AlexNet,VGG,GoogleNet,ResNet
AlexNet:
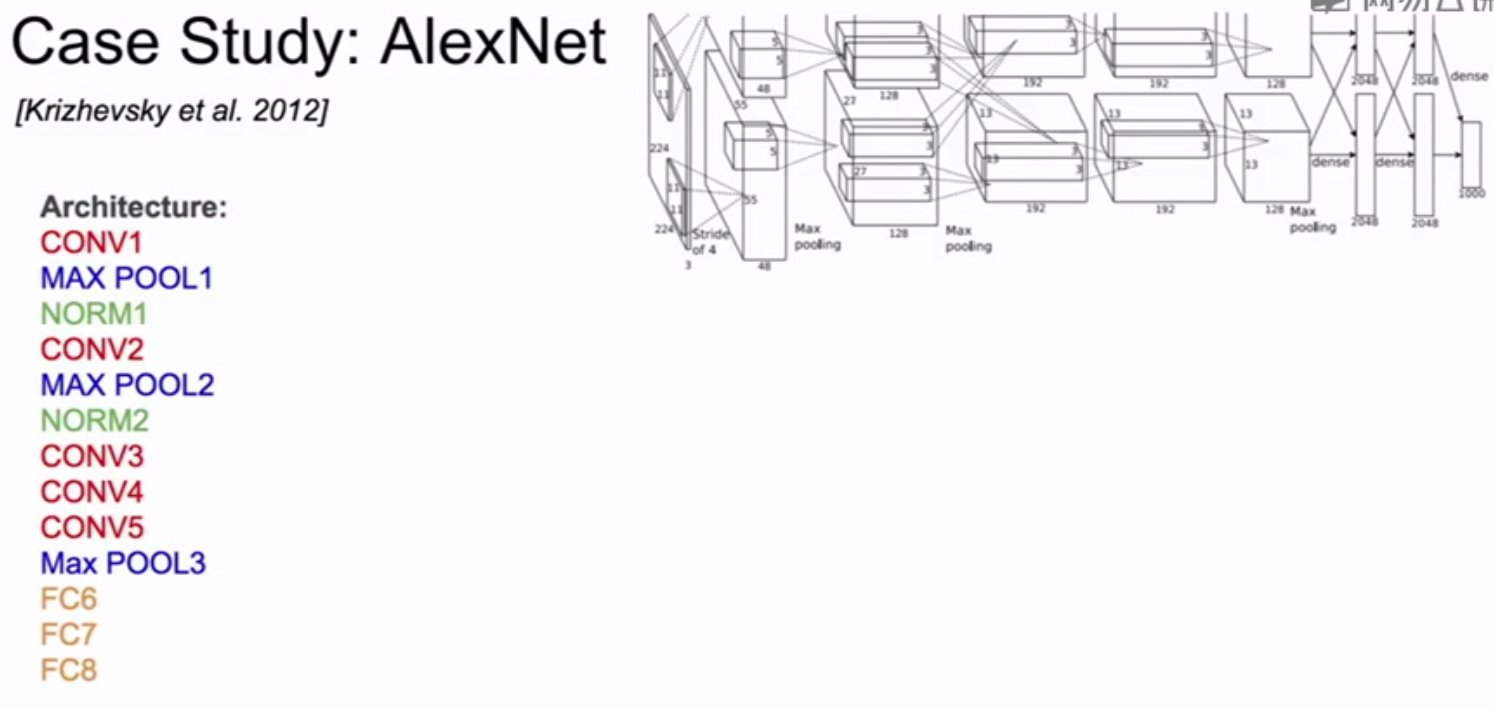


VGGNet:

