【Redis】集群数据迁移
Redis通过对KEY计算hash,将KEY映射到slot,集群中每个节点负责一部分slot的方式管理数据,slot最大个数为16384。
在集群节点对应的结构体变量clusterNode中可以看到slots数组,数组的大小为CLUSTER_SLOTS除以8,CLUSTER_SLOTS的值是16384:
#define CLUSTER_SLOTS 16384
typedef struct clusterNode {
unsigned char slots[CLUSTER_SLOTS/8];
// 省略...
} clusterNode;
因为一个字符占8位,所以数组个数为16384除以8,每一位可以表示一个slot,如果某一位的值为1,表示当前节点负责这一位对应的slot。
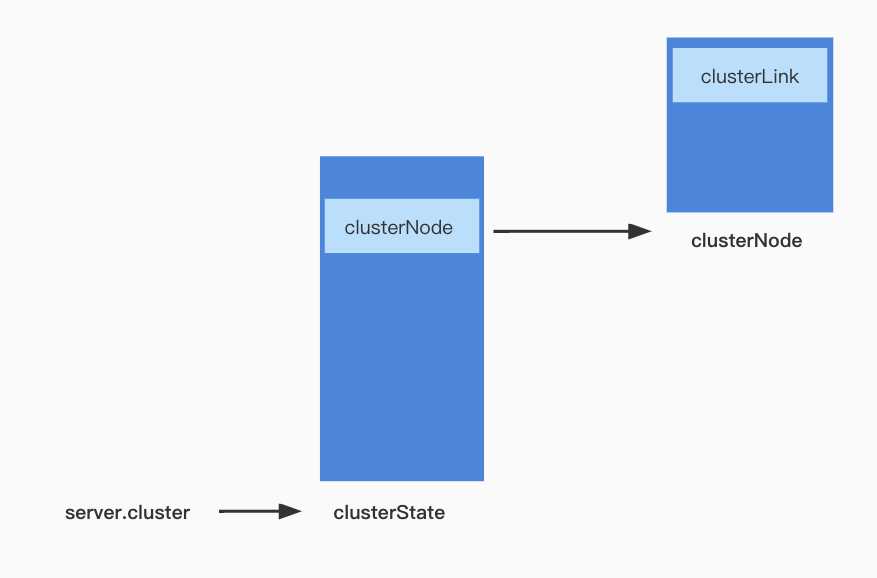
clusterState
clusterNode里面保存了节点相关的信息,集群数据迁移信息并未保存在clusterNode中,而是使用了clusterState结构体来保存:
- migrating_slots_to数组: 记录当前节点负责的slot迁移到了哪个节点
- importing_slots_from数组: 记录当前节点负责的slot是从哪个节点迁入的
- slots数组:记录每个slot是由哪个集群节点负责的
- slots_keys_count:slot中key的数量
- slots_to_keys:是一个字典树,记录KEY和SLOT的对应关系
typedef struct clusterState {
clusterNode *myself; /* 当前节点自己 */
clusterNode *migrating_slots_to[CLUSTER_SLOTS];
clusterNode *importing_slots_from[CLUSTER_SLOTS];
clusterNode *slots[CLUSTER_SLOTS];
uint64_t slots_keys_count[CLUSTER_SLOTS];
rax *slots_to_keys;
// ...
} clusterState;
clusterState与clusterNode的关系
集群数据迁移
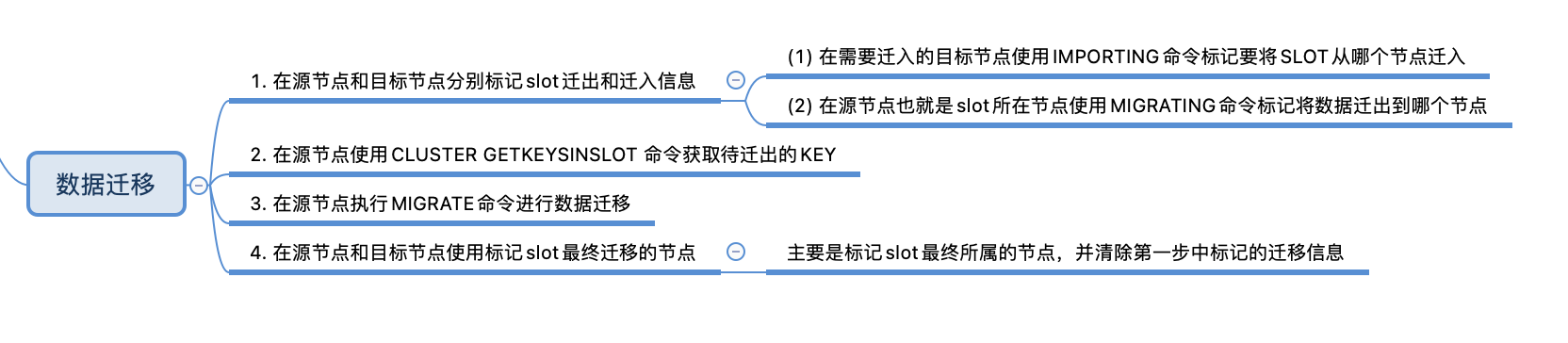
在手动进行数据迁移时,需要执行以下步骤:
- 在源节点和目标节点分别使用
CLUSTER SETSLOT MIGRATING和CLUSTER SETSLOT IMPORTING标记slot迁出和迁入信息 - 在源节点使用
CLUSTER GETKEYSINSLOT命令获取待迁出的KEY - 在源节点执行
MIGRATE命令进行数据迁移,MIGRATE既支持单个KEY的迁移,也支持多个KEY的迁移 - 在源节点和目标节点使用
CLUSTER SETSLOT命令标记slot最终迁移节点
标记数据迁移节点
在进行数据迁移之前,首先在需要迁入的目标节点使用SETSLOT命令标记要将SLOT从哪个节点迁入到当前节点:
- :哈希槽的值
- :表示slot所在的节点
CLUSTER SETSLOT <slot> IMPORTING <node>
然后在源节点也就是slot所在节点使用MIGRATING命令标记将数据迁出到哪个节点:
- :哈希槽的值
- :表示slot要迁出到的目标节点
CLUSTER SETSLOT <slot> MIGRATING <node>
比如slot1当前在node1中,需要将slot1迁出到node2,那么首先在nodd2上执行IMPORTING命令,标记slot准备从node1迁到当前节点node2中:
CLUSTER SETSLOT slot1 IMPORTING node1
然后在node1中执行MIGRATING命令标记slot1需要迁移到node2:
CLUSTER SETSLOT slot1 MIGRATING node2
clusterCommand
SETSLOT命令的处理在clusterCommand函数(cluster.c文件中)中:
- 校验当前节点是否是从节点,如果当前节点是从节点,返回错误,
SETSLOT只能用于主节点 - 如果是
migrating命令,表示slot需要从当前节点迁出到其他节点,处理如下:
(1) 如果需要迁移的slot不在当前节点,返回错误
(2)如果要迁移到的目标slot节点未查询到,返回错误
(3)将当前节点的migrating_slots_to[slot]的值置为迁出到的目标节点,记录slot迁移到了哪个节点 - 如果是
importing命令,表示slot需要从其他节点迁入到当前节点
(1)如果要迁移的slot已经在当前节点,返回slot数据已经在当前节点的响应
(2)由于importing需要从slot所在节点迁移到当前节点,如果未从集群中查询slot当前所在节点,返回错误信息
(3)将当前节点的importing_slots_from[slot]置为slot所在节点,记录slot是从哪个节点迁入到当前节点的
void clusterCommand(client *c) {
if (server.cluster_enabled == 0) {
addReplyError(c,"This instance has cluster support disabled");
