完整数据分析流程:Python中的Pandas如何解决业务问题

开篇
作为万金油式的胶水语言,Python几乎无所不能,在数据科学领域的作用更是不可取代。数据分析硬实力中,Python是一个非常值得投入学习的工具。
这其中,数据分析师用得最多的模块非Pandas莫属,如果你已经在接触它了,不妨一起来通过完整的数据分析流程,探索Pandas是如何解决业务问题的。
数据背景
为了能尽量多地使用不同的Pandas函数,我设计了一个古古怪怪但是实际中又很真实的数据,说白了就是比较多不规范的地方,等着我们去清洗。
数据源是改编自一家超市的订单,文末附文件路径。
导入所需模块
import pandas as pd
数据导入
Pandas提供了丰富的数据IO接口,其中最常用的是pd.read_excel及pd.read_csv函数。
data = pd.read_excel('文件路径.xlsx',
sheet_name='分页名称')
data = pd.read_csv('文件路径.csv')
从超市数据集中把多页数据分别导入:
orders = pd.read_excel('超市数据集.xlsx',
sheet_name= '订单表')
customers = pd.read_excel('超市数据集.xlsx',
sheet_name= '客户表')
products = pd.read_excel('超市数据集.xlsx',
sheet_name= '产品表')
该环节除了导入数据外,还需要对数据有初步的认识,明确有哪些字段,及其定义
这里我们通过 pd.Series.head() 来查看每个数据表格的字段及示例数据

明确业务问题及分析思路
在业务分析实战中,在开始分析之前,需要先明确分析目标,倒推分析方法、分析指标,再倒推出所需数据。
这就是「以终为始」的落地思维。
假设业务需求是通过用户分层运营、形成差异化用户运营策略。数据分析师评估后认为可基于RFM用户价值模型对顾客进行分群,并通过不同族群画像特征制定运营策略,比如重要价值用户属于金字塔顶端人群,需要提供高成本、价值感的会员服务;而一般价值用户属于价格敏感型的忠诚顾客,需要通过折扣刺激消费等。
因此,这里的分析方法则是对存量用户进行RFM模型分群,并通过统计各族群数据特征,为业务提供策略建议。
明确业务需求及分析方法后,我们才能确定去统计顾客的R、F、M、以及用于画像分析的客单价等指标,此时才能进入下一步。
特征工程与数据清洗
数据科学中有句话叫 "Garbage In, Garbage Out",意思是说如果用于分析的数据质量差、存在许多错误,那么即使分析的模型方法再缜密复杂,都不能变出花来,结果仍是不可用的。
所以也就有了数据科家中80%的工作都是在做数据预处理工作的说法。
特征工程主要应用在机器学习算法模型过程,是为使模型效果最佳而进行的系统工程,包括数据预处理(Data PrePorcessing)、特征提取(Feature Extraction)、特征选择(Feature Selection)以及特征构造(Feature Construction)等问题。
直白地说,可以分成两部分:
- 数据预处理,可以理解成我们常说的数据清洗;
- 特征构造,比如此次构建RFM模型及分组用户画像中,R、F、M、客单价等标签就是其对应的特征。
(当然,RFM非机器学习模型,这里是为了便于理解进行的解释。)
数据清洗
什么是数据清洗?
