MySQL MGR集群单主模式的自动搭建和自动化故障修复
随着MySQL MGR的版本的升级以及技术成熟,在把MHA拉下神坛之后, MGR越来越成为MySQL高可用的首选方案。
MGR的搭建并不算很复杂,但是有一系列手工操作步骤,为了简便MGR的搭建和故障诊断,这里完成了一个自动化的脚本,来实现MGR的自动化搭建,自动化故障诊断以及修复。
MGR自动化搭建
为了简便起见,这里以单机多实例的模式进行测试,
先装好三个MySQL实例,端口号分别是7001,7002,7003,其中7001作为写节点,其余两个节点作为读节,8000节点是笔者的另外一个测试节点,请忽略。
在指明主从节点的情况下,如下为mgr_tool.py一键搭建MGR集群的测试demo

MGR故障模拟1
MGR节点故障自动监测和自愈实现,如下是搭建完成后的MGR集群,目前集群处于完全正常的状态中。
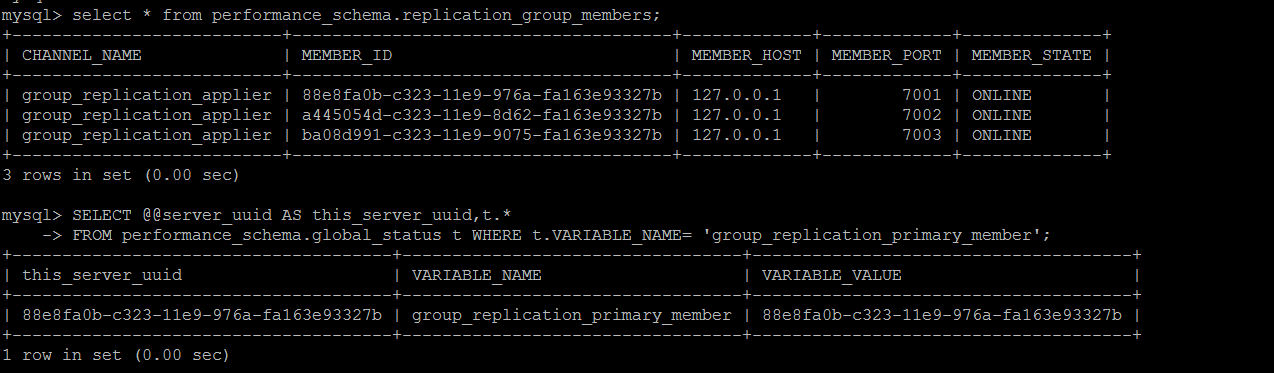
主观造成主从节点间binlog的丢失
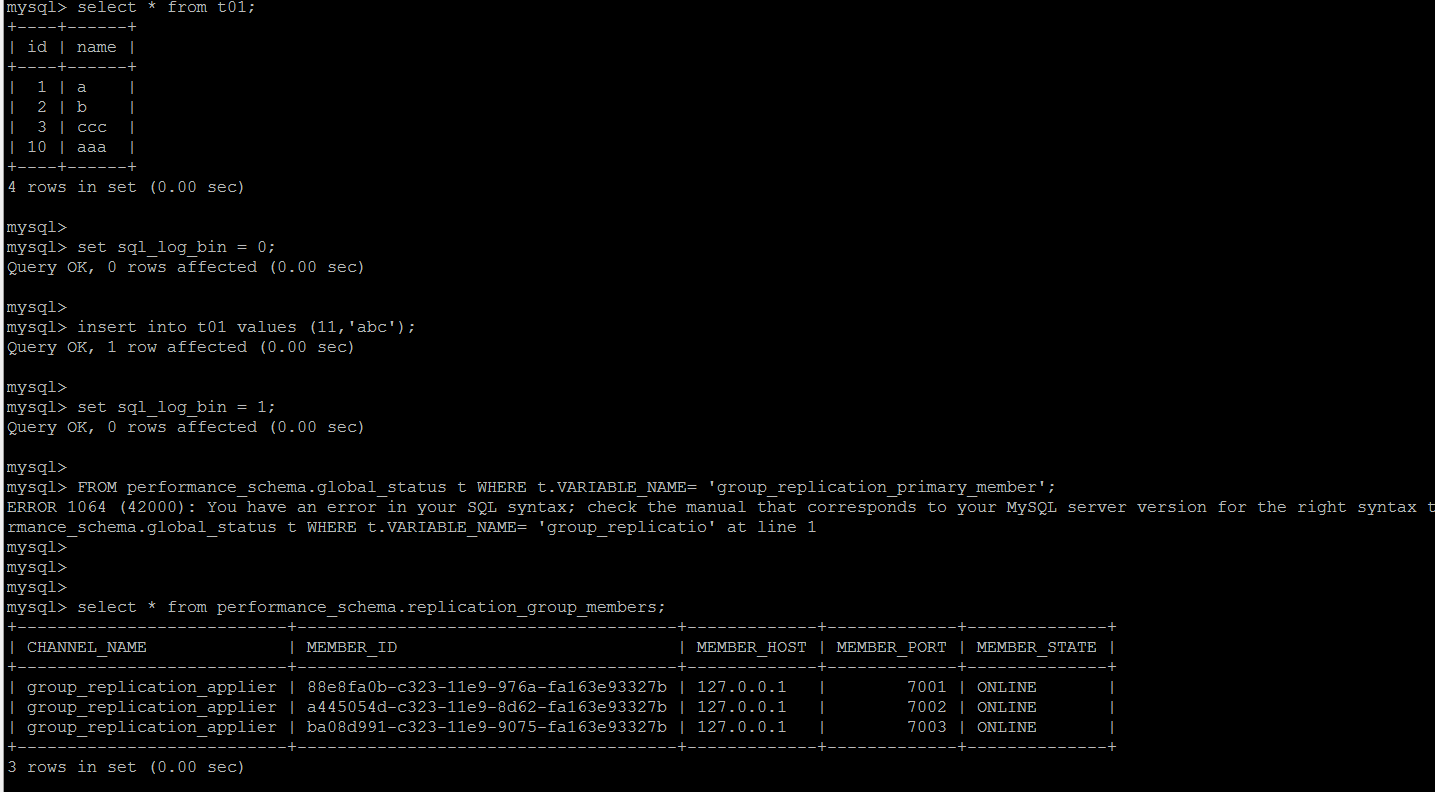
在主节点上对于对于从节点丢失的数据操作,GTID无法找到对应的数据,组复制立马熄火
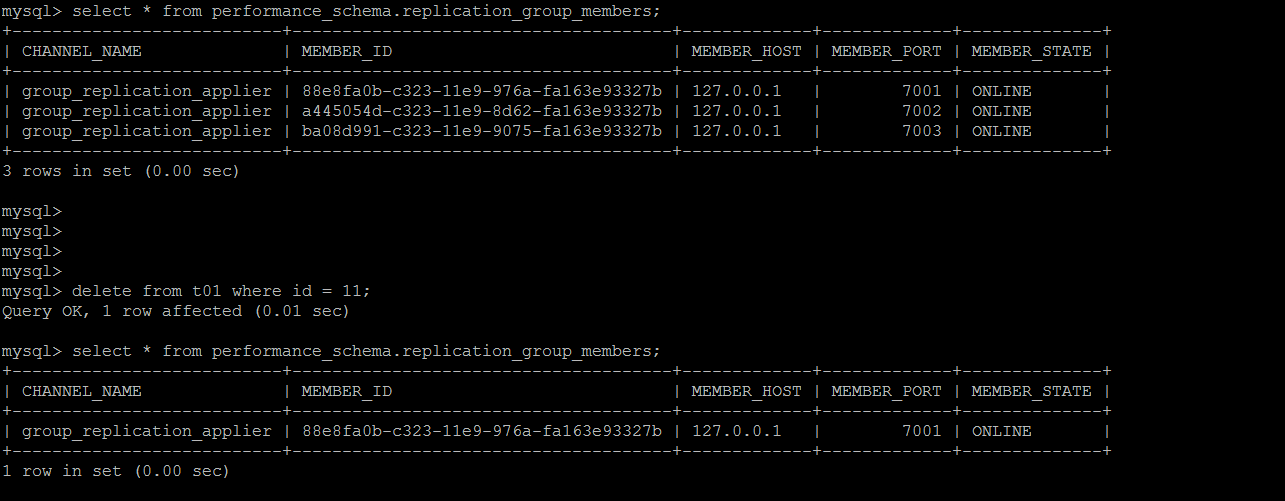
非写入节点出现错误
看下errorlog
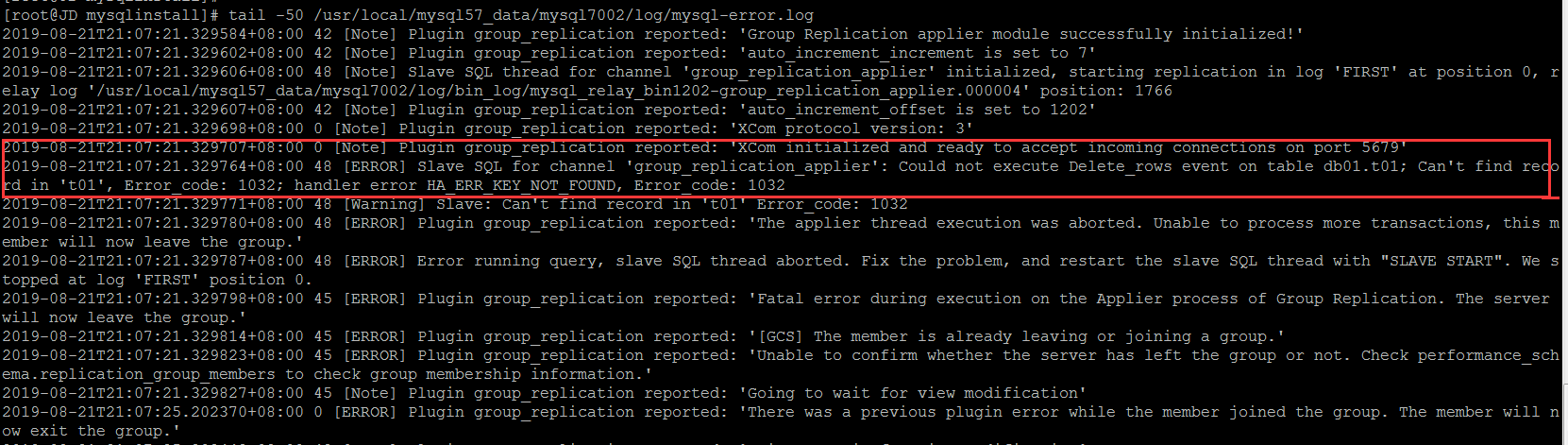
如果是手动解决的话,还是GTID跳过错误事物的套路,master上的GTID信息

尝试跳过最新的一个事物ID,然后重新连接到组,可以正常连接到组,另外一个节点仍旧处于error状态
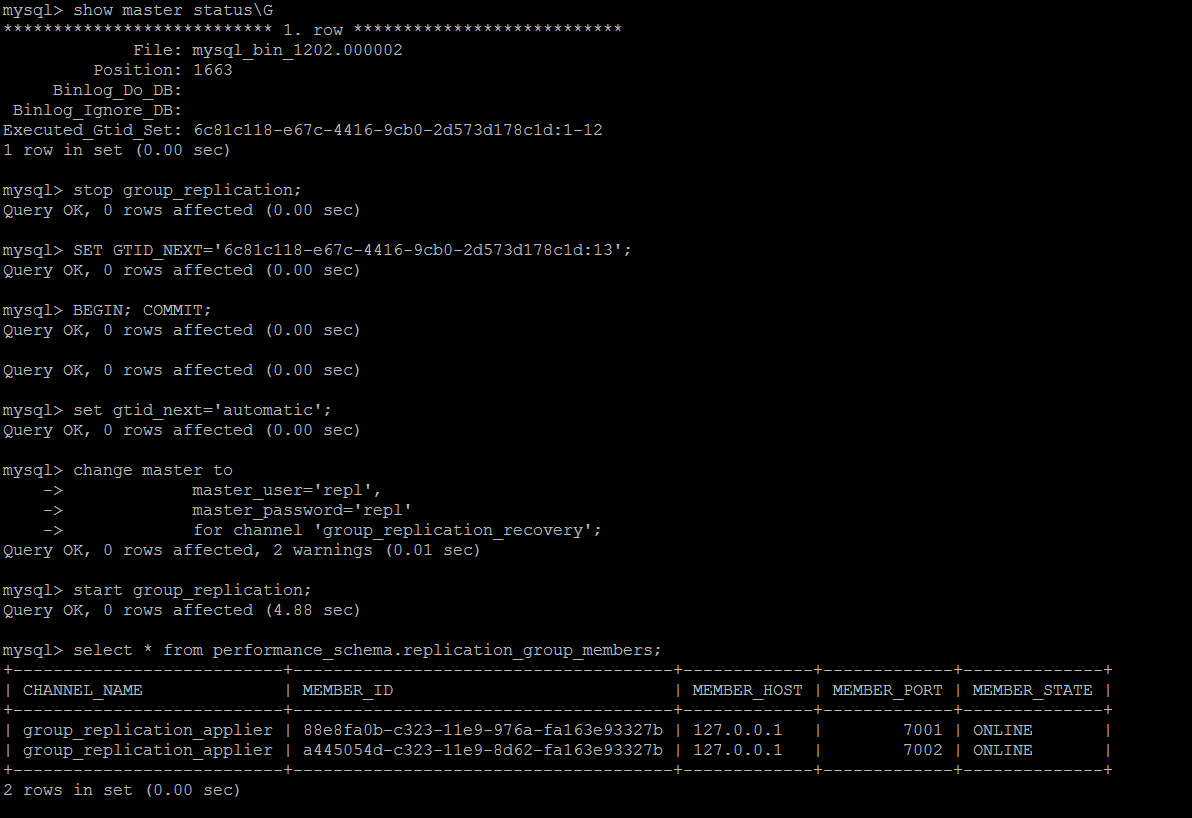
另外一个节点类似,依次解决。
MGR故障模拟2
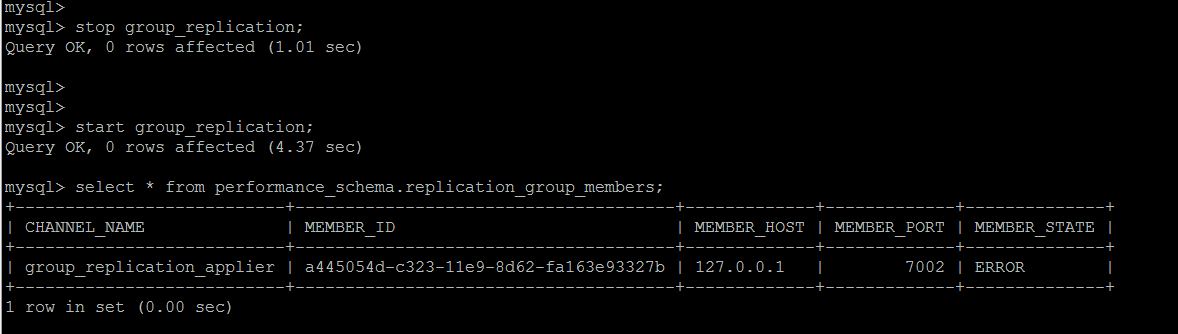
从节点脱离Group
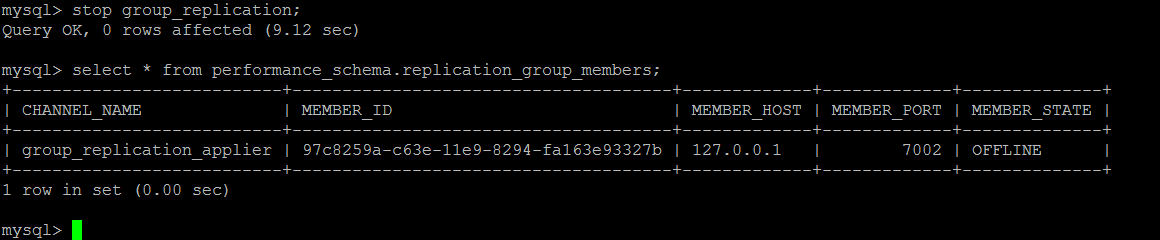
这种情况倒是比较简单,重新开始组复制即可,start group_replication
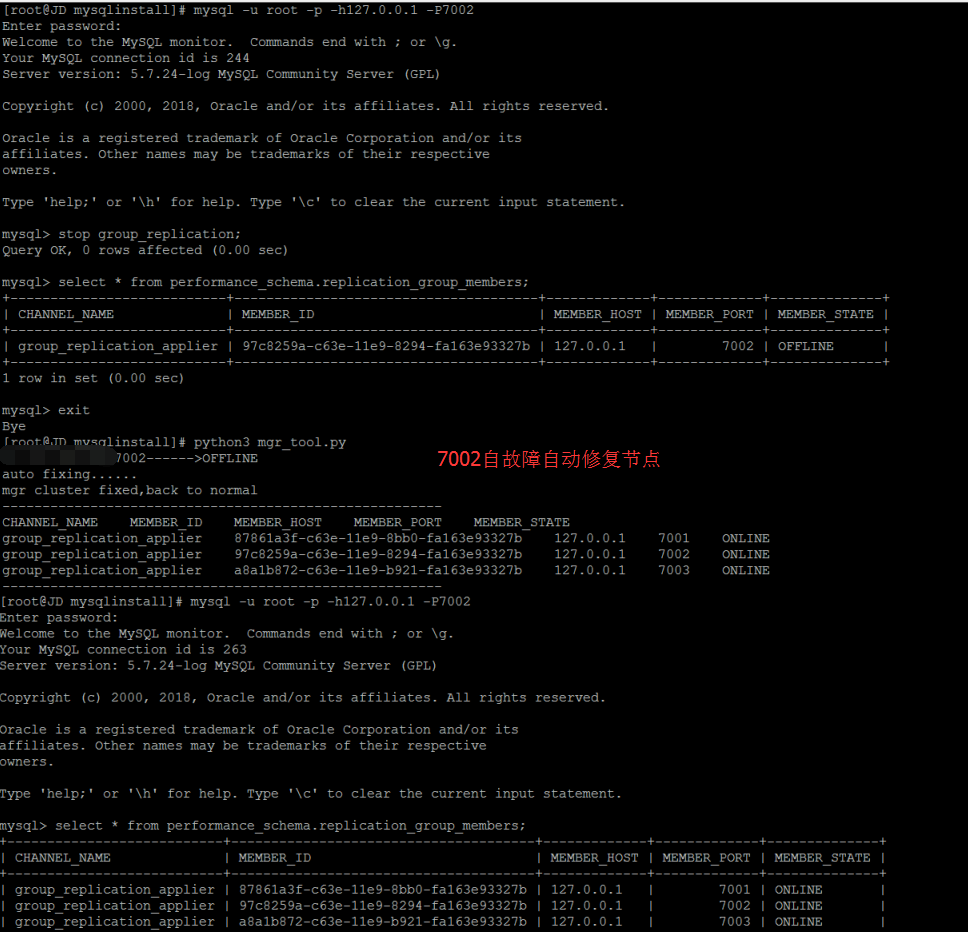
MGR故障自动检测和修复
对于如上的两种情况,
1,如果是从节点丢失主节点的事物,尝试在从节点上跳过GTID,重新开始复制即可
2,如果是从节点非丢失主节点事物,尝试在从节点重新开始组复制即可
实现代码如下
def auto_fix_mgr_error(conn_master_dict,conn_slave_dict):
group_replication_status = get_group_replication_status(conn_slave_dict)
if(group_replication_status[0]["MEMBER_STATE"]=="ERROR" or group_replication_status[0]["MEMBER_STATE"] == "OFFLINE"):
print(conn_slave_dict["host"]+str(conn_slave_dict["port"])+'------>'+group_replication_status[0]["MEMBER_STATE"])
print("auto fixing......")
while 1 > 0:
master_gtid_list = get_gtid(conn_master_dict)
slave_gtid_list = get_gtid(conn_slave_dict)
master_executed_gtid_value = int((master_gtid_list[-1]["Executed_Gtid_Set"]).split("-")[-1])
slave_executed_gtid_value = int(slave_gtid_list[-1]["Executed_Gtid_Set"].split("-")[-1])
slave_executed_gtid_prefix = slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[0]
