[ch05-02] 用神经网络解决多变量线性回归问题
系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI,
点击star加星不要吝啬,星越多笔者越努力
5.2 神经网络解法
与单特征值的线性回归问题类似,多变量(多特征值)的线性回归可以被看做是一种高维空间的线性拟合。以具有两个特征的情况为例,这种线性拟合不再是用直线去拟合点,而是用平面去拟合点。
5.2.1 定义神经网络结构
我们定义一个如图5-1所示的一层的神经网络,输入层为2或者更多,反正大于2了就没区别。这个一层的神经网络的特点是:
- 没有中间层,只有输入项和输出层(输入项不算做一层);
- 输出层只有一个神经元;
- 神经元有一个线性输出,不经过激活函数处理,即在下图中,经过\(\Sigma\)求和得到\(Z\)值之后,直接把\(Z\)值输出。
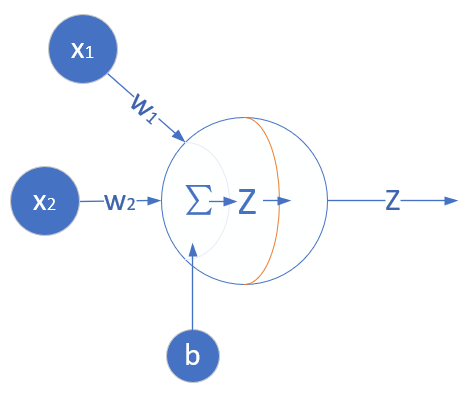
图5-1 多入单出的单层神经元结构
与上一章的神经元相比,这次仅仅是多了一个输入,但却是质的变化,即,一个神经元可以同时接收多个输入,这是神经网络能够处理复杂逻辑的根本。
输入层
单独看第一个样本是这样的:
\[
x_1 =
\begin{pmatrix}
x_{11} & x_{12}
\end{pmatrix} =
\begin{pmatrix}
10.06 & 60
\end{pmatrix}
\]
\[
y_1 = \begin{pmatrix} 302.86 \end{pmatrix}
\]
一共有1000个样本,每个样本2个特征值,X就是一个\(1000 \times 2\)的矩阵:
\[
X =
\begin{pmatrix}
x_1 \\ x_2 \\ \dots \\ x_{1000}
\end{pmatrix} =
\begin{pmatrix}
x_{1,1} & x_{1,2} \\
x_{2,1} & x_{2,2} \\
\dots & \dots \\
x_{1000,1} & x_{1000,2}
\end{pmatrix}
\]
\[
Y =
\begin{pmatrix}
y_1 \\ y_2 \\ \dots \\ y_{1000}
\end{pmatrix}=
\begin{pmatrix}
302.86 \\ 393.04 \\ \dots \\ 450.59
\end{pmatrix}
\]
\(x_1\)表示第一个样本,\(x_{1,1}\)表示第一个样本的一个特征值,\(y_1\)是第一个样本的标签值。
权重W和B
由于输入层是两个特征,输出层是一个变量,所以w的形状是2x1,而b的形状是1x1。
\[
W=
\begin{pmatrix}
w_1 \\ w_2
\end{pmatrix}
\]
\[B=(b)\]
B是个单值,因为输出层只有一个神经元,所以只有一个bias,每个神经元对应一个bias,如果有多个神经元,它们都会有各自的b值。
输出层
由于我们只想完成一个回归(拟合)任务,所以输出层只有一个神经元。由于是线性的,所以没有用激活函数。
\[
\begin{aligned}
z&=
\begin{pmatrix}
x_{11} & x_{12}
\end{pmatrix}
\begin{pmatrix}
w_1 \\ w_2
\end{pmatrix}
+(b) \\
&=x_{11}w_1+x_{12}w_2+b
\end{aligned}
\]
写成矩阵形式:
\[Z = X\cdot W + B\]
损失函数
因为是线性回归问题,所以损失函数使用均方差函数。
\[loss(w,b) = \frac{1}{2} (z_i-y_i)^2 \tag{1}\]
其中,\(z_i\)是样本预测值,\(y_i\)是样本的标签值。
5.2.2 反向传播
单样本多特征计算
与上一章不同,本章中的前向计算是多特征值的公式:
\[z_i = x_{i1} \cdot w_1 + x_{i2} \cdot w_2 + b\]
\[
=\begin{pmatrix}
x_{i1} & x_{i2}
\end{pmatrix}
\begin{pmatrix}
w_1 \\
w_2
\end{pmatrix}+b \tag{2}
\]
因为\(x\)有两个特征值,对应的\(W\)也有两个权重值。\(x_{i1}\)表示第\(i\)个样本的第1个特征值,所以无论是\(x\)还是\(W\)都是一个向量或者矩阵了,那么我们在反向传播方法中的梯度计算公式还有效吗?答案是肯定的,我们来一起做个简单推导。
由于\(W\)被分成了\(w1\)和\(w2\)两部分,根据公式1和公式2,我们单独对它们求导:
\[
