hbase性能优化,看这篇就够了
HDFS(hdfs-site.xml)相关调整
- dfs.datanode.synconclose = true
dfs.datanode.synconclose set to false in hdfs-site.xml: data loss is possible on hard system reset or power loss
- mount ext4 with dirsync! Or use XFS
- dfs.datanode.sync.behind.writes = true (default false)
设置为true,在数据写入完成之后,datanode会要求操作系统将数据直接同步到磁盘
- dfs.namenode.avoid.read.stale.datanode = true (default false)
- dfs.namenode.avoid.write.stale.datanode = true (default false)
- dfs.namenode.stale.datanode.interval = 30000 (default 30000)
避免读写declared dead的datanode,datanode会发送心跳给namenode,如果超过了dfs.namenode.stale.datanode.interval的时间还未接收到datanode的心跳,则认为该datanode为stale状态,也就会将datanode declare成dead。默认情况下,namenode仍然会对stale状态的datanode读
- dfs.datanode.failed.volumes.tolerated = <N>
keep DN running with some failed disks,tolerate losing this many disks,根据磁盘实际配置数量调整
- dfs.client.read.shortcircuit = true
启用短路径读取(short-circuit): 当client请求数据时,datanode会读取数据然后通过TCP协议发送给client,short-circuit绕过了datanode直接读取数据。 ,并且datanode和regionserver共处一个节点。 除此之后,指标Locality(数据本地性)需要额外关注,因为更高的数据本地性,可以使短路径发挥更好的性能
- dfs.datanode.max.transfer.threads = 8192 (default 4096)
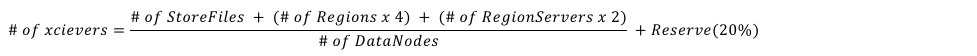
Specifies the maximum number of threads to use for transferring data in and out of the DN. An HDFS DataNode has an upper bound on the number of files that it will serve at any one time详见:https://hbase.apache.org/book.html#dfs.datanode.max.transfer.threadshttp://www.larsgeorge.com/2012/03/hadoop-hbase-and-xceivers.html
- dfs.namenode.handler.count = 64 (default 10)
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
- dfs.datanode.handler.count = 8 (default 10)
The number of server threads for the datanode.
HBase(hbase-site.xml)相关调整
- hbase.hstore.blockingStoreFiles = 16
- hbase.hregion.memstore.block.multiplier = 4
- hbase.hregion.memstore.flush.size = 128
如果storefile的数量超过了10个,就会阻塞flush,compact线程进行合并(如果观察日志,你会看到类似"Too many HFiles, delaying flush"之类的输出),如果想让数据写入更加平滑或者业务写入量巨大,可以考虑增大该值。另外,在达到了blockingStoreFiles阀值的时候,开始阻塞flush,那么memstore就会膨胀,当memstore膨胀到 flush size 乘于 multiplier(flush size X multiplier)的时候,这个列簇的写操作就会被阻塞,一直到flush完成(可以关注日志,会有相关日志输出)。所以如果写入量巨大,建议同时增加multiplier大小,至于flush size的大小,一般默认即可
- hbase.regionserver.handler.count = 30
每个regionserver启动的RPC Listener实例个数,hbase.master.handler.count参数意思跟它基本一样。handler个数并非越多越好,如果设置了过多的handler可能得到一个适得其反的结果。如果是read-only的场景,handler的个数接近与cpu个数比较好。在调整该参数时候,建议设置为cpu个数的倍数,从两倍cpu个数开始调整。
- hbase.hregion.max.filesize = 10G
控制region split的阀值,需要注意:如果有多个列簇,不管哪个列簇达到了该值,就会触发split,并且是region级别的,哪怕其他的列簇的hfile值还很小目前来说,推荐的最大region size为10-20G,当然也可以设置的更大,比如50G(如果设置了压缩,该值指的是压缩之后的大小)
- hbase.regionserver.region.split.policy = SteppingSplitPolicy