slave_executed_skiped_gtid = slave_executed_gtid_value + 1
if (master_executed_gtid_value > slave_executed_gtid_value):
print("skip gtid and restart group replication,skiped gtid is "
+ slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[-1].split("-")[0]
+ ":"+str(slave_executed_skiped_gtid))
slave_executed_skiped_gtid = slave_executed_gtid_prefix+":"+str(slave_executed_skiped_gtid)
skip_gtid_on_slave(conn_slave_dict,slave_executed_skiped_gtid)
time.sleep(10)
start_group_replication(conn_slave_dict)
if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"):
print("mgr cluster fixed,back to normal")
break
else:
start_group_replication(conn_slave_dict)
if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"):
print("mgr cluster fixed,back to normal")
break
elif (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'):
print("mgr cluster is normal,nothing to do")
check_replication_group_members(conn_slave_dict)
对于故障类型1,GTID事物不一致的自动化修复

对于故障类型2从节点offline的自动化修复
完整的实现代码
该过程要求MySQL实例必须满足MGR的基本条件,如果环境本身无法满足MGR,一切都无从谈起,因此要非常清楚MGR环境的最基本要求
完成的实现代码如下,花了一个下午写的,目前来说存在以下不足
1,创建复制用户的时候,没有指定具体的slave机器,目前直接指定的%:create user repl@'%' identified by repl
2,对于slave的修复,目前无法整体修复,只能一台一台修复,其实就是少了一个循环slave机器判断的过程
3,目前搭建之前都会reset master(不管主从,主要是清理可能的残留GTID),因此只适合新环境的搭建
4,目前只支持offline和gtid事物冲突的错误类型修复,无法支持其他MGR错误类型的修复
5,开发环境是单机多实例模式测试,没有在多机单实例模式下充分测试
以上都会逐步改善&加强。
# -*- coding: utf-8 -*- import pymysql
import logging
import time
import decimal def execute_query(conn_dict,sql):
conn = pymysql.connect(host=conn_dict['host'],
port=conn_dict['port'],
user=conn_dict['user'],
passwd=conn_dict['password'],
db=conn_dict['db'])
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql)
list = cursor.fetchall()
cursor.close()
conn.close()
return list def execute_noquery(conn_dict,sql):