数据清洗是指找出数据中的「异常值」并「处理」它们,使数据应用层面的结论更贴近真实业务。
异常值:
- 不规范的数据,如空值、重复数据、无用字段等,需要注意是否存在不合理的值,比如订单数据中存在内部测试订单、有超过200岁年龄的顾客等
- 特别注意数据格式是否合理,否则会影响表格合并报错、聚合统计报错等问题
- 不符合业务分析场景的数据,比如要分析2019-2021年的用户行为,则在此时间段之外的行为都不应该被纳入分析
如何处理:
- 一般情况下,对于异常值,直接剔除即可
- 但对于数据相对不多,或该特征比较重要的情况下,异常值可以通过用平均值替代等更丰富的方式处理
在了解数据清洗的含义后,我们便可以开始用Pandas来实操该部分内容。
数据类型
先用pd.dtypes来检查数据字段是否合理
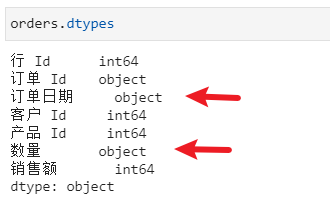
发现订单日期、数量是Object(一般即是字符)类型,后面无法用它们进行运算,需要通过pd.Series.astype()或pd.Series.apply()方法来修改字符类型
orders['订单日期'] = orders['订单日期'].astype('datetime64')
orders['数量'] = orders['数量'].apply(int)
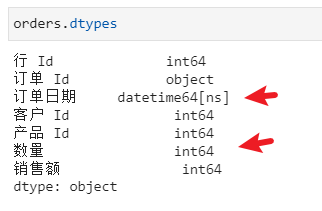
另外,对时间类型的处理也可以通过pd.to_datetime进行:
orders['订单日期'] = pd.to_datetime(orders['订单日期'])
修改字段名
经验丰富的数据分析师发现字段名字也有问题,订单 Id存在空格不便于后面的引用,需要通过pd.rename()来修改字段名
orders = orders.rename(columns={'订单 Id':'订单ID',
'客户 Id':'客户ID',
'产品 Id':'产品ID'})
customers = customers.rename(columns={'客户 Id':'客户ID'})
多表连接
把字段名以及数据类型处理好后,就可以用pd.merge将多个表格进行连接。
表连接中的on有两种方式,一种是两个表用于连接的字段名是相同的,直接用on即可,如果是不相同,则要用left_on, right_on进行。
data = orders.merge(customers, on='客户ID', how='left')
data = data.merge(products, how='left',
left_on='产品ID', right_on='物料号')
剔除多余字段
对于第二种情况,得到的表就会存在两列相同含义但名字不同的字段,需要用pd.drop剔除多余字段。此外,“行 Id”在这里属于无用字段,一并剔除掉。
data.drop(['物料号','行 Id'],axis=1,
inplace=True)
调整后得到的表结构:

文本处理——剔除不符合业务场景数据
根据业务经验,订单表中可能会存在一些内部测试用的数据,它们会对分析结论产生影响,需要把它们找出来剔除。与业务或运维沟通后,明确测试订单的标识是在“产品名称”列中带“测试”的字样。
因为是文本内容,需要通过pd.Series.str.contains把它们找到并剔除

data = data[~data['产品名称'].str.contains('测试')]
时间处理——剔除非分析范围数据
影响消费者的因素具有时间窗口递减的特性,例如你10年前买了顶可可爱爱的帽子,不代表你今天还需要可可爱爱风格的产品,因为10年时间足以让你发生许多改变;但是如果你10天以前才买了田园风的裙子,那么就可以相信你现在还会喜欢田园风产品,因为你偏好的风格在短期内不会有太大改变。
也就是说,在用户行为分析中,行为数据具有一定时效,因此需要结合业务场景明确时间范围后,再用pd.Series.between()来筛选近符合时间范围的订单数据进行RFM建模分析。