split算法有多种,不一一介绍了。默认是SteppingSplitPolicy算法,可以根据实际场景情况选择更为合适的,比如对于已知数据大小的历史数据,可以将表的split算法设置为org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy,以实现更好的控制region数目
- zookeeper.session.timeout = 90000(default,in milliseconds)
regionserver与zookeeper建立session,zookeeper通过session来确认regionserver的状态,每个regionserver在zookeeper中都有自己的临时znode。如果建立的session断开了或者超时了(比如gc或者网络问题),那么zk中的这个regionserver的临时znode将被删除,并且该regionserver标记为crashed。 .在设置该参数值需要注意,要关注zookeeper server的Minimum session timeout和Maximum session timeout,zookeeper默认Minimum session timeout 为 X tick x tick time,tick time为心跳间隔(默认2秒)。 也就是说你在hbase侧设置的最大会话超时时间在是以client的身份设置的,所以最终还是以zookeeper server为主。(在cdh集群中,如果hbase的该参数值大于zk server的最大会话超时时间,会提示你修改),比如你在hbase侧设置最大超时时间为90s,但是zk的最大超时时间是40s,那么最终还是如果超过40s便视为超时。 .如果想增加hbase超时时间限制,可以提高tick time的值,但是建议不要超过5秒,超过5秒不利于zookeeper集群的正常运行 .对于那种failing quickly is better than waiting的应用,可以将超时时间限定小一些(建议值20秒-30秒),但是在此之前,你需要对GC的时间有一个良好的控制。否则会因为GC导致regionserver频繁被标记为crashed
- hbase.regionserver.thread.compaction.small = 1 (default)
用于minor compact的线程数,当compact quene比较高的时候,建议增加该值。但是需要注意的是:该线程数永远不要超过你可用磁盘数目的一半。 比如:你有8块SSDs, 该值不要超过4 同理hbase.hstore.flusher.count
- hbase.regionserver.hlog.blocksize = 128M (default)
默认即可,但是需要了解的是WAL一般在达到该值的95%的时候就会滚动
- hbase.regionserver.maxlogs = 32 (default)
配置WAL Files的数量,(WAL:to recover memstore data not yet flushed to disk if a RegionServer crashes),WAL files过少的话,会触发更多的flush,太多的话,hbase recovery时间会比较长。
根据不同的regionserver堆大小设置不同数量的WAL。有一个经验公式:
(regionserver_heap_size * memstore fraction) / (default_WAL_size)
例如,HBase集群配置如下:
• GB RegionServer heap
• 0.4 memstore fraction
• MB default WAL size
The formula for this configuration looks as follows:
( MB * MB = approximately WAL files
注意:如果recovery的时间过长,可以减小上面计算的值
- hbase.wal.provider = mutiwal
默认情况下,一个regionserver只有一个wal文件,所有region的walEntry都写到这个wal文件中,在HBase-5699之后,一个regionserver可以配置多个wal文件,这样可以提高写WAL时的吞吐,进而降低数据写延时,其中配置hbase.wal.regiongrouping.strategy决定了每个region写入wal时的分组策略,默认是bounded,表示每个regiongroup写入固定数量个wal;
Multiple Wal:HBASE-(available +)
.版本低于1.2.0 replication存在问题
.写入性能较单WAL提升20%
.hbase.wal.regiongrouping.strategy = bounded(分组策略)
.hbase.wal.regiongrouping.numgroups = (根据盘数设置)
注意:hbase.regionserver.maxlogs,决定了一个regionserver中wal文件的最大数量,默认是32,在上述配置下,如果仍旧设置保持32,等价于不使用multiwal时的64;
HBase表属性调整
Compression
.可以选择的有NONE, GZIP, SNAPPY, 等等
.指定压缩方式:create ’test', {NAME => ’cf', COMPRESSION => 'SNAPPY’}}
.节省磁盘空间
.压缩针对的是整个块,对get或scan不太友好
.缓存块的时候不会使用压缩,除非指定hbase.block.data.cachecompressed = true,这样可以缓存更多的块,但是读取数据时候,需要进行解压缩
HFile Block Size
. 不等同于HDFS block size
. 指定BLOCKSIZE属性
create ‘test′,{NAME => ‘cf′, BLOCKSIZE => ’'}
.默认64KB,对Scan和Get等同的场景比较友好
.增加该值有利于scan
.减小该值有利于get
Garbage Collection优化
目前对于hbase来说,G1 GC使用比较多,后续单独对G1 GC优化写一篇文章...