conn = pymysql.connect(host=conn_dict['host'],
port=conn_dict['port'],
user=conn_dict['user'],
passwd=conn_dict['password'],
db=conn_dict['db'])
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
cursor.close()
conn.close()
return list def get_gtid(conn_dict):
sql = "show master status;"
list = execute_query(conn_dict,sql)
return list def skip_gtid_on_slave(conn_dict,gtid):
sql_1 = 'stop group_replication;'
sql_2 = '''set gtid_next='{0}';'''.format(gtid)
sql_3 = 'begin;'
sql_4 = 'commit;'
sql_5 = '''set gtid_next='automatic';''' try:
execute_noquery(conn_dict, sql_1)
execute_noquery(conn_dict, sql_2)
execute_noquery(conn_dict, sql_3)
execute_noquery(conn_dict, sql_4)
execute_noquery(conn_dict, sql_5)
except:
raise def get_group_replication_status(conn_dict):
sql = '''select MEMBER_STATE from performance_schema.replication_group_members
where (MEMBER_HOST = '{0}' or ifnull(MEMBER_HOST,'') = '')
AND (MEMBER_PORT={1} or ifnull(MEMBER_PORT,'') ='') ; '''.format(conn_dict["host"], conn_dict["port"])
result = execute_query(conn_dict,sql)
if result:
return result
else:
return None def check_replication_group_members(conn_dict):
print('-------------------------------------------------------')
result = execute_query(conn_dict, " select * from performance_schema.replication_group_members; ")
if result:
column = result[0].keys()
current_row = ''
for key in column:
current_row += str(key) + " "
print(current_row) for row in result:
current_row = ''
for key in row.values():
current_row += str(key) + " "
print(current_row)
print('-------------------------------------------------------') def auto_fix_mgr_error(conn_master_dict,conn_slave_dict):
group_replication_status = get_group_replication_status(conn_slave_dict)
