Arrays.sort(one);
Arrays.sort(two);
for (int i = 0; i < one.length; i++){
Node node = new Node(one[i]);
p1.next = node;
p1 = p1.next;
}
for (int i = 0; i < two.length; i++){
Node node = new Node(two[i]);
p2.next = node;
p2 = p2.next;
}
long start = System.nanoTime();
Node re = change(headOne.next, headTwo.next);
long end = System.nanoTime();
System.out.println("直接操作:" + (end - start) + "ns");
start = System.nanoTime();
Node reSet = changeSet(headOne.next, headTwo.next);
end = System.nanoTime();
System.out.println("Set时间: " + (end - start) + "ns");
}
private static Node change(Node headOne, Node headTwo){
//空值判断
if (headTwo == null){
return headOne;
}
if (headOne == null){
return headTwo;
}
//返回首元素较小的头结点, 先取一个节点为基准
Node reHead = headOne.data <= headTwo.data? headOne: headTwo;
Node p2 = headOne.data >= headTwo.data? headTwo: headOne; //另一条链
Node pre = reHead; //上一个节点
Node p1 = reHead.next; //当前链
while(p1 != null && p2 != null){
if(p1.data <= p2.data){
if (p1.data == p2.data){
p2 = p2.next;
}
if (p1.data != pre.data){
pre = pre.next;
p1 = p1.next;
}else{
pre.next = p1.next; //跳过该相同节点
p1 = p1.next;
}
}else{
if (p2.data != pre.data){
pre.next = p2;
p2 = p2.next;
pre = pre.next;
pre.next = p1;
}else {
p2 = p2.next;
}
}
}
Node now = p1 != null? p1: p2;
pre.next = now;
while(now!= null){
if (pre.data == now.data){
now = now.next;
pre.next = now;
}else{
pre = pre.next;
now = now.next;
}
}
return reHead;
}
private static Node changeSet(Node headOne, Node headTwo){
Node re = new Node(-1);
Node head = re;
TreeSet<Node> s = new TreeSet<>();
while(headOne != null){
s.add(headOne);
headOne = headOne.next;
}
while(headTwo != null){
s.add(headTwo);
headTwo = headTwo.next;
}
Iterator iterator = s.iterator();
while (iterator.hasNext()){
Node p = (Node) iterator.next();
Node tmp = new Node(p.data);
head.next = tmp;
head = head.next;
}
return re.next;
}
}
class Node implements Comparable{
int data;
Node next;
public Node(int data){
this.data = data;
}
@Override
public int compareTo(Object o) {
Node t = (Node)o;
if (this.data > t.data){
return 1;
}else if (this.data == t.data){
return 0;
}else {
return -1;
}
}
}
实现代码
然后运行的时间截图:
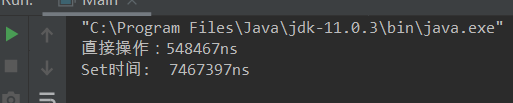
如有错误和不足,望指正
千里之行,始于足下
去重合并两个有序链表之直接操作和Set集合操作的更多相关文章
- 【LeetCode题解】21_合并两个有序链表
目录 21_合并两个有序链表 描述 解法一:迭代 思路 Java 实现 Python 实现 解法二:递归 思路 Java 实现 Python 实现 21_合并两个有序链表 描述 将两个有序链表合并为一 ...
- leetcode 21 Merge Two Sorted Lists 合并两个有序链表
描述: 合并两个有序链表. 解决: ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) { if (!l1) return l2; if (!l2) ...
- Leecode刷题之旅-C语言/python-21.合并两个有序链表
/* * @lc app=leetcode.cn id=21 lang=c * * [21] 合并两个有序链表 * * https://leetcode-cn.com/problems/merge-t ...
- LeetCode初级算法--链表02:合并两个有序链表
LeetCode初级算法--链表02:合并两个有序链表 搜索微信公众号:'AI-ming3526'或者'计算机视觉这件小事' 获取更多算法.机器学习干货 csdn:https://blog.csdn. ...
