Hadoop RPC机制详解
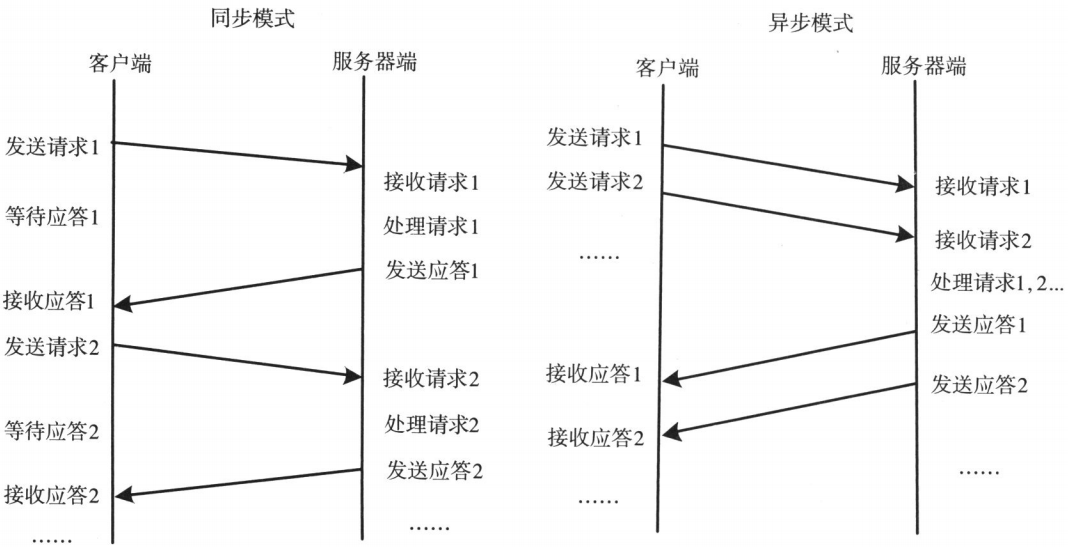
- 通信模块。两个相互协作的通信模块实现请求 - 应答协议,它们在客户和服务器之间传递请求和应答消息,一般不会对数据包进行任何处理。请求 - 应答协议的实现一般有同步方式和异步方式两种
- 同步模式下客户端程序一直阻塞到服务器断发送的应答请求到达本地
- 异步模式下将请求发送到服务端后,不必等待应答返回,可以做其他事情
- Stub程序。客户端和服务器端均包含Stub程序,可以将之看作代理程序。它使得远程函数调用表现的跟本地调用一样,对用户程序完全透明。在客户端,Stub程序像一个本地程序,但不直接执行本地调用,而是将请求信息提供网络模块发送给服务器端,服务器端给客户端发送应答后,客户端Stub程序会解码对应结果。在服务器端,Stub程序依次进行解码请求消息中的参数、调用相应的服务过程和编码应答结果的返回值等处理
- 调度程序。调度程序接收来自通信模块的请求信息,并根据其中的标识选择一个Stub程序进行处理。通常客户端并发请求量比较大时,会采用线程池提高处理效率
- 客户程序/服务过程。请求的发出者和请求的处理者
- 客户程序以本地方式调用系统产生的Stub程序
- 该Stub程序将函数调用信息按照网络通信模块的要求封装成消息包,并交给通信模块发送给远程服务器端
- 远程服务器端接收此消息后,将此消息发送给相应的Stub程序
- Stub程序拆封消息,形成被调过程要求的形式,并调用对应函数
- 被调用函数按照所获参数执行,并将结果返回给Stub程序
- Stub程序将此结果封装成消息,通过网络通信模块逐级地传送给客户程序
- 透明性。这是所有RPC框架最根本的特点,即当用户在一台计算机的程序调用另外一台计算机上的子程序时,用户自身不应感觉到其间设计机器间的通信,而是感觉像是在执行一个本地调用
- 高性能。Hadoop各个系统(HDFS,YARN,MapReduce等)均采用了Master/Slave架构,其中,Master实际上是一个RPC Server,它负责处理集群中所有Slave发送的服务请求,为了保证Master的并发处理能力,RPC Server应是一个高性能服务器,能够高效地处理来自多个Client的并发RPC请求
- 可控性。RPC是Hadoop最底层最核心的模块之一,保证其轻量级,高性能和可控性显得尤为重要
- 序列化层。序列化主要作用是将结构化对象转为字节流以便于通过网络进行传输或写入持久存储,在RPC框架中,它主要是用于将用户请求中的参数或者应答转换成字节流以便跨机器传输
- 函数调用层。函数调用层主要功能是定位要调用的而函数并执行该函数,Hadoop RPC采用了Java反射机制与动态代理实现了函数调用
- 网络传输层。网络传输层描述了Client与Server之间消息传输的方式,Hadoop RPC采用了基础TCP/IP的Socket机制
- 服务器端处理框架。服务器端处理框架可被抽象为网络I/O模型,它描述了客户端与服务器间信息的交互方式,它的设计直接决定这服务器端的并发处理能力,而Hadoop RPC采用了基于Reactor设计模式的事件驱动I/O模型
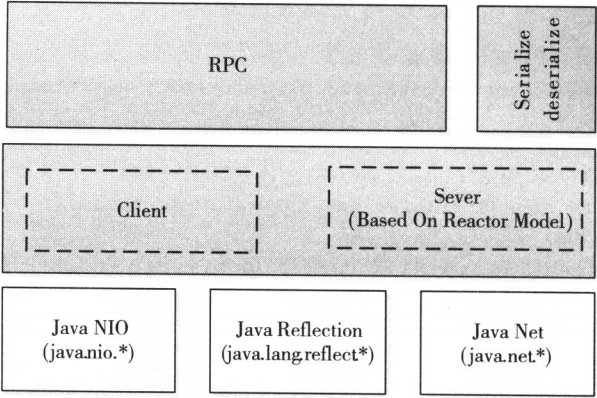
Hadoop RPC总体架构
- public static <T>ProtocolProxy <T> getProxy/waitForProxy() : 构造一个客户端代理对象,用于向服务器发送RPC请求