if(group_replication_status[0]["MEMBER_STATE"]=="ERROR" or group_replication_status[0]["MEMBER_STATE"] == "OFFLINE"):
print(conn_slave_dict["host"]+str(conn_slave_dict["port"])+'------>'+group_replication_status[0]["MEMBER_STATE"])
print("auto fixing......")
while 1 > 0:
master_gtid_list = get_gtid(conn_master_dict)
slave_gtid_list = get_gtid(conn_slave_dict)
master_executed_gtid_value = int((master_gtid_list[-1]["Executed_Gtid_Set"]).split("-")[-1])
slave_executed_gtid_value = int(slave_gtid_list[-1]["Executed_Gtid_Set"].split("-")[-1])
slave_executed_gtid_prefix = slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[0]
slave_executed_skiped_gtid = slave_executed_gtid_value + 1
if (master_executed_gtid_value > slave_executed_gtid_value):
print("skip gtid and restart group replication,skiped gtid is "
+ slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[-1].split("-")[0]
+ ":"+str(slave_executed_skiped_gtid))
slave_executed_skiped_gtid = slave_executed_gtid_prefix+":"+str(slave_executed_skiped_gtid)
skip_gtid_on_slave(conn_slave_dict,slave_executed_skiped_gtid)
time.sleep(10)
start_group_replication(conn_slave_dict)
if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"):
print("mgr cluster fixed,back to normal")
break
else:
start_group_replication(conn_slave_dict)
if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"):
print("mgr cluster fixed,back to normal")
break
elif (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'):
print("mgr cluster is normal,nothing to do")
check_replication_group_members(conn_slave_dict) '''
reset master
'''
def reset_master(conn_dict):
try:
execute_noquery(conn_dict, "reset master;")
except:
raise def install_group_replication_plugin(conn_dict):
get_plugin_sql = "SELECT name,dl FROM mysql.plugin WHERE name = 'group_replication';"
