InceptionV3代码解析
InceptionV3代码解析
- import tensorflow as tf
- from datetime import datetime
- import math
- import time
- ##参考tensorflow实战书籍+博客https://blog.csdn.net/superman_xxx/article/details/65451916,不过丰富了很多细节
- ##适合像我一样的初学者
- slim = tf.contrib.slim
- #Slim is an interface to contrib functions, examples and models.
- #只是一个接口作用
- trunc_normal = lambda stddev: tf.truncated_normal_initializer(0.0, stddev)
- #匿名函数 lambda x: x * x 实际上就是:返回x的平方
- # tf.truncated_normal_initializer产生截断的正态分布
- ########定义函数生成网络中经常用到的函数的默认参数########
- # 默认参数:卷积的激活函数、权重初始化方式、标准化器等
- def inception_v3_arg_scope(weight_decay=0.00004, # 设置L2正则的weight_decay
- stddev=0.1, # 标准差默认值0.1
- batch_norm_var_collection='moving_vars'):
- # 定义batch normalization(批量标准化/归一化)的参数字典
- batch_norm_params = {
- 'decay': 0.9997, # 定义参数衰减系数
- 'epsilon': 0.001,
- 'updates_collections': tf.GraphKeys.UPDATE_OPS,
- 'variables_collections': {
- 'beta': None,
- 'gamma': None,
- 'moving_mean': [batch_norm_var_collection],
- 'moving_variance': [batch_norm_var_collection],#值就是前面设置的batch_norm_var_collection='moving_vars'
- }
- }
- # 给函数的参数自动赋予某些默认值
- # slim.arg_scope常用于为tensorflow里的layer函数提供默认值以使构建模型的代码更加紧凑苗条(slim):
- with slim.arg_scope([slim.conv2d, slim.fully_connected],
- weights_regularizer=slim.l2_regularizer(weight_decay)):
- # 对[slim.conv2d, slim.fully_connected]自动赋值,可以是列表或元组
- # 使用slim.arg_scope后就不需要每次都重复设置参数了,只需要在有修改时设置
- with slim.arg_scope( # 嵌套一个slim.arg_scope对卷积层生成函数slim.conv2d的几个参数赋予默认值
- [slim.conv2d],
- weights_initializer=trunc_normal(stddev), # 权重初始化器
- activation_fn=tf.nn.relu, # 激活函数
- normalizer_fn=slim.batch_norm, # 标准化器
- normalizer_params=batch_norm_params) as sc: # 标准化器的参数设置为前面定义的batch_norm_params
- return sc # 最后返回定义好的scope
- ########定义函数可以生成Inception V3网络的卷积部分########
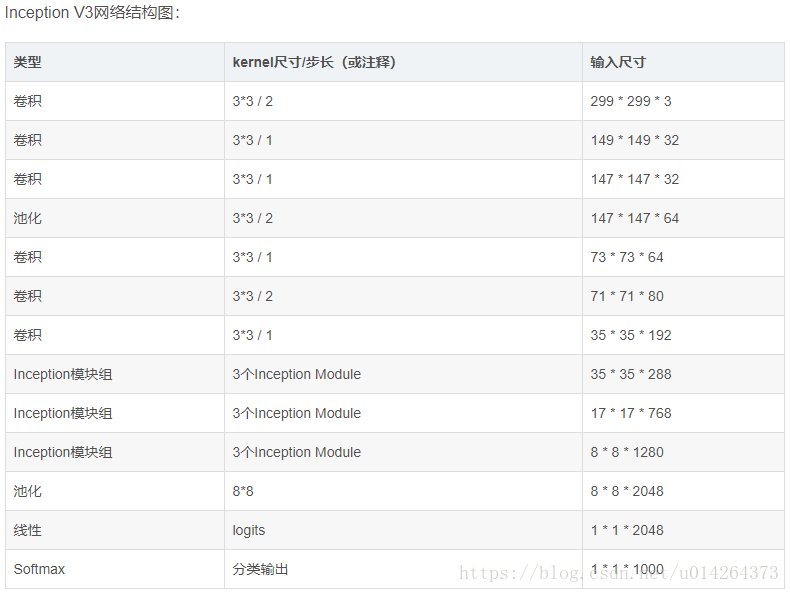
- #########Inception V3架构见TENSORFLOW实战书-黄文坚 p124-p125页
- def inception_v3_base(inputs, scope=None):
- '''
- Args:
- inputs:输入的tensor
- scope:包含了函数默认参数的环境
- '''
- end_points = {} # 定义一个字典表保存某些关键节点供之后使用
- with tf.variable_scope(scope, 'InceptionV3', [inputs]):
- with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d], # 对三个参数设置默认值
- stride=1, padding='VALID'):
- # 正式定义Inception V3的网络结构。首先是前面的非Inception Module的卷积层
- #输入图像尺寸299 x 299 x 3
- # slim.conv2d的第一个参数为输入的tensor,第二个是输出的通道数,卷积核尺寸,步长stride,padding模式
- net = slim.conv2d(inputs, 32, [3, 3], stride=2, scope='Conv2d_1a_3x3')
- # 输出尺寸149 x 149 x 32
- '''
- 因为使用了slim以及slim.arg_scope,我们一行代码就可以定义好一个卷积层
- 相比AlexNet使用好几行代码定义一个卷积层,或是VGGNet中专门写一个函数定义卷积层,都更加方便
- '''
- net = slim.conv2d(net, 32, [3, 3], scope='Conv2d_2a_3x3')
- # 输出尺寸147 x 147 x 32
- net = slim.conv2d(net, 64, [3, 3], padding='SAME', scope='Conv2d_2b_3x3')
- # 输出尺寸147 x 147 x 64
- net = slim.max_pool2d(net, [3, 3], stride=2, scope='MaxPool_3a_3x3')
- # 输出尺寸73 x 73 x 64
- net = slim.conv2d(net, 80, [1, 1], scope='Conv2d_3b_1x1')
- #输出尺寸 73 x 73 x 80.
- net = slim.conv2d(net, 192, [3, 3], scope='Conv2d_4a_3x3')
- #输出尺寸 71 x 71 x 192.
- net = slim.max_pool2d(net, [3, 3], stride=2, scope='MaxPool_5a_3x3')
- # 输出尺寸35 x 35 x 192.
- '''上面部分代码一共有5个卷积层,2个池化层,实现了对图片数据的尺寸压缩,并对图片特征进行了抽象
- 有个疑问是框架例里给出的表格中是6个卷积和一个池化,并没有1x1的卷积,为什么要这么做,以及scope后面的名字为什么要这样叫。
- '''
- '''
- 接下来就是三个连续的Inception模块组,三个Inception模块组中各自分别有多个Inception Module,这部分是Inception Module V3