data= data[data['订单日期'].between('2019-01-01','2021-08-13')]
特征构造
此环节目的在于构造分析模型,也就是RFM模型及分群画像分析所需的特征字段。
数据聚合——顾客消费特征
首先,是RFM模型中顾客的消费特征:
- R:客户最近一次购买离分析日期 (设为2021-08-14)的距离,用以判断购买用户活跃状态
- F:客户消费频次
- M:客户消费金额
这些都是一段时间内消费数据的聚合,所以可以用pd.groupby().agg()实现
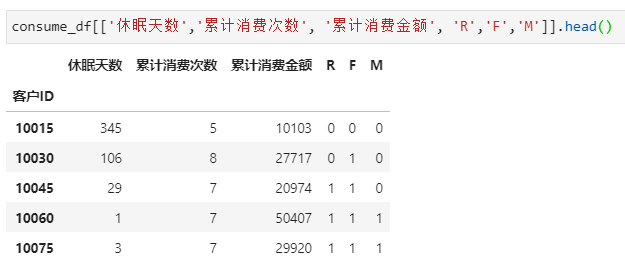
consume_df = data.groupby('客户ID').agg(累计消费金额=('销售额',sum),
累计消费件数=('数量',sum),
累计消费次数=('订单日期', pd.Series.nunique),
最近消费日期=('订单日期',max)
)
其中,R值比较特殊,需要借用datetime模块,计算日期之间的距离
from datetime import datetime
consume_df['休眠天数'] = datetime(2021,8,14) - consume_df['最近消费日期']
consume_df['休眠天数'] = consume_df['休眠天数'].map(lambda x:x.days)
计算所得顾客累计消费数据统计表:
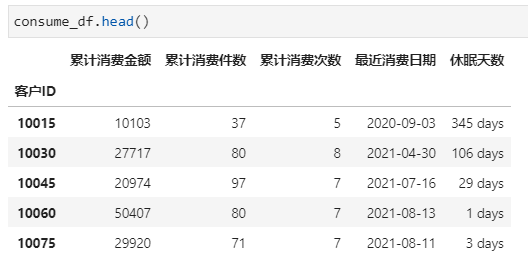
分箱处理——客单价区间划分
根据前面分析思路所述,完成RFM模型用户分群后,还要统计各族群用户消费画像,这里因篇幅限制仅统计各族群客单价分布特征。
此时,计算完客单价数据后,需要用pd.cut对客单价进行分箱操作,形成价格区间。
consume_df['客单价'] = consume_df['累计消费金额']/consume_df['累计消费次数']
consume_df['客单价区间'] = pd.cut(consume_df['客单价'],bins=5)
通过pd.Series.value_counts方法统计客单价区间分布情况:
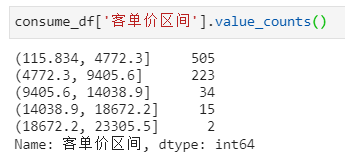
pd.cut中的bins参数为将客单价划分的区间数,填入5,则平均分为5档。当然,还是那句话,这个在实操中需要与业务明确,或结合业务场景确定。
RFM建模
完成数据清洗及特征构造后,就进入到建模分析环节。
Tukey's Test 离群值检测
根据分析经验,离群值会极大地对统计指标造成影响,产生较大误差,例如把马云放到你们班里,计算得出班级平均资产上百亿。在这里,马云就是离群值,要把它剔除出去。
所以,在开始对RFM阈值进行计算之前,有必要先对R、F、M的值进行离群值检测。
这里我们用Turkey's Test 方法,简单来说就是通过分位数之间的运算形成数值区间,将在此区间之外的数据标记为离群值。不清楚的同学可以知乎搜一下,这里不展开讲。
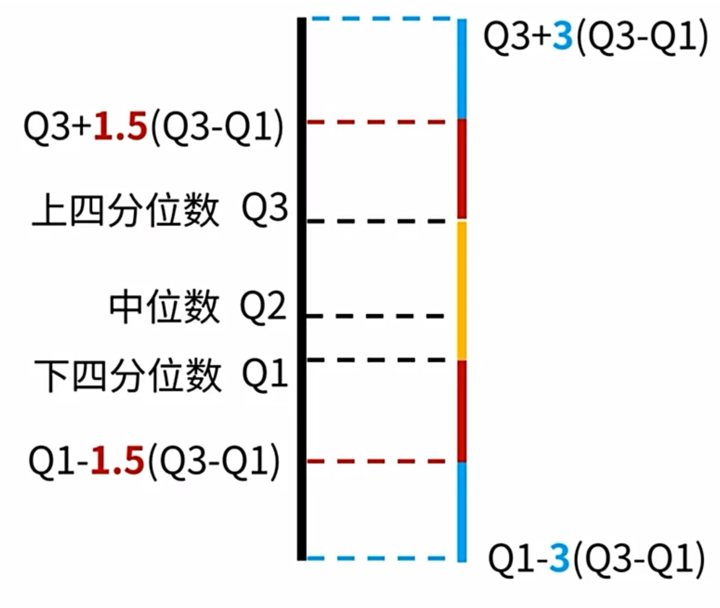
Turkey's Test方法依赖分位数的计算,在Pandas,通过pd.Series.quantile计算分位数
def turkeys_test(fea):
Q3 = consume_df[fea].quantile(0.75)
Q1 = consume_df[fea].quantile(0.25)
max_ = Q3+1.5*(Q3-Q1)
min_ = Q1-1.5*(Q3-Q1)
if min_<0:
min_ =0
return max_, min_
以上代码实现了Tukey's Test函数,其中Q3就是75分位、Q1就是25分位。而min_ 和 max_则形成合理值区间,在此区间之外的数据,不论太高还是太低还是离群值。