install_plugin_sql = '''install plugin group_replication soname 'group_replication.so'; '''
try:
result = execute_query(conn_dict, get_plugin_sql)
if not result:
execute_noquery(conn_dict, install_plugin_sql)
except:
raise def create_mgr_repl_user(conn_master_dict,user,password):
try:
reset_master(conn_master_dict)
sql_exists_user = '''select user from mysql.user where user = '{0}'; '''.format(user)
user_list = execute_query(conn_master_dict,sql_exists_user)
if not user_list:
create_user_sql = '''create user {0}@'%' identified by '{1}'; '''.format(user,password)
grant_privilege_sql = '''grant replication slave on *.* to {0}@'%';'''.format(user)
execute_noquery(conn_master_dict,create_user_sql)
execute_noquery(conn_master_dict, grant_privilege_sql)
execute_noquery(conn_master_dict, "flush privileges;")
except:
raise def set_super_read_only_off(conn_dict):
super_read_only_off = '''set global super_read_only = 0;'''
execute_noquery(conn_dict, super_read_only_off) def open_group_replication_bootstrap_group(conn_dict):
sql = '''select variable_name,variable_value from performance_schema.global_variables where variable_name = 'group_replication_bootstrap_group';'''
result = execute_query(conn_dict, sql)
open_bootstrap_group_sql = '''set @@global.group_replication_bootstrap_group=on;'''
if result and result[0]['variable_value']=="OFF":
execute_noquery(conn_dict, open_bootstrap_group_sql) def close_group_replication_bootstrap_group(conn_dict):
sql = '''select variable_name,variable_value from performance_schema.global_variables where variable_name = 'group_replication_bootstrap_group';'''
result = execute_query(conn_dict, sql)
close_bootstrap_group_sql = '''set @@global.group_replication_bootstrap_group=off;'''
if result and result[0]['variable_value'] == "ON":