- 的精华所在。每个Inception模块组内部的几个Inception Mdoule结构非常相似,但是存在一些细节的不同
- '''
- # Inception blocks
- with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d], # 设置所有模块组的默认参数
- stride=1, padding='SAME'): # 将所有卷积层、最大池化、平均池化层步长都设置为1
- #注意这个模块已经统一指定了padding='SAME',后面不用再说明
- # 第一个模块组包含了三个结构类似的Inception Module
- # 第一个模块组第一个Inception Module,Mixed_5b
- with tf.variable_scope('Mixed_5b'): # 第一个Inception Module名称。Inception Module有四个分支
- with tf.variable_scope('Branch_0'): # 第一个分支64通道的1*1卷积
- branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
- #输出尺寸35*35*64
- with tf.variable_scope('Branch_1'): # 第二个分支48通道1*1卷积后一层链接一个64通道的5*5卷积
- branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0a_1x1')
- #输出尺寸35*35*48
- branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv2d_0b_5x5')
- #输出尺寸35*35*64
- with tf.variable_scope('Branch_2'): #第三个分支64通道1*1卷积后一层链接2个96通道的5*5卷积
- branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
- #输出尺寸35*35*64
- branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
- #输出尺寸35*35*96
- branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
- # 输出尺寸35*35*96
- with tf.variable_scope('Branch_3'): # 第四个分支为3*3的平均池化后一层连接32通道的1*1卷积
- branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
- # 输出尺寸35*35*192
- branch_3 = slim.conv2d(branch_3, 32, [1, 1], scope='Conv2d_0b_1x1')
- # 输出尺寸35*35*32
- net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
- # 将四个分支的输出合并在一起(第三个维度合并,即输出通道上合并)64+64+96+32=256个通道
- # 输出尺寸35*35*256
- # 第一个模块组第二个Inception Module 名称是:Mixed_5c
- with tf.variable_scope('Mixed_5c'): #同样有4个分支,唯一不同的是第4个分支最后接的是64输出通道
- with tf.variable_scope('Branch_0'):
- branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
- # 输出尺寸35*35*64
- with tf.variable_scope('Branch_1'):
- branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0b_1x1')
- # 输出尺寸35*35*48
- branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv_1_0c_5x5')
- # 输出尺寸35*35*64
- with tf.variable_scope('Branch_2'):
- branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
- # 输出尺寸35*35*64
- branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
- # 输出尺寸35*35*96
- branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
- # 输出尺寸35*35*96
- with tf.variable_scope('Branch_3'):
- branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
- # 输出尺寸35*35*192
- branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
- # 输出尺寸35*35*64
- net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
- # 将四个分支的输出合并在一起(第三个维度合并,即输出通道上合并)64+64+96+64=288个通道
- # 输出尺寸35*35*288
- # 第一个模块组第3个Inception Module 名称是:Mixed_5d
- with tf.variable_scope('Mixed_5d'):
- with tf.variable_scope('Branch_0'):
- branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
- with tf.variable_scope('Branch_1'):
- branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0a_1x1')
- branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv2d_0b_5x5')
- with tf.variable_scope('Branch_2'):
- branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
- branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
- branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
- with tf.variable_scope('Branch_3'):
- branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
- branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