注意,在这里因为存在min_是负数的情况,而消费数据不可能是负数,所以补充了一个把转为0的操作。
接下来,给RFM特征数据表新增字段"是否异常",默认值为0,然后再用Tukey's Test函数把异常数据标记为1,最后只需保留值为0的数据即可。
consume_df['是否异常'] = 0
for fea in rfm_features:
max_, min_= turkeys_test(fea)
outlet = consume_df[fea].between(min_,max_) #bool
consume_df.loc[~outlet,'是否异常']=1
consume_df = consume_df[consume_df['是否异常']==0]
聚类与二八原则——RFM阈值计算
现在已经可以确保建模所用的特征是有效的,此时就需要计算各指标阈值,用于RFM建模。阈值的计算一般通过聚类算法进行,但这里不涉及机器学习算法。从本质上讲,聚类结果通常是符合二八原则的,也就是说重要客群应该只占20%,所以我们可以计算80分位数来近似作为RFM模型阈值。
M_threshold = consume_df['累计消费金额'].quantile(0.8)
F_threshold=consume_df['累计消费次数'].quantile(0.8)
R_threshold = consume_df['休眠天数'].quantile(0.2)
RFM模型计算
得到RFM阈值后,即可将顾客的RFM特征进行计算,超过阈值的则为1,低于阈值的则为0,其中R值计算逻辑相反,因为R值是休眠天数,数值越大反而代表越不活跃。
consume_df['R'] = consume_df['休眠天数'].map(lambda x:1 if x<R_threshold else 0)
consume_df['F'] = consume_df['累计消费次数'].map(lambda x:1 if x>F_threshold else 0)
consume_df['M'] = consume_df['累计消费金额'].map(lambda x:1 if x>M_threshold else 0)
对顾客RFM特征划分1和0,即高与低后,即可进行分群计算:
consume_df['RFM'] = consume_df['R'].apply(str)+'-' + consume_df['F'].apply(str)+'-'+ consume_df['M'].apply(str)
rfm_dict = {
'1-1-1':'重要价值用户',
'1-0-1':'重要发展用户',
'0-1-1':'重要保持用户',
'0-0-1':'重要挽留用户',
'1-1-0':'一般价值用户',
'1-0-0':'一般发展用户',
'0-1-0':'一般保持用户',
'0-0-0':'一般挽留用户'
}
consume_df['RFM人群'] = consume_df['RFM'].map(lambda x:rfm_dict[x])

至此,已完成RFM建模及用户分群计算。
分群画像
完成模型分群后,就要对各族群分别统计人数及客单价分布。
人数占比
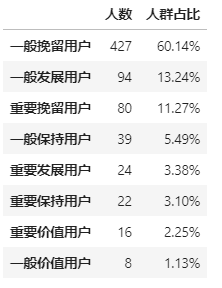
最简单的一个画像分析,则是用pd.Series.value_counts对各族群进行人数统计,分析相对占比大小。
rfm_analysis = pd.DataFrame(consume_df['RFM人群'].value_counts()).rename(columns={'RFM人群':'人数'})
rfm_analysis['人群占比'] = (rfm_analysis['人数']/rfm_analysis['人数'].sum()).map(lambda x:'%.2f%%'%(x*100))