- public static Server RPC.Builder (Configuration).build() : 为某个协议实例构造一个服务器对象,用于处理客户端发送的请求
interface ClientProtocol extends org.apache.hadoop.ipc.VersionedProtocol {
public static final long versionID = 1L;
String echo(String value) throws IOException;
int add(int v1 , int v2) throws IOException;
}
public static class ClientProtocolImpl implements ClientProtocol {
//重载的方法,用于获取自定义的协议版本号
public long getProtocolVersion(String protocol, long clientVersion) {
return ClientProtocol.versionID;
}
//重载的方法,用于获取协议签名
public ProtocolSignature getProtocolSignature(String protocol, long clientVersion, inthashcode) {
return new ProtocolSignature(ClientProtocol.versionID, null);
}
public String echo(String value) throws IOException {
return value;
}
public int add(int v1, int v2) throws IOException {
return v1 + v2;
}
}
Server server = new RPC.Builder(conf).setProtocol(ClientProtocol.class)
.setInstance(new ClientProtocolImpl()).setBindAddress(ADDRESS).setPort(0)
.setNumHandlers(5).build();
server.start();
// BindAddress : 服务器的HOST
// Port : 监听端口号,0代表系统随机选择一个端口号
// NumHandlers : 服务端处理请求的线程数目
proxy = (ClientProtocol)RPC.getProxy(
ClientProtocol.class, ClientProtocol.versionID, addr, conf);
int result = proxy.add(5, 6);
String echoResult = proxy.echo("result");
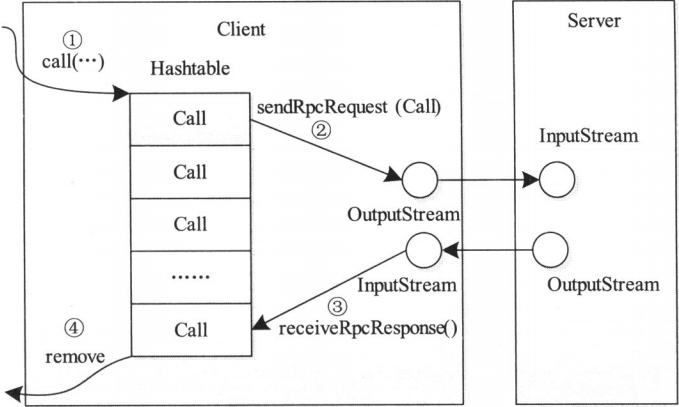
- Call类 : 封装了一个RPC请求,它包含5个成员变量,分别是唯一标识ID、函数调用信息param、函数执行返回值value、出错或者异常信息error和执行完成标识符done。由于Hadoop RPC Server采用异步方式处理客户端请求,这使远程过程调用的发生顺序与结果返回顺序无直接关系,而Client端正式提供ID识别不同的函数调用的。当客户端向服务器端发送请求时,只需填充id和param两个变量,而剩下的三个变量则由服务器根据函数执行情况填充