execute_noquery(conn_dict, close_bootstrap_group_sql) def start_group_replication(conn_dict):
start_group_replication = '''start group_replication;'''
group_replication_status = get_group_replication_status(conn_dict)
if not (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'):
execute_noquery(conn_dict, start_group_replication) def connect_to_group(conn_dict,repl_user,repl_password):
connect_to_group_sql = '''change master to
master_user='{0}',
master_password='{1}'
for channel 'group_replication_recovery'; '''.format(repl_user,repl_password)
try:
execute_noquery(conn_dict, connect_to_group_sql)
except:
raise def start_mgr_on_master(conn_master_dict,repl_user,repl_password):
try:
set_super_read_only_off(conn_master_dict)
reset_master(conn_master_dict)
create_mgr_repl_user(conn_master_dict,repl_user,repl_password)
connect_to_group(conn_master_dict,repl_user,repl_password) open_group_replication_bootstrap_group(conn_master_dict)
start_group_replication(conn_master_dict)
close_group_replication_bootstrap_group(conn_master_dict) group_replication_status = get_group_replication_status(conn_master_dict)
if (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'):
print("master added in mgr and run successfully")
return True
except:
raise
print("############start master mgr error################")
exit(1) def start_mgr_on_slave(conn_slave_dict,repl_user,repl_password):
try:
set_super_read_only_off(conn_slave_dict)
reset_master(conn_slave_dict)
connect_to_group(conn_slave_dict,repl_user,repl_password)
start_group_replication(conn_slave_dict)
# wait for 10
time.sleep(10)
# then check mgr status
group_replication_status = get_group_replication_status(conn_slave_dict)
if (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'):
print("slave added in mgr and run successfully")
