DataTable数据检索的性能分析(转寒江独钓)
我们知道在.NET平台上有很多种数据存储,检索解决方案-ADO.NET Entity Framework,ASP.NET Dynamic Data,XML, NHibernate,LINQ to SQL 等等,但是由于一些原因,如平台限制,比如说必须基于.NET Framework2.0及以下平台;遗留的或者第三方数据接口采用的就是DataTable等等,仍然需要使用DataTable作为数据存储结构。另一方面DataTable比较容易使用,一些数据访问的接口可能直接采用了DataTable结构。在使用DataTable进行数据检索的时候,有一些需要注意的地方,这些地方会严重的影响对数据的检索效率。
本人最近工作中需要对大量的DataTable进行拼接。接口的数据是以DataSet然后里面放DataTable的方式提供的,暂不提是否合理,同时进行多个请求的时,服务端会返回一个DataSet,其中包含每个请求的结果DataTable,这些DataTable中有一列相当于”关键字”列。现在需要按照这个关键字,将这些DataTable中的列合并到一个DataTable,然后展现到界面上来。
最开始,我使用的是DataTable的Select方法来循环遍历拼接实现的,发现很慢,于是总结了一下对DataTable进行查询等操作的一些经验,和大家分享。
一 场景
为了简化问题,有两张DataTable,名为表A,表B,字段分别为
表A,存储股票的最高价信息, 表B存储股票最低价信息
SecurityCode High SecurityCode Low
000001.SZ 20 000001.SZ 18.5
000002.SZ 26 000002.SZ 56
现在需要,将这两张表拼接到一张表中,这张表有三列字段,SecurityCode High Low,之前采用的方法是,新建一张含有这三个字段的DataTable 表C,然后复制Security字段,然后遍历另外两张表,对其采用Select方法查找对应的SecurityCode,然后复制给C中对应字段。发现效率很慢,问题出现在Select方法上,于是需要进行优化。
二 DataTable的查询效率
DataTable提供了两个查询数据的接口,DataTable.Select和DataTable.Rows.Find方法。
DataTable的Select方法通过传入一系列条件,然后返回一个DataRow[ ]类型的数据,他需要遍历整个表,然后挨个匹配条件,然后返回所有匹配的值。很显然在策略上,之前的DataTable拼接采用Select方法存在问题,因为我们只需要查找匹配上的一条记录即可。
DataTable.Rows 的Find查找第一个匹配上的唯一一条记录。在指定了主键的基础上,查找会采用二叉树的方式查找,效率高。要创建主键,需要指定DataTable的PrimaryKey字段如下:
dtA.PrimaryKey = new DataColumn[] { dtA.Columns["SecurityCode"] };
当然,创建主键会增加时间消耗,这也分为在数据填充前创建和数据填充后创建。在数据量大的情况下,创建主键的消耗是需要考虑进去的。下面的图中显示了在填充数据之前创建主键,之后创建主键,以及创建Dictionary所需的时间。可以看到:
|
ArraySize |
PreIndex Creation Time |
PostIndex Creation Time |
Dictionary Creation Time |
|
10 |
0 |
0 |
0 |
|
50 |
0 |
0 |
0 |
|
100 |
1 |
0 |
0 |
|
500 |
6 |
1 |
0 |
|
1000 |
15 |
2 |
0 |
|
5000 |
107 |
16 |
2 |
|
10000 |
261 |
42 |
5 |
|
50000 |
1727 |
271 |
31 |
|
100000 |
3525 |
544 |
47 |
|
500000 |
20209 |