- Connection类 : Client与每个Server之间维护一个通信连接,与该连接相关的基本信息及操作被封装到Connection类中,基本信息主要包括通信连接唯一标识、与Server端通信的Socket、网络输入数据流(in)、网络输出数据流(out)、保存RPC请求的哈希表(calls)等。操作则包括 :
- addCall -- 将一个Call对象添加到哈希表中
- sendParam -- 向服务器端发送RPC请求
- receiveResponse -- 从服务器端接收已经处理完成的RPC请求
- run -- Connection是一个线程类,它的run方法调用了receiveResponse方法,会一直等待接收RPC返回结果
- 创建一个Connection对象,并将远程方法调用信息封装成Call对象,放到Connection对象中的哈希表中
- 调用Connection类中的sendRpcRequest()方法将当前Call对象发送给Server端
- Server端处理完RPC请求后,将结果通过网络返回给Client端,Client端通过receiveRpcResponse()函数获取结果
- Client检查结果处理状态,并将对应Call对象从哈希表中删除
- 通过派发/分离IO操作事件提高系统的并发性能
- 提供了粗粒度的并发控制,使用单线程实现,避免了复杂的同步处理
- Reactor : I/O事件的派发者
- Acceptor : 接受来自Client的连接,建立与Client对应的Handler,并向Reactor注册此Handler
- Handler : 与一个Client通信的实体,并按一定的过程实现业务的处理
- Reader/Sender : 为了加速处理速度,Reactor模式往往构建一个存放数据处理线程的线程池,这样数据读出后,立即扔到线程吃中等待后续处理即可。为此,Reactor模式一般分离Handler中的读和写两个过程,分别注册成单独的读事件和写事件,并由对应的Reader和Sender线程处理

- Reader线程数目。参数ipc.server.read.threadpool.size设置
- 每个Handler线程对应的最大Call数目。参数ipc.server.handler.queue.size设置
- Handler线程数目。参数yarn.resourcemanager.resource-tracker.client.thread-count和dfs.namenode.service.handler.count设置
- 客户端最大重试次数。参数ipc.client.connect.max.size设置
Hadoop RPC机制详解的更多相关文章
- hadoop之mapreduce详解(进阶篇)
上篇文章hadoop之mapreduce详解(基础篇)我们了解了mapreduce的执行过程和shuffle过程,本篇文章主要从mapreduce的组件和输入输出方面进行阐述. 一.mapreduce ...
- hadoop基础-SequenceFile详解
hadoop基础-SequenceFile详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.SequenceFile简介 1>.什么是SequenceFile 序列文件 ...
- java面试题之----JVM架构和GC垃圾回收机制详解
JVM架构和GC垃圾回收机制详解 jvm,jre,jdk三者之间的关系 JRE (Java Run Environment):JRE包含了java底层的类库,该类库是由c/c++编写实现的 JDK ( ...
