卷积神经网络详细讲解 及 Tensorflow实现
【附上个人git完整代码地址:https://github.com/Liuyubao/Tensorflow-CNN】
【如有疑问,更进一步交流请留言或联系微信:523331232】
Reference
本文主要参考以下链接:
- Google《Tensorflow实战》
- http://neuralnetworksanddeeplearning.com/chap6.html
- http://cs231n.github.io/convolutional-networks/
- https://blog.csdn.net/marsjhao/article/details/72900646
- https://blog.csdn.net/cxmscb/article/details/71023576
分为以下几个部分进行讲解
- 从神经网络到卷积神经网络
- 深入卷积神经网络
- 经典卷积神经网络
- 总结
一、从神经网络到卷积神经网络

上面是最基本最普通的神经网络,卷积神经网络跟它是什么关系呢?
其实卷积神经网络依旧是层级网络,只是层的功能和形式做了变化,可以说是传统神经网络的一个改进。比如下图中就多了许多传统神经网络没有的层次。

从以下5层来对神经网络进行介绍:
- 数据输入层/ Input layer
- 卷积计算层/ CONV layer
- ReLU激励层 / ReLU layer
- 池化层 / Pooling layer
- 全连接层 / FC layer
二、深入卷积神经网络
【2.1 数据输入层】
对原始图像数据进行预处理
• 去均值:把输入数据各个维度都中心化为0,如下图所示,其目的就是把样本的中心拉回到坐标系原点上。
• 归一化:幅度归一化到同样的范围,如下所示,即减少各维度数据取值范围的差异而带来的干扰,比如,我们有两个维度的特征A和B,A范围是0到10,而B范围是0到10000,如果直接使用这两个特征是有问题的,好的做法就是归一化,即A和B的数据都变为0到1的范围。
• PCA/白化:用PCA降维;白化是对数据各个特征轴上的幅度归一化

在CNN的输入层中,(图片)数据输入的格式 与 全连接神经网络的输入格式(一维向量)不太一样。
CNN的输入层的输入格式保留了图片本身的结构(多维向量)。
- 黑白: 28×28