\frac{\partial loss}{\partial w_1}=\frac{\partial loss}{\partial z_i}\frac{\partial z_i}{\partial w_1}=(z_i-y_i) \cdot x_{i1} \tag{3}
\]
\[
\frac{\partial loss}{\partial w_2}=\frac{\partial loss}{\partial z_i}\frac{\partial z_i}{\partial w_2}=(z_i-y_i) \cdot x_{i2} \tag{4}
\]
求损失函数对\(W\)矩阵的偏导是无法直接求的,所以要变成求各个\(W\)的分量的偏导。由于\(W\)的形状是:
\[
W=
\begin{pmatrix}
w_1 \\ w_2
\end{pmatrix}
\]
所以求\(loss\)对\(W\)的偏导,由于\(W\)是个矩阵,所以应该这样写:
\[
\begin{aligned}
\frac{\partial loss}{\partial W}&=
\begin{pmatrix}
{\partial loss}/{\partial w_1} \\
\\
{\partial loss}/{\partial w_2}
\end{pmatrix}
=\begin{pmatrix}
(z_i-y_i)\cdot x_{i1} \\
(z_i-y_i) \cdot x_{i2}
\end{pmatrix} \\
&=\begin{pmatrix}
x_{i1} \\
x_{i2}
\end{pmatrix}
(z_i-y_i)
=\begin{pmatrix}
x_{i1} & x_{i2}
\end{pmatrix}^T(z_i-y_i) \\
&=x_i^T(z_i-y_i)
\end{aligned} \tag{5}
\]
\[
{\partial loss \over \partial B}=z_i-y_i \tag{6}
\]
多样本多特征计算
当进行多样本计算时,我们用m=3个样本做一个实例化推导:
\[
z_1 = x_{11}w_1+x_{12}w_2+b
\]
\[
z_2= x_{21}w_1+x_{22}w_2+b
\]
\[
z_3 = x_{31}w_1+x_{32}w_2+b
\]
\[
J(w,b) = \frac{1}{2 \times 3}[(z_1-y_1)^2+(z_2-y_2)^2+(z_3-y_3)^2]
\]
\[
\begin{aligned}
\frac{\partial J}{\partial W}&=
\begin{pmatrix}
\frac{\partial J}{\partial w_1} \\
\\
\frac{\partial J}{\partial w_2}
\end{pmatrix}
=\begin{pmatrix}
\frac{\partial J}{\partial z_1}\frac{\partial z_1}{\partial w_1}+\frac{\partial J}{\partial z_2}\frac{\partial z_2}{\partial w_1}+\frac{\partial J}{\partial z_3}\frac{\partial z_3}{\partial w_1} \\
\\
\frac{\partial J}{\partial z_1}\frac{\partial z_1}{\partial w_2}+\frac{\partial J}{\partial z_2}\frac{\partial z_2}{\partial w_2}+\frac{\partial J}{\partial z_3}\frac{\partial z_3}{\partial w_2}
\end{pmatrix}
\\
&=\begin{pmatrix}
\frac{1}{3}(z_1-y_1)x_{11}+\frac{1}{3}(z_2-y_2)x_{21}+\frac{1}{3}(z_3-y_3)x_{31} \\
\frac{1}{3}(z_1-y_1)x_{12}+\frac{1}{3}(z_2-y_2)x_{22}+\frac{1}{3}(z_3-y_3)x_{32}
\end{pmatrix}
\\
&=\frac{1}{3}
\begin{pmatrix}
x_{11} & x_{21} & x_{31} \\
x_{12} & x_{22} & x_{32}
\end{pmatrix}
\begin{pmatrix}
z_1-y_1 \\
z_2-y_2 \\
z_3-y_3
\end{pmatrix}
