Springboot2.x + ShardingSphere 实现分库分表
之前一篇文章中我们讲了基于Mysql8的读写分离(文末有链接),这次来说说分库分表的实现过程。
概念解析
垂直分片
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
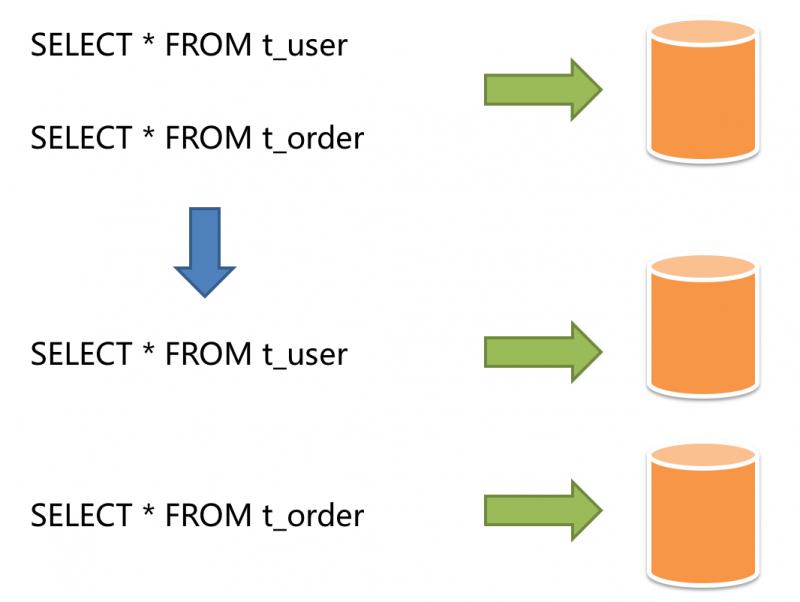
垂直分片往往需要对架构和设计进行调整。通常来讲,是来不及应对互联网业务需求快速变化的;而且,它也并无法真正的解决单点瓶颈。 垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入0库(或表),奇数主键的记录放入1库(或表),如下图所示。
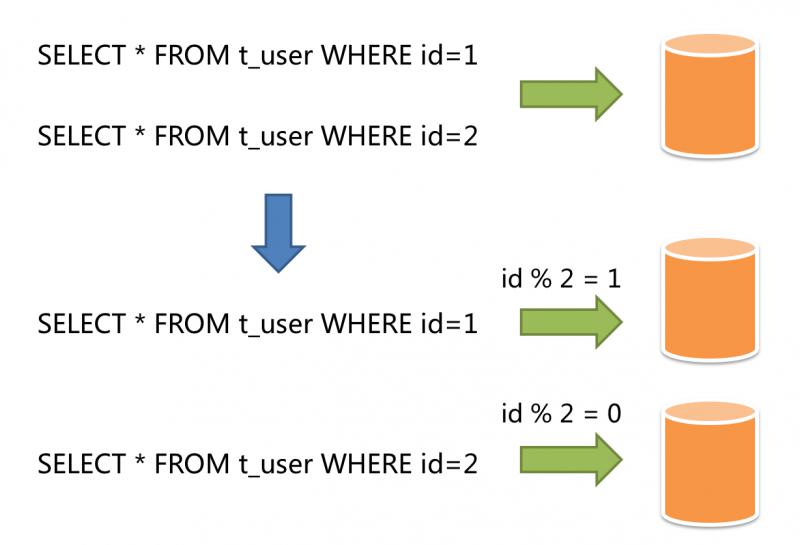
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是分库分表的标准解决方案。
开发准备
分库分表常用的组件就是shardingsphere,目前已经是apache顶级项目,这次我们使用springboot2.1.9 + shardingsphere4.0.0-RC2(均为最新版本)来完成分库分表的操作。
假设有一张订单表,我们需要将它分成2个库,每个库三张表,根据id字段取模确定最终数据的位置,数据库环境配置如下:
- 172.31.0.129
- blog
- t_order_0
- t_order_1
- t_order_2
- blog
- 172.31.0.131
- blog
- t_order_0
- t_order_1
- t_order_2
- blog
三张表的逻辑表为t_order,大家可以根据建表语句准备好其他所有数据表。
DROP TABLE IF EXISTS `t_order_0;
CREATE TABLE `t_order_0` (
`id` bigint(20) NOT NULL,
`name` varchar(255) DEFAULT NULL COMMENT '名称',
`type` varchar(255) DEFAULT NULL COMMENT '类型',
`gmt_create` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;注意,千万不能将主键的生成规则设置成自增长,需要按照一定规则来生成主键,这里使用shardingsphere中的SNOWFLAKE俗称雪花算法来生成主键
代码实现
- 修改pom.xml,引入相关组件
<properties>
<java.version>1.8</java.version>
<mybatis-plus.version>3.1.1</mybatis-plus.version>
<sharding-sphere.version>4.0.0-RC2</sharding-sphere.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>- 配置mysql-plus
@Configuration
@MapperScan("com.github.jianzh5.blog.mapper")
public class MybatisPlusConfig {
/**
* 攻击 SQL 阻断解析器
*/
@Bean
public PaginationInterceptor paginationInterceptor(){
PaginationInterceptor paginationInterceptor = new PaginationInterceptor();
List<ISqlParser> sqlParserList = new ArrayList<>();
sqlParserList.add(new BlockAttackSqlParser());
paginationInterceptor.setSqlParserList(sqlParserList);
return new PaginationInterceptor();
}
/**
* SQL执行效率插件
*/
@Bean
// @Profile({"dev","test"})
public PerformanceInterceptor performanceInterceptor() {
return new PerformanceInterceptor();
}
}- 编写实体类Order
@Data
@TableName("t_order")
public class Order {
private Long id;
private String name;
private String type;
private Date gmtCreate;
}- 编写DAO层,OrderMapper
/**
* 订单Dao层
*/
public interface OrderMapper extends BaseMapper<Order> {
}- 编写接口及接口实现
public interface OrderService extends IService<Order> {
}
/**
* 订单实现层
* @author jianzh5
* @date 2019/10/15 17:05
*/
@Service
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements OrderService {
}- 配置文件(配置说明见备注)
server.port=8080
# 配置ds0 和ds1两个数据源
spring.shardingsphere.datasource.names = ds0,ds1