- RGB: 3×28×28

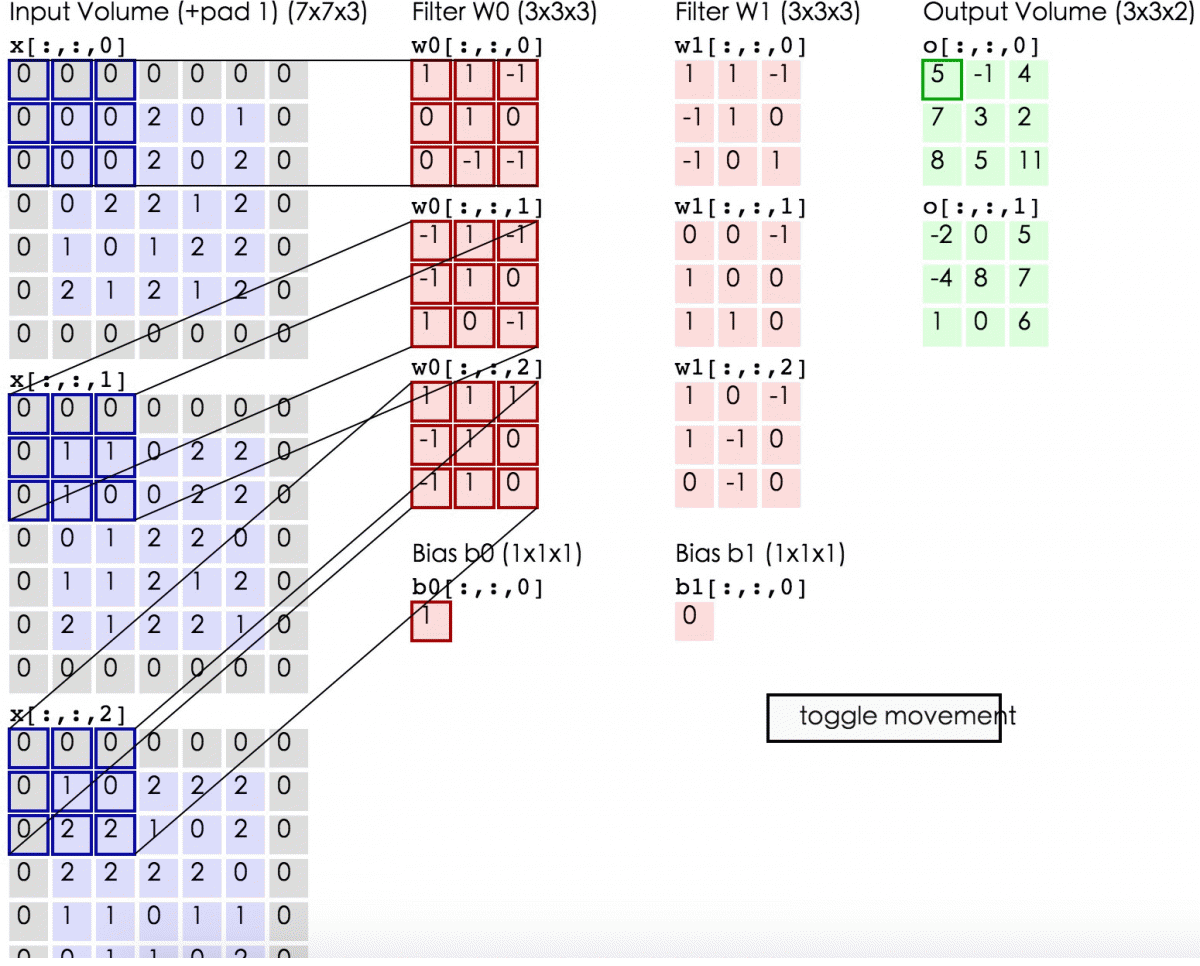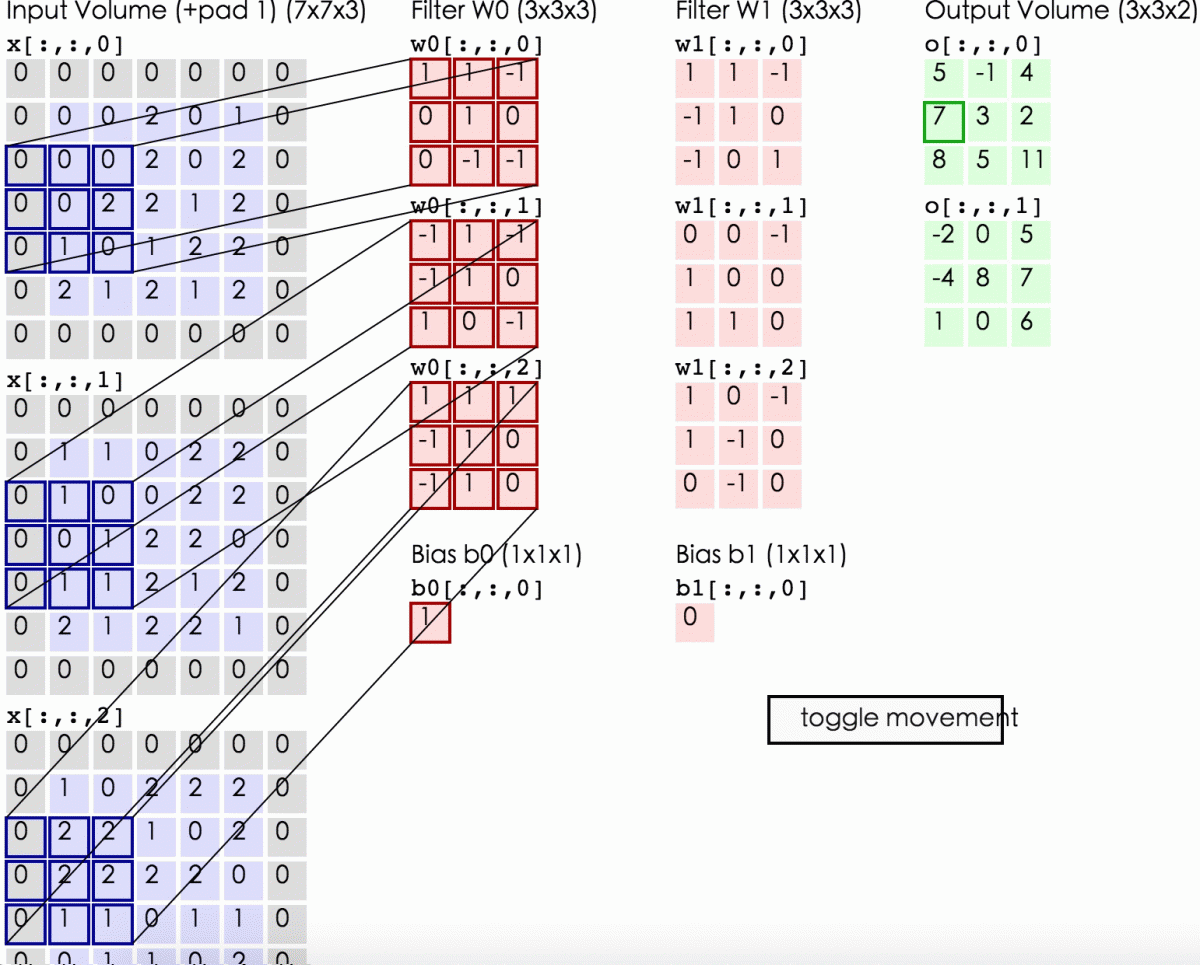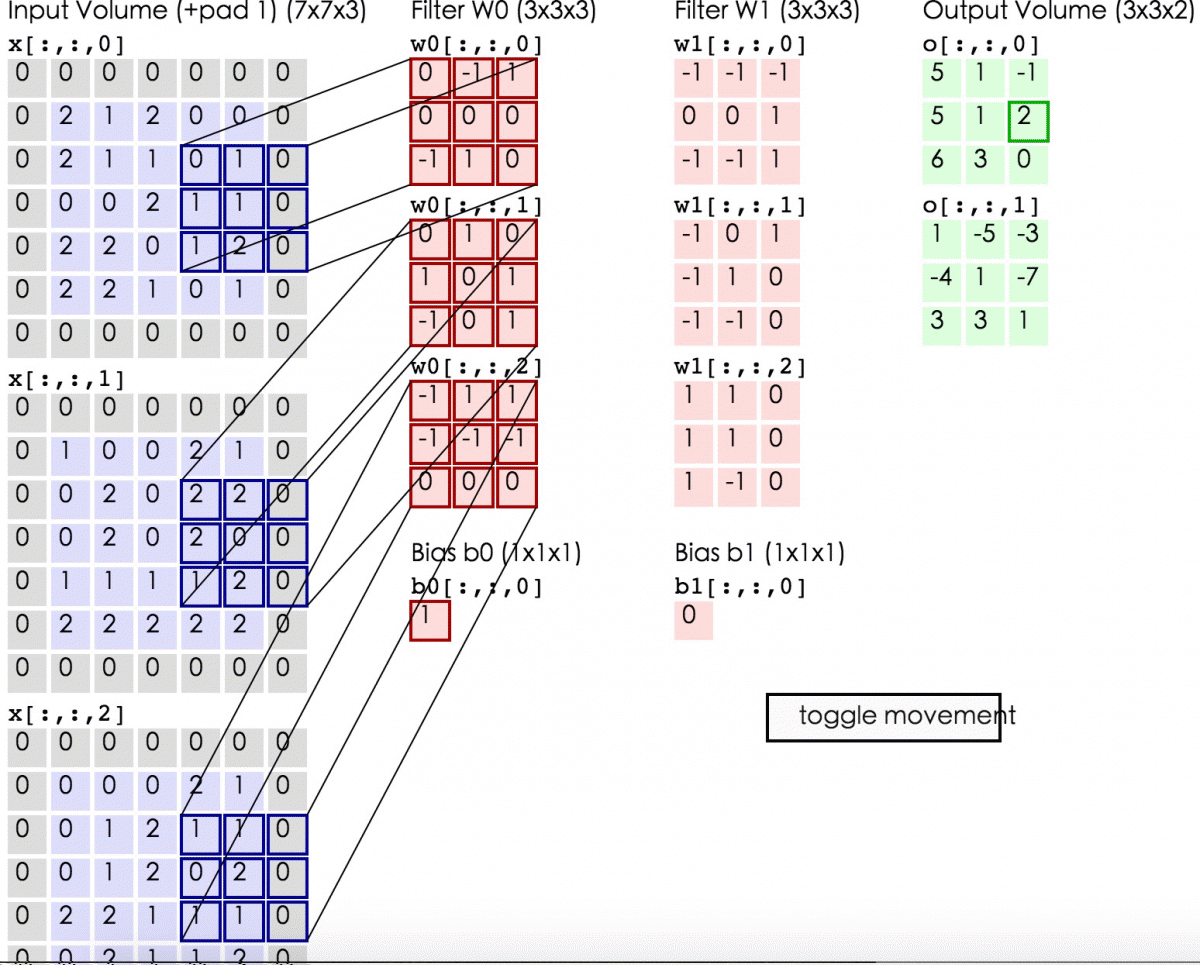