用3x3的小的卷积核代替大的卷积核,让网络只关注相邻的像素

3x3的感受野与7x7的感受野相同,但是需要更深的网络
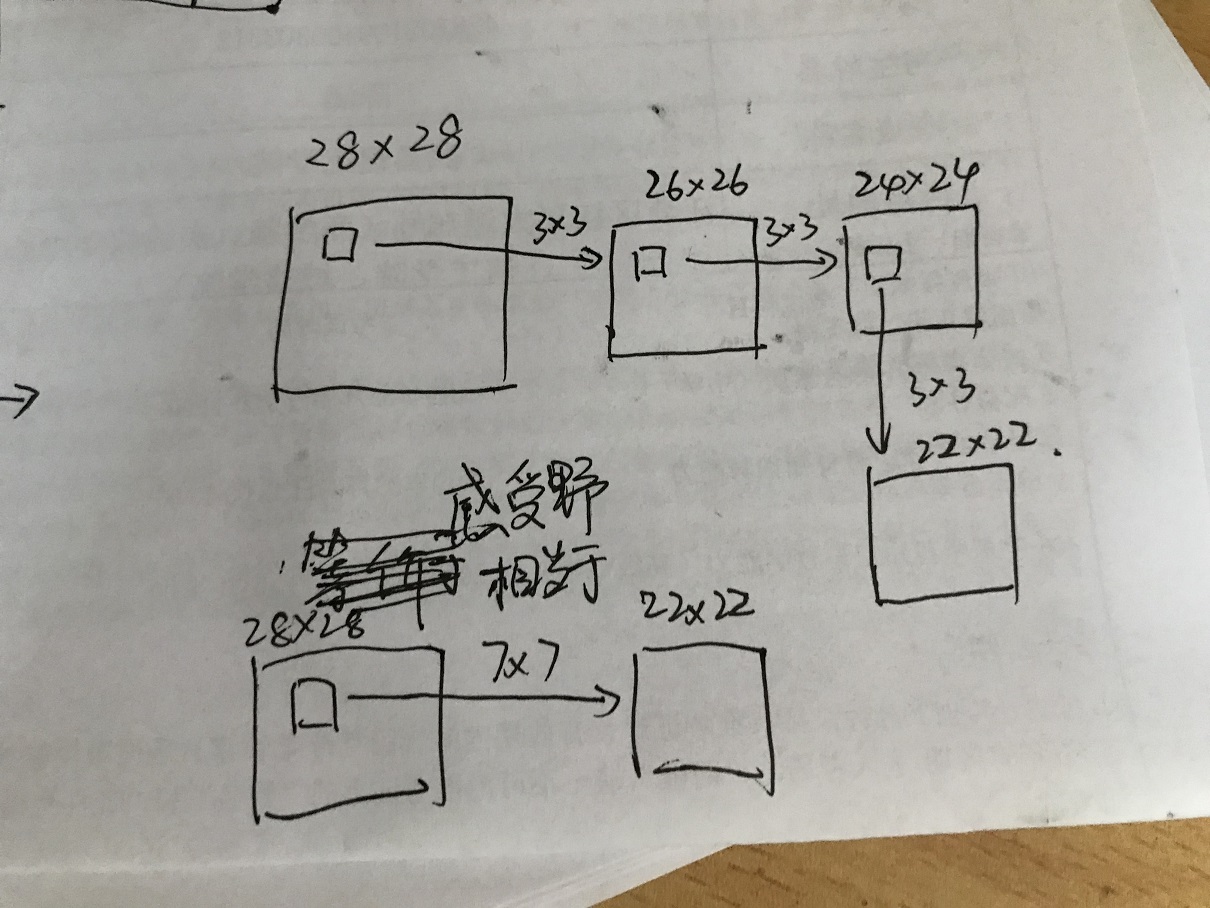
这样使得参数更少


大多数内存占用在靠前的卷积层,大部分的参数在后面的全连接层

GoogleNet:
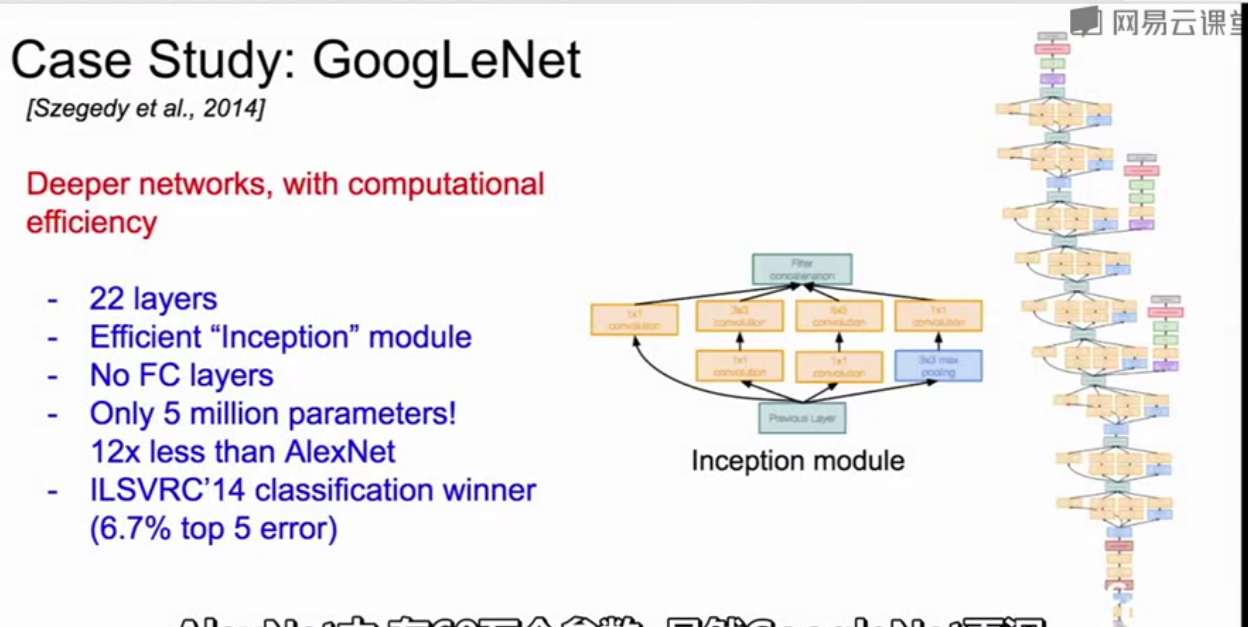

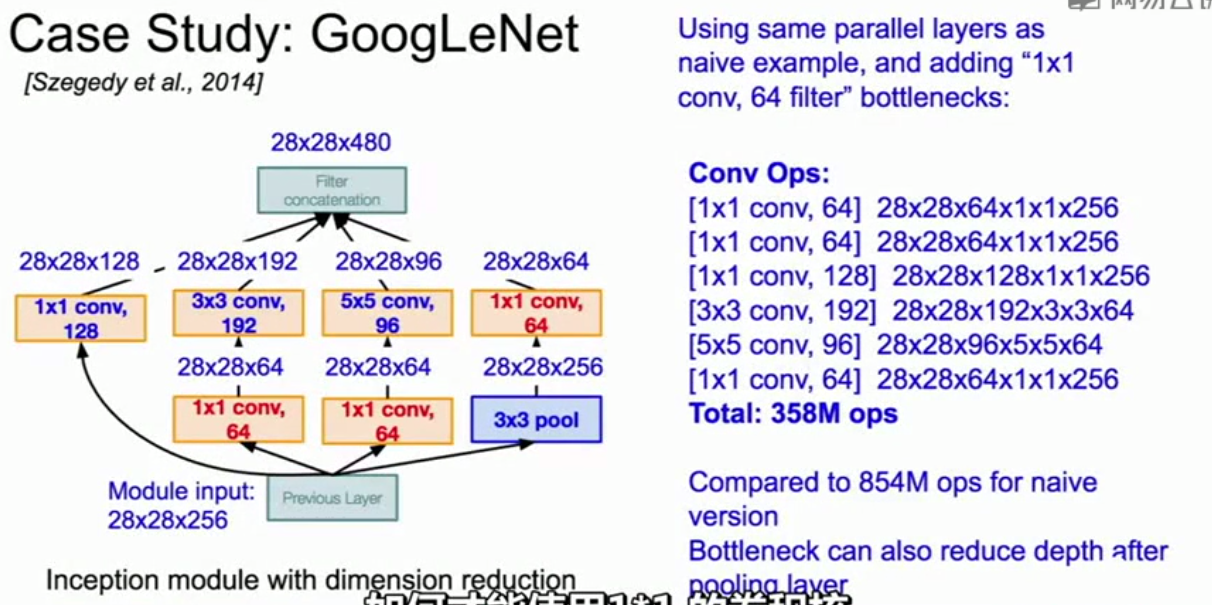
Inception模块:设计了一个局部网络拓扑结构,然后堆放大量的局部拓扑在每一个的顶部
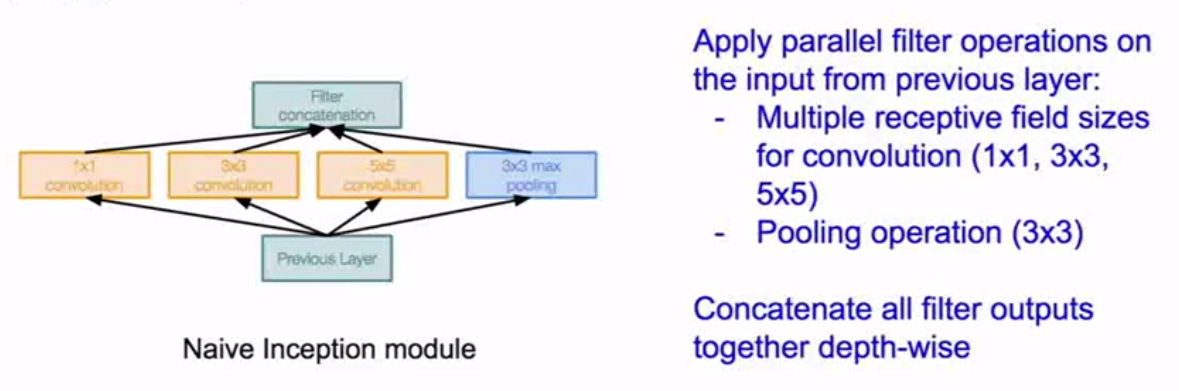
目的是将卷积和池化(filter)操作并行,最后在顶层将得到的输出串联得到一个张量进入下一层
这种做法会增加庞大的计算量:

(图中输入输出尺寸不变是因为增加了零填充)
为了降低计算量,会在inception之前增加一个瓶颈层通过1x1的卷积核进行降维操作

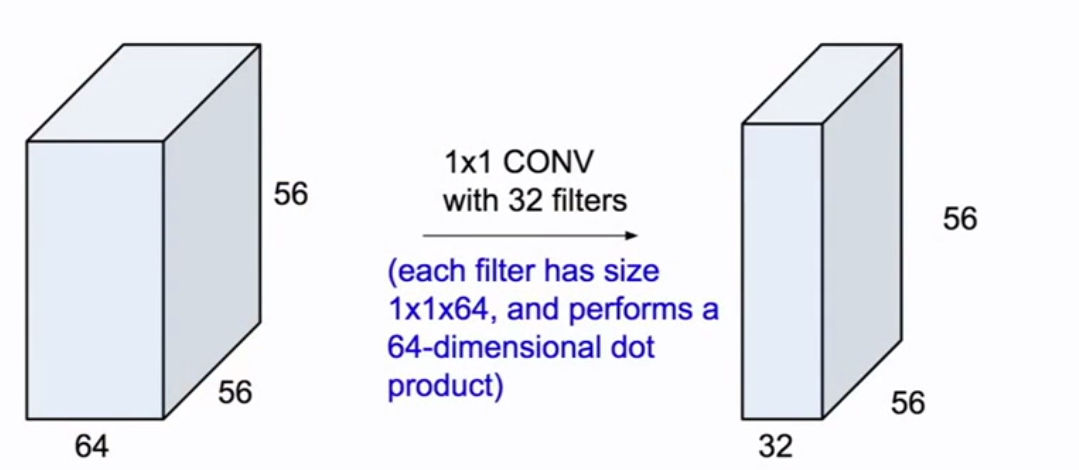


相比没有1x1卷积核的降维,计算量从8.54亿次减小到3.58亿次
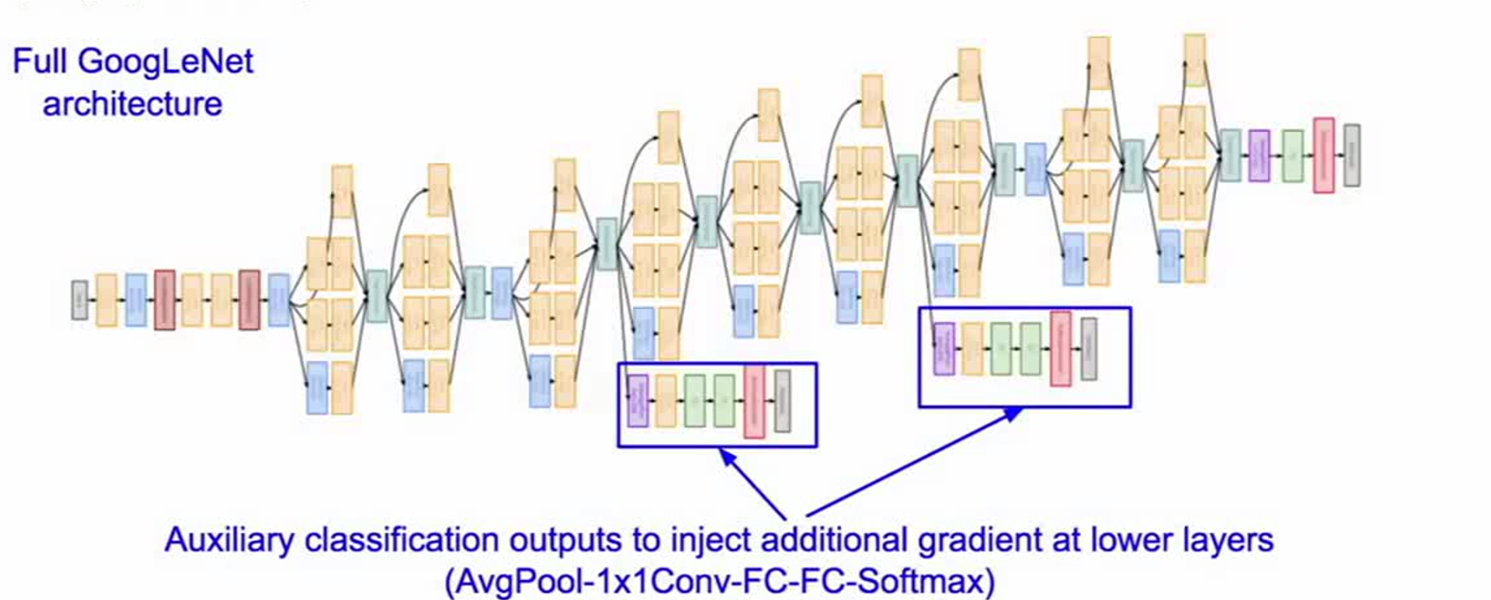
网络结构尾部完全移除全连接层,大量减少参数;有两个额外的辅助分类层