2895 |
240 |
|
1000000 |
43382 |
5919 |
517 |
作图如下:
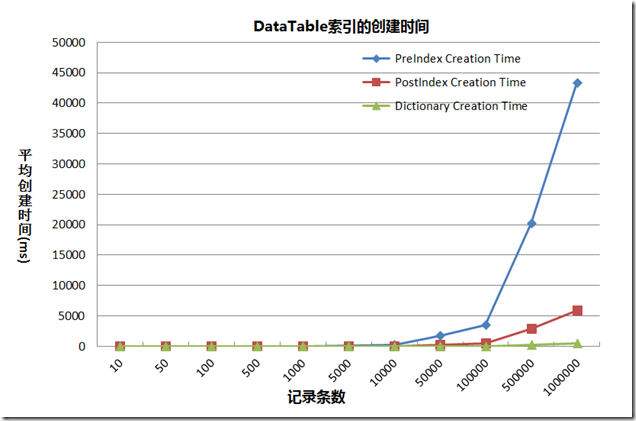
从上图可以得到:
- 在填充数据之前创建主键,然后填充数据,比填充数据完之后创建主键消耗的时间要多。这是由于,创建主键后,再向其中添加数据,会导致需要重新生成索引,这和数据库中,不适合在频繁变动的字段上创建主键的原理是一样的。在我的笔记本 (Win7 32bit,CPU T6600 2.0GHZ,RAM 2GB)上,为100万条记录的DataTable创建索引大约需要5秒钟,所以在数据量大的情况下,需要考虑索引的创建时间。
- 创建DataTable然后创建主键与直接创建和该DataTable相同的Dictionary结构相比,创建Dictionary所需要的时间要少的多,而且几乎不随着记录条数规模的变大而变大。
创建完成之后,下面来测试几种情况下的DataTable的检索效率。为此,在建立主键和没有建立索引的条件下,测试了在不同规模下 DataTable.Select, DataTable.Rows.Find 的查询速度,由于在DataTable比较小的时候,时间不能很好的显示,所以测试采用的单位是StopWatch的Tick数。每个方法在数据规模不同的情况下,各执行了10次,然后取平均值,结果如下:
| ArraySize | Dictionary Create | Dictionary Search | Table Select | Indexed Table Select | Table Rows Find | LINQ |
| 10 | 13 | 3 | 40 | 25 | 8 | 16 |
| 50 | 27 | 2 | 69 | 37 | 8 | 27 |
| 100 | 51 | 3 | 112 | 38 | 9 | 39 |
| 500 | 210 | 3 | 589 | 51 | 11 | 155 |
| 1000 | 461 | 4 | 1175 | 60 | 14 | 328 |
| 5000 | 2264 | 14 | 8412 | 85 | 17 | 1540 |
| 10000 | 6235 | 7 | 16806 | 99 | 20 | 3354 |
| 50000 | 23768 | 8 | 150133 | 138 | 26 | 15824 |
| 100000 | 49133 | 7 | 259794 | 147 | 26 | 31525 |
| 500000 | 252103 | 51 | 1547935 | 181 | 30 | 158317 |
| 1000000 | 494647 | 9 | 2736616 | 209 | 30 | 315716 |
作图如下:
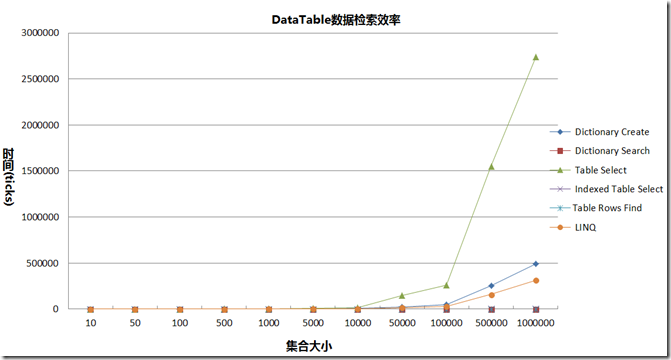
可以看到:
- 在没有创建主键的条件下,对DataTable执行Select操作时比较低效的。在建立主键之后,仅对主键所在列执行Select操作,速度提高了很多,这种差距在数据量大的情况下尤其明显,在集合大小规模为1000时,该差异达到了近20倍。
- LINQ对DataTable的查询效率比DataTale.Select方法要高,但是仍然比DataTable.Rows.Find方法效率要低。
- 在对主键进行唯一性查找时,我们应该使用DataTable.Rows.Find操作,在DataTable建立主键,并且仅对主键进行操作的情况下,Find方法会比Select方法快3-6倍,这可能是由于Select方法需要对里面的过滤字符串进行解析及判断。因为Select方法可以接受多个条件的查询以及以一些比较复杂的表达式,处理及解析可能需要耗费一些时间。并且在一般条件下Select是完全搜索,即查找整个集合找到所有满足条件的记录。而Find方法则仅对主键字段进行检索,如果没有设置主键,那么调用Find方法就会报错。