RegionServer节点硬件配置
大多时候,对于hbase集群我们会面临这样的一些问题:
• 应该分配多少的RAM/heap?
• 应该准备多少块磁盘?
• 磁盘的大小应该多大?
• 网卡带宽?
• 应该有多少个cpu core?
regionserver的磁盘大小与堆大小是有一个比例的: Disk/Heap ratio: RegionSize / MemstoreSize *ReplicationFactor *HeapFractionForMemstores * 那么在默认情况下,该比例等于:10gb/128mb * * = 也就是说: 在磁盘上每存储192字节的数据,对应堆的大小应为1字节 那么如果设置32G的堆,磁盘上也就是可以存储大概6TB的数据(32gb * = 6tb)
理想状况下regionserver的硬件配置:
.每个节点<=6TB的磁盘空间
.regionserver heap 约等于磁盘大小/(上面的比例公式)
.由于hbase属于cpu密集型,所以较多的cpu core数量更适合
.网卡带宽和磁盘吞吐量的匹配值:
(背景:磁盘使用传统HDD,I/O 100M/s)
CASE1:1GE的网卡,配备24块磁盘,像这样的搭配是不太理想的,因为1GE的网卡流量等于125M/s,而24块磁盘的吞吐量大概2.4GB/s,网卡成为瓶颈
CASE2:10GE的网卡,配备24块磁盘,比较理想
CASE3:1GE的网卡,配置4-6块磁盘,也是比较理想的
hbase性能优化,看这篇就够了的更多相关文章
- Nginx 性能优化有这篇就够了!
目录: 1.Nginx运行工作进程数量 Nginx运行工作进程个数一般设置CPU的核心或者核心数x2.如果不了解cpu的核数,可以top命令之后按1看出来,也可以查看/proc/cpuinfo文件 g ...
- 转:Nginx 性能优化有这篇就够了!
目录: https://mp.weixin.qq.com/s/YoZDzY4Tmj8HpQkSgnZLvA 1.Nginx运行工作进程数量 Nginx运行工作进程个数一般设置CPU的核心或者核心数x2 ...
- Vue学习看这篇就够
Vue -渐进式JavaScript框架 介绍 vue 中文网 vue github Vue.js 是一套构建用户界面(UI)的渐进式JavaScript框架 库和框架的区别 我们所说的前端框架与库的 ...
- Python GUI之tkinter窗口视窗教程大集合(看这篇就够了) JAVA日志的前世今生 .NET MVC采用SignalR更新在线用户数 C#多线程编程系列(五)- 使用任务并行库 C#多线程编程系列(三)- 线程同步 C#多线程编程系列(二)- 线程基础 C#多线程编程系列(一)- 简介
Python GUI之tkinter窗口视窗教程大集合(看这篇就够了) 一.前言 由于本篇文章较长,所以下面给出内容目录方便跳转阅读,当然也可以用博客页面最右侧的文章目录导航栏进行跳转查阅. 一.前言 ...
- 【转载】 Spark性能优化指南——基础篇
转自:http://tech.meituan.com/spark-tuning-basic.html?from=timeline 前言 开发调优 调优概述 原则一:避免创建重复的RDD 原则二:尽可能 ...