- net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
- # 将四个分支的输出合并在一起(第三个维度合并,即输出通道上合并)64+64+96+64=288个通道
- # 输出尺寸35*35*288
- # 第二个Inception模块组是一个非常大的模块组,包含了5个Inception Mdoule,2-5个Inception Mdoule结构非常相似
- #第二个模块组第一个Inception Module 名称是:Mixed_6a
- #输入是35*35*288
- with tf.variable_scope('Mixed_6a'): #包含3个分支
- with tf.variable_scope('Branch_0'):
- branch_0 = slim.conv2d(net, 384, [3, 3], stride=2,
- padding='VALID', scope='Conv2d_1a_1x1')
- # padding='VALID'图片尺寸会被压缩,通道数增加
- # 输出尺寸17*17*384
- with tf.variable_scope('Branch_1'): #64通道的1*1加2个96通道的3*3卷积
- branch_1 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
- #输出尺寸35 * 35 * 64
- branch_1 = slim.conv2d(branch_1, 96, [3, 3], scope='Conv2d_0b_3x3')
- #输出尺寸35*35*96
- branch_1 = slim.conv2d(branch_1, 96, [3, 3], stride=2,
- padding='VALID', scope='Conv2d_1a_1x1')
- # 图片被压缩/输出尺寸17*17*96
- with tf.variable_scope('Branch_2'):
- branch_2 = slim.max_pool2d(net, [3, 3], stride=2, padding='VALID',
- scope='MaxPool_1a_3x3')
- #输出尺寸17 * 17 * 288(这里大家注意,书上还有很多博客上都是384+96+256=736并不是768,所以最后应该加288)
- net = tf.concat([branch_0, branch_1, branch_2], 3)
- # 输出尺寸定格在17 x 17 x 768
- # 第二个模块组第二个Inception Module 名称是:Mixed_6b
- with tf.variable_scope('Mixed_6b'): #4个分支
- with tf.variable_scope('Branch_0'):
- branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
- # 输出尺寸17*17*192
- with tf.variable_scope('Branch_1'):
- branch_1 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1')
- # 输出尺寸17 * 17 * 128
- branch_1 = slim.conv2d(branch_1, 128, [1, 7],
- scope='Conv2d_0b_1x7')
- # 输出尺寸17 * 17 * 128
- # 串联1*7卷积和7*1卷积合成7*7卷积,减少了参数,减轻了过拟合
- branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
- # 输出尺寸17 * 17 * 192
- with tf.variable_scope('Branch_2'):
- branch_2 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1')
- # 输出尺寸17 * 17 * 128
- # 反复将7*7卷积拆分
- branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope='Conv2d_0b_7x1')
- branch_2 = slim.conv2d(branch_2, 128, [1, 7], scope='Conv2d_0c_1x7')
- branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope='Conv2d_0d_7x1')
- branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
- # 这种方法算是利用Factorization into small convolutions 的典范
- with tf.variable_scope('Branch_3'): #3*3的平均池化
- branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
- # 输出尺寸17 * 17 * 768
- branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
- # 输出尺寸17 * 17 * 192
- net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
- # 输出尺寸定格在17 x 17 x (192*4)=17*17*768
- # 第二个模块组第三个Inception Module 名称是:Mixed_6c
- # 同前面一个相似,第二个分支和第三个分支的前几层通道由120升为160
- with tf.variable_scope('Mixed_6c'):
- with tf.variable_scope('Branch_0'):
- '''
- 我们的网络每经过一个inception module,即使输出尺寸不变,但是特征都相当于被重新精炼了一遍,
- 其中丰富的卷积和非线性化对提升网络性能帮助很大。
- '''
- branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
- with tf.variable_scope('Branch_1'):
- branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
- branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope='Conv2d_0b_1x7')
- branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
- with tf.variable_scope('Branch_2'):
- branch_2 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
- branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0b_7x1')
- branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope='Conv2d_0c_1x7')
- branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0d_7x1')
- branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
- with tf.variable_scope('Branch_3'):
- branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
- branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
- net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
- # 输出尺寸定格在17 x 17 x (192*4)=17*17*768
- # 第二个模块组第四个Inception Module 名称是:Mixed_6d
- # 和前面一个完全一样,增加卷积和非线性,提炼特征
- with tf.variable_scope('Mixed_6d'):
- with tf.variable_scope('Branch_0'):
- branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
- with tf.variable_scope('Branch_1'):
- branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
- branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope='Conv2d_0b_1x7')
- branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
- with tf.variable_scope('Branch_2'):
- branch_2 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
- branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0b_7x1')
- branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope='Conv2d_0c_1x7')
- branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0d_7x1')
- branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
- with tf.variable_scope('Branch_3'):
- branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
- branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
- net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
- # 输出尺寸定格在17 x 17 x (192*4)=17*17*768
- # 第二个模块组第五个Inception Module 名称是:Mixed_6e
- # 也同前面一样,通道数变为192,但是要将Mixed_6e存储在end_points中
- with tf.variable_scope('Mixed_6e'):
- with tf.variable_scope('Branch_0'):
- branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
- with tf.variable_scope('Branch_1'):
- branch_1 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
- branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope='Conv2d_0b_1x7')
- branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
- with tf.variable_scope('Branch_2'):
- branch_2 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
- branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope='Conv2d_0b_7x1')
- branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0c_1x7')
- branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope='Conv2d_0d_7x1')
- branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
- with tf.variable_scope('Branch_3'):
- branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
- branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
- net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
- # 输出尺寸定格在17 x 17 x (192*4)=17*17*768
- end_points['Mixed_6e'] = net
- # 将Mixed_6e存储于end_points中,作为Auxiliary Classifier辅助模型的分类
- # 第三个Inception模块包含了3个Inception Mdoule,后两个个Inception Mdoule结构非常相似
- # 第三个模块组第一个Inception Module 名称是:Mixed_7a
- with tf.variable_scope('Mixed_7a'): # 3个分支
- with tf.variable_scope('Branch_0'):
- branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
- # 输出尺寸17*17*192
- branch_0 = slim.conv2d(branch_0, 320, [3, 3], stride=2,
- padding='VALID', scope='Conv2d_1a_3x3')
- # 压缩图片# 输出尺寸8*8*320
- with tf.variable_scope('Branch_1'):
- branch_1 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
- branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope='Conv2d_0b_1x7')
- branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
- branch_1 = slim.conv2d(branch_1, 192, [3, 3], stride=2,
- padding='VALID', scope='Conv2d_1a_3x3')
- # 输出尺寸8*8*192
- with tf.variable_scope('Branch_2'): # 池化层不会对输出通道数产生改变
- branch_2 = slim.max_pool2d(net, [3, 3], stride=2, padding='VALID',
- scope='MaxPool_1a_3x3')
- # 输出尺寸8*8*768
- net = tf.concat([branch_0, branch_1, branch_2], 3)
- # 输出图片尺寸被缩小,通道数增加,tensor的总size在持续下降中
- # 输出尺寸8*8*(320+192+768)=8*8*1280
- # 第三个模块组第二个Inception Module 名称是:Mixed_7b
- '''
- 这个模块最大的区别是分支内又有分支,network in network in network
- '''
- with tf.variable_scope('Mixed_7b'): # 4 个分支
- with tf.variable_scope('Branch_0'):
- branch_0 = slim.conv2d(net, 320, [1, 1], scope='Conv2d_0a_1x1')
- # 输出尺寸8*8*320
- with tf.variable_scope('Branch_1'): #第二个分支里还有分支
- branch_1 = slim.conv2d(net, 384, [1, 1], scope='Conv2d_0a_1x1')
- # 输出尺寸8*8*384
- branch_1 = tf.concat([
- slim.conv2d(branch_1, 384, [1, 3], scope='Conv2d_0b_1x3'),
- slim.conv2d(branch_1, 384, [3, 1], scope='Conv2d_0b_3x1')], 3)
- # 输出尺寸8 * 8 * (384+384)=8*8*768
- with tf.variable_scope('Branch_2'): #这个分支更复杂:1*1>3*3>1*3+3*1,总共有三层
- branch_2 = slim.conv2d(net, 448, [1, 1], scope='Conv2d_0a_1x1')
- branch_2 = slim.conv2d(
- branch_2, 384, [3, 3], scope='Conv2d_0b_3x3')
- branch_2 = tf.concat([
- slim.conv2d(branch_2, 384, [1, 3], scope='Conv2d_0c_1x3'),
- slim.conv2d(branch_2, 384, [3, 1], scope='Conv2d_0d_3x1')], 3)
- # 输出尺寸8 * 8 * (384+384)=8*8*768
- with tf.variable_scope('Branch_3'):
- branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
- branch_3 = slim.conv2d(
- branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
- # 输出尺寸8 * 8 * (384+384)=8*8*192
- net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
- # 输出通道数增加到2048 # 输出尺寸8 * 8 * (320+768+768+192)=8*8*2048
- # 第三个模块组第三个Inception Module 名称是:Mixed_7c
- #同前一个一样
- with tf.variable_scope('Mixed_7c'):
- with tf.variable_scope('Branch_0'):
- branch_0 = slim.conv2d(net, 320, [1, 1], scope='Conv2d_0a_1x1')
- with tf.variable_scope('Branch_1'):
- branch_1 = slim.conv2d(net, 384, [1, 1], scope='Conv2d_0a_1x1')
- branch_1 = tf.concat([
- slim.conv2d(branch_1, 384, [1, 3], scope='Conv2d_0b_1x3'),
- slim.conv2d(branch_1, 384, [3, 1], scope='Conv2d_0c_3x1')], 3)
- with tf.variable_scope('Branch_2'):
- branch_2 = slim.conv2d(net, 448, [1, 1], scope='Conv2d_0a_1x1')
- branch_2 = slim.conv2d(
- branch_2, 384, [3, 3], scope='Conv2d_0b_3x3')
- branch_2 = tf.concat([
- slim.conv2d(branch_2, 384, [1, 3], scope='Conv2d_0c_1x3'),
- slim.conv2d(branch_2, 384, [3, 1], scope='Conv2d_0d_3x1')], 3)
- with tf.variable_scope('Branch_3'):
- branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
- branch_3 = slim.conv2d(
- branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
- net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
- # 输出尺寸8 * 8 * (320+768+768+192)=8*8*2048
- return net, end_points
- #Inception V3网络的核心部分,即卷积层部分就完成了
- '''
- 设计inception net的重要原则是图片尺寸不断缩小,inception模块组的目的都是将空间结构简化,同时将空间信息转化为
- 高阶抽象的特征信息,即将空间维度转为通道的维度。降低了计算量。Inception Module是通过组合比较简单的特征
- 抽象(分支1)、比较比较复杂的特征抽象(分支2和分支3)和一个简化结构的池化层(分支4),一共四种不同程度的
- 特征抽象和变换来有选择地保留不同层次的高阶特征,这样最大程度地丰富网络的表达能力。
- '''