\\
&=\frac{1}{3}
\begin{pmatrix}
x_{11} & x_{12} \\
x_{21} & x_{22} \\
x_{31} & x_{32}
\end{pmatrix}^T
\begin{pmatrix}
z_1-y_1 \\
z_2-y_2 \\
z_3-y_3
\end{pmatrix}
\\
&=\frac{1}{m}X^T(Z-Y)
\end{aligned}
\tag{7}
\]
\[
{\partial J \over \partial B}={1 \over m}(Z-Y) \tag{8}
\]
5.2.3 代码实现
公式6和第4.4节中的公式5一样,所以我们依然采用第四章中已经写好的HelperClass目录中的那些类,来表示我们的神经网络。虽然此次神经元多了一个输入,但是不用改代码就可以适应这种变化,因为在前向计算代码中,使用的是矩阵乘的方式,可以自动适应x的多个列的输入,只要对应的w的矩阵形状是正确的即可。
但是在初始化时,我们必须手动指定x和w的形状,如下面的代码所示:
if __name__ == '__main__':
# net
params = HyperParameters(2, 1, eta=0.1, max_epoch=100, batch_size=1, eps = 1e-5)
net = NeuralNet(params)
net.train(reader)
# inference
x1 = 15
x2 = 93
x = np.array([x1,x2]).reshape(1,2)
print(net.inference(x))在参数中,指定了学习率0.1,最大循环次数100轮,批大小1个样本,以及停止条件损失函数值1e-5。
在神经网络初始化时,指定了input_size=2,且output_size=1,即一个神经元可以接收两个输入,最后是一个输出。
最后的inference部分,是把两个条件(15公里,93平方米)代入,查看输出结果。
在下面的神经网络的初始化代码中,W的初始化是根据input_size和output_size的值进行的。
class NeuralNet(object):
def __init__(self, params):
self.params = params
self.W = np.zeros((self.params.input_size, self.params.output_size))
self.B = np.zeros((1, self.params.output_size))正向计算的代码
class NeuralNet(object):
def __forwardBatch(self, batch_x):
Z = np.dot(batch_x, self.W) + self.B
return Z误差反向传播的代码
class NeuralNet(object):
def __backwardBatch(self, batch_x, batch_y, batch_z):
m = batch_x.shape[0]
dZ = batch_z - batch_y
dB = dZ.sum(axis=0, keepdims=True)/m
dW = np.dot(batch_x.T, dZ)/m
return dW, dB5.2.4 运行结果
在Visual Studio 2017中,可以使用Ctrl+F5运行Level2的代码,但是,会遇到一个令人沮丧的打印输出:
epoch=0
NeuralNet.py:32: RuntimeWarning: invalid value encountered in subtract
self.W = self.W - self.params.eta * dW
0 500 nan
epoch=1
1 500 nan
epoch=2
2 500 nan
epoch=3
3 500 nan
......减法怎么会出问题?什么是nan?
nan的意思是数值异常,导致计算溢出了,出现了没有意义的数值。现在是每500个迭代监控一次,我们把监控频率调小一些,再试试看:
epoch=0
0 10 6.838664338516814e+66
0 20 2.665505502247752e+123
0 30 1.4244204612680962e+179
0 40 1.393993758296751e+237
0 50 2.997958629609441e+290
NeuralNet.py:76: RuntimeWarning: overflow encountered in square
LOSS = (Z - Y)**2
0 60 inf
...