透视表
各族群客单价分布涉及多维度分析,可以通过Pandas透视功能pd.pivot_table实现
代码中,聚合函数aggfunc我用了pd.Series.nunique方法,是对值进行去重计数的意思,在这里就是对客户ID进行去重计数,统计各价位段的顾客数。
pd.pivot_table(consume_df.reset_index(), # DataFrame
values='客户ID', # 值
index='RFM人群', # 分类汇总依据
columns='客单价区间', # 列
aggfunc=pd.Series.nunique, # 聚合函数
fill_value=0, # 对缺失值的填充
margins=True, # 是否启用总计行/列
dropna=False, # 删除缺失
margins_name='All' # 总计行/列的名称
).sort_values(by='All',ascending=False)
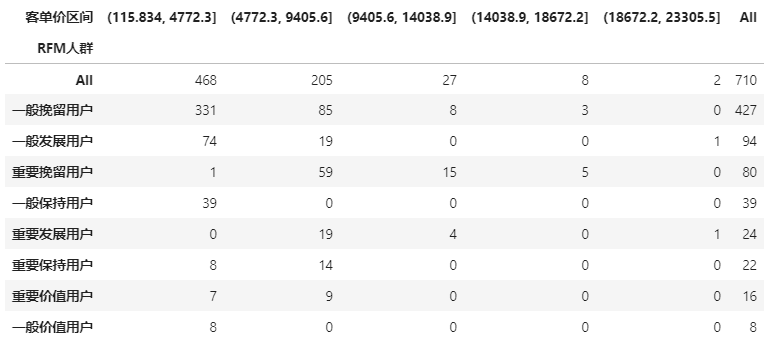
这样就得到了每个族群在不同价位段上的分布,配合其他维度的画像分析可以进一步形成营销策略。
逆透视表
最后,做个骚操作,就是透视后的表属于多维度表格,但我们要导入到PowerBI等工具进行可视化分析时,需要用pd.melt将它们逆透视成一维表。
pivot_table.melt(id_vars='RFM人群',
value_vars=['(124.359, 3871.2]', '(3871.2, 7599.4]',
'(7599.4, 11327.6]', '(11327.6, 15055.8]',
'(15055.8, 18784.0]']).sort_values(by=['RFM人群','variable'],ascending=False)
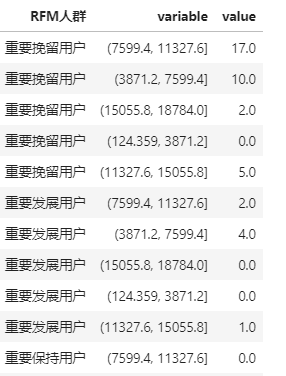
这样字段名为"人群"、"指标"、"值"的表格,可以一行就把信息呈现的表格就是一维表。而前面各族群人数统计中,需要一行一列来定位信息的就是二维表。
结尾
至此,我们已经通过Pandas建立了RFM模型及分组人群画像分析,完成了业务分析需求。
受限于篇幅,本文仅对数据分析过程中Pandas高频使用的函数方法进行了演示,同样重要的还有整个分析过程。如果其中对某些函数不熟悉,鼓励同学多利用知乎或搜索引擎补充学习。同时也欢迎加饼干哥哥微信讨论。
更多Pandas函数使用说明,可查询中文文档
本文算是数据分析流程的基础篇,计划会再整理一份进阶篇,涉及机器学习流程、以及更多特征工程内容,同样会以业务落地实战的方式进行介绍。
完整数据分析流程:Python中的Pandas如何解决业务问题的更多相关文章
- python中的pandas的两种基本使用
python中的pandas的两种基本使用2018年05月19日 16:03:36 木子柒努力成长 阅读数:480 一.pandas简介 pandas:panel data analysis(面板数据 ...
- 沉淀,再出发:python中的pandas包
沉淀,再出发:python中的pandas包 一.前言 python中有很多的包,正是因为这些包工具才使得python能够如此强大,无论是在数据处理还是在web开发,python都发挥着重要的作用,下 ...
- Python中的Pandas模块
目录 Pandas Series 序列的创建 序列的读取 DataFrame DataFrame的创建 DataFrame数据的读取 Panel Panel的创建 Pandas Pandas ( Py ...
- python中安装pandas
在运行网上找的代码时,报错:ImportError: No module named 'pandas',解决:安装pandas安装过程:(因为网上教程有的说用pip命令行安装:有的直接下载安装包,然后 ...