- ########全局平均池化、Softmax和Auxiliary Logits(之前6e模块的辅助分类节点)########
- def inception_v3(inputs,
- num_classes=1000, # 最后需要分类的数量(比赛数据集的种类数)
- is_training=True, # 标志是否为训练过程,只有在训练时Batch normalization和Dropout才会启用
- dropout_keep_prob=0.8, # 节点保留比率
- prediction_fn=slim.softmax, # 最后用来分类的函数
- spatial_squeeze=True, # 参数标志是否对输出进行squeeze操作(去除维度数为1的维度,比如5*3*1转为5*3)
- reuse=None, # 是否对网络和Variable进行重复使用
- scope='InceptionV3'): # 包含函数默认参数的环境
- with tf.variable_scope(scope, 'InceptionV3', [inputs, num_classes], # 定义参数默认值
- reuse=reuse) as scope:
- #'InceptionV3'是命名空间
- with slim.arg_scope([slim.batch_norm, slim.dropout], # 定义标志默认值
- is_training=is_training):
- # 拿到最后一层的输出net和重要节点的字典表end_points
- net, end_points = inception_v3_base(inputs, scope=scope) # 用定义好的函数构筑整个网络的卷积部分
- # Auxiliary Head logits作为辅助分类的节点,对分类结果预测有很大帮助,
- # 对end_points的结界做平均池化、卷积最后通过1*1的卷积将通道变为1000
- with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
- stride=1, padding='SAME'): # 将卷积、最大池化、平均池化步长设置为1
- aux_logits = end_points['Mixed_6e'] # 通过end_points取到Mixed_6e
- with tf.variable_scope('AuxLogits'):
- aux_logits = slim.avg_pool2d(
- aux_logits, [5, 5], stride=3, padding='VALID', # 在Mixed_6e之后接平均池化。压缩图像尺寸
- scope='AvgPool_1a_5x5')
- # 输入图像尺寸17*17*768,输出5*5*768
- aux_logits = slim.conv2d(aux_logits, 128, [1, 1], # 卷积。压缩图像尺寸。
- scope='Conv2d_1b_1x1')
- # 输出图像尺寸5*5*128
- # Shape of feature map before the final layer.
- aux_logits = slim.conv2d(
- aux_logits, 768, [5,5],
- weights_initializer=trunc_normal(0.01), # 权重初始化方式重设为标准差为0.01的正态分布
- padding='VALID', scope='Conv2d_2a_5x5')
- # 输出图像尺寸1*1*768
- aux_logits = slim.conv2d(
- aux_logits, num_classes, [1, 1], activation_fn=None,
- normalizer_fn=None, weights_initializer=trunc_normal(0.001),
- scope='Conv2d_2b_1x1')
- # 输出变为1*1*1000,这里的num_classes表示输出通道数,不用激活和标准化,权重重设为0.001的正态分布
- if spatial_squeeze: # tf.squeeze消除tensor中前两个为1的维度。
- aux_logits = tf.squeeze(aux_logits, [1, 2], name='SpatialSqueeze')
- # 这里非常值得注意,tf.squeeze(aux_logits, [1, 2])为什么是[1, 2]而不是[0,1],括号里表示为1的维度
- #因为训练的时候是输入的批次,第一维不是1,[32,1,1,1000].
- end_points['AuxLogits'] = aux_logits
- # 最后将辅助分类节点的输出aux_logits储存到字典表end_points中
- # 处理正常的分类预测逻辑
- # Final pooling and prediction
- # 这一过程的主要步骤:对Mixed_7c的输出进行8*8的全局平均池化>Dropout>1*1*1000的卷积>除去维数为1>softmax分类
- with tf.variable_scope('Logits'):
- net = slim.avg_pool2d(net, [8, 8], padding='VALID',
- scope='AvgPool_1a_8x8')
- #输入为8*8*2048 输出为1 x 1 x 2048
- net = slim.dropout(net, keep_prob=dropout_keep_prob, scope='Dropout_1b')
- end_points['PreLogits'] = net
- # 1*1*2048
- logits = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
- normalizer_fn=None, scope='Conv2d_1c_1x1')
- # 激活函数和规范化函数设为空 # 输出通道数1*1*1000
- if spatial_squeeze: # tf.squeeze去除输出tensor中维度为1的节点
- logits = tf.squeeze(logits, [1, 2], name='SpatialSqueeze')
- end_points['Logits'] = logits
- end_points['Predictions'] = prediction_fn(logits, scope='Predictions')
- # Softmax对结果进行分类预测
- return logits, end_points # 最后返回logits和包含辅助节点的end_points
- #end_points里面有'AuxLogits'、'Logits'、'Predictions'分别是辅助分类的输出,主线的输出以及经过softmax后的预测输出
- '''
- 到这里,前向传播已经写完,对其进行运算性能测试
- '''
- ########评估网络每轮计算时间########
- def time_tensorflow_run(session, target, info_string):
- # Args:
- # session:the TensorFlow session to run the computation under.