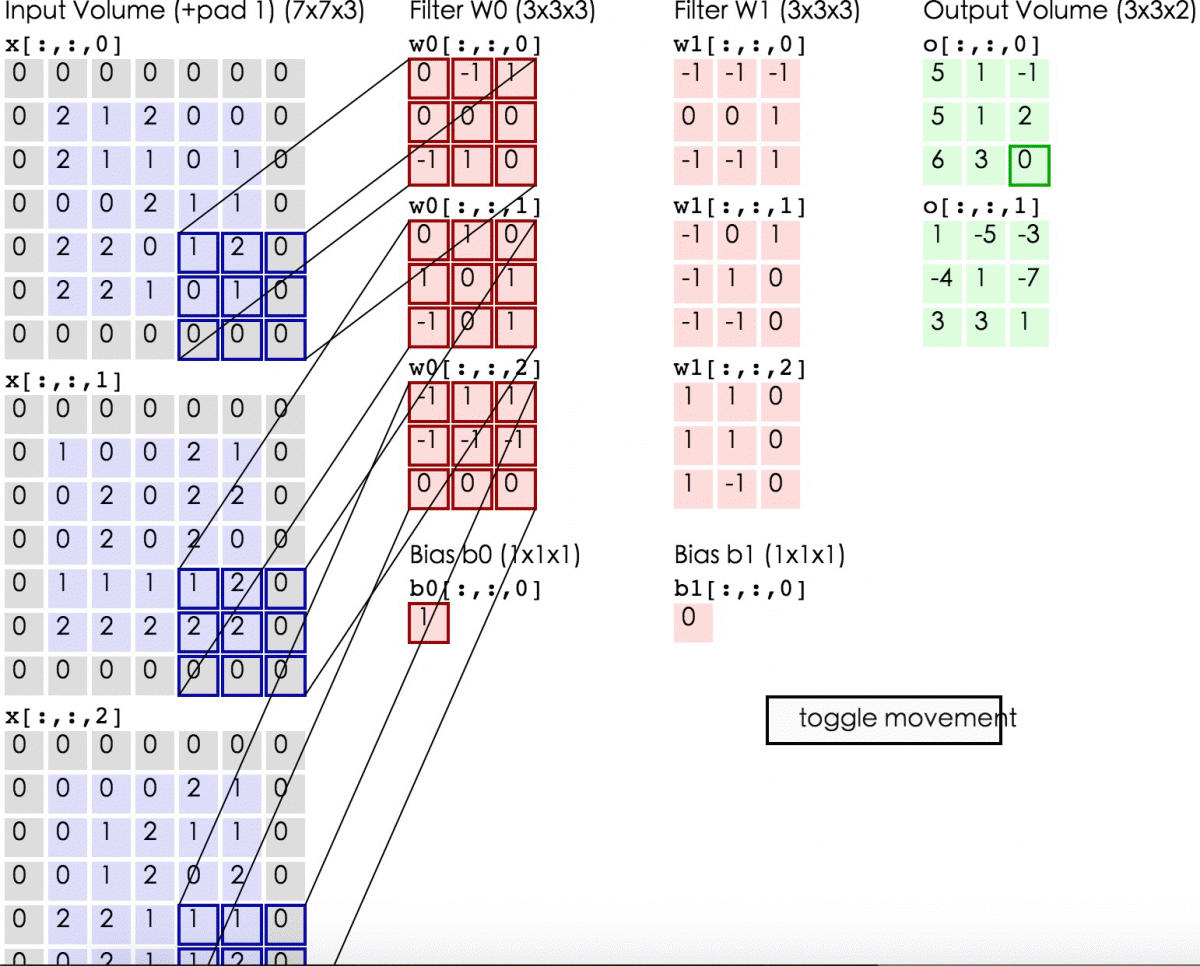
【2.2 卷积计算层】
在卷积层中有2个重要的概念:
local receptive fields(感受视野)
shared weights(共享权值)