- 采用Dictionary来代替DataTable结构来进行检索,能达到最快的速度,且几乎不受规模的影响,但是在数据量较大的情况下,将DataTable转换为对应的Dictionary结构可能需要花费时间,如果操作频繁,诸如在进行多个DataTable基于关键字进行拼接的情况下,对目标DataTable使用Dictionary<String,DataRow> 的方式进行存储,能够使用ContainsKey的基于Hash的方式对关键字进行查找,这能极大地提高效率。并且在DataTable列有重复字段,不能建立主键的情况下,可以采用Dictionary<string,List<DataRow>>能够解决DataTable无法创建主键,从而导致查找性能下降的问题。
三 实施效果
基于上面的分析,在实际中的工作中,替换了Select方法,创建了一个类型为Dictionary<String,DataRow>的包含目标合并后DataTable对象的所有行的结构C,其中关键字为SecurityCode,DataRow为包含SecurityCode,High,Low三列数据的行。在合并的时候,直接遍历表A的所有行,然后判断在C中是否包含该行中的SecurityCode,如果包含,取出,直接赋值。然后遍历表B。整个过程使得DataTable合并的效率至少提高了10倍。
四 结语
本文简要介绍了DataTable中检索数据的两种方法,DataTable.Select 和DataTable.Rows.Find方法。在测试方法的执行效率之前介绍了如何为DataTable设置主键,并比较了在数据填充之前和数据填充之后设置主键花费的时间,结果表明,在数据填充完成之后,设置主键要比在填充数据之前设置主键效率要高的多。设置主键之后,比较了在有无主键的情况下,DataTable.Select 方法在仅对主键字段进行过滤时的性能,结果表明,在仅对主键进行检索时,设置主键之后使用DataTable.Select 方法会比没有主键的情况下的检索速度会快非常多。在相同条件下,如果仅需要查找某一条记录,使用DataTable.Rows.Find会比DataTable.Select快很多。在某些需要频繁操作DataTable查询的时候,要避免在循环体内调用DataTable.Select方法,采用将DataTable转换为等价的Dictionary结构,能够有效解决由于键值重复导致不能创建主键的问题,并且Dicitonary的采用哈希表的方式查找能够极大地提高查询效率。
点击此处下载本文测试用例及代码,希望对您在对DataTable进行检索操作时,如何提高效率能够带来一点儿帮助。
注:个人认为若DataTable设值主键且仅查找主键,使用后设置主键方式比Dictionary速度要快。
DataTable数据检索的性能分析(转寒江独钓)的更多相关文章
- DataTable数据检索的性能分析[转]
原文链接 作者写得非常好,我学到了许多东西,这里只是转载! 我们知道在.NET平台上有很多种数据存储,检索解决方案-ADO.NET Entity Framework,ASP.NET Dynamic D ...
- KTHREAD 线程调度 SDT TEB SEH shellcode中DLL模块机制动态获取 《寒江独钓》内核学习笔记(5)
目录 . 相关阅读材料 . <加密与解密3> . [经典文章翻译]A_Crash_Course_on_the_Depths_of_Win32_Structured_Exception_Ha ...
- ETHREAD APC 《寒江独钓》内核学习笔记(4)
继续学习windows 中和线程有关系的数据结构: ETHREAD.KTHREAD.TEB 1. 相关阅读材料 <windows 内核原理与实现> --- 潘爱民 2. 数据结构分析 我们 ...
- EPROCESS 进程/线程优先级 句柄表 GDT LDT 页表 《寒江独钓》内核学习笔记(2)
在学习笔记(1)中,我们学习了IRP的数据结构的相关知识,接下来我们继续来学习内核中很重要的另一批数据结构: EPROCESS/KPROCESS/PEB.把它们放到一起是因为这三个数据结构及其外延和w ...
