《Stepwise Metric Promotion for Unsupervised Video Person Re-identification》 ICCV 2017
Motivation:
这是ICCV 17年做无监督视频ReID的一篇文章。这篇文章简单来说基于两个Motivation。
- 在不同地方或者同一地方间隔较长时间得到的tracklet往往包含的人物是不同的
- 一个tracklet里面,大多数图片帧对应的都是同一个人
以上两点虽然是假设,但是也是满足大部分条件下的客观事实,之后的一些操作便是基于这两点假设展开。
Introduction:
这篇文章的出发点在于避免ReID领域令人头疼的标注工作。至于为什么做基于Video的ReID作者解释道首先是因为video比image多很多信息,比如时空线索以及姿势变化等,并且video需要的tracklet也容易使用目标追踪技术得到,同时video也能够抵抗一些背景噪声。
作者提出了一个渐进的学习框架。如果研究过无监督行人重识别,那么一定知道其中一个常见的方法就是打伪标签,然后不断在特征学习与伪标签赋值这两个过程中迭代以促进提取到的特征的准确性。这篇文章的做法也是这样,其流程如下所示。
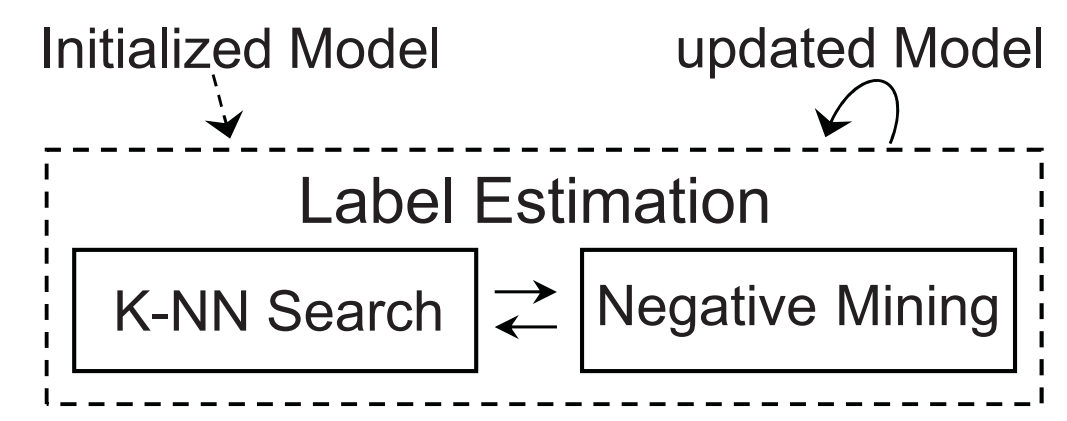
Method:
从以上的框架图可以看出这篇文章主要需要讲清楚三件事情,一个是如何进行模型初始化,第二个是如何进行标签估计,以及如何使用估计标签进行模型更新。
(1)模型初始化
因为需要打伪标签,所以我们先要有一个基本可靠的模型。这里作者就基于两个假设出发,在行人重识别问题中,不同的相机对应着不同的地点,而同一相机下,只要保证拍摄间隔比较长,那么追踪得到的tracklet往往就是不同人物的。所以我们可以在同一个相机下得到$N$个不同人物的tracklet,而每个tracklet里面拥有$n_{i}, i=1, \dots, N$张图片,一个tracklet里面的$n_{i}$张图片按照假设2来说是拥有同一身份的。所以这就从假设出发构建了一个天然存在的标签关系,就能够使用这些图片去初始化模型。
当然,问题并没有至此解决,因为行人重识别中真正困难的部分在于跨摄像头匹配,这样单一相机下学习到的模型往往在遇到多相机的匹配时就歇菜了。虽然表现不强,但是对于初始模型还是ok的。比如,作者使用MARS数据集的相机1做训练,之后在其他摄像头下执行搜索,效果如下所示:

(2)伪标签估计