0 110 inf
NeuralNet.py:32: RuntimeWarning: invalid value encountered in subtract
self.W = self.W - self.params.eta * dW
0 120 nan
0 130 nan前10次迭代,损失函数值已经达到了6.83e+66,而且越往后运行值越大,最后终于溢出了。下面的损失函数历史记录也表明了这一过程。
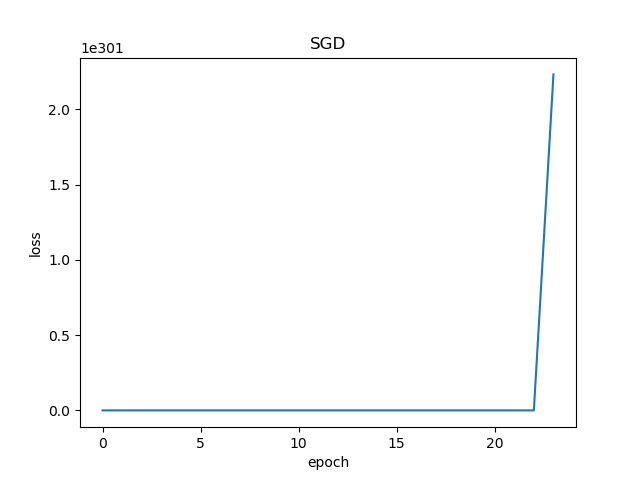
图5-2 训练过程中损失函数值的变化
5.2.5 寻找失败的原因
我们可以在NeuralNet.py文件中,在图5-3代码行上设置断点,跟踪一下训练过程,以便找到问题所在。
图5-3 在VisualStudio中Debug
在VS2017中用F5运行debug模式,看第50行的结果:
batch_x
array([[ 4.96071728, 41. ]])
batch_y
array([[244.07856544]])返回的样本数据是正常的。再看下一行:
batch_z
array([[0.]])第一次运行前向计算,由于W和B初始值都是0,所以z也是0,这是正常的。再看下一行:
dW
array([[ -1210.80475712],
[-10007.22118309]])
dB
array([[-244.07856544]])dW和dB的值都非常大,这是因为图5-4所示这行代码。
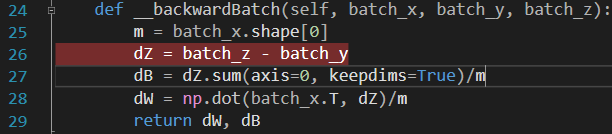
图5-4 有问题的代码行
batch_z是0,batch_y是244.078,二者相减,是-244.078,因此dB就是-244.078,dW因为矩阵乘了batch_x,值就更大了。
再看W和B的更新值,一样很大:
self.W
array([[ 121.08047571],
[1000.72211831]])
self.B
array([[24.40785654]])如果W和B的值很大,那么再下一轮进行前向计算时,会得到更糟糕的结果:
batch_z
array([[82459.53752331]])果不其然,这次的z值飙升到了8万多,如此下去,几轮以后数值溢出是显而易见的事情了。
那么我们到底遇到了什么情况?
代码位置
ch05, Level2
[ch05-02] 用神经网络解决多变量线性回归问题的更多相关文章
- [ch05-01] 正规方程法解决多变量线性回归问题
系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI, 点击star加星不要吝啬,星越多笔者越努力. 5.1 正规方程解法 英文名是 Normal Equat ...
- [ch05-00] 多变量线性回归问题
系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI, 点击star加星不要吝啬,星越多笔者越努力. 第5章 多入单出的单层神经网络 5.0 多变量线性回归问 ...
- Stanford机器学习---第二讲. 多变量线性回归 Linear Regression with multiple variable
原文:http://blog.csdn.net/abcjennifer/article/details/7700772 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- 机器学习 (二) 多变量线性回归 Linear Regression with Multiple Variables
文章内容均来自斯坦福大学的Andrew Ng教授讲解的Machine Learning课程,本文是针对该课程的个人学习笔记,如有疏漏,请以原课程所讲述内容为准.感谢博主Rachel Zhang 的个人 ...