#ds0 配置
spring.shardingsphere.datasource.ds0.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url = jdbc:mysql://192.168.249.129:3306/blog?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.shardingsphere.datasource.ds0.username = root
spring.shardingsphere.datasource.ds0.password = 000000
#ds1 配置
spring.shardingsphere.datasource.ds1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url = jdbc:mysql://192.168.249.131:3306/blog?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.shardingsphere.datasource.ds1.username = root
spring.shardingsphere.datasource.ds1.password = 000000
# 分库策略 根据id取模确定数据进哪个数据库
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column = id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression = ds$->{id % 2}
# 具体分表策略
# 节点 ds0.t_order_0,ds0.t_order_1,ds1.t_order_0,ds1.t_order_1
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = ds$->{0..1}.t_order_$->{0..2}
# 分表字段id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = id
# 分表策略 根据id取模,确定数据最终落在那个表中
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{id % 3}
# 使用SNOWFLAKE算法生成主键
spring.shardingsphere.sharding.tables.t_order.key-generator.column = id
spring.shardingsphere.sharding.tables.t_order.key-generator.type = SNOWFLAKE
#spring.shardingsphere.sharding.binding-tables=t_order
spring.shardingsphere.props.sql.show = true- 编写单元测试,查看结果是否正确
public class OrderServiceImplTest extends BlogApplicationTests {
@Autowired
private OrderService orderService;
@Test
public void testSave(){
for (int i = 0 ; i< 100 ; i++){
Order order = new Order();
order.setName("电脑"+i);
order.setType("办公");
orderService.save(order);
}
}
@Test
public void testGetById(){
long id = 1184489163202789377L;
Order order = orderService.getById(id);
System.out.println(order.toString());
}
}在数据表中查看数据,确认数据正常插入

至此分库分表开发完成
往期回顾
欢迎关注我的个人公众号:JAVA日知录
Springboot2.x + ShardingSphere 实现分库分表的更多相关文章
- 分库分表(5) ---SpringBoot + ShardingSphere 实现分库分表
分库分表(5)--- ShardingSphere实现分库分表 有关分库分表前面写了四篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论) 3. ...
- 分库分表(7)--- SpringBoot+ShardingSphere实现分库分表 + 读写分离
分库分表(7)--- ShardingSphere实现分库分表+读写分离 有关分库分表前面写了六篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理 ...
- 在多数据源中对部分数据表使用shardingsphere进行分库分表
背景 近期在项目中需要使用多数据源,其中有一些表的数据量比较大,需要对其进行分库分表:而其他数据表数据量比较正常,单表就可以. 项目中可能使用其他组的数据源数据,因此需要多数据源支持. 经过调研多数据 ...
- 分库分表(6)--- SpringBoot+ShardingSphere实现分表+ 读写分离
分库分表(6)--- ShardingSphere实现分表+ 读写分离 有关分库分表前面写了五篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论 ...
