Docker 下部署hadoop集群
一、主机规划
3台主机:1个master、2个slaver/worker
ip地址使用docker默认的分配地址:
master:
主机名: hadoop2、ip地址: 172.17.0.2
slaver1:
主机名: hadoop3、ip地址: 172.17.0.3
主机名: hadoop4、ip地址: 172.17.0.4
二、软件安装
1、在docker中安装centos镜像,并启动centos容器,安装ssh。--详见"docker上安装centos镜像"一文。
2、通过ssh连接到centos容器,安装jdk1.8、hadoop3.0
可以按照传统linux安装软件的方法,通过将jdk和hadoop的tar包上传到主机进行安装。
获取centos7镜像
$ docker pull centos
大概是70多M,使用阿里云等Docker加速器的话很快就能下载完,之后在镜像列表中就可以看到
查看镜像列表的命令:
$ docker images
安装SSH
以centos7镜像为基础,构建一个带有SSH功能的centos
$ vi Dockerfile
内容:
FROM centos
MAINTAINER weiliangleo@126.com RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
RUN yum install -y openssh-clients RUN echo "root:abc123" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key RUN mkdir /var/run/sshd
EXPOSE
CMD ["/usr/sbin/sshd", "-D"]
这段内容的大意是:以 centos 镜像为基础,安装SSH的相关包,设置了root用户的密码为 abc123,并启动SSH服务
执行构建镜像的命令,新镜像命名为 centos7-ssh
$ docker build -t centos7-ssh .
执行完成后,可以在镜像列表中看到
$ docker images
构建Hadoop镜像
上面是运行了3个centos容器,需要在每个容器中单独安装Hadoop环境,我们可以像构建SSH镜像一样,构建一个Hadoop镜像,然后运行3个Hadoop容器,这样就更简单了
$ vi Dockerfile
内容:
FROM centos7-ssh
ADD jdk-8u151-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1..0_151 /usr/local/jdk1.
ENV JAVA_HOME /usr/local/jdk1.
ENV PATH $JAVA_HOME/bin:$PATH ADD hadoop-3.1..tar.gz /usr/local
RUN mv /usr/local/hadoop-3.1. /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH RUN yum install -y which sudo
这里是基于 centos7-ssh 这个镜像,把 JAVA 和 Hadoop 的环境都配置好了
前提:在Dockerfile所在目录下准备好 jdk-8u101-linux-x64.tar.gz 与 hadoop-2.7.3.tar.gz
执行构建命令,新镜像命名为 hadoop
$ docker build -t hadoop .
在/etc/hosts文件中添加3台主机的主机名和ip地址对应信息
172.17.0.2 hadoop2
172.17.0.3 hadoop3
172.17.0.4 hadoop4
在docker中直接修改/etc/hosts文件,在重启容器后会被重置、覆盖。因此需要通过容器启动脚本docker run的--add-host参数将主机和ip地址的对应关系传入,容器在启动后会写入hosts文件中。如:
docker run --name hadoop2--add-host hadoop2:172.17.0.2 --add-host hadoop3:172.17.0.3 --add-host hadoop4:172.17.0.4 hadoop
docker exec -it hadoop2 bash
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod ~/.ssh/authorized_keys
hadoop部署
1.在workers文件中定义工作节点
在hadoop根目录下的etc/hadoop目录下新建workers文件,并添加工作节点主机信息。
按照步骤一中的主机规划,工作节点主机为hadoop3和hadoop4两台主机。如:
[root@9e4ede92e7db ~]# cat /usr/local/hadoop/etc/hadoop/workers
hadoop3
hadoop4
2、修改配置文件信息
a、在hadoop-env.sh中,添加JAVA_HOME信息
[root@9e4ede92e7db ~]# cat /usr/local/hadoop/etc/hadoop/hadoop-env.sh |grep JAVA_HOME
# JAVA_HOME=/usr/java/testing hdfs dfs -ls
# Technically, the only required environment variable is JAVA_HOME.
# export JAVA_HOME=
JAVA_HOME=/usr/local/jdk1.