- hadoop之yarn详解(框架进阶篇)
前面在hadoop之yarn详解(基础架构篇)这篇文章提到了yarn的重要组件有ResourceManager,NodeManager,ApplicationMaster等,以及yarn调度作业的运行 ...
- Hadoop学习笔记—3.Hadoop RPC机制的使用
一.RPC基础概念 1.1 RPC的基础概念 RPC,即Remote Procdure Call,中文名:远程过程调用: (1)它允许一台计算机程序远程调用另外一台计算机的子程序,而不用去关心底层的网 ...
- 从mixin到new和prototype:Javascript原型机制详解
从mixin到new和prototype:Javascript原型机制详解 这是一篇markdown格式的文章,更好的阅读体验请访问我的github,移动端请访问我的博客 继承是为了实现方法的复用 ...
- 浏览器 HTTP 协议缓存机制详解
最近在准备优化日志请求时遇到了一些令人疑惑的问题,比如为什么响应头里出现了两个 cache control.为什么明明设置了 no cache 却还是发请求,为什么多次访问时有时请求里带了 etag, ...
- JVM的垃圾回收机制详解和调优
JVM的垃圾回收机制详解和调优 gc即垃圾收集机制是指jvm用于释放那些不再使用的对象所占用的内存.java语言并不要求jvm有gc,也没有规定gc如何工作.不过常用的jvm都有gc,而且大多数gc都 ...
- 【转载】Hadoop历史服务器详解
免责声明: 本文转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除. 原文作者:过往记忆(http://www.iteblog.com/) 原文地址: ...
随机推荐
- cordova把我搞晕了
天啦,搞了几十次,这次求你成功好吗?
- LiteDB源码解析系列(3)索引原理详解
在这一章,我们将了解LiteDB里面几个基本数据结构包括索引结构和数据块结构,我也会试着说明前辈数据之巅在博客中遇到的问题,最后对比mysql进一步深入了解LiteDB的索引原理. 1.LiteDB的 ...
- 用margin还是padding ?
margin是用来隔开元素与元素的间距:padding是用来隔开元素与内容的间隔. margin用于布局分开元素使元素与元素互不相干:padding用于元素与内容之间的间隔,让内容(文字)与(包裹)元 ...
- Set接口的使用
Set集合里多个对象之间没有明显的顺序.具体详细方法请参考API文档(可见身边随时带上API文档有多重要),基本与Collection方法相同.只是行为不同(Set不允许包含重复元素). Set集合不 ...
- Java NIO学习系列六:Java中的IO模型
前文中我们总结了linux系统中的5中IO模型,并且着重介绍了其中的4种IO模型: 阻塞I/O(blocking IO) 非阻塞I/O(nonblocking IO) I/O多路复用(IO multi ...
- 01-k8s 架构
原文地址:https://github.com/kubernetes/kubernetes/blob/release-1.3/docs/design/architecture.md Kubernete ...
- 【Algorithm】插入排序法
通常人们整理桥牌的方法是一张一张的来,将每一张插入到其他已经有序的牌中的适当位置. • 思想:每步将一个待排序的记录,按其顺序码大小插入到前面已经排序的序列的合适位置,直到全部插入排序完为止. Jav ...
- 搭建谷歌浏览器无头模式抓取页面服务,laravel->php->python->docker !!!
背景: 公司管理系统需要获取企业微信页面的配置参数如企业名.logo.人数等信息并操作,来隐藏相关敏感信息并自定义简化企业号配置流程 第一版已经实现了扫码登录获取cookie,使用该cookie就能获 ...
- nginx 之负载均衡 :PHP session 跨多台服务器配置
公司一个项目单点压力越来越大,考虑到稳定性和降压,使用nginx做负载均衡,将请求分发到多个docker上去,这里记录下PHP多服务器间的会话session共享问题,解决方案是把session单独存在 ...
- 如何在Vue项目中使用vw实现移动端适配
有关于移动端的适配布局一直以来都是众说纷纭,对应的解决方案也是有很多种.在< 使用Flexible实现手淘H5页面的终端适配>提出了Flexible的布局方案,随着 viewport 单位 ...