这一步是这篇文章的重点,同样是基于前面两个假设。比如现在我们存在一个probe名为tracklet $p$,并且我们知道它是来自哪个相机的。现在我们用初始模型在这个相机下对$p$做检索,可以得到$M$个近邻 $x_{p}^{1}, x_{p}^{2}, \ldots, x_{p}^{M}$,基于假设1,这些tracklet一定和probe $p$包含的人物不同(如果$y_{p}$为1,它们则为0 ),我们令$X=\left\{x_{p}, x_{p}^{1}, \ldots, x_{p}^{M}\right\}$,对应的标签为$Y_{L}=\left\{y_{p}, y_{p}^{1}, \ldots, y_{p}^{M}\right\}$。可知$Y_{L}$是已知的。
之后呢,我们在gallery中再对$p$进行检索,得到K个近邻$Y_{U}=\left\{y_{g}^{1}, \ldots, y_{g}^{K}\right\}$,它们对应的标签为$Y_{U}=\left\{y_{g}^{1}, \ldots, y_{g}^{K}\right\}$,这些标签是未知的。现在我们的目标是利用$X$和$Y_{L}$来估计$Y_{U}$。
为了做到这一点,首先需要建立样本之间关联,作者使用Mahalanobis 来做距离度量,$\sigma$是一个控制参数,使用了类似于softmax的方法来标准化样本间相似度。
$w_{i, j}=\exp \left(-\frac{d_{i, j}}{\sigma^{2}}\right)$
$P_{i, j}=\frac{w_{i, j}}{\sum_{k=1}^{K+M+1} w_{k, j}}$
这里的$P_{i, j}$就代表的是样本j和i的相似度。同样还定义了一个标签矩阵$\boldsymbol{Y}$,前面的$(K+1)$行是$Y_{L}$,剩下的是$Y_{U}$。标签传播为$Y \leftarrow P Y$。其中$Y_{L}$应该永远保持不变,我们把$P$分为四个部分:
$P=\left[\begin{array}{ll}{P_{L L}} & {P_{L U}} \\ {P_{U L}} & {P_{U U}}\end{array}\right]$
所以$Y_{U}=\left(I-P_{U U}\right)^{-1} P_{U L} Y_{L}$。
通过以上我们可以在$Y_{U}$中找出最大值位置所对应的gallery样本,然后将这一样本也进行上述操作,再查看它的最大值处是否对应为$p$。如果满足这一条件,则两者标签一致,也就是互近邻的关系。

(3)模型更新
作者这里将XQDA推广到无监督的U-XQDA,来对所有训练样本学习一个统一的投影$W$和距离度量$M$。在XQDA中W对应的Generalized Rayleigh Quotient 为:
$J(W)=\frac{W^{\top} \Sigma_{E} W}{W^{\top} \Sigma_{I} W}$