设移动的步长为1:从左到右扫描,每次移动 1 格,扫描完之后,再
向下移动一格,再次从左到右扫描。
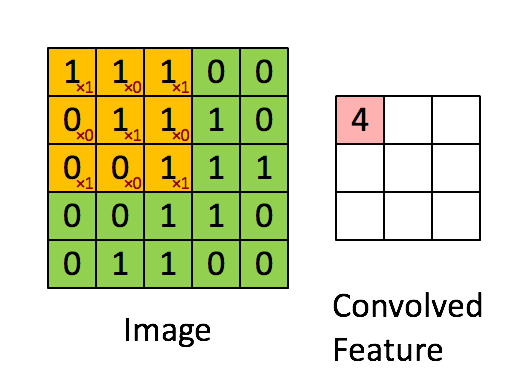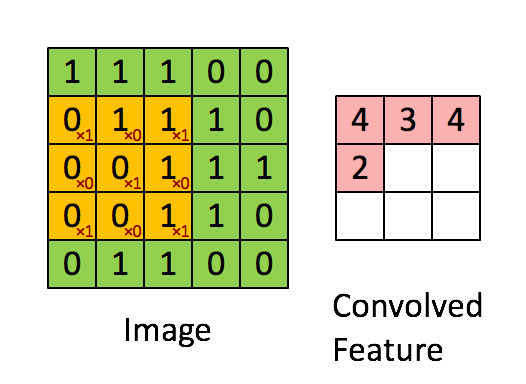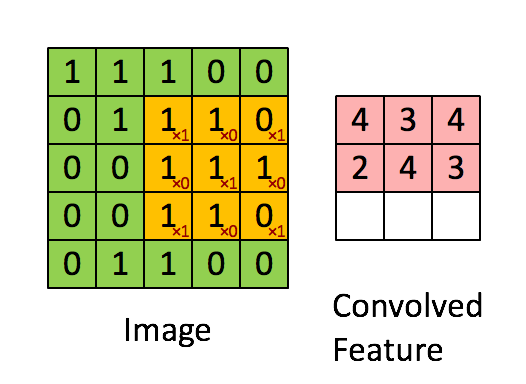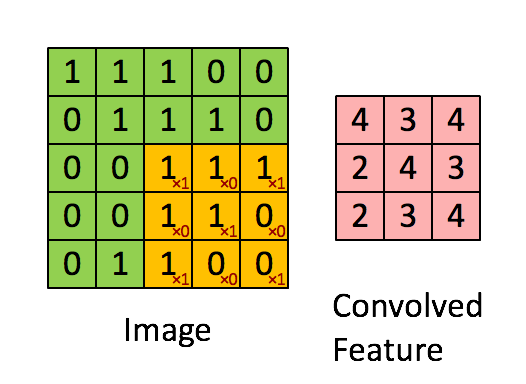
【2.3 激励层】
激励层主要对卷积层的输出进行一个非线性映射,因为卷积层的计算还是一种线性计算。
使用的激励函数一般为ReLu函数:
f(x)=max(x,0)
卷积层和激励层通常合并在一起称为“卷积层”。

