python爬取京东评论
一.分析
1.找到京东商品评论所在位置(记得点击商品评论,否则找不到productPageComments.action)
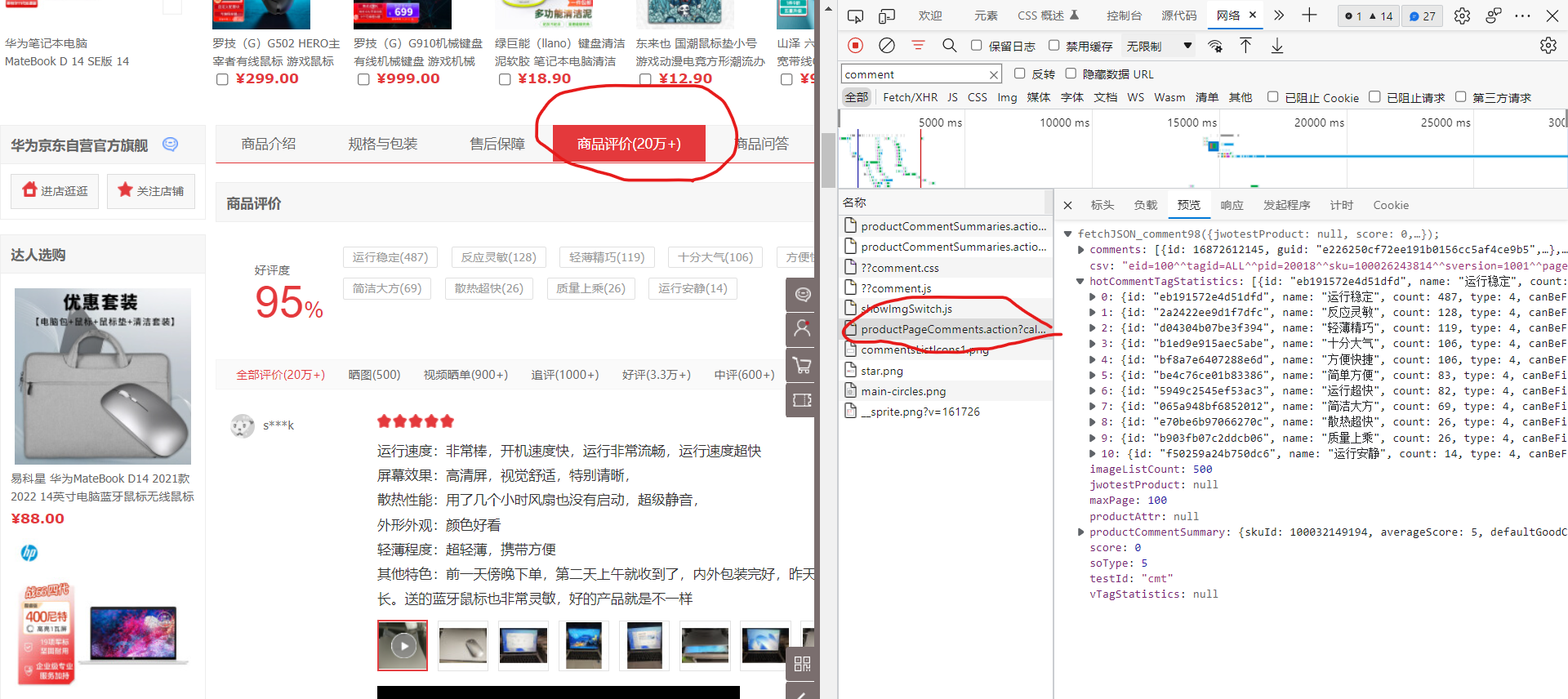
2.解析文件
打开后发现是json数据,但不是那么规范,所以需要去点前面的字符串和括号,还有最后一行的分号和括号

3.放到json解析器可以看到数据的结构

4.解析网址

里面的参数:
productid:产品id;不同的id不同的商品
score:0是全部评论,1是差评,2是中评,3是好评,4是晒图评价,5是追平
page:页数 ,评论较多的最多显示100页,虽然评论是20万+,但是也只能爬取一百页
,评论较多的最多显示100页,虽然评论是20万+,但是也只能爬取一百页
所以根据更改page可以爬取多个页面评论
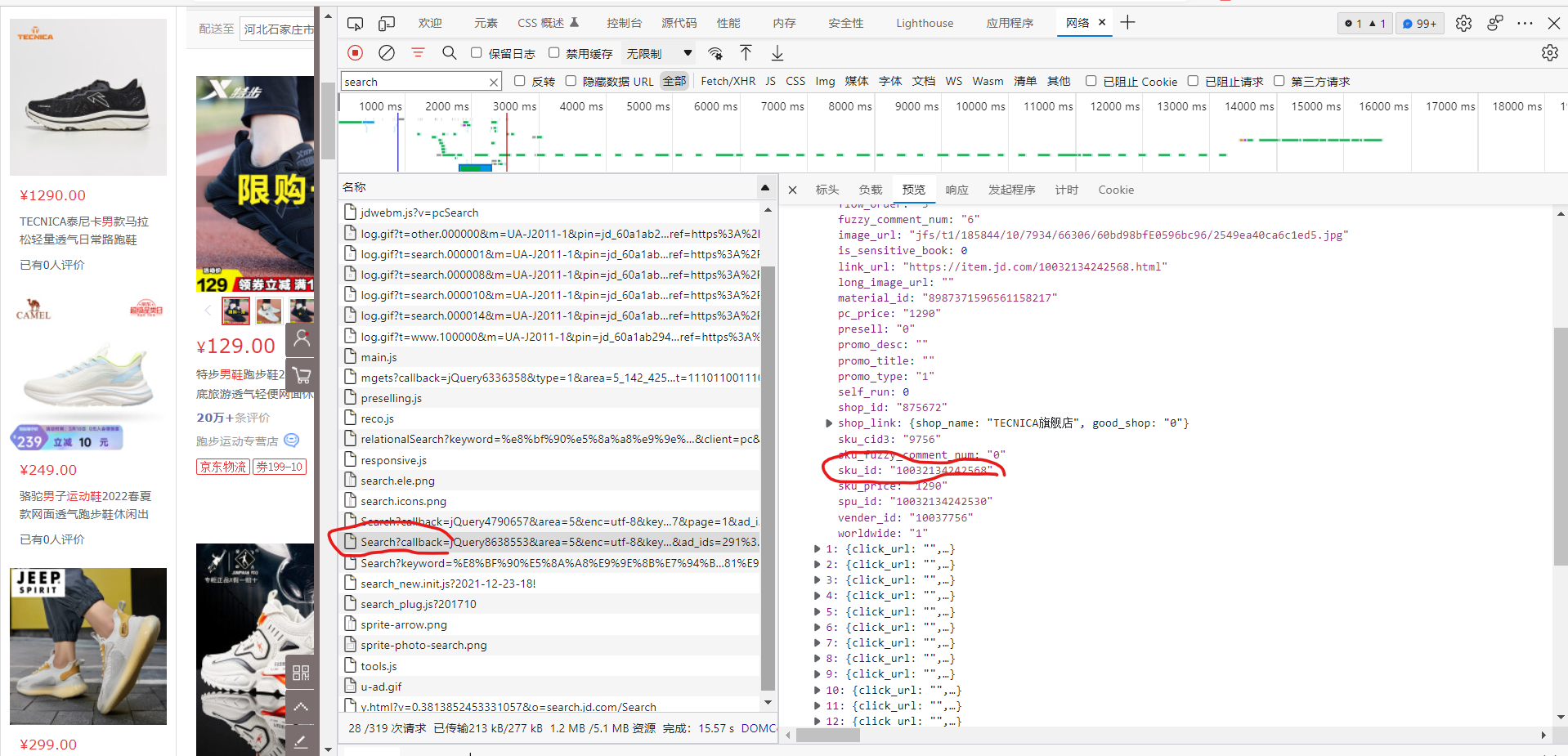
5.爬取多个商品
要爬取多个商品就要多个productid,所以就要去找它
通过搜索xxxx,可以在search中找到sku_id,将它解析出来即可,同上
二.编写爬虫代码
# -*- coding: utf-8 -*-
import gzip
import urllib.request
import json
import time
import random
import demjson as dj
import requests
import itertools headers = {
"Cookie": "__jdu=1507876332; shshshfpa=2ea021ee-52dd-c54e-1be1-f5aa9e333af2-1640075639; areaId=5; PCSYCityID=CN_0_0_0; shshshfpb=n7UymiTWOsGPvQfCup%2B3J1g%3D%3D; ipLoc-djd=5-142-42547-54561; jwotest_product=99; pinId=S4TjgVP4kjjnul02leqp07V9-x-f3wj7; pin=jd_60a1ab2940be3; unick=jd_60a1ab2940be3; ceshi3.com=000; _tp=672TNfWmOtaDFuqCPQqYycXMpi6F%2BRiwrhIuumNmoJ4%3D; _pst=jd_60a1ab2940be3; __jdc=122270672; shshshfp=4e8d45f57897e469586da47a0016f20e; ip_cityCode=142; CCC_SE=ADC_rzqTR2%2bUDTtHDYjJdX25PEGvHsBpPY%2bC9pRDVdNK7pU%2fwikRihpN3XEXZ1cn4Jd4w5OWdpJuduhBFwUvdeB6X1VFb7eIZkqL0OJvBn9RB6AJYo4An%2fGTiU%2b8rvqQwYxBI4QCM8a9w9kYQczygSjPxPjn1pbQLtBgo%2fzKBhwfKhAWs563NfBjmnRlkGHPX6E7jy6%2fEdfEhtkNSTCQod238cEpUFpKiQ%2bWV%2bW8MiaL3ti7d7ozdlNbZ03ylqRbI1XrXylDiqzW%2b2uALhF5H1eHuk3yH3t4ojXZmRbDy3k2OoZFk%2bcmrXD0eWhcIaD5RnhHbToYLuX%2byx7otaPuemTVAG4Z7CSyEfmUBAj7QuGmHg647a7KuoaR3hoCvxj%2f3woXdd2H9b40oqmJ5PO958Z1g%2fr7Jbk8a5w2CU547IaXRzakehLhW9xzG57Ak0Jhv85Jlt9A5N6hl%2ft4DSAwh%2bGhwg%3d%3d; unpl=JF8EAJJnNSttDBxWAxxSEkUVQg4EW1QKTx9TazcCAV8KSFICE1FIF0N7XlVdXhRKFR9vYhRUW1NPVA4ZBysSEXteVV1YCE0TAGlnNWRtW0tkBCsCHxMWQltTXF8LeycDZ2M1VFxZSlYGHQEbEBBCbWRbXQlKFQBpYQVQbVl7VTVZbEJTDBkCBxNdDEoRCmlgB1ZeaEpkBg; JSESSIONID=347F847A6818E35675648739BD4BA9FF.s1; __jda=122270672.1507876332.1640075637.1647251498.1647261295.13; thor=8D225D1673AA75681B9D3811417B0D325568BB2DD7F2729798D3AECF0428F59F7C70EA7504347F8E059F895AEE7D6E2662F565665845F0D94F2D7D56739CF3BC2B15F5F6E2ADDB891DDA80A9E9F88B7BA0BA95147512F78D28D8095E52379AB78550E451558DB6595C2270A1D5CFA2E211FF20F22ADA1987C6AE9E864DA6A7364D5BFD3EE08DA597D2EF2B37444CFD7A47134EFFD71B3A70B0C8BD55D51F274F; token=397b2c7c58f4021bbe9a9bbe9eeda694,3,915145; __tk=46fbcc7e51f75824dcdc2e8820904365,3,915145; shshshsID=5c5095f0b5728a839c0397308d625da5_1_1647261360535; __jdb=122270672.2.1507876332|13.1647261295; __jdv=122270672|jd.idey.cn|t_2024175271_|tuiguang|ef376a8f48ba48359a5a6d3c2769bb4b|1647261360584; 3AB9D23F7A4B3C9B=24HI5ARAA3SK7RJERTWUDZKA2NYJIXX3ING24VG466VC3ANKUALJLLD7VBYLQ3QPRYUSO3R6QBJYLVTVXBDIGJLGBA",
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39"
}
headers2 = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cookie": "__jdu=1507876332; shshshfpa=2ea021ee-52dd-c54e-1be1-f5aa9e333af2-1640075639; areaId=5; PCSYCityID=CN_0_0_0; ipLoc-djd=5-142-42547-54561; pinId=S4TjgVP4kjjnul02leqp07V9-x-f3wj7; pin=jd_60a1ab2940be3; unick=jd_60a1ab2940be3; _tp=672TNfWmOtaDFuqCPQqYycXMpi6F%2BRiwrhIuumNmoJ4%3D; _pst=jd_60a1ab2940be3; user-key=a2aaf011-2c1e-4dea-bf76-3392d16b1fb1; __jdc=122270672; wlfstk_smdl=jlwwba2gmccq62touff9evvbp3fk8gbr; ceshi3.com=000; shshshfp=4e8d45f57897e469586da47a0016f20e; ip_cityCode=142; shshshfpb=n7UymiTWOsGPvQfCup%2B3J1g%3D%3D; joyya=1647305570.1647305909.27.0kop377; __jda=122270672.1507876332.1640075637.1647314039.1647318046.22; token=d5899471c4530886f6a9658cbea3ca94,3,915176; __tk=1570759a7dd1a720b0db2dec5df8d044,3,915176; CCC_SE=ADC_Wj0UWzuXioxsiUvbIxw9PbW9q011vNMASHkfjXFO%2fZlkeGDtZUHe5qgaEpWv8RDEkCruGSGmCItsvHjIZ3aHbh9heUjNIZh6WZl9ZDfDokk66kRX6I%2by%2bDsdf4JtPOQUuULSsWOA%2fcDyP7Bb91YuHOwNnciLtS97UIKO7XA5sAd34Rf4XDKijy6Fw1DFTx%2b7izzme6YALuLp9Y%2bByC6aUTDzU9te7g1BZXPXtfGGwqu52ZVkdVId2jpxPnhX24fFD9WI9aX1qgswZ1PPZSGYKswUkqXhIf2S9aLFkjXW2n61LVzw2ZeqJRQI8QIcmi%2fF7WHOHLbWScnKwG594WIk0SRiCa0n2aEJAhVlXmzEE%2f5%2f%2bXWsKhlneTLduVs52ST5m96zdx%2bLnNGgDERqznFNu3AT5zvLcN0PyVq08n4keSv2ngLLTZK4QQJslS4he9MT3XJoEUfe9L8beZNh1239eLHYF6w4KWMCWWTfwxdCUOY%3d; unpl=JF8EAJZnNSttDEhSAkwDE0dEGAoEWw8LSh9TbjRVXV5QHFIDGwMfGhd7XlVdXhRKFR9vYxRUXlNIUw4ZBysSEXteVV1YCE0TAGlnNWRtW0tkBCsCHxMWQltTXF8LeycDZ2M1VFxZSlYGGwcTEhhObWRbXQlKFQBpYQVQbVl7VTVNbBsTEUpcVVteDENaA2tmA11bX0lWBisDKxE; __jdv=122270672|jd.idey.cn|t_2024175271_|tuiguang|e276f09debfa4c209a0ba829f7710596|1647318395561; thor=8D225D1673AA75681B9D3811417B0D325568BB2DD7F2729798D3AECF0428F59F4C39726C44E930AA2DD868FC4BCA33EA0D52228F39A68FC9F5C1157433CAACF1110B20B6975502864453B70E6B21C0ED165B733359002643CD05BDBA37E4A673AF38CC827B6013BCB5961ADA022E57DB6811E99E10E9C4E6410D844CD129071F7646EC7CE120A0B3D2F768020B044A010452D9F8ABD67A59D41880DD1991935C; 3AB9D23F7A4B3C9B=24HI5ARAA3SK7RJERTWUDZKA2NYJIXX3ING24VG466VC3ANKUALJLLD7VBYLQ3QPRYUSO3R6QBJYLVTVXBDIGJLGBA; __jdb=122270672.5.1507876332|22.1647318046; shshshsID=d7a96097b296c895558adfd840546a72_5_1647318650562",
"referer": "https://search.jd.com/"
} def crawlProductComment(url):
# 读取原始数据
try:
req = requests.get(url=url, headers=headers2).text
reqs = req.replace("fetchJSON_comment98(", "").strip(');')
print(reqs)
jsondata = json.loads(reqs)
# 遍历商品评论列表
comments = jsondata['comments']
return comments
except IOError:
print("Error: gbk不合适")
def getProduct(url):
# 爬取商品id
ids = []
req = requests.get(url=url, headers=headers2).text
reqs = req.replace("jQuery1544821(", "").strip(')')