这里$\boldsymbol{\Sigma}_{I}$和$\Sigma_{E}$分别是类内差异和类间差异。对比XQDA,作者提出的方法利用标签自动标记集S1和标签估计集S2来更新模型。所以目标函数被写成是:
$J(W)=\frac{W^{\top}\left(\Sigma_{E, S_{1}}+\Sigma_{E, S_{2}}\right) W}{W^{\top}\left(\Sigma_{I, S_{1}}+\Sigma_{I, S_{2}}\right) W}$
上面的$\Sigma_{E, S_{1}}, \Sigma_{E, S_{2}}$和$\Sigma_{I, S_{1}}, \Sigma_{I, S_{2}}$是类外差异和类内差异。这个最大化问题也可以通过广义特征值分解来求解。

如上图所示,更新完模型后,就会再次用模型来估计标签和关联跨视角的tracklet。这两个过程不断迭代,直到不再产生新的跨视角tracklet对。
(4)测试阶段
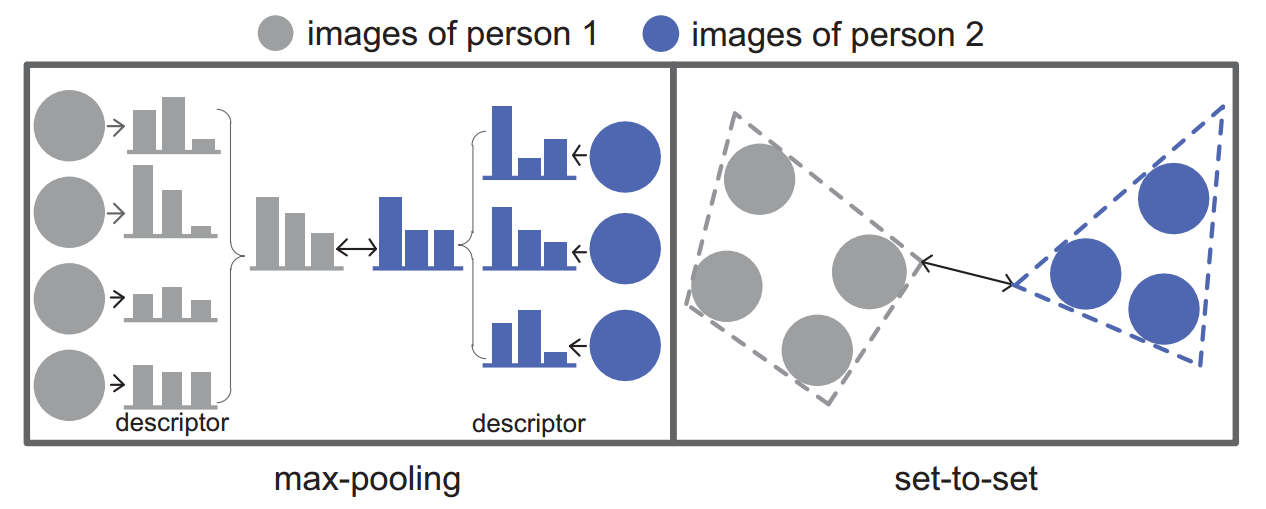
作者认为目前的所有基于视频的行人重识别方法都是在通过max-pooling使用点对点的距离来衡量相似度,而这里在训练阶段(比如无标签样本关联)和测试阶段都使用set-to-set的距离来度量tracklet可以带来更好的表现。
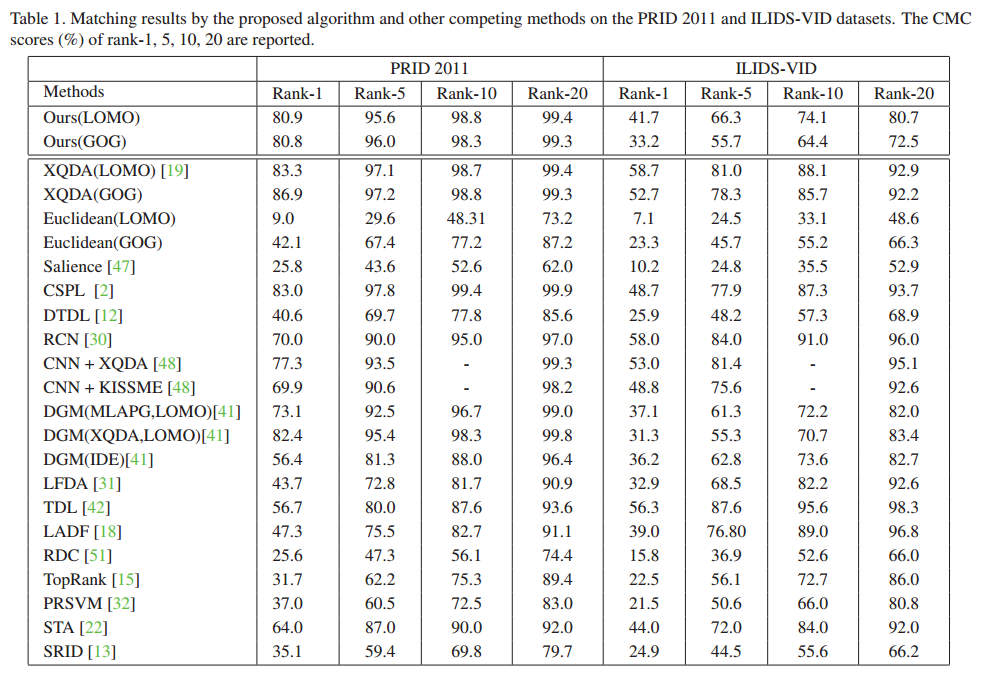
Experiments:
《Stepwise Metric Promotion for Unsupervised Video Person Re-identification》 ICCV 2017的更多相关文章
- 《数字图像处理原理与实践(MATLAB文本)》书代码Part7
这篇文章是<数字图像处理原理与实践(MATLAB文本)>一本书的代码系列Part7(由于调整先前宣布订单,请读者注意分页程序,而不仅仅是基于标题数的一系列文章),第一本书特色186经225 ...
- 论文阅读:Face Recognition: From Traditional to Deep Learning Methods 《人脸识别综述:从传统方法到深度学习》
论文阅读:Face Recognition: From Traditional to Deep Learning Methods <人脸识别综述:从传统方法到深度学习> 一.引 ...
- 《Java程序设计与数据结构教程(第二版)》学习指导
<Java程序设计与数据结构教程(第二版)>学习指导 欢迎关注"rocedu"微信公众号(手机上长按二维码) 做中教,做中学,实践中共同进步! 原文地址:http:// ...