【2.4 池化层】
池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。
简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。

池化层用的方法有Max pooling 和 average pooling,而实际用的较多的是Max pooling。
这里就说一下Max pooling,其实思想非常简单。

【2.5 全连接层】
两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。
也就是跟传统的神经网络神经元的连接方式是一样的:

【2.6 卷积神经网络的优缺点】
优点
• 共享卷积核,对高维数据处理无压力
• 无需手动选取特征,训练好权重,即得特征分类效果好
缺点
• 需要调参,需要大样本量,训练最好要GPU
• 物理含义不明确(也就说,我们并不知道没个卷积层到底提取到的是什么特征,而且神经网络本身就是一种难以解释的“黑箱模型”)
三、经典卷积神经网络
- LeNet,这是最早用于数字识别的CNN
- AlexNet, 2012 ILSVRC比赛远超第2名的CNN,比LeNet更深,用多层小卷积层叠加替换单大卷积层。
- ZF Net, 2013 ILSVRC比赛冠军
- GoogLeNet, 2014 ILSVRC比赛冠军
- VGGNet, 2014 ILSVRC比赛中的模型,图像识别略差于GoogLeNet,但是在很多图像转化学习问题(比如object detection)上
效果奇好

【3.1 LeNet】
第一个卷积神经网络,1994年由Yann LeCun基于1988年以来的工作提出,并命名为LeNet5。
贡献
- 在神经网络中引入卷积层
- 引入下采样
- 卷积+池化(下采样)+非线性激活的组合是CNN的典型特征
- 使用MPL作为分类器

【3.2 Dan Ciresan Net】
2010年,Dan Claudiu Ciresan和Jurgen Schmidhuber实现了第一个GPU神经网络。
【3.3 AlexNet】
AlexNet是2012年ImageNet比赛的冠军,第一个基于CNN的ImageNet冠军,网络比LeNet5更深(8层)。
贡献
- 使用ReLU作为非线性激活函数
- 数据扩增
- 使用最大池化
- 使用dropout避免过拟合
- 使用GPU减少训练时间
从AlexNet之后,深度学习就变成了一种叫做”解决任务的更大规模的神经网络”的技术。

【3.4 VGGNet】
VGG是2014年的ImageNet分类的亚军,物体检测冠军,使用了更小的卷积核(3x3),并且连续多层组合使用。
贡献
- 更深
- 连续多个3x3的卷积层
VGG论文的一个主要结论就是深度的增加有益于精度的提升,这个结论堪称经典。

【3.5 GoogleNet】
GoogLeNet是2014年的ImageNet图像分类的冠军,比VGG19多3层,而其参数却只有AlexNet的1/12,同时获得了当时state-of-the-art的结果。
Inception模块使用1x1的卷积(bottleneck layer)减少了特征数量,同时,分类器部分只保留了必要的一个全连接层,极大的降低了运算数量。Inception模块是GoogLeNet以更深的网络和更高的计算效率取得更好的结果的主要原因。 此后,Inception模块不断改进,产生了Inception-2和Inception-3。