jsondata = json.loads(reqs)['291']# 解析文件
for i in range(0, len(jsondata)):
ids.append(jsondata[i]['sku_id'])
print(ids)
return ids
# 将productid写成list形式
ids = []
for i in range(0,10):
product_id = getProduct(
"https://search-x.jd.com/Search?callback=jQuery1544821&area=5&enc=utf-8&keyword=%E7%94%B7%E5%A3%AB%E8%BF%90%E5%8A%A8%E9%9E%8B&adType=7&page="+str(i)+"&ad_ids=291%3A33&xtest=new_search&_=1647325621019")
time.sleep(random.randint(1, 3))
ids.append(product_id) data = []
count = 0
# 去除重复productid,加快爬虫速度
for k in list(set(itertools.chain.from_iterable(ids))):
for i in range(0, 100):
# 通过更改page参数的值来循环读取多页评论信息
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=' + str(
k) + '&score=1&sortType=5&page=' \
+ str(i) + '&pageSize=10&isShadowSku=0&fold=1'
comments = crawlProductComment(url)
if len(comments) <= 0:
break
print(comments)
data.extend(comments)
# 设置休眠时间
time.sleep(random.randint(1, 5))
print('-------', i) print("这是第{}类商品".format(count))
# 每爬取一个商品就保存一个文件,防止爬虫中途中断(不建议使用追加,因为不同商品爬虫时生成的json文件有多个中括号,不适合解析)
with open('data2/shoes'+str(count)+'.json', 'w+', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
count += 1
# 保存为最终文件
with open('data/shoes_all.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
三.爬虫结果:
结果以json形式输出,之后需要什么数据,直接解析即可
[{
"id": 16517111016,
"guid": "742b5c0124eb4da7c673f0405cd9b512",
"content": "上个月买了同款网眼的,穿的非常舒服,看到有冬款又买了,做工和穿着舒适度没得说!款式与某国外品牌类似!但价格相差十万八千里!",
"creationTime": "2021-10-25 18:25:44",
"isDelete": false,
"isTop": false,
"userImageUrl": "storage.360buyimg.com/i.imageUpload/6a645f3532393535313732373035373831343931363631383932333836_sma.jpg",
"topped": 0,
"replyCount": 0,
"score": 5,
"imageStatus": 1,
"usefulVoteCount": 0,
"userClient": 4,
"discussionId": 983275343,
"imageCount": 4,
"anonymousFlag": 1,
"plusAvailable": 201,