- 斯坦福第四课:多变量线性回归(Linear Regression with Multiple Variables)
4.1 多维特征 4.2 多变量梯度下降 4.3 梯度下降法实践 1-特征缩放 4.4 梯度下降法实践 2-学习率 4.5 特征和多项式回归 4.6 正规方程 4.7 正规方程及不可逆性 ...
- python实现多变量线性回归(Linear Regression with Multiple Variables)
本文介绍如何使用python实现多变量线性回归,文章参考NG的视频和黄海广博士的笔记 现在对房价模型增加更多的特征,例如房间数楼层等,构成一个含有多个变量的模型,模型中的特征为( x1,x2,..., ...
- Ng第四课:多变量线性回归(Linear Regression with Multiple Variables)
4.1 多维特征 4.2 多变量梯度下降 4.3 梯度下降法实践 1-特征缩放 4.4 梯度下降法实践 2-学习率 4.5 特征和多项式回归 4.6 正规方程 4.7 正规方程及不可逆性 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 4_Linear Regression with Multiple Variables 多变量线性回归
Lecture 4 Linear Regression with Multiple Variables 多变量线性回归 4.1 多维特征 Multiple Features4.2 多变量梯度下降 Gr ...
- 机器学习第4课:多变量线性回归(Linear Regression with Multiple Variables)
4.1 多维特征 目前为止,我们探讨了单变量/特征的回归模型,现在我们对房价模型增加更多的特征, 例如房间数楼层等,构成一个含有多个变量的模型,模型中的特征为(x1,x2,...,xn).
随机推荐
- 华为OceanConnect物联网平台概念全景 | 我的物联网成长记
作者 | 我是卤蛋 华为云OceanConnect IoT云服务包括应用管理.设备管理.系统管理等能力,实现统一安全的网络接入.各种终端的灵活适配.海量数据的采集分析,从而实现新价值的创造. 华为云O ...
- Vim 便捷 | 自己的Vim
在.vimrc中安排自己的Vim set softtabstop=4 "将连续数量的空格视为一个制表符 set shiftwidth=4 "自动缩进所使用的空白数 set auto ...
- python面试看这一篇就够了
python-面试通关宝典 有面Python开发方向的,看这一个repo就够啦? 语言特性 1.谈谈对 Python 和其他语言的区别 Python属于解释型语言,当程序运行时,是一行一行的解释,并运 ...
- beacon帧字段结构最全总结(二)——HT字段总结
一.HT Capabilities HT Capabilities:802.11n的mac层给802.11的mac层加入了高吞吐量单元.所有新加的802.11n功能都是通过管理帧中的HT单元才得以实现 ...
- javascript iframe跳转问题
javascript iframe跳转问题如果在iframe里面有要点击跳转最外层的连接 要只能用<pre> <div onclick="parent.location.h ...
- bash:双引号和单引号
单引号.双引号都能引用字符和字符串 单引号:'$i'仅仅是字符,没有变量的意思了 双以号:变量等能表示出来
- php5.6开启curl
1. 打开php安装目录,打开ext目录,是否有php_curl.dll扩展文件,如果没有该扩展文件,请在网上下载此文件. 2. 打开php.ini,找到 ;extension=php_cu ...
- 深入ObjC GCD中的dispatch group工作原理。
本文是基于GCD的支持库libdispatch的源代码分析的结果或是用于作为源代码阅读的参考,尽量不帖代码,力求用UML图来说明工作流. 本文参考的源代码版本为v501.20.1,如有兴趣请自行到苹果 ...
- Javascript脚本语言
找组件用 id (唯一) 2.name 样式 使用分类 1 页面中 2 建JS文件 可以放在head也可以在body 工作区可以有 1 全局变量 2 由多个函数构成 标签编辑器 onChange 改变 ...
- 官宣!Amazon EMR正式支持Apache Hudi
Apache Hudi是一个开源的数据管理框架,其通过提供记录级别的insert, update, upsert和delete能力来简化增量数据处理和数据管道开发.Upsert指的是将记录插入到现有 ...