- 【转】【技术博客】Spark性能优化指南——高级篇
http://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651745207&idx=1&sn=3d70d59cede236e ...
- 【转】Spark性能优化指南——基础篇
http://mp.weixin.qq.com/s?__biz=MjM5NDMwNjMzNA==&mid=2651805828&idx=1&sn=2f413828d1fdc6a ...
- .NET Core实战项目之CMS 第二章 入门篇-快速入门ASP.NET Core看这篇就够了
作者:依乐祝 原文链接:https://www.cnblogs.com/yilezhu/p/9985451.html 本来这篇只是想简单介绍下ASP.NET Core MVC项目的(毕竟要照顾到很多新 ...
- 想了解SAW,BAW,FBAR滤波器的原理?看这篇就够了!
想了解SAW,BAW,FBAR滤波器的原理?看这篇就够了! 很多通信系统发展到某种程度都会有小型化的趋势.一方面小型化可以让系统更加轻便和有效,另一方面,日益发展的IC**技术可以用更低的成本生产 ...
- Spark性能优化指南——基础篇(转载)
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
随机推荐
- .NET Core CSharp初级篇 1-5 接口、枚举、抽象
.NET Core CSharp初级篇 1-5 本节内容类的接口.枚举.抽象 简介 问题 如果你需要表示星期或者是某些状态,使用字符串或者数字是否不直观? 你是否发现,无论何种电脑,它的USB口的设计 ...
- Python登录豆瓣并爬取影评
上一篇我们讲过Cookie相关的知识,了解到Cookie是为了交互式web而诞生的,它主要用于以下三个方面: 会话状态管理(如用户登录状态.购物车.游戏分数或其它需要记录的信息) 个性化设置(如用户自 ...
- Javascript中style,currentStyle和getComputedStyle的区别以及获取css操作方法
style: 只能获取行内style. 调用:obj.style.属性; 兼容:都兼容 currentStyle: 可以获取该obj所有style,但只可读. 调用:obj.currentStyle[ ...
- SpringBoot系列——@Async优雅的异步调用
前言 众所周知,java的代码是同步顺序执行,当我们需要执行异步操作时我们需要创建一个新线程去执行,以往我们是这样操作的: /** * 任务类 */ class Task implements Run ...
- z-index不起作用
摘录自 https://blog.csdn.net/apple_01150525/article/details/76546367 z-index无效的情况,一共有三种:1.父标签 position属 ...
- springBoot的过滤器,监听器,拦截器
概述 在开发中,我们经常要考虑一些问题,对敏感词进行过滤,用户是否已经登录,是否需要对他的请求进行拦截,或者领导问现在在线人数有多少人?我们如何实现这些功能哪 @WebFilter package c ...
- 【iOS】no identity found Command /usr/bin/codesign failed with exit code 1
今天遇到了这个问题,详情如下图: 后来发现是自己脑子短路了……只添加了 Provisioning Profiles, 而忘记添加 Certificates, 就是下面的两个:
- Core CLR 自定义的Host官方推荐的一种形式(第一种)
.Net Core CLR提供两种Host API访问 托管代码的形式,按照微软官方的说法,一种是通过CoreClr.DLL来直接调用托管生成的DLL程序集,另外一种是通过CoreClr里面的C导出函 ...
- 【JDK】JDK源码分析-AbstractQueuedSynchronizer(2)
概述 前文「JDK源码分析-AbstractQueuedSynchronizer(1)」初步分析了 AQS,其中提到了 Node 节点的「独占模式」和「共享模式」,其实 AQS 也主要是围绕对这两种模 ...
- html的一些基本语法学习与实战
其实在学校前端开始之前,问过自己为什么要学,因为自己学的比较杂,直到现在刚刚毕业出来工作了,才明确了方向了,要往嵌入式方向走,但是随着时代的发展,在编程和智能硬件结合的越来越紧密,特别是物联网这一块, ...