- <每日 1 OJ> -LeetCode 21. 合并两个有序链表
题目: 将两个有序链表合并为一个新的有序链表并返回.新链表是通过拼接给定的两个链表的所有节点组成的. 示例: 输入:1->2->4, 1->3->4输出:1->1-> ...
- 算法练习之合并两个有序链表, 删除排序数组中的重复项,移除元素,实现strStr(),搜索插入位置,无重复字符的最长子串
最近在学习java,但是对于数据操作那部分还是不熟悉 因此决定找几个简单的算法写,用php和java分别实现 1.合并两个有序链表 将两个有序链表合并为一个新的有序链表并返回.新链表是通过拼接给定的两 ...
- LeetCode 21. 合并两个有序链表(Merge Two Sorted Lists)
21. 合并两个有序链表 21. Merge Two Sorted Lists 题目描述 将两个有序链表合并为一个新的有序链表并返回.新链表是通过拼接给定的两个链表的所有节点组成的. LeetCode ...
- leecode刷题(23)-- 合并两个有序链表
leecode刷题(23)-- 合并两个有序链表 合并两个有序链表 将两个有序链表合并为一个新的有序链表并返回.新链表是通过拼接给定的两个链表的所有节点组成的. 示例: 输入:1->2-> ...
- LeetCode_21.合并两个有序链表
LeetCode_21 LeetCode-21.合并两个有序链表 将两个有序链表合并为一个新的有序链表并返回. 新链表是通过拼接给定的两个链表的所有节点组成的. 示例: 输入:1->2-> ...
随机推荐
- Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- ecshop 管理后台菜单及权限管理机制
ecshop 所有的一级菜单选项存放于languages\zh_cn\admin\common.php 文件里面,使用 $_LANG['02_cat_and_goods'] = '商品管理'; 这样 ...
- Python.append()与Python.extend()的区别
lst=[1,2] >>>[1,2] lst.append([3,4]) >>>[1, 2, [3, 4]] lst.extend([3,4]) >>& ...
- 洛谷 P3628 特别行动队
洛谷题目页面传送门 题意见洛谷. 这题一看就是DP... 设\(dp_i\)表示前\(i\)个士兵的最大战斗力.显然,最终答案为\(dp_n\),DP边界为\(dp_0=0\),状态转移方程为\(dp ...
- 链表:如何实现LRU缓存淘汰算法?
缓存淘汰策略: FIFO:先入先出策略 LFU:最少使用策略 LRU:最近最少使用策略 链表的数据结构: 可以看到,数组需要连续的内存空间,当内存空间充足但不连续时,也会申请失败触发GC,链表则可 ...
- Go调度器介绍和容易忽视的问题
本文记录了本人对Golang调度器的理解和跟踪调度器的方法,特别是一个容易忽略的goroutine执行顺序问题,看了很多篇Golang调度器的文章都没提到这个点,分享出来一起学习,欢迎交流指正. 什么 ...
- Map集合的遍历(利用entry接口的方式)
核心思想: 调用map集合中的方法entrySet()将集合中的映射关系存放在Set集合中. 迭代Set集合 获取出的Set集合的元素是映射关系对象 通过映射关系对象方法的getKey(),getVa ...
- StudyAndroid.1
目标: 手动创建第一个Activity 开发环境: Android Studio 3.3.1 Build #AI-182.5107.16.33.5264788, built on January 29 ...
- ansible之变量
一.常用系统变量 1. loop #表示循环,去读循环体里的变量固定使用{{item}},item是个字典对象item.key=value,例如如下playbook内容: --- - name: ...
- 关于sparksql中设置自定义自增列的相关要点(工作共踩过的坑-1)
小白终于进入了职场,从事大数据方面的工作! 分到项目组了,搬砖的时候遇到了一个这样的问题. 要求:用spark实现oracle的存储过程中计算部分. 坑:由于报表中包含了一个ID字段,其要求是不同的区 ...