b、core-site.xml
configuration><property>
<name>fs.default.name</name>
<value>hdfs://hadoop2:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value></value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
c、hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:</value>
<description># 通过web界面来查看HDFS状态 </description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value></value>
<description># 每个Block有2个备份</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
d、yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop2:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop2:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop2:</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop2:</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop2:</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value></value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value></value>
</property>
</configuration>
e、mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop2:</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop2:</value>
</property>
</configuration>
f、为防止进坑提前做好准备
vi start-dfs.sh vi stop-dfs.sh
HDFS_DATANODE_USER=root
#HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
vi start-yarn.sh vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
注意:
以上步骤完成以后停止当前容器,并使用docker命令保持到一个新的镜像。使用新的镜像重新启动集群,这样集群每台机器都有相同的账户、配置和软件,无需再重新配置。如:
a、停止容器
docker stop hadoop2
b、保存镜像
docker commit hadoop2 hadoop_me:v1.
测试
1、端口映射
集群启动后,需要通过web界面观察集群的运行情况,因此需要将容器的端口映射到宿主主机的端口上,可以通过docker run命令的-p选项完成。比如:
将yarn任务调度端口映射到宿主主机8088端口上:
docker run -it -p : hadoop_me:v1.
2、从新镜像启动3个容器
docker run --name hadoop2 --add-host hadoop2:172.17.0.2 --add-host hadoop3:172.17.0.3 --add-host hadoop4:172.17.0.4 -d -p : -p : -p : -p : hadoop_me:v1. docker run --name hadoop3 --add-host hadoop2:172.17.0.2 --add-host hadoop3:172.17.0.3 --add-host hadoop4:172.17.0.4 -d -p : hadoop_me:v1. docker run --name hadoop4 --add-host hadoop2:172.17.0.2 --add-host hadoop3:172.17.0.3 --add-host hadoop4:172.17.0.4 -d -p : hadoop_me:v1.
3.格式化
进入到/usr/local/hadoop目录下
执行格式化命令
bin/hdfs namenode -format
修改hadoop2中hadoop的一个配置文件etc/hadoop/slaves
删除原来的所有内容,修改为如下
hadoop3
hadoop4
在hadoop2中执行命令
scp -rq /usr/local/hadoop hadoop3:/usr/local
scp -rq /usr/local/hadoop hadoop4:/usr/local
4.在master主机上执行start-all.sh脚本启动集群 在hadoop上 /usr/local/hadoop 目录下执行:sbin/start-all.sh
5.通过web页面访问
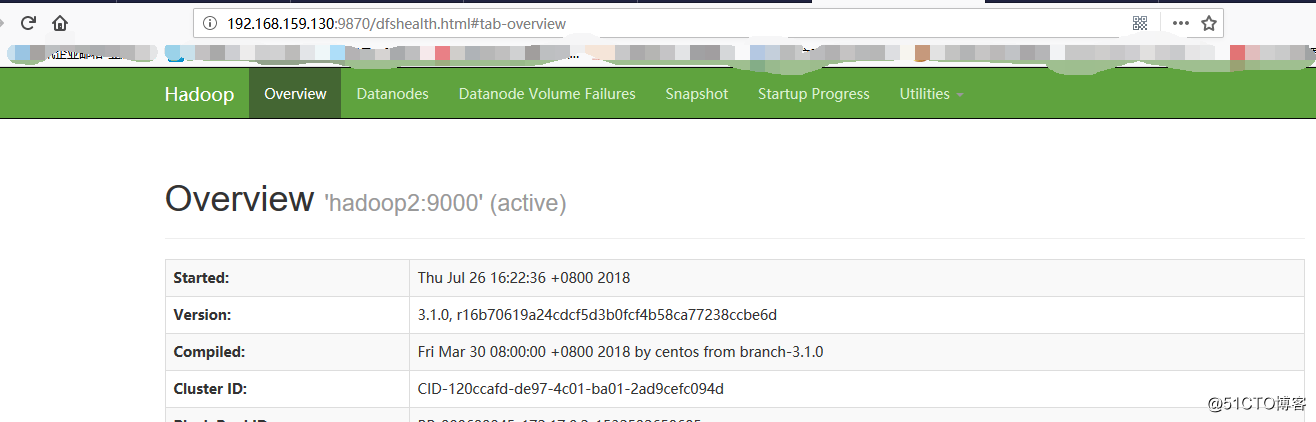
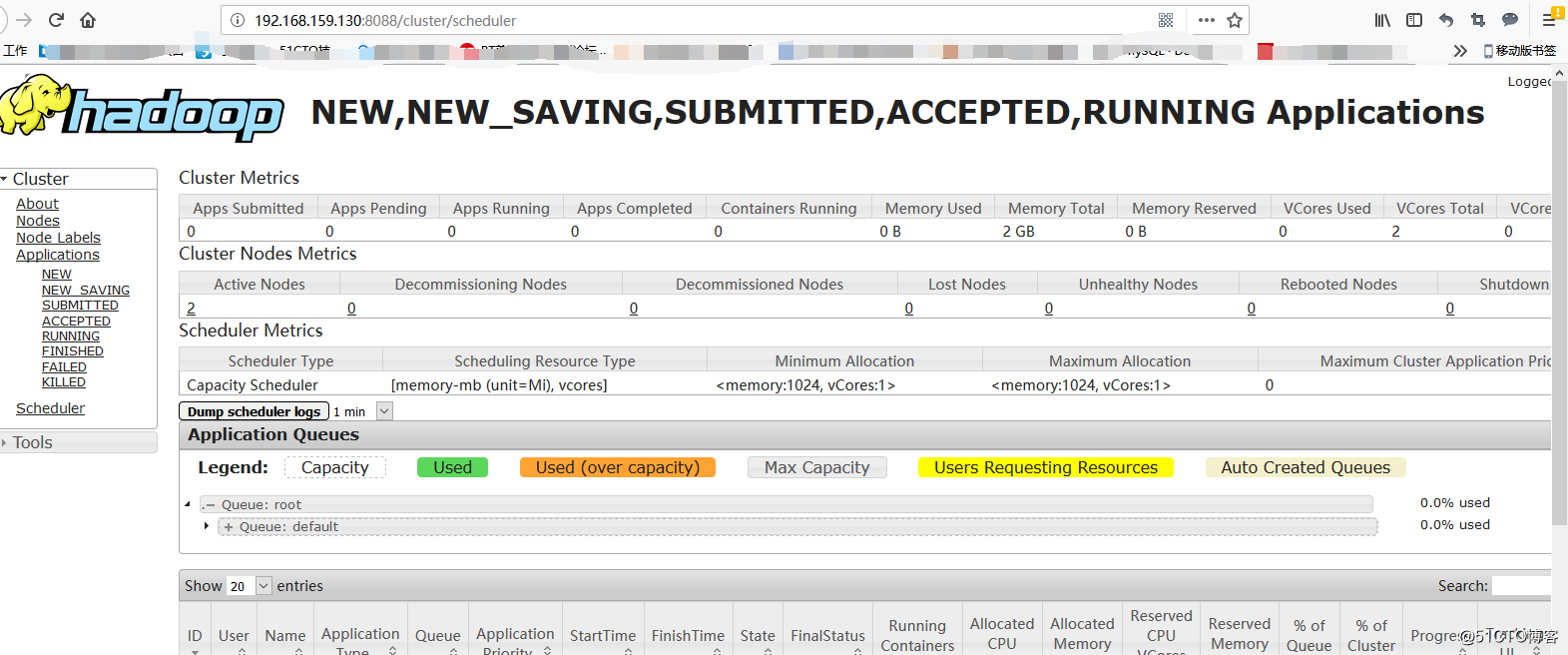

Docker 下部署hadoop集群的更多相关文章
- docker下部署kafka集群(多个broker+多个zookeeper)
网上关于kafka集群的搭建,基本是单个broker和单个zookeeper,测试研究的意义不大.于是折腾了下,终于把正宗的Kafka集群搭建出来了,在折腾中遇到了很多坑,后续有时间再专门整理份搭建问 ...
