kafka(一)-为什么选择kafka
作为开发人员,我们在选择一个框架或者工具时,我们都需要考虑些什么,我们不是头脑发热,一拍脑袋就它了,我们首先要认清这个框架或工具的作用是什么,能给我们带来什么样的好处,同时也要考虑带来什么样的负面结果,我们在使用时才能更好的扬其长避其短,kafka大家可能都不陌生,到底我们为什么选择kafka呢?
1.首先kafka是一个消息队列,作为消息队列一般会在很多场景中用到,如:
应用解耦
在系统交互时,有时我们很难一次性就设计出非常完善的接口,可能会随着业务发展,这些交互接口也会不断的变迁,如果我们的系统较多,系统间交互也较多,维护起来可能就是噩梦,这是可能就需要考虑引入一种基于数据的接口层(消息队列),这样各个系统可以独立的扩展或修改自己的处理过程,只要保证他们准守实现设计的数据格式约束。解耦的同时也提高了系统的稳定性(某个组件失效不会影响其他部分正常运行)和扩展性(可以横向扩展系统以增加处理消息的能力)。
异步处理
有时候我们的业务逻辑可能涉及到很多步骤,而且这些步骤可能上下关联性不是很强,如果我们串行执行时,总耗时=每个步骤耗时之和,如果我们让每个步骤并行处理,总耗时< 每个步骤耗时之和,在这里我们就可以引入消息队列,将每个处理步骤发送到消息队列,并且针对每个处理步骤都有对应的线程去监听,这样就能达到串行执行异步化转为并行执行,从而提高系统的的吞吐量。
流量削峰
在秒杀或抢购活动中,一般会因为流量暴增,应用因处理不过来而挂掉,此时一般会引入消息队列,这样流量会先进入消息队列,我们的应用再根据自己的实际处理能力来消费这些消息,从而达到缓解流量暴增对系统构成的压力
日志处理
有时我们需要采集日志,系统运行中会产生大量的日志,尤其是在流量高峰时,而这项日志需要存储在其他地方,一般进行其他的计算或处理,日志在写入磁盘此时,由于磁盘IO速度可能不是很快,会对系统造成压力,这时我们就可以引入比较高性能的消息队列(kafka往往会被用到),消息队列可以起到缓冲作用。
消息通信
消息队列一般都内置了高效的通信机制,有点对点通信,也有发布订阅式通信,因此也可以用在纯的消息通讯。
冗余存储
消息队列一般会把消息存储起来,只有消费完成后,才把消息删除,这样就防止了某些时候因为处理异常,而导致消息丢失的问题
2.在众多的消息中间件中,为什么选择kafka
主要特性
- 快速持久化:可以在O(1)的系统开销下进行消息持久化;
- 高吞吐:在一台普通的服务器上既可以达到10W/s的吞吐速率;
- 完全的分布式系统:Broker、Producer和Consumer都原生自动支持分布式,自动实现负载均衡;
- 支持同步和异步复制两种高可用机制;
- 支持数据批量发送和拉取;
- 零拷贝技术(zero-copy):减少IO操作步骤,提高系统吞吐量;
- 数据迁移、扩容对用户透明;
- 无需停机即可扩展机器;
- 其他特性:丰富的消息拉取模型、高效订阅者水平扩展、实时的消息订阅、亿级的消息堆积能力、定期删除机制;
优点
- 客户端语言丰富:支持Java、.Net、PHP、Ruby、Python、Go等多种语言;
- 高性能:单机写入TPS约在100万条/秒,消息大小10个字节;
- 提供完全分布式架构,并有replica机制,拥有较高的可用性和可靠性,理论上支持消息无限堆积;
- 支持批量操作;
- 消费者采用Pull方式获取消息。消息有序,通过控制能够保证所有消息被消费且仅被消费一次;
- 有优秀的第三方KafkaWeb管理界面Kafka-Manager;
- 在日志领域比较成熟,被多家公司和多个开源项目使用。
缺点
- Kafka单机超过64个队列/分区时,Load时会发生明显的飙高现象。队列越多,负载越高,发送消息响应时间变长;
- 使用短轮询方式,实时性取决于轮询间隔时间;
- 消费失败不支持重试;
- 支持消息顺序,但是一台代理宕机后,就会产生消息乱序;
- 社区更新较慢。
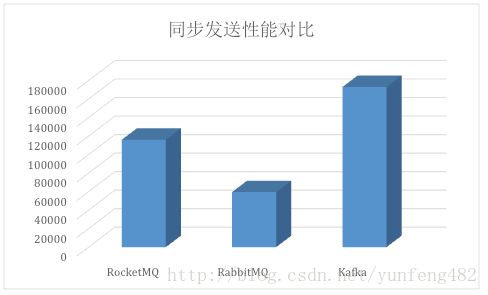
附和其他MQ速度对比:
kafka(一)-为什么选择kafka的更多相关文章
- 【Kafka】《Kafka权威指南》入门
发布与订阅消息系统 在正式讨论Apache Kafka (以下简称Kafka)之前,先来了解发布与订阅消息系统的概念, 并认识这个系统的重要性.数据(消息)的发送者(发布者)不会直接把消息发送给接收 ...