ResNet:

单纯不停的堆叠卷积层池化层plain convolutional neural network不使用残差结构)来加深网络的深度并不能表现得更好(不是因为过拟合,在训练集上表现得也不如20层的网络)
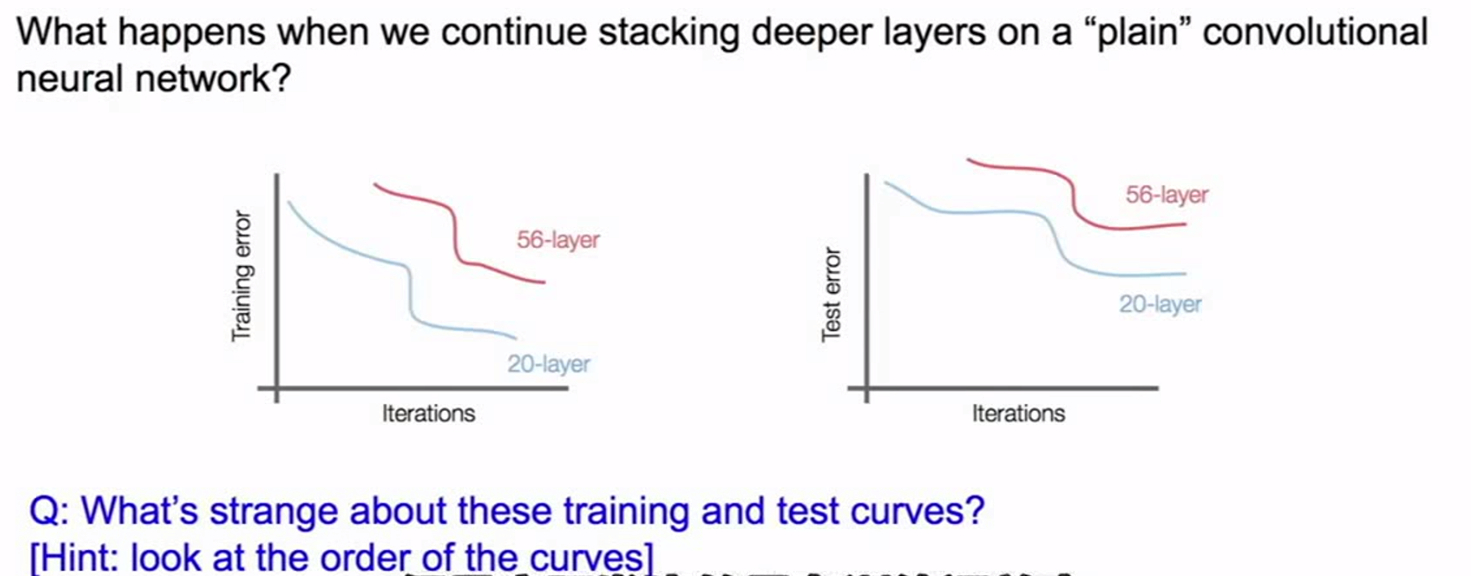
这是一个优化问题,深层的网络更加难以优化