- 分库分表(3) ---SpringBoot + ShardingSphere 实现读写分离
分库分表(3)---ShardingSphere实现读写分离 有关ShardingSphere概念前面写了两篇博客: 1.分库分表(1) --- 理论 2. 分库分表(2) --- ShardingS ...
- 分库分表(4) ---SpringBoot + ShardingSphere 实现分表
分库分表(4)--- ShardingSphere实现分表 有关分库分表前面写了三篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论) 3.分库 ...
- mysql 分库分表 ~ ShardingSphere生态圈
一 简介 Apache ShardingSphere是一款开源的分布式数据库中间件组成的生态圈二 成员包含 Sharding-JDBC是一款轻量级的Java框架,在JDBC层提供上述核心功能 ...
- 分库分表利器——sharding-sphere
背景 得不到的东西让你彻夜难眠,没有尝试过的技术让我跃跃欲试. 本着杀鸡焉用牛刀的准则,我们倡导够用就行,不跟风,不盲从. 所以,结果就是我们一直没有真正使用分库分表.曾经好几次,感觉没有分库分表(起 ...
- 分库分表(2) --- ShardingSphere(理论)
ShardingSphere---理论 ShardingSphere在中小企业需要分库分表的时候用的会比较多,因为它维护成本低,不需要额外增派人手;而且目前社区也还一直在开发和维护,还算是比较活跃. ...
随机推荐
- odoo12之应用:一、双因子验证(Two-factor authentication, 2FA)(HOTP,TOTP)附源码
前言 双因子认证:双因子认证(2FA)是指结合密码以及实物(信用卡.SMS手机.令牌或指纹等生物标志)两种条件对用户进行认证的方法.--百度百科 跟我一样"老"的网瘾少年想必一定见 ...
- 全网最实用的 Debug调试技巧汇总-Python大佬偷偷使用的神技
一.思考❓❔ 1.什么是debug? 找茬 找软件的茬 发现程序的缺陷 2.为什么需要debug? 谁都不敢保证,写的代码没有任何问题 高效查找软件异常 一位优秀的开发工程师 20%的时间写代码 80 ...
- Go依赖管理及Go module使用
Go语言的依赖管理随着版本的更迭正逐渐完善起来. 依赖管理 为什么需要依赖管理 最早的时候,Go所依赖的所有的第三方库都放在GOPATH这个目录下面.这就导致了同一个库只能保存一个版本的代码.如果不同 ...
- 使用dubbo引用和发布服务时出现的异常:HTTP状态500 - 请求处理失败; 嵌套异常是com.alibaba.dubbo.rpc.RpcException:无法在服务cn.e3mall.service.ItemService中调用方法getTbItemById。使用dubbo版本2.5.3在消费者...
异常情况如下: 从异常看,主要是因为TbItem没有序列化: 分析问题: 表现层调用服务端时返回了一个TbItem对象即Java对象,此时这个对象远程调用拿过来必须进行序列化,要进行网络传输必须先要把 ...
- 配置Linux使用LDAP用户认证
配置Linux使用LDAP用户认证 本文首发:https://www.cnblogs.com/somata/p/LinuxLDAPUserAuthentication.html 我这里使用的是Cent ...
- Spring系列__04AOP
AOP简介 今天来介绍一下AOP.AOP,中文常被翻译为"面向切面编程",其作为OOP的扩展,其思想除了在Spring中得到了应用,也是不错的设计方法.通常情况下,一个软件系统,除 ...
- FreeSql (三十一)分区分表
分区 分区就是把一个数据表的文件和索引分散存储在不同的物理文件中.把一张表的数据分成N多个区块,这些区块可以在同一个磁盘上,也可以在不同的磁盘上,数据库不同实现方式有所不同. 与分表不同,一张大表进行 ...
- 高级部分_委托、Lambda表达式、事件
委托 (1)把方法当作参数来传递的话,就要用到委托: (2)委托是一个类型,这个类型可以赋值一个方法的引用. C#使用一个类分为两个阶段,首先定义这个类,告诉编译器这个类由什么字段和方法组成:然后使用 ...
- unittest核心要素
1 TestCase 一个TestCase的实例就是一个测试用例.什么是测试用例呢?就是一个完整的测试流程, 包括测试环境的准备(setUp),执行测试代码(run),以及测试后环境的还原(tearD ...
- springboot postman 对象里传时间格式问题
主要问题是系列化的问题,在定义时间变量处使用如下的注解即可.导包注意了······ 如果springmvc使用的是com.fasterxml.jackson 的jar包则直接使用一下注解即可 impo ...