- [Kafka][1][初识Kafka]
目录 第1章 初识Kafka 1.1 发布与订阅消息系统 1.1.1 如何开始 1.1.2 独立的队列系统 1.2 Kafka登场 1.2.1 消息和批次(Message and batch) 1.2 ...
- kafka学习(三)-kafka集群搭建
kafka集群搭建 下面简单的介绍一下kafka的集群搭建,单个kafka的安装更简单,下面以集群搭建为例子. 我们设置并部署有三个节点的 kafka 集合体,必须在每个节点上遵循下面的步骤来启动 k ...
- Kafka系列之-Kafka入门
接下来的这些博客,主要内容来自<Learning Apache Kafka Second Edition>这本书,书不厚,200多页.接下来摘录出本书中的重要知识点,偶尔参考一些网络资料, ...
- Kafka Ecosystem(Kafka生态)
http://kafka.apache.org/documentation/#ecosystem https://cwiki.apache.org/confluence/display/KAFKA/E ...
- Kafka监控系统Kafka Eagle:支持kerberos认证
在线文档:https://ke.smartloli.org/ 作者博客:https://www.cnblogs.com/smartloli/p/9371904.html 源码地址:https://gi ...
- Kafka监控系统Kafka Eagle剖析
1.概述 最近有同学留言反馈了使用Kafka监控工具Kafka Eagle的一些问题,这里笔者特意整理了这些问题.并且希望通过这篇博客来解答这些同学的在使用Kafka Eagle的时候遇到的一些困惑, ...
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- Structured Streaming + Kafka Integration Guide 结构化流+Kafka集成指南 (Kafka broker version 0.10.0 or higher)
用于Kafka 0.10的结构化流集成从Kafka读取数据并将数据写入到Kafka. 1. Linking 对于使用SBT/Maven项目定义的Scala/Java应用程序,用以下工件artifact ...
随机推荐
- Linux 基础(一)stat函数
Header file: #include <sys/types.h> #include <sys/stat.h> #include <unistd.h> DEFI ...
- Recall(召回率);Precision(准确率);F1-Meature(综合评价指标);true positives;false positives;false negatives..
转自:http://blog.csdn.net/t710smgtwoshima/article/details/8215037 Recall(召回率);Precision(准确率);F1-Meat ...
- VS code 汉化及快捷键修改
VsCode汉化方式 Vscode是一款开源的跨平台编辑器.默认情况下,vscode使用的语言为英文(us),如何将其显示语言修改成中文了? 打开vscode工具: 点击左侧的Extensions(拓 ...
- layui图片上传之后后台如何修改图片的后缀名以及返回数据给前台
const pathLib = require('path');//引入node.js下的一个path模块的方法,主要处理文件的名字等工作,具体可看文档 const fs = require(''fs ...
- json文件生成
// import Translate from 'translate-components' /* * 匹配所有汉字RegExp: [\u4e00-\u9fa5] [\u4E00-\u9FA5]|[ ...
- 数据预处理以及探索性分析(EDA)
1.根据某个列进行groupby,判断是否存在重复列. # Count the unique variables (if we got different weight values, # for e ...
- 006.MFC_对话框_复选框_单选钮
对话框和控件复选框单选框分组框示例:三原色画图 一.建立名为Demo2的MFC工程,按照下图添加控件 并修改2个Group Box Caption属性分别为颜色.外观 修改3个Check Box Ca ...
- HBase的TTL介绍
1. 定义 TTL(Time to Live) 用于限定数据的超时时间. 2.原理 以Column Family的TTL为例介绍, hbase(main):001:0> desc 'wxy:te ...
- easyUI dataGrid主从表点击展开问题
昨天在公司写代码遇到了一个问题,就是在用easyUI做主从表的时候在查询之后点击展开的时候不能再次展开了.先说一下主从表我也是第一次用 效果如下图: 然后点击前面的小加号出现以下效果: 然而遇到了一个 ...
- appium+ios+macaca自动化测试环境部署
环境准备(供参考) mac v10.14.4 xcode v10.2 python v3.6 确保上述环境已满足,即可开始搭建appium+ios测试环境 1 jdk安装 下载mac版本的jdk并安装 ...