if (group_replication_status[0]['MEMBER_STATE'] == 'RECOVERING'):
print("slave is recovering")
except:
print("############start slave mgr error################")
exit(1) def auto_mgr(conn_master,conn_slave_1,conn_slave_2,repl_user,repl_password):
install_group_replication_plugin(conn_master)
master_replication_status = get_group_replication_status(conn_master) if not (master_replication_status[0]['MEMBER_STATE'] == 'ONLINE'):
start_mgr_on_master(conn_master,repl_user,repl_password) slave1_replication_status = get_group_replication_status(conn_slave_1)
if not (slave1_replication_status[0]['MEMBER_STATE'] == 'ONLINE'):
install_group_replication_plugin(conn_slave_1)
start_mgr_on_slave(conn_slave_1, repl_user, repl_user) slave2_replication_status = get_group_replication_status(conn_slave_2)
if not (slave2_replication_status[0]['MEMBER_STATE'] == 'ONLINE'):
install_group_replication_plugin(conn_slave_2)
start_mgr_on_slave(conn_slave_2, repl_user, repl_user) check_replication_group_members(conn_master) if __name__ == '__main__':
conn_master = {'host': '127.0.0.1', 'port': 7001, 'user': 'root', 'password': 'root', 'db': 'mysql', 'charset': 'utf8mb4'}
conn_slave_1 = {'host': '127.0.0.1', 'port': 7002, 'user': 'root', 'password': 'root', 'db': 'mysql', 'charset': 'utf8mb4'}
conn_slave_2 = {'host': '127.0.0.1', 'port': 7003, 'user': 'root', 'password': 'root', 'db': 'mysql', 'charset': 'utf8mb4'}
repl_user = "repl"
repl_password = "repl"
#auto_mgr(conn_master,conn_slave_1,conn_slave_2,repl_user,repl_password) auto_fix_mgr_error(conn_master,conn_slave_1)
check_replication_group_members(conn_master)
/*
the waiting game:尽管人生如此艰难,不要放弃;不要妥协;不要失去希望
*/
MySQL MGR集群单主模式的自动搭建和自动化故障修复的更多相关文章
- MySQL集群MGR架构for单主模式
本文转载自: https://www.93bok.com MGR简介 MySQL Group Replication(简称MGR)是MySQL官方于2016年12月推出的一个全新的高可用与高扩展的解决 ...