深层的网络至少会跟浅层的网络表现的一样好,解决方案是将从浅层模型学到的层通过恒等映射copy到较深的层。
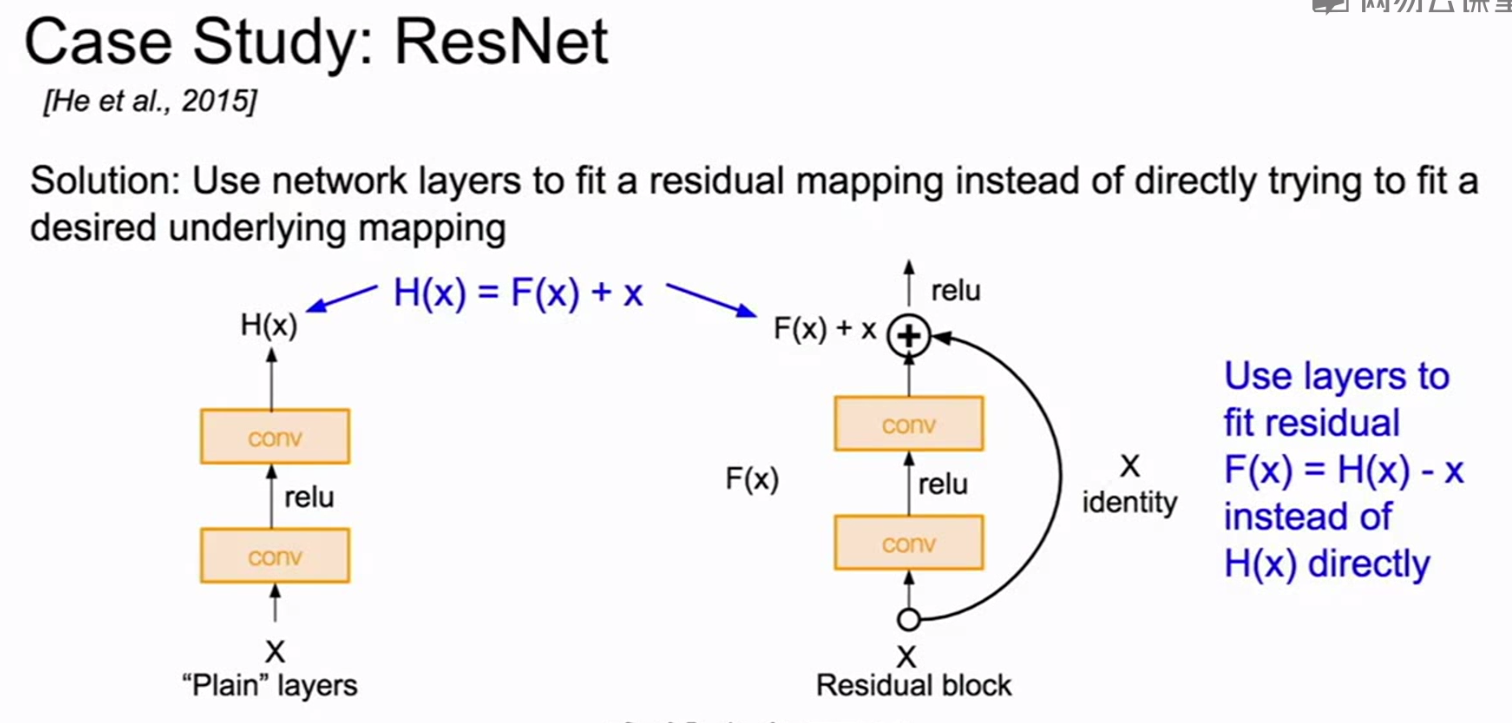
若将输入设为X,将某一有参网络层设为H,那么以X为输入的此层的输出将为H(X)。一般的CNN网络如Alexnet/VGG等会直接通过训练学习出参数函数H的表达,从而直接学习X -> H(X)。
而残差学习则是致力于使用多个有参网络层来学习输入、输出之间的参差即H(X) - X即学习X -> (H(X) - X) + X。其中X这一部分为直接的identity mapping,而H(X) - X则为有参网络层要学习的输入输出间残差。
残差学习单元通过Identity mapping的引入在输入、输出之间建立了一条直接的关联通道,从而使得强大的有参层集中精力学习输入、输出之间的残差。一般我们用F(X, Wi)来表示残差映射,那么输出即为:Y = F(X, Wi) + X。
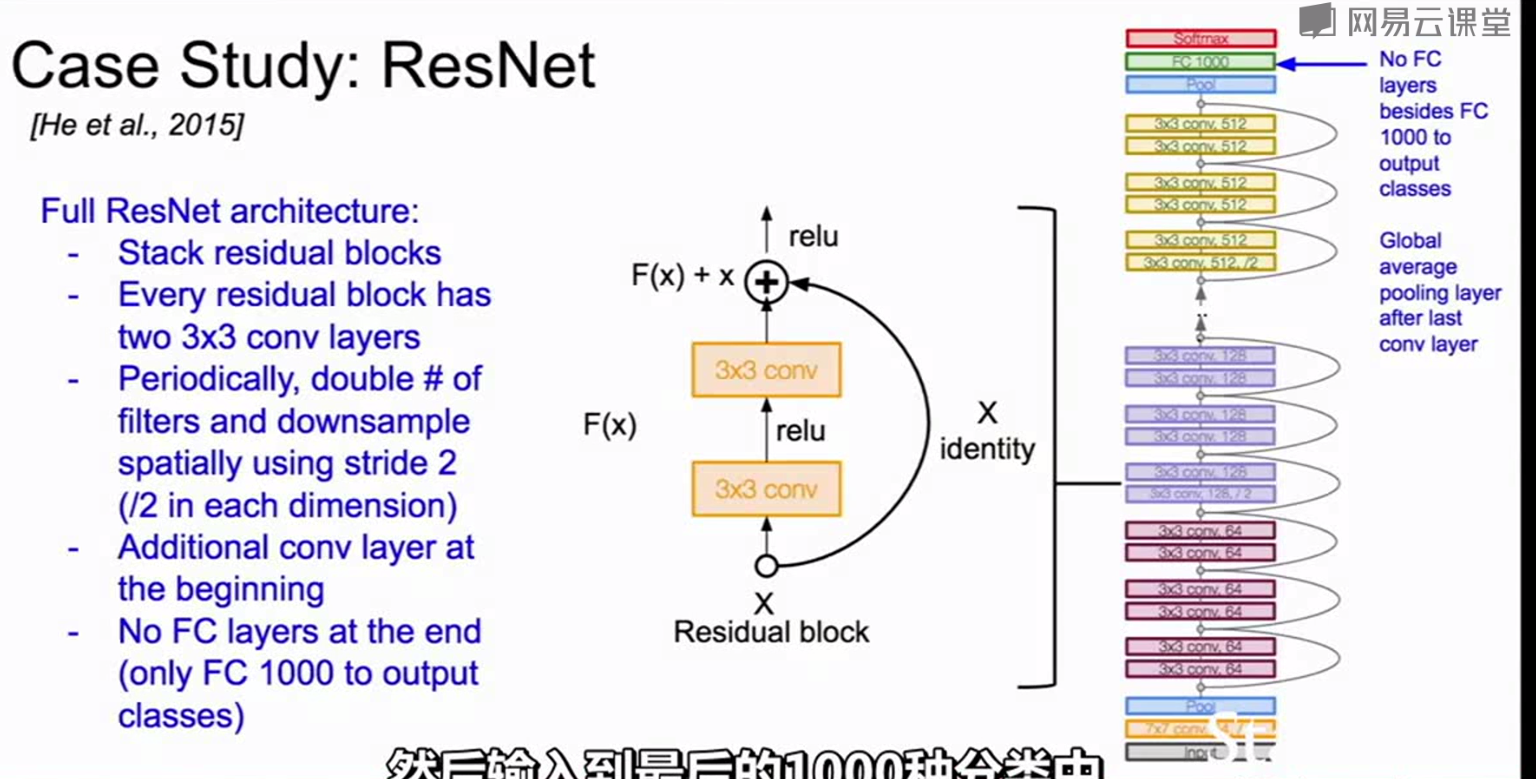
resnet也用到了GoogleNet中的瓶颈层操作