"mobileVersion": "10.2.0",
"images": [
{
"id": 1577587353,
"imgUrl": "//img30.360buyimg.com/n0/s128x96_jfs/t1/135814/13/20705/98256/61768626E72015f0f/167476690ac02dea.jpg",
"imgTitle": "",
"status": 0
},
{
"id": 1577587354,
"imgUrl": "//img30.360buyimg.com/n0/s128x96_jfs/t1/162488/7/27962/106230/61768627Ed0036d75/6e6987536e0bc545.jpg",
"imgTitle": "",
"status": 0
},
{
"id": 1577587355,
"imgUrl": "//img30.360buyimg.com/n0/s128x96_jfs/t1/156456/26/25453/120365/61768627E7cb4ead7/4030e3fe60102e8d.jpg",
"imgTitle": "",
"status": 0
},
{
"id": 1577587356,
"imgUrl": "//img30.360buyimg.com/n0/s128x96_jfs/t1/200969/9/13143/81333/61768628E2433528c/8a7607cae7c80ce4.jpg",
"imgTitle": "",
"status": 0
}
],
"mergeOrderStatus": 2,
"productColor": "黑色竖口系带",
"productSize": "39",
"textIntegral": 40,
"imageIntegral": 40,
"status": 1,
"referenceId": "30424977080",
"referenceTime": "2021-10-08 21:17:48",
"nickname": "****3",
"replyCount2": 0,
"userImage": "storage.360buyimg.com/i.imageUpload/6a645f3532393535313732373035373831343931363631383932333836_sma.jpg",
"orderId": 0,
"integral": 80,
"productSales": "[]",
"referenceImage": "jfs/t1/130672/22/26171/157596/622e31d5E051db120/2c09c9b8c5711f0b.jpg",
"referenceName": "金利来男鞋休闲运动皮鞋真皮软底英伦鞋子潮流户外旅游鞋波鞋男运动鞋 黑色竖口系带 41",
"firstCategory": 11729,
"secondCategory": 11730,
"thirdCategory": 6908,
"aesPin": null,
"days": 17,
"afterDays": 0
}]
python爬取京东评论的更多相关文章
- 使用Python 爬取 京东 ,淘宝。 商品详情页的数据。(避开了反爬虫机制)
以下是爬取京东商品详情的Python3代码,以excel存放链接的方式批量爬取.excel如下 代码如下 from selenium import webdriver from lxml import ...
- 毕设二:python 爬取京东的商品评论
# -*- coding: utf-8 -*- # @author: Tele # @Time : 2019/04/14 下午 3:48 # 多线程版 import time import reque ...
- 票房和口碑称霸国庆档,用 Python 爬取猫眼评论区看看电影《我和我的家乡》到底有多牛
今年的国庆档电影市场的表现还是比较强势的,两名主力<我和我的家乡>和<姜子牙>起到了很好的带头作用. <姜子牙>首日破 2 亿,一举刷新由<哪吒之魔童降世&g ...