- MySQL MGR集群搭建
本文来自网易云社区,转载务必请注明出处. 本文将从零开始搭建一个MySQL Group Replication集群,包含3个节点.简单介绍如何查询MGR集群状态信息.并介绍如何进行MGR节点上下线操作 ...
- Mysql组复制之单主模式(一)
环境 系统:CentOS release 6.9 (Final) Mysql:5.7 机器: S1 10.0.0.7 lemon S2 10.0.0.8 lemon2 S3 10.0.0.9 lemo ...
- MySQL MGR 集群从数据库显示RECOVRING
因为断电 或者 其他瞎折腾 导致: 从节点显示RECOVRING 查看错误日志显示: Slave SQL for channel 'group_replication_recovery': Error ...
- MySQL+MGR 单主模式和多主模式的集群环境 - 部署手册 (Centos7.5)
MySQL Group Replication(简称MGR)是MySQL官方于2016年12月推出的一个全新的高可用与高扩展的解决方案.MGR是MySQL官方在5.7.17版本引进的一个数据库高可用与 ...
- 多云部署多主模式的MGR集群,每个云一个MGR 节点,满足业务单元化改造的需求
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答 GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 本 ...
- MySQL集群MGR架构for多主模式
本文转载自: https://www.93bok.com MGR简介 MySQL Group Replication(简称MGR)是MySQL官方于2016年12月推出的一个全新的高可用与高扩展的解决 ...
- [MGR——Mysql的组复制之单主模式 ]详细搭建部署过程
1,关于MySQL Group Replication 基于组的复制(Group-basedReplication)是一种被使用在容错系统中的技术.Replication-group(复制组)是由 ...
- MySQL MGR 单主模式下master角色切换规则
MGR单主模式,master节点可读可写,其余节点都是只读.当配置MGR为单主模式,非master节点自动开启super_read_only 当可读可写的节点异常宕机,会进行怎样的切换?在选择新的可写 ...
随机推荐
- 20190719 NOIP模拟测试6 (考后反思)
总分 130 排名第6 虽然与前几次进步了一些,但总会感觉到不安 因为我只是A掉了第一题,而第一题又是道水题,很显然的DP,我相信大佬们没A掉只是因为一些小问题(也许有大佬不屑于这种题吧,lockey ...
- 个人永久性免费-Excel催化剂功能第101波-批量替换功能(增加正则及高性能替换能力)
数据处理无小事,正如没有人活在真空理想环境一下,在数据分析过程中,也没有那么真空理想化的数据源可以使用,数据处理占据数据分析的80%的时间,每一个小小的改善,获益都良多.Excel查找替换,有其局限性 ...
- Node.js实现简易的获取access_token
还是老样子,在自学node.js的道路上走得坑坑洼洼,按住了躁动的自己,调整好心情 ,ready........Go....! 首先在项目里新建config.json,其中 appid 与 appsc ...
- TensorFlow(1)-基础知识点总结
1. tensorflow简介 Tensorflow 是 google 开源的机器学习工具,在2015年11月其实现正式开源,开源协议Apache 2.0. Tensorflow采用数据流图(data ...
- 探究netty的观察者设计模式
javadoc笔记点 观察者的核心思想就是,在适当的时机回调观察者的指定动作函数 我们知道,在使用netty创建channel时,一般都是把这个channel设置成非阻塞的模式,这意味着什么呢? 意味 ...
- linux初学者-系统启动故障篇
linux初学者-系统启动故障篇 在系统的操作中,有时会不小心误删或者操作失误使得系统启动不起来,下文将列举几种常见的系统启动失败的情况及解决的办法. 1.删除或者覆盖mbr的446个字节 mbr的4 ...
- 加深对C#数据类型的认识
值类型: 值类型源于System.Value家族,每个值类型的对象都有一个独立的内存区域用于保存自己的值,值类型 所在的内存区域称之为栈(Stack),只要在代码中修改它,就会在内存区域保存这个值. ...
- rabbitMQ_helloworld(一)
在下图中,“P”是我们的生产者,“C”是我们的消费者.中间的框是队列 - RabbitMQ代表消费者的消息缓冲区. 本例使用maven构建项目,在pom.xml中添加一下依赖 <dependen ...
- Docker 安装部署Sql Server
前言 在如今,容器化概念越来越盛行,.Net Core项目也可以跨平台部署了,那么思考下Sql Server能不能呢?当然是可以的啦.本文今天就是介绍Docker部署配置和连接Sql Server.本 ...
- 第三章、Go-内建容器
3.1.数组 (1)数组的定义 package main import ( "fmt" ) func main() { //用var定义数组可以不用赋初值 var arr1 [5] ...