- IRP IO_STACK_LOCATION 《寒江独钓》内核学习笔记(1)
在学习内核过滤驱动的过程中,遇到了大量的涉及IRP操作的代码,这里有必要对IRP的数据结构和与之相关的API函数做一下笔记. 1. 相关阅读资料 <深入解析 windows 操作系统(第4版,中 ...
- 《寒江独钓_Windows内核安全编程》中修改类驱动分发函数
最近在阅读<寒江独钓_Windows内核安全编程>一书的过程中,发现修改类驱动分发函数这一技术点,书中只给出了具体思路和部分代码,没有完整的例子. 按照作者的思路和代码,将例子补充完整,发 ...
- KPROCESS IDT PEB Ldr 《寒江独钓》内核学习笔记(3)
继续上一篇(2)未完成的研究,我们接下来学习 KPROCESS这个数据结构. 1. 相关阅读材料 <深入理解计算机系统(原书第2版)> 二. KPROCESS KPROCESS,也叫内核进 ...
- SQL查询性能分析
http://blog.csdn.net/dba_huangzj/article/details/8300784 SQL查询性能的好坏直接影响到整个数据库的价值,对此,必须郑重对待. SQL Serv ...
- MySQL性能分析(转)
第一步:检查系统的状态 通过操作系统的一些工具检查系统的状态,比如CPU.内存.交换.磁盘的利用率.IO.网络,根据经验或与系统正常时的状态相比对,有时系统表面上看起来看空闲,这也可能不是一个正常的状 ...
随机推荐
- monkeyrunner之坐标或控件ID获取方法(六)
Monkeyrunner的环境已经搭建完成,现在对Monkeyrunner做一个简介. Monkeyrunner工具提供了一套API让用户/测试人员来调用,调用这些api可以控制一个Android设备 ...
- Fast RCNN 训练自己数据集 (2修改数据读取接口)
Fast RCNN训练自己的数据集 (2修改读写接口) 转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ http ...
- 第24章 java线程(3)-线程的生命周期
java线程(3)-线程的生命周期 1.两种生命周期流转图 ** 生命周期:**一个事物冲从出生的那一刻开始到最终死亡中间的过程 在事物的漫长的生命周期过程中,总会经历不同的状态(婴儿状态/青少年状态 ...
- Java设计模式之单例
一.Java中的单例: 特点: ① 单例类只有一个实例 ② 单例类必须自己创建自己唯一实例 ③ 单例类必须给所有其他对象提供这一实例 二.两种模式: ①懒汉式单例<线程不安全> 在类加载时 ...
- Sublime中Markdown的安装与使用
摘要:为什么用它,因为用markdown写出来的东西很好看,展示下:isujin.com(差不多就是这个样子啦,好看不?) 网页版Markdown编辑器有: 简书 jianshu.com等 客户端Ma ...
- Path Sum II
Path Sum II Given a binary tree and a sum, find all root-to-leaf paths where each path's sum equals ...
- jenkins 入门教程(上)
jenkins是一个广泛用于持续构建的可视化web工具,持续构建说得更直白点,就是各种项目的"自动化"编译.打包.分发部署.jenkins可以很好的支持各种语言(比如:java, ...
- [网络安全] [视频分享]KaLi Linux基础培训2016 最新的哦【福吧资源网】
最新的教程同时针对kali linux2016最新版本的多个问题解决办法还有一些实例利用. 下载地址:http://www.fu83.cn/thread-310-1-1.html
- jquey on
1.如果你的元素是用clone方法复制出来的,并且,用了on来绑定事件的话,必须在clone的后边添加true,负责你的事件不会生效. 2.必须在on $('.js-liubody').on('cli ...
- 配置Windows下的PHP开发环境
一.配置 Apache 开发环境: 二.配置 PHP 开发环境 配置 Apache 开发环境 0. 下载 Apache.由于官方只提供了源码包,我们要么自己编译要么使用别人提供的已经编译好的二进制包. ...