- # target:需要评测的运算算子。
- # info_string:测试名称。
- num_steps_burn_in = 10
- # 先定义预热轮数(头几轮跌代有显存加载、cache命中等问题因此可以跳过,只考量10轮迭代之后的计算时间)
- total_duration = 0.0 # 记录总时间
- total_duration_squared = 0.0 # 总时间平方和 -----用来后面计算方差
- #迭代计算时间
- for i in range(num_batches + num_steps_burn_in): # 迭代轮数
- start_time = time.time() # 记录时间
- _ = session.run(target) # 每次迭代通过session.run(target)
- duration = time.time() - start_time
- #每十轮输出一次
- if i >= num_steps_burn_in:
- if not i % 10:
- print ('%s: step %d, duration = %.3f' %
- (datetime.now(), i - num_steps_burn_in, duration))
- total_duration += duration # 累加便于后面计算每轮耗时的均值和标准差
- total_duration_squared += duration * duration
- mn = total_duration / num_batches # 每轮迭代的平均耗时
- vr = total_duration_squared / num_batches - mn * mn
- # 方差,是把一般的方差公式进行化解之后的结果,值得 借鉴
- sd = math.sqrt(vr) # 标准差
- print ('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %
- (datetime.now(), info_string, num_batches, mn, sd))
- #输出的时间是处理一批次的平均时间加减标准差
- # 测试前向传播性能
- batch_size = 32 # 因为网络结构较大依然设置为32,以免GPU显存不够
- height, width = 299, 299 # 图片尺寸
- # 随机生成图片数据作为input
- inputs = tf.random_uniform((batch_size, height, width, 3))
- with slim.arg_scope(inception_v3_arg_scope()):
- # scope中包含了batch normalization默认参数,激活函数和参数初始化方式的默认值
- logits, end_points = inception_v3(inputs, is_training=False)
- # inception_v3中传入inputs获取里logits和end_points
- init = tf.global_variables_initializer() # 初始化全部模型参数
- sess = tf.Session() # 创建session
- sess.run(init)
- num_batches=100 # 测试的batch数量
- time_tensorflow_run(sess, logits, "Forward")
- '''
- 虽然输入图片比VGGNet的224*224大了78%,但是forward速度却比VGGNet更快。
- 这主要归功于其较小的参数量,inception V3参数量比inception V1的700万
- 多了很多,不过仍然不到AlexNet的6000万参数量的一半。相比VGGNet的1.4
- 亿参数量就更少了。整个网络的浮点计算量为50亿次,比inception V1的15亿
- 次大了不少,但是相比VGGNet来说不算大。因此较少的计算量让inception V3
- 网络变得非常实用,可以轻松地移植到普通服务器上提供快速响应服务,甚至
- 移植到手机上进行实时的图像识别。
- '''
- #分析结果:前面的输出是当前时间下每10步的计算时间,最后输出的是当前时间下前向传播的总批次以及平均时间+-标准差
InceptionV3代码解析的更多相关文章
- VBA常用代码解析
031 删除工作表中的空行 如果需要删除工作表中所有的空行,可以使用下面的代码. Sub DelBlankRow() DimrRow As Long DimLRow As Long Dimi As L ...
- [nRF51822] 12、基础实验代码解析大全 · 实验19 - PWM
一.PWM概述: PWM(Pulse Width Modulation):脉冲宽度调制技术,通过对一系列脉冲的宽度进行调制,来等效地获得所需要波形. PWM 的几个基本概念: 1) 占空比:占空比是指 ...