- python爬取京东价格
昨天准备爬取一个京东商品的价格,正则写好了一直是空的 后来我去页面里面看了下,价格标签里果然是空的 百度了下,大家都说是js来控制显示价格的 于是去抓包试试,找到了一条mgets的请求 中间很多参数不 ...
- Python爬取新浪微博评论数据,写入csv文件中
因为新浪微博网页版爬虫比较困难,故采取用手机网页端爬取的方式 操作步骤如下: 1. 网页版登陆新浪微博 2.打开m.weibo.cn 3.查找自己感兴趣的话题,获取对应的数据接口链接 4.获取cook ...
- python 爬取京东手机图
初学urllib,高手勿喷... import re import urllib.request #函数:每一页抓取的30张图片 def craw(url,page): imagelist = []# ...
- python爬取网易评论
学习python不久,最近爬的网页都是直接源代码中直接就有的,看到网易新闻的评论时,发现评论时以json格式加载的..... 爬的网页是习大大2015访英的评论页http://comment.news ...
- python制作爬虫爬取京东商品评论教程
作者:蓝鲸 类型:转载 本文是继前2篇Python爬虫系列文章的后续篇,给大家介绍的是如何使用Python爬取京东商品评论信息的方法,并根据数据绘制成各种统计图表,非常的细致,有需要的小伙伴可以参考下 ...
- 用Python爬取了三大相亲软件评论区,结果...
小三:怎么了小二?一副愁眉苦脸的样子. 小二:唉!这不是快过年了吗,家里又催相亲了 ... 小三:现在不是流行网恋吗,你可以试试相亲软件呀. 小二:这玩意靠谱吗? 小三:我也没用过,你自己看看软件评论 ...
随机推荐
- VM虚拟机 Ubuntu配置与ssh连接
VMware安装ubuntu 自定义 不作更改 选择稍后安装操作系统,相当于裸机,没装系统. 选择ubuntu64 选择虚拟机名字与保存路径 配置情况 2G即可 网络类型,选择NAT 可以了解一下这几 ...
- JZ-049-把字符串转换成整数
把字符串转换成整数 题目描述 将一个字符串转换成一个整数,要求不能使用字符串转换整数的库函数. 数值为0或者字符串不是一个合法的数值则返回0 输入描述: 输入一个字符串,包括数字字母符号,可以为空 返 ...
- mybatis 基本配置 学习总结01
Mybatis 1.什么是Mybatis Mybatis是一款优秀的持久层框架. 几乎避免了所有JDBC代码和手动设置参数以及获取结果集的过程. Mybatis是一个半自动化的ORM框架(Object ...
- Jira8.0.2安装及破解
最近开发部总监需要部署JIRA管理项目,就安装了一个JIRA8.5.7版安装并破解后,有天断电重启了,发现启动不了提示连接不上数据库.后来我又换了台机器重新安装后又进行了重启发现此破解版本存在问题.并 ...
- 9.Flink实时项目之订单宽表
1.需求分析 订单是统计分析的重要的对象,围绕订单有很多的维度统计需求,比如用户.地区.商品.品类.品牌等等.为了之后统计计算更加方便,减少大表之间的关联,所以在实时计算过程中将围绕订单的相关数据整合 ...
- python3输出由1、2、3、4这四个数字组成的每位数都不相同的所有三位数
for i in range(1,5): for j in range(1,5): for k in range(1,5): if(i!=j and i!=k and j!=k): print(i*1 ...
- Django模块导入
Django模块导入篇 Django基础 urls.py 导入app中的视图函数 from app名字 import views app.view视图函数中导入models.py中的类 from ap ...
- 放在initramfs的ko会先加载,还是/lib/modules/下面的ko会先加载?
如果是在switchroot时加载,用的是initramfs,在switchroot后,用的是硬盘上的,有些ko放到initramfs中,但是switchroot前不加载的话,用的还是硬盘上的,关键看 ...
- IC设计基础
一 前言 这一周连续两场线下面试,紧接着又是微信视频面试,从连续三天的面试中,收获颇丰! 存在的问题: 一是对项目细节模糊: 二是IC基础知识薄弱: 具体表现是,在面试过程中,如被问到DDR3和千兆以 ...
- STL基本用法的一些记录
迭代器 (set类型)::iterator 就是迭代器 迭代器可以看成stl容器内元素的指针 set 默认从小到大排序 begin() set中最小的元素的迭代器 end() set中最大的元素的迭代 ...