- python中的TypeError错误解决办法
新手在学习python时候,会遇到很多的坑,下面来具体说说其中一个. 在使用python编写面向对象的程序时,新手可能遇到TypeError: this constructor takes no ar ...
- python 中安装pandas
由于计算arima模型需要用到pandas,费尽千辛万苦找到了一个下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/,在这里能下载到很多我们要用的模块.找到 ...
- Python中近期Pandas使用总结
近期做了很多关于数据处理的问题,发现灵活运用pandas包对于数据分析来说可以轻松好多 导包 import numpy as npimport pandas as pdfrom pandas impo ...
- Python中的栈溢出及解决办法
1.递归函数 在函数内部,可以调用其他函数.如果一个函数在内部调用自身本身,这个函数就是递归函数. 举个例子,我们来计算阶乘n! = 1 x 2 x 3 x ... x n,用函数fact(n)表示, ...
- Python中 No module named解决方法
对于pycharm安装包失败的原因借解决办法 在pycharm中安装包安装失败:Non-zero exit code (1) 可能是在库中找不到对应版本.解决:cmd中使用命令:pip install ...
- python中匹配中文,解决不匹配,乱码等问题
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe7 in position 0: ordinal 字符串前加 ur‘str’即可;
随机推荐
- day48-JDBC和连接池04
JDBC和连接池04 10.数据库连接池 10.1传统连接弊端分析 传统获取Connection问题分析 传统的 JDBC 数据库连接使用DriverManager来获取,每次向数据库建立连接的时候都 ...
- Windows开启关闭测试模式的方法(含开启测试模式失败的解决办法)
前言: 内含:Windows开启关闭测试模式的方法.开启测试模式失败的解决办法.win10进入bios的方式.BitLocker恢复方式. 对于互联网从业者来说 ...
- JavaScript基础&实战(4)js中的对象、函数、全局作用域和局部作用域
文章目录 1.对象的简介 2.对象的基本操作 2.1 代码 2.2 测试结果 3.属性和属性值 3.1 代码 3.2 测试结果 4.对象的方法 4.1 代码 4.2 测试结果 5.对象字面量 5.1 ...
- 齐博x1.3通用栏目名称及参数调用接口
对于全站的频道可以使用下面的方法取出相应的栏目名称及参数http://qb.net/index.php/cms/wxapp.sorts.html注意,只需要把qb.net换成你的域名,cms 换成其它 ...
- 驱动开发:内核测试模式过DSE签名
微软在x64系统中推出了DSE保护机制,DSE全称(Driver Signature Enforcement),该保护机制的核心就是任何驱动程序或者是第三方驱动如果想要在正常模式下被加载则必须要经过微 ...
- PMM实现监控Mysql-MGR
一.docker安装PMM服务端 1.安装yum配置单元 # 如果已安装,略过此步 yum install -y yum-utils #yum配置单元 2.配置docker阿里云yum源 #配置doc ...
- LVS综合实验
LVS综合实验 1.环境准备 提前准备:Mysql8.0.30安装包.Mysql安装脚本.shopxo2.3.0安装包.DNS脚本 服务器 IP地址 作用 系统版本 Mysql-master 10.0 ...
- 【Bluetooth蓝牙开发】一、开篇词 | 打造全网最详细的Bluetooth开发教程
个人主页:董哥聊技术 我是董哥,嵌入式领域新星创作者 创作理念:专注分享高质量嵌入式文章,让大家读有所得! 文章目录 1.前言 2.蓝牙综合介绍 3.精华文章汇总 4.结语 1.前言 大家好,我是董哥 ...
- 纯css爱心代码-最近超级火的打火机与公主裙中的爱心代码(简易版)
theme: cyanosis 最近打火机与公主裙中的爱心代码超级火,看着特别心动,让俺用css来写个简易版!!! 先看效果: 代码拆解: 主要是分为3大部分 分子颗粒 爱心 动画 代码实现: 分子颗 ...
- 配置jmeter环境变量
好记性不如烂笔头. 本文采用jmeter5.4.1版本. 1. Linux系统 1.1 将jmeter上传到安装目录并解压 jmeter5.4.1链接: https://pan.baidu.com/ ...