【3.6 ResNet】
卷积神经网络模型的发展历程一次次证明加深网络的深度和宽度能得到更好的效果,但是后来的研究发现,网络层次较深的网络模型的效果反而会不如较浅层的网络,称为“退化”现象,如图所示。
退化现象产生的原因在于当模型的结构变得复杂时,随机梯度下降的优化变得更加困难,导致网络模型的效果反而不如浅层网络。

ResNet的基本思想是引入了能够跳过一层或多层的“shortcut connection”,即增加一个identity mapping(恒等映射),将原始所需要学的函数H(x)转换成F(x)+x,而作者认为这两种表达的效果相同,但是优化的难度却并不相同,作者假设F(x)的优化 会比H(x)简单的多。这一想法也是源于图像处理中的残差向量编码,通过一个reformulation,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。

四、总结
卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。
卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
【FAQ】
1.神经网络Vs传统机器学习?
2.CNN与NN输入层的不同?
3.为什么要卷积?
4.为什么要池化?
5.为什么要dropout?
6.损失函数?
7.为什么要softmax?
五、代码
【附上个人git完整代码地址:https://github.com/Liuyubao/Tensorflow-CNN】
【如有疑问,更进一步交流请留言或联系微信:523331232】
【5.1 Tensorflow实现简单CNN】
# -*- coding: UTF-8 -*-
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
sess = tf.InteractiveSession() # 创建一个会话初始化权重函数,truncated_normal创建 标准差为0.1的截断正态函数
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)初始化偏置函数,由于使用ReLU要加一些正值0.1,避免死亡节点(dead neurons)
def bias_variable(shape):
initial = tf.constant(0.1, shape = shape)
return tf.Variable(initial)x:输入 w:卷积参数 例[5, 5, 1, 32]:5, 5为卷积核尺寸
1:为多少channel 彩色是3 灰度是1
32:为卷积核的数量(这个卷积层会提取的多少类特征)
strides:卷积模板移动的步长,[1, 2, 2, 1]官方前后必须为1,中间两个分别代表横向和竖向
padding:代表边界处理方式,SAME即输入和输出保持同样尺寸
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides = [1, 1, 1, 1], padding = 'SAME')池化层函数 max_pool:最大池化函数
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],
padding='SAME')#x:特征
x = tf.placeholder(tf.float32, [None, 784])
#y_真实的label
y_ = tf.placeholder(tf.float32, [None, 10])卷积神经网络会利用到原有的空间结构信息,因此需要将1D的输入向量转化为2D图片结构(1x784->28x28)
因为只有一个颜色通道,故最终尺寸为[-1, 28, 28, 1]其中:-1代表样本数量不固定,1代表颜色通道数量
x_image = tf.reshape(x, [-1, 28, 28, 1])先定义weights和bias,然后使用conv2d函数进行卷积操作并加上偏置,
接着使用ReLU激活函数进行非线性处理,最好使用max_pool_2x2对卷积的输出结果进行池化操作
w_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1)+b_conv1)
h_pool1 = max_pool_2x2(h_conv1)定义第二个卷积层,不同在于特征变为64
w_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2)+b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
经历两次2x2步长的最大池化,边长变为1/4,图片尺寸由28x28->7x7
由于第二个卷积层的卷积核数量为64,其输出tensor尺寸为7x7x64。
使用tf.reshape函数对其变形,转化为1D向量,然后连接一个全连接层,
隐含节点为1024,并使用Relu激活函数
w_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1)+b_fc1)为减轻过拟合,使用一个dropout层
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)dropout层输出连softmax层,得到最后的概率输出
w_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, w_fc2)+b_fc2)
定义损失函数 cross_entropy
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y_conv),
reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
评测准确率
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
开始训练,mini-batch为50, 20000次迭代,每100次输出评测结果
tf.global_variables_initializer().run()
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, train accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
在测试集上进行测试
print("test accuracy%g"%accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))结果展示:

【5.2 Tensorflow实现进阶CNN】
使用的数据集是CIFAR-10,这是一个经典的数据集,包含了60000张32*32的彩色图像,其中训练集50000张,测试集10000张,如同其名字,CIFAR-10数据集一共标注为10类,每一类6000张图片,这10类分别是airplane、automobile、bird、cat、deer、dog、frog、horse、ship和truck。类别之间没有重叠,也不会一张图片中出现两类物体,其另一个数据集CIFAR-100则标注了100类。