- [nRF51822] 11、基础实验代码解析大全 · 实验16 - 内部FLASH读写
一.实验内容: 通过串口发送单个字符到NRF51822,NRF51822 接收到字符后将其写入到FLASH 的最后一页,之后将其读出并通过串口打印出数据. 二.nRF51822芯片内部flash知识 ...
- [nRF51822] 10、基础实验代码解析大全 · 实验15 - RTC
一.实验内容: 配置NRF51822 的RTC0 的TICK 频率为8Hz,COMPARE0 匹配事件触发周期为3 秒,并使能了TICK 和COMPARE0 中断. TICK 中断中驱动指示灯D1 翻 ...
- [nRF51822] 9、基础实验代码解析大全 · 实验12 - ADC
一.本实验ADC 配置 分辨率:10 位. 输入通道:5,即使用输入通道AIN5 检测电位器的电压. ADC 基准电压:1.2V. 二.NRF51822 ADC 管脚分布 NRF51822 的ADC ...
- java集合框架之java HashMap代码解析
java集合框架之java HashMap代码解析 文章Java集合框架综述后,具体集合类的代码,首先以既熟悉又陌生的HashMap开始. 源自http://www.codeceo.com/arti ...
- Kakfa揭秘 Day8 DirectKafkaStream代码解析
Kakfa揭秘 Day8 DirectKafkaStream代码解析 今天让我们进入SparkStreaming,看一下其中重要的Kafka模块DirectStream的具体实现. 构造Stream ...
- linux内存管理--slab及其代码解析
Linux内核使用了源自于 Solaris 的一种方法,但是这种方法在嵌入式系统中已经使用了很长时间了,它是将内存作为对象按照大小进行分配,被称为slab高速缓存. 内存管理的目标是提供一种方法,为实 ...
- MYSQL常见出错mysql_errno()代码解析
如题,今天遇到怎么一个问题, 在理论上代码是不会有问题的,但是还是报了如上的错误,把sql打印出來放到DB中却可以正常执行.真是郁闷,在百度里面 渡 了很久没有相关的解释,到时找到几个没有人回复的 & ...
随机推荐
- elasticsearch+filebeat+kibana提取多行日志
filebeat的配置文件filebeat.yml以下三行去掉注释 multiline.pattern: ^\[ multiline.negate: true //false改为true multil ...
- 在select标签中添加a标签
<!--第一个选项不能写连接--> <select id="" onchange="window.location=this.value"&g ...
- vs 利用web deploy发布 常见问题解决
1. 下载并安装 web deploy, 安装时选择自定义,选择全部安装 https://www.iis.net/downloads/microsoft/web-deploy 2. 确保iis的管理 ...
- System.Math.cs
ylbtech-System.Math.cs 1. 程序集 mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c56193 ...
- System.Web.Mvc.IActionFilter.cs
ylbtech-System.Web.Mvc.IActionFilter.cs 1.程序集 System.Web.Mvc, Version=5.2.3.0, Culture=neutral, Publ ...
- Docker系列(八):Kubernetes横空出世背后的秘密
Docker与CoreOS的恩怨情仇 2013年2月,Docker建立了一个网站发布它的首个演示版本, 3月,美国加州Alex Polvi正在自己的车库开始 他的 第二次创业 有了第一桶金的Alex这 ...
- hibernate annotation 之 注解声明
@Entity 将一个 POJO 类注解成一个实体 bean ( 持久化 POJO 类 ) @Table 为实体 bean 映射指定具体的表,如果该注解没有被声明,系统将使用默认值 ( 即实体 bea ...
- JS之缓冲动画
原素材 main.html <!DOCTYPE html> <html lang="en"> <head> <link href=&quo ...
- HYNB Round 15: PKU Campus 2019
HYNB Round 15: PKU Campus 2019 C. Parade 题意 将平面上n*2个点安排在长度为n的两行上. 做法 首先可以忽略每个点之间的影响,只用考虑匹配即可 然后把所以点归 ...
- UASCO Cow Pedigrees /// oj10140
题目大意: 输入n,m :二叉树 输出 n个点分为m层 的方案数: 每个点的分支要么是0要么是2 Sample Input 5 3 Sample Output 2 即 两个方案为 O ...