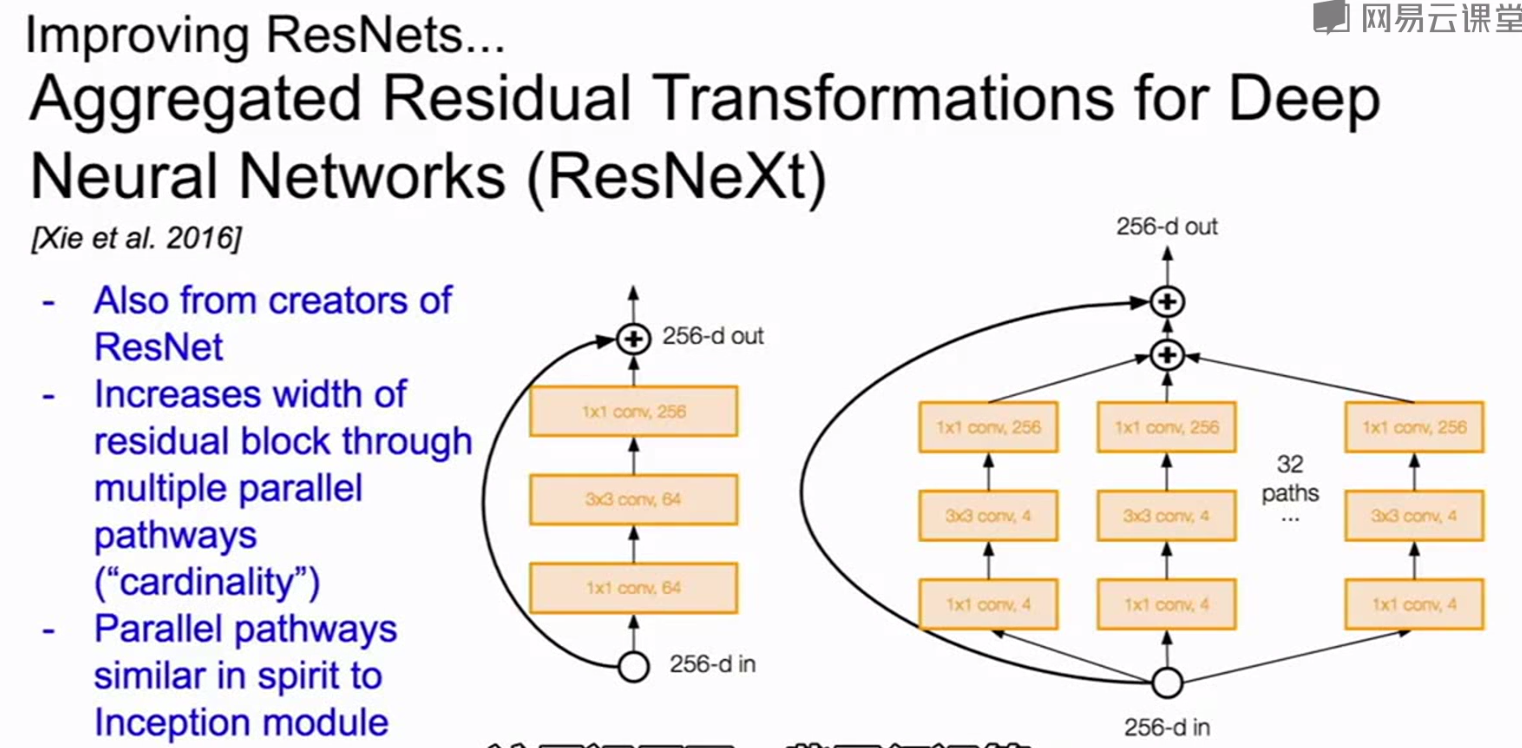
改进的残差:

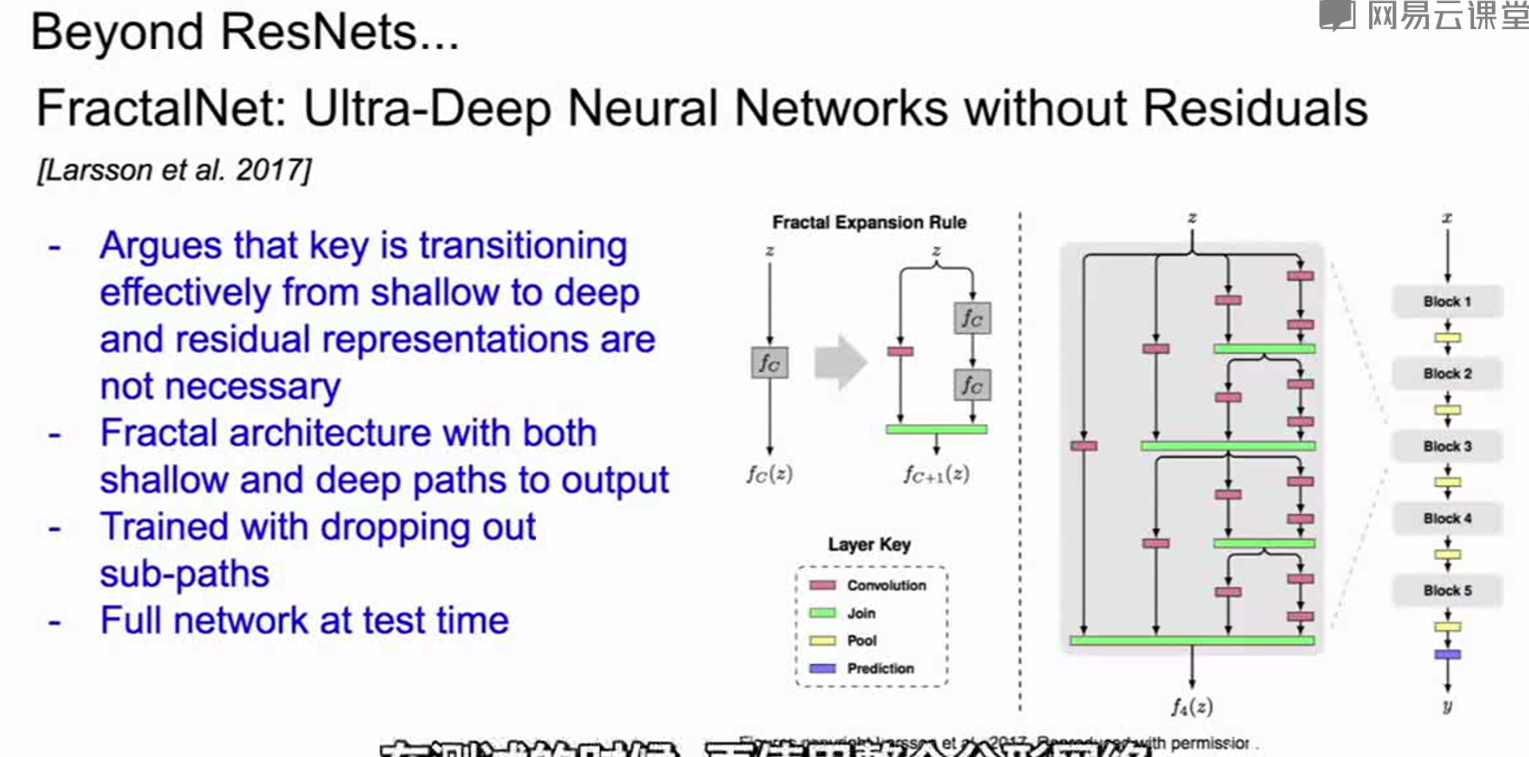
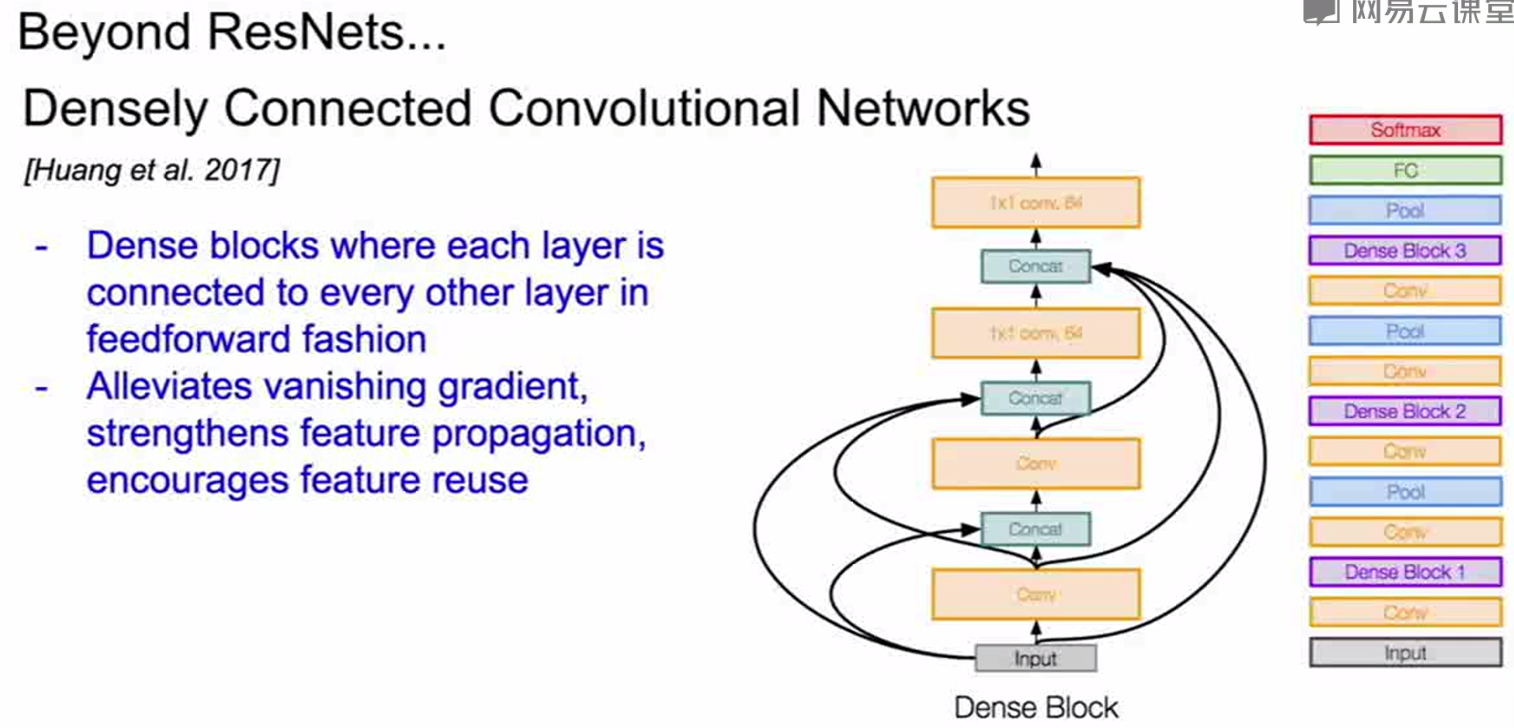
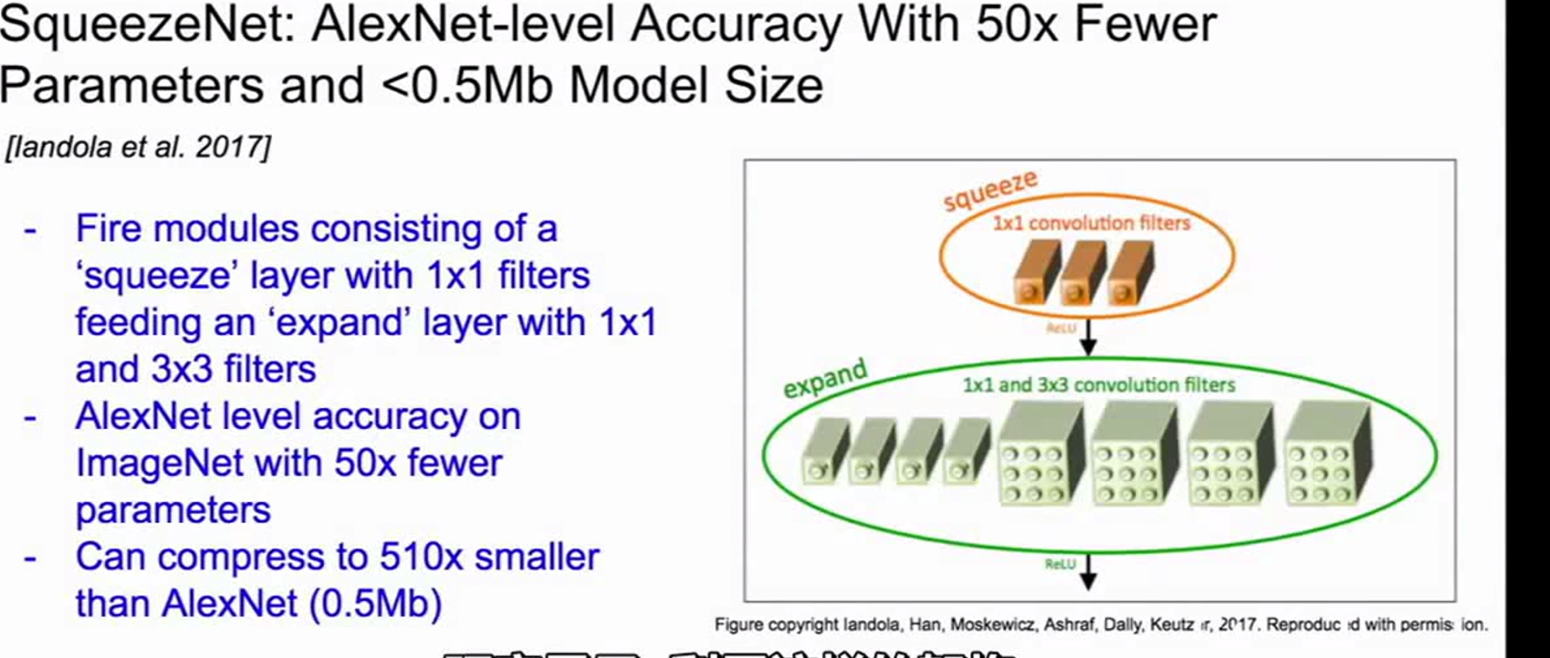
其他的网络:

1
AlexNet,VGG,GoogleNet,ResNet的更多相关文章
- CNN Architectures(AlexNet,VGG,GoogleNet,ResNet,DenseNet)
AlexNet (2012) The network had a very similar architecture as LeNet by Yann LeCun et al but was deep ...
- LeNet, AlexNet, VGGNet, GoogleNet, ResNet的网络结构
1. LeNet 2. AlexNet 3. 参考文献: 1. 经典卷积神经网络结构——LeNet-5.AlexNet.VGG-16 2. 初探Alexnet网络结构 3.
- #Deep Learning回顾#之LeNet、AlexNet、GoogLeNet、VGG、ResNet
CNN的发展史 上一篇回顾讲的是2006年Hinton他们的Science Paper,当时提到,2006年虽然Deep Learning的概念被提出来了,但是学术界的大家还是表示不服.当时有流传的段 ...
- (转)ResNet, AlexNet, VGG, Inception: Understanding various architectures of Convolutional Networks
ResNet, AlexNet, VGG, Inception: Understanding various architectures of Convolutional Networks by KO ...
- Deep Learning 经典网路回顾#之LeNet、AlexNet、GoogLeNet、VGG、ResNet
#Deep Learning回顾#之LeNet.AlexNet.GoogLeNet.VGG.ResNet 深入浅出——网络模型中Inception的作用与结构全解析 图像识别中的深度残差学习(Deep ...
- 经典深度学习CNN总结 - LeNet、AlexNet、GoogLeNet、VGG、ResNet
参考了: https://www.cnblogs.com/52machinelearning/p/5821591.html https://blog.csdn.net/qq_24695385/arti ...
- Deep Learning回顾#之LeNet、AlexNet、GoogLeNet、VGG、ResNet - 我爱机器学习
http://www.cnblogs.com/52machinelearning/p/5821591.html
- 深度学习方法(五):卷积神经网络CNN经典模型整理Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 关于卷积神经网络CNN,网络和文献中 ...
- L17 AlexNet VGG NiN GoogLeNet
深度卷积神经网络(AlexNet) LeNet: 在大的真实数据集上的表现并不尽如⼈意. 1.神经网络计算复杂. 2.还没有⼤量深⼊研究参数初始化和⾮凸优化算法等诸多领域. 机器学习的特征提取:手工定 ...
随机推荐
- 阿里云数据库自研产品亮相国际顶级会议ICDE 推动云原生数据库成为行业标准
4月9日,澳门当地时间下午4:00-5:30,阿里云在ICDE 2019举办了主题为“云时代的数据库”的专场分享研讨会. 本次专场研讨会由阿里巴巴集团副总裁.高级研究员,阿里云智能数据库产品事业部负责 ...
- java对象转化为json字符串并传到前台
package cc.util; import java.util.ArrayList; import java.util.Date; import java.util.HashMap; import ...
- oralce GROUPING
/*从上面的结果中我们很容易发现,每个统计数据所对应的行都会出现null, 如何来区分到底是根据那个字段做的汇总呢,grouping函数判断是否合计列!*/ select decode(groupin ...
- @atcoder - AGC038E@ Gachapon
目录 @description@ @solution - 1@ @accepted code - 1@ @solution - 2@ @accepted code - 2@ @details@ @de ...
- JSON解析的成长史——原来还可以这么简单
本文系统介绍,JSON解析的成长史,未经允许,禁止转载. JSON是一种轻量级的数据格式,一般用于数据交互 Android交互数据主要有两种方式:Json和Xml,Xml格式的数据量要比Json格式略 ...
- Linux 用户he用户组管理
8)系统中有一类用户称为伪用户(psuedo users). 这些用户在/etc/passwd 文件中也占有一条记录,但是不能登陆,因为他们的登陆shell 为空,他们的存在主要是方便系统管理,满足 ...
- mysql数据库之mysql下载与设置
下载和安装mysql数据库 mysql为我们提供了开源的安装在各个操作系统上的安装包,包括ios,liunx,windows. mysql的安装,启动和基础配置-------linux版本 mysql ...
- BZOJ 1935 Tree 园丁的烦恼 CDQ分治/主席树
CDQ分治版本 我们把询问拆成四个前缀和,也就是二维前缀和的表达式, 我们把所有操作放入一个序列中 操作1代表在x,y出现一个树 操作2代表加上在x,y内部树的个数 操作3代表减去在x,y内部树的个数 ...
- Oracle ltrim() 函数用法
Oracle ltrim() 函数用法 2015-03-21 20:42:40 Je_WangZhe 阅读数 8834更多 分类专栏: Oracle 版权声明:本文为博主原创文章,遵循CC 4.0 ...
- sleep usleep nanosleep alarm setitimer使用
sleep使用的是alarm之类的定时器,定时器是使得进程被挂起,使进程处于就绪的状态. signal+alarm定时器 alarm参数的类型为uint, 并且不能填0 #include <st ...