更多CIFAR相关的信息请参见:http://www.cs.toronto.edu/~kriz/cifar.html
载入常用库部分首先要添加CIFAR-10相关的cifar10和cifar10_input模块,定义最大迭代轮数max_steps等宏观参数。
定义初始化权重weight的函数,使用截断的正态分布来初始化权重。这里通过一个参数wl来控制对weight的正则化处理。在机器学习中,无论是分类还是回归任务,都可能会因特征过多而导致过拟合问题,一般通过特征选取或惩罚不重要的特征的权重来解决这个问题。但是对于哪些特征是不重要的,我们并不能直观得出,而正则化就是帮助我们惩罚特征权重的,即特征的权重也是损失函数的一部分。可以理解为为了使用某个特征需要付出代价,如果不是这个特征对于减少损失函数非常有效其权重就会被惩罚减小。这样就可以有效的筛选出有效的特征,通过减少特征权重防止过拟合,即奥卡姆剃刀原则(越简单越有效)。L1正则化会制造稀疏的特征,大部分无用的特征直接置为0,而L2正则化会让特征的权重不会过大,使特征的权重比较平均。对于实现L2正则化,有两种方法,tf.multiply(tf.nn.l2_loss(var), wl)其中wl是正则化系数;tf.contrib.layers.l2_regularizer(lambda)(var)其中lambda是正则化系数。
随后使用cifar10模块来下载数据集并解压、展开到默认位置。再用cifar10_input模块来产生数据。其中cifar10_input.distorted_inputs()和cifar10_input.inputs()函数都是TensorFlow的操作operation,操作返回封装好的Tensor,这就需要在会话中run来实际运行。cifar10_input.distorted_inputs()对数据进行了DataAugmentation(数据增强),包括了随机的水平翻转、随机剪切一块24*24的图片、设置随机的亮度和对比度以及对数据进行标准化。通过这些操作,我们可以获得更多的带噪声的样本,扩大了样本容量,对提高准确率有所帮助。需要注意的是,对图像数据进行增强操作会耗费大量的CPU计算时间,因此函数内部使用了16个独立的线程来加速任务,函数内部会产生线程池,在需要时会通过TensorFlow queue进行调度,通过tf.train.start_queue_runners()来启动线程队列。产生测试数据集时则不需要太多操作,仅需要裁剪图片正中间的24*24大小的区块并进行数据标准化操作。
创建第一个卷积层,首先通过variable_with_weight_loss函数创建卷积核的参数并进行初始化,卷积核尺寸为5*5,3个颜色通道,64个卷积核(卷积核深度为64),设置weight初始化标准差为0.05(5e-2),不对第一层卷积层的weight进行L2正则化处理,即wl设为0。在ReLU激活函数之后,我们采用一个3*3的步长为2*2的池化核进行最大池化处理,注意这里最大池化的尺寸和步长不一致,这样可以增加数据的丰富性。随后我们使用tf.nn.lrn()函数,即对结果进行LRN处理。LRN层(局部响应归一化层)模仿了生物神经系统的“侧抑制”机制,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。LRN对ReLU这种没有上限边界的激活函数比较试用,不适合于Sigmoid这种有固定边界并且能抑制过大值的激活函数。
相似的步骤创建卷积层2,注意权重weight的shape中,通道数为64,bias初始化为0.1,最后的最大池化层和LRN层调换了顺序,先进行LRN层处理后进行最大池化处理。
两个卷积层后使用一个全连接层3,首先将卷积层的输出的样本都reshape为一维向量,获取每个样本的长度后作为全连接层的输入单元数,输出单元数设为384。权重weight初始化并设置L2正则化系数为0.004,我们希望这一层全连接层不要过拟合。
接下来的全连接层4和前一层很像,隐含节点减少一半到192。全连接层5也类似,隐含单元变为最终的分类总数10。
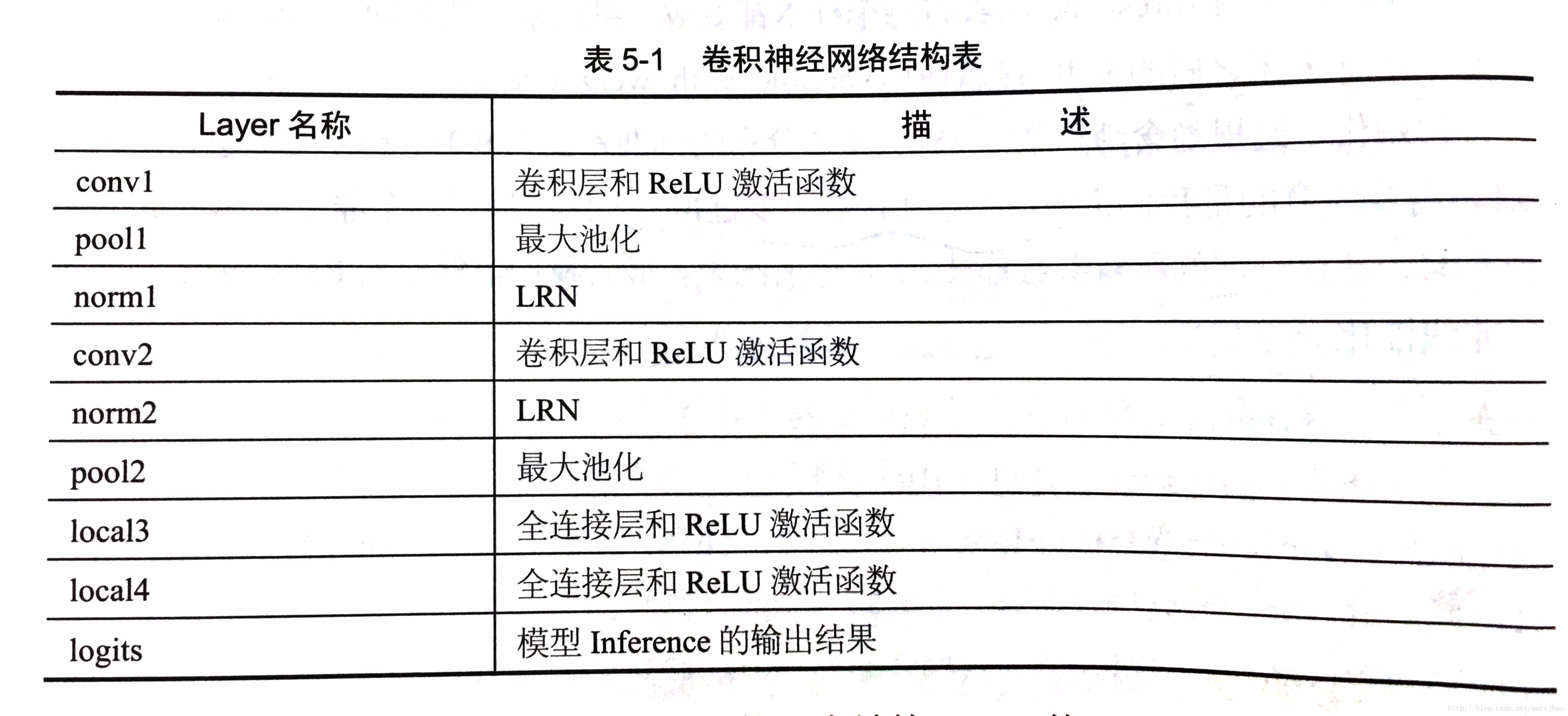
至此,整个网络的inference部分已经完成,网络结构如下表:
# -*- coding: UTF-8 -*-
import cifar10, cifar10_input
import tensorflow as tf
import numpy as np
import time
max_steps = 50 # 最大迭代轮数
batch_size = 128 # 批大小
data_dir = '/tmp/cifar10_data/cifar-10-batches-bin' # 数据所在路径
# 初始化weight函数,通过wl参数控制L2正则化大小
def variable_with_weight_loss(shape, stddev, wl):
var = tf.Variable(tf.truncated_normal(shape, stddev=stddev))
if wl is not None:
# L2正则化可用tf.contrib.layers.l2_regularizer(lambda)(w)实现,自带正则化参数
weight_loss = tf.multiply(tf.nn.l2_loss(var), wl, name='weight_loss')
tf.add_to_collection('losses', weight_loss)
return var
cifar10.maybe_download_and_extract()
# 此处的cifar10_input.distorted_inputs()和cifar10_input.inputs()函数
# 都是TensorFlow的操作operation,需要在会话中run来实际运行
# distorted_inputs()函数对数据进行了数据增强
images_train, labels_train = cifar10_input.distorted_inputs(data_dir=data_dir,
batch_size=batch_size)
# 裁剪图片正中间的24*24大小的区块并进行数据标准化操作
images_test, labels_test = cifar10_input.inputs(eval_data=True,
data_dir=data_dir,
batch_size=batch_size)
# 定义placeholder
# 注意此处输入尺寸的第一个值应该是batch_size而不是None
image_holder = tf.placeholder(tf.float32, [batch_size, 24, 24, 3])
label_holder = tf.placeholder(tf.int32, [batch_size])
# 卷积层1,不对权重进行正则化
weight1 = variable_with_weight_loss([5, 5, 3, 64], stddev=5e-2, wl=0.0) # 0.05
kernel1 = tf.nn.conv2d(image_holder, weight1,
strides=[1, 1, 1, 1], padding='SAME')
bias1 = tf.Variable(tf.constant(0.0, shape=[64]))
conv1 = tf.nn.relu(tf.nn.bias_add(kernel1, bias1))
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1], padding='SAME')
norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)
# 卷积层2
weight2 = variable_with_weight_loss([5, 5, 64, 64], stddev=5e-2, wl=0.0)
kernel2 = tf.nn.conv2d(norm1, weight2, strides=[1, 1, 1, 1], padding='SAME')
bias2 = tf.Variable(tf.constant(0.1, shape=[64]))
conv2 = tf.nn.relu(tf.nn.bias_add(kernel2, bias2))
norm2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)
pool2 = tf.nn.max_pool(norm2, ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1], padding='SAME')
# 全连接层3
reshape = tf.reshape(pool2, [batch_size, -1]) # 将每个样本reshape为一维向量
dim = reshape.get_shape()[1].value # 取每个样本的长度
weight3 = variable_with_weight_loss([dim, 384], stddev=0.04, wl=0.004)
bias3 = tf.Variable(tf.constant(0.1, shape=[384]))
local3 = tf.nn.relu(tf.matmul(reshape, weight3) + bias3)
# 全连接层4
weight4 = variable_with_weight_loss([384, 192], stddev=0.04, wl=0.004)
bias4 = tf.Variable(tf.constant(0.1, shape=[192]))
local4 = tf.nn.relu(tf.matmul(local3, weight4) + bias4)
# 全连接层5
weight5 = variable_with_weight_loss([192, 10], stddev=1 / 192.0, wl=0.0)
bias5 = tf.Variable(tf.constant(0.0, shape=[10]))
logits = tf.matmul(local4, weight5) + bias5
# 定义损失函数loss
def loss(logits, labels):
labels = tf.cast(labels, tf.int64)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=logits, labels=labels, name='cross_entropy_per_example')
cross_entropy_mean = tf.reduce_mean(cross_entropy, name='cross_entropy')