- Docker部署Hadoop集群
Docker部署Hadoop集群 2016-09-27 杜亦舒 前几天写了文章"Hadoop 集群搭建"之后,一个朋友留言说希望介绍下如何使用Docker部署,这个建议很好,Doc ...
- 使用docker部署hadoop集群
最近要在公司里搭建一个hadoop测试集群,于是采用docker来快速部署hadoop集群. 0. 写在前面 网上也已经有很多教程了,但是其中都有不少坑,在此记录一下自己安装的过程. 目标:使用doc ...
- Docker 容器部署 Consul 集群
Docker 容器部署 Consul 集群 一.docker安装与启动1.1安装docker[root@localhost /]# yum -y install docker-io 1.2更改配置文件 ...
- 使用docker安装部署Spark集群来训练CNN(含Python实例)
使用docker安装部署Spark集群来训练CNN(含Python实例) http://blog.csdn.net/cyh_24/article/details/49683221 实验室有4台神服务器 ...
- 如何部署hadoop集群
假设我们有三台服务器,他们的角色我们做如下划分: 10.96.21.120 master 10.96.21.119 slave1 10.96.21.121 slave2 接下来我们按照这个配置来部署h ...
- 批量部署Hadoop集群环境(1)
批量部署Hadoop集群环境(1) 1. 项目简介: 前言:云火的一塌糊涂,加上自大二就跟随一位教授做大数据项目,所以很早就产生了兴趣,随着知识的积累,虚拟机已经不能满足了,这次在服务器上以生产环境来 ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
随机推荐
- 函数调用约定_stdcall[转]
关键字 清理堆栈 参数入栈顺序 函数名称修饰(C) __cdecl 调用函数 右 à 左 _函数名 __stdcall 被调用函数 右 à 左 _函数名@数字 __fastcall 被调用函数 右 à ...
- Netty源码分析之ChannelPipeline—入站事件的传播
之前的文章中我们说过ChannelPipeline作为Netty中的数据管道,负责传递Channel中消息的事件传播,事件的传播分为入站和出站两个方向,分别通知ChannelInboundHandle ...
- Sophus库CMakeLists.txt内容详解笔记
CMakeLists.txt: SET(PROJECT_NAME Sophus) PROJECT(${PROJECT_NAME}) CMAKE_MINIMUM_REQUIRED(VERSION 2.6 ...
- CSS selector? [class*=“span”]怎么理解
我在Twitter 中有看到如下selector: .show-grid [class*="span"] { background-color: #eee; text-align: ...
- [python-docx]docx文档操作的库
from docx import Document from docx.shared import Inches # 新建document对象 document = Document() # 添加段落 ...
- 前端:CSS第四章第一节
块级元素一行只有一个,比如P标签 CSS层叠样式表,意思就是样式是可以叠加的,比如下面的代码 <style> .ok{ color: aqua; } .blue{ color: #5283 ...
- 转AngularJS路由插件
AngularJS学习笔记--002--Angular JS路由插件ui.router源码解析 标签: angular源码angularjs 2016-05-04 13:14 916人阅读 评论(0) ...
- C语言寒假大作战04
问题 答案 这个作业属于那个课程 https://edu.cnblogs.c0m/campus/zswxy/CST2019-4 这个作业的要求在哪里 https://edu.cnblogs.com/c ...
- comm diff 文件对比
comm: 利用comm命令进行处理的文件必须首先通过sort命令进行排序处理并且是unix格式而非dos格式的文本文件 功能说明:比较两个已排过序的文件.(使用sort排序)语 法:comm [-1 ...
- codewars--js--Pete, the baker
问题描述: Pete likes to bake some cakes. He has some recipes and ingredients. Unfortunately he is not go ...