- 《zw版·Halcon入门教程与内置demo》
<zw版·Halcon入门教程与内置demo> halcon系统的中文教程很不好找,而且大部分是v10以前的版本. 例如,QQ群: 247994767(Delphi与halcon), 共享 ...
- 《开源安全运维平台:OSSIM最佳实践》内容简介
<开源安全运维平台:OSSIM最佳实践 > 李晨光 著 清华大学出版社出版 内 容 简 介在传统的异构网络环境中,运维人员往往利用各种复杂的监管工具来管理网络,由于缺乏一种集成安全运维平台 ...
- [转载]《民航科技》2012年4月专家论坛:程延松《关于中国民航SWIM框架及技术实现探讨》
专家介绍:程延松,现任成都民航空管发展有限公司总经理,理学博士,高级工程师,长期从事空管技术研究和产品研发工作,作为课题负责人,参与了国家863计划.国家科技支撑计划.国家空管委重点课题.民航局重点课 ...
- 《隆重介绍 思源黑体:一款Pan-CJK 开源字体》
关于思源黑体 思源黑体是谷歌与 Adobe 联合开发,支持简体中文.繁体中文.日文.韩文以及英文:支持 ExtraLight.Light.Normal.Regular.Medium.Bold 和 He ...
- 2015年8月18日,杨学明老师《技术部门的绩效管理提升(研讨会)》在中国科学院下属机构CNNIC成功举办!
2015年8月18日,杨学明老师为中国网络新闻办公室直属央企中国互联网络中心(CNNIC)提供了一天的<技术部门的绩效管理提升(研讨会)>培训课程.杨学明老师分别从研发绩效管理概述.研发绩 ...
- 《介绍一款开源的类Excel电子表格软件》续:七牛云存储实战(C#)
两个月前的发布的博客<介绍一款开源的类Excel电子表格软件>引起了热议:在博客园有近2000个View.超过20个评论. 同时有热心读者电话咨询如何能够在SpreadDesing中实现存 ...
随机推荐
- XGBoost文本分类,多分类、二分类、10-Fold(K-Fold)
做机器学习的时候经常用到XGB,简单记录一下 K折交叉验证也是模型常用的优化方法.一起记录... K折交叉验证:类似三个臭皮匠,顶个诸葛亮.我的理解是,就是用民主投票的方式,选取票数最高的那个当结果. ...
- vscode设置vue文件高亮显示
打开VS Code,左上角 文件->首选项->设置->文本编辑器->文件,点击右侧的"在settings.json中编辑",进入settings.json文 ...
- Django学习——静态文件配置、request对象方法、pycharm如何链接数据库、Django如何指定数据库、Django orm操作
静态文件配置 # 1.静态文件 网站所使用的已经提前写好的文件 css文件 js文件 img文件 第三方文件 我们在存储静态文件资源的时候一般默认都是放在static文件夹下 # 2.Django静态 ...
- 工程师姓什么很重要!别再叫我“X工”!!!
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ 工程师之间都是这么互相打招呼的-- "高工,你设计图通过了么?" &quo ...
- c++:-3
上一节学习了C++的函数:c++:-2,本节学习C++的数组.指针和字符串 数组 定义和初始化 定义 例如:int a[10]; 表示a为整型数组,有10个元素:a[0]...a[9] 例如: int ...
- Caused by: java.lang.Exception: No native library is found for os.name=Mac and os.arch=aarch64. path=/org/sqlite/native/Mac/aarch64
编译项目报错: Caused by: java.lang.Exception: No native library is found for os.name=Mac and os.arch=aarch ...
- bean的自动装配,使用注解开发,使用java的方式配置Spring
bean的自动装配 自动装配是Spring满足bean依赖一种方式! Spring会在上下文中自动寻找,并自动给bean装配属性! 在Spring中有三种装配的方式 在xml中显示的配置 在java中 ...
- 面试简历书写、Flask框架介绍与快速使用、Flask演示登录页面、用户信息页面案例
今日内容概要 面试简历编写 Flask框架介绍与安装 内容详细 1.面试简历编写 # 千万不要几个小时把简历凑出来 几天到一周 # 有没有面试机会,取决于简历写得怎么样 简历写好是第一步 # 投简历的 ...
- 【多线程】线程创建方式三:实现callable接口
线程创建方式三:实现callable接口 代码示例: import org.apache.commons.io.FileUtils; import java.io.File; import java. ...
- 482. License Key Formatting - LeetCode
Question 482. License Key Formatting Solution 思路:字符串转化为char数组,从后遍历,如果是大写字母就转化为小写字母,如果是-就忽略,如果遍历了k个字符 ...