tf.add_to_collection('losses', cross_entropy_mean)
return tf.add_n(tf.get_collection('losses'), name='total_loss')
loss = loss(logits, label_holder) # 定义loss
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss) # 定义优化器
top_k_op = tf.nn.in_top_k(logits, label_holder, 1)
# 定义会话并开始迭代训练
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
# 启动图片数据增强的线程队列
tf.train.start_queue_runners()
# 迭代训练
for step in range(max_steps):
start_time = time.time()
image_batch, label_batch = sess.run([images_train, labels_train]) # 获取训练数据
_, loss_value = sess.run([train_op, loss],
feed_dict={image_holder: image_batch,
label_holder: label_batch})
duration = time.time() - start_time # 计算每次迭代需要的时间
if step % 10 == 0:
examples_per_sec = batch_size / duration # 每秒处理的样本数
sec_per_batch = float(duration) # 每批需要的时间
format_str = ('step %d, loss=%.2f (%.1f examples/sec; %.3f sec/batch)')
print(format_str % (step, loss_value, examples_per_sec, sec_per_batch))
# 在测试集上测评准确率
num_examples = 10000
import math
num_iter = int(math.ceil(num_examples / batch_size))
true_count = 0
total_sample_count = num_iter * batch_size
step = 0
while step < num_iter:
image_batch, label_batch = sess.run([images_test, labels_test])
predictions = sess.run([top_k_op],
feed_dict={image_holder: image_batch,
label_holder: label_batch})
true_count += np.sum(predictions)
step += 1
precision = true_count * 1.0 / total_sample_count
print('precision @ 1 = %.3f' % precision)
'''
step 2900, loss=1.14 (363.7 examples/sec; 0.352 sec/batch)
step 2910, loss=1.05 (372.0 examples/sec; 0.344 sec/batch)
step 2920, loss=1.26 (368.7 examples/sec; 0.347 sec/batch)
step 2930, loss=1.09 (366.4 examples/sec; 0.349 sec/batch)
step 2940, loss=1.02 (366.6 examples/sec; 0.349 sec/batch)
step 2950, loss=1.30 (365.9 examples/sec; 0.350 sec/batch)
step 2960, loss=0.91 (367.1 examples/sec; 0.349 sec/batch)
step 2970, loss=0.96 (364.2 examples/sec; 0.351 sec/batch)
step 2980, loss=1.13 (361.8 examples/sec; 0.354 sec/batch)
step 2990, loss=0.97 (356.0 examples/sec; 0.360 sec/batch)
precision @ 1 =0.702
'''【附上个人git完整代码地址:https://github.com/Liuyubao/Tensorflow-CNN】
【如有疑问,更进一步交流请留言或联系微信:523331232】
卷积神经网络详细讲解 及 Tensorflow实现的更多相关文章
- 卷积神经网络CNN原理以及TensorFlow实现
在知乎上看到一段介绍卷积神经网络的文章,感觉讲的特别直观明了,我整理了一下.首先介绍原理部分. [透析] 卷积神经网络CNN究竟是怎样一步一步工作的? 通过一个图像分类问题介绍卷积神经网络是如何工作的 ...
- CNN(卷积神经网络)原理讲解及简单代码
一.原理讲解 1. 卷积神经网络的应用 分类(分类预测) 检索(检索出该物体的类别) 检测(检测出图像中的物体,并标注) 分割(将图像分割出来) 人脸识别 图像生成(生成不同状态的图像) 自动驾驶 等 ...
- TensorFlow实战第八课(卷积神经网络CNN)
首先我们来简单的了解一下什么是卷积神经网路(Convolutional Neural Network) 卷积神经网络是近些年逐步兴起的一种人工神经网络结构, 因为利用卷积神经网络在图像和语音识别方面能 ...
- 【翻译】TensorFlow卷积神经网络识别CIFAR 10Convolutional Neural Network (CNN)| CIFAR 10 TensorFlow
原网址:https://data-flair.training/blogs/cnn-tensorflow-cifar-10/ by DataFlair Team · Published May 21, ...
- 使用 Estimator 构建卷积神经网络
来源于:https://tensorflow.google.cn/tutorials/estimators/cnn 强烈建议前往学习 tf.layers 模块提供一个可用于轻松构建神经网络的高级 AP ...
- UFLDL深度学习笔记 (六)卷积神经网络
UFLDL深度学习笔记 (六)卷积神经网络 1. 主要思路 "UFLDL 卷积神经网络"主要讲解了对大尺寸图像应用前面所讨论神经网络学习的方法,其中的变化有两条,第一,对大尺寸图像 ...
- 4.3CNN卷积神经网络最详细最容易理解--tensorflow源码MLP对比
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取: https://www.cnblogs.com/bclshuai/p/11380657.html 1.1 CNN卷积神经网络 ...
- AI相关 TensorFlow -卷积神经网络 踩坑日记之一
上次写完粗浅的BP算法 介绍 本来应该继续把 卷积神经网络算法写一下的 但是最近一直在踩 TensorFlow的坑.所以就先跳过算法介绍直接来应用场景,原谅我吧. TensorFlow 介绍 TF是g ...
- TensorFlow构建卷积神经网络/模型保存与加载/正则化
TensorFlow 官方文档:https://www.tensorflow.org/api_guides/python/math_ops # Arithmetic Operators import ...
随机推荐
- springboot 项目打包部署后设置上传文件访问的绝对路径
1.设置绝对路径 application.properties的配置 #静态资源对外暴露的访问路径 file.staticAccessPath=/upload/** #文件上传目录(注意Linux和W ...
- 【ADO.NET基础-GridView】GridView的编辑、更新、取消、删除以及相关基础操作代码
代码都是基础操作,后续功能还会更新,如有问题欢迎提出和提问....... 前台代码: <asp:GridView ID=" OnRowDataBound="GridView1 ...
- docker 更新后出现 error during connect
docker更新后出现 error during connect: Get http://%2F%2F.%2Fpipe%2Fdocker_engine/v1.39/containers/json: o ...
- php数字函数
is_numeric() 检查变量是否包含一个合法数字 round() 取整数,四舍五入 round(数字, 小数位) ceil() 向上取整 floor() 向下取整 range() 生成范围 ...
- HashMap 取数算法
Map,百度翻译给我的解释是映射,在Java编程中,它是存储键值对(key-value)的一种容器,也是Java程序员常用的对象.这篇博客介绍下HashMap的实现:java是面向对象编程语言,jdk ...
- 程序员修神之路--设计一套RPC框架并非易事
菜菜哥,我最近终于把Socket通信调通了 这么底层的东西你现在都会了,恭喜你离涨薪又进一步呀 http协议不也是利用的Socket吗 可以这么说,http协议是基于TCP协议的,底层的数据传输可以说 ...
- [插件化开发] 1. 初识OSGI
初识 OSGI 背景 当前product是以solution的方式进行售卖,但是随着公司业务规模的快速夸张,随之而来的是新客户的产品开发,老客户的产品维护,升级以及修改bug,团队的效能明显下降,为了 ...
- iOS性能优化-预排版
参考地址:https://blog.ibireme.com/2015/11/12/smooth_user_interfaces_for_ios/ 前面一篇说了异步绘制文字,异步渲染图片,这篇主要是预排 ...
- 网络游戏开发-客户端2(自定义websocket协议格式)
Egret官方提供了一个Websocket的库,可以让我们方便的和服务器长连接交互. 标题写的时候自定义websocket的协议格式.解释一下,不是说我们去动websocket本身的东西,我们是在we ...
- session,cookie,sessionStorage,localStorage的相关设置以及获取删除
一.cookie 什么是 Cookie? "cookie 是存储于访问者的计算机中的变量.每当同一台计算机通过浏览器请求某个页面时,就会发送这个 cookie.你可以使用 JavaScrip ...