return;
}
if (c->argc == 2 && !strcasecmp(c->argv[1]->ptr,"help")) {
// ...
}
// ...
else if (!strcasecmp(c->argv[1]->ptr,"setslot") && c->argc >= 4) { // 处理setslot命令
int slot;
clusterNode *n;
// 如果当前节点是从节点,返回错误,SETSLOT只能用于主节点
if (nodeIsSlave(myself)) {
addReplyError(c,"Please use SETSLOT only with masters.");
return;
}
// 查询slot
if ((slot = getSlotOrReply(c,c->argv[2])) == -1) return;
// 处理migrating迁出
if (!strcasecmp(c->argv[3]->ptr,"migrating") && c->argc == 5) {
// 如果需要迁移的slot不在当前节点,返回错误
if (server.cluster->slots[slot] != myself) {
addReplyErrorFormat(c,"I'm not the owner of hash slot %u",slot);
return;
}
// 如果要迁移到的目标节点未查询到,返回错误
if ((n = clusterLookupNode(c->argv[4]->ptr)) == NULL) {
addReplyErrorFormat(c,"I don't know about node %s",
(char*)c->argv[4]->ptr);
return;
}
// 将当前节点的migrating_slots_to[slot]置为目标节点,记录slot要迁移到的节点
server.cluster->migrating_slots_to[slot] = n;
} else if (!strcasecmp(c->argv[3]->ptr,"importing") && c->argc == 5) { // 处理importing迁入
// 如果要迁移的slot已经在当前节点
if (server.cluster->slots[slot] == myself) {
addReplyErrorFormat(c,
"I'm already the owner of hash slot %u",slot);
return;
}
// importing需要从slot所在节点迁移到当前节点,如果未从集群中查询slot当前所在节点,返回错误信息
if ((n = clusterLookupNode(c->argv[4]->ptr)) == NULL) {
addReplyErrorFormat(c,"I don't know about node %s",
(char*)c->argv[4]->ptr);
return;
}
// 记录slot是从哪个节点迁移过来的
server.cluster->importing_slots_from[slot] = n;
}
// 省略其他if else
// ...
else {
addReplyError(c,
"Invalid CLUSTER SETSLOT action or number of arguments. Try CLUSTER HELP");
return;
}
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|CLUSTER_TODO_UPDATE_STATE);
addReply(c,shared.ok);
}
// ...
else {
addReplySubcommandSyntaxError(c);
return;
}
}
获取待迁出的key
在标记完迁入、迁出节点后,就可以使用CLUSTER GETKEYSINSLOT 命令获取待迁出的KEY:
:哈希槽的值
:迁出KEY的数量
CLUSTER GETKEYSINSLOT <slot> <count>
getkeysinslot命令的处理也在clusterCommand函数中,处理逻辑如下:
- 从命令中解析slot的值以及count的值,count的值记为maxkeys,并校验合法性
- 调用countKeysInSlot函数获取slot中key的数量,与maxkeys对比,如果小于maxkeys,就将maxkeys的值更新为slot中key的数量
- 根据获取key的个数分配相应的内存空间
- 从slot中获取key并将数据返回给客户端
void clusterCommand(client *c) {
if (server.cluster_enabled == 0) {
addReplyError(c,"This instance has cluster support disabled");
return;
}
if (c->argc == 2 && !strcasecmp(c->argv[1]->ptr,"help")) {
// ...
}
// ...
else if (!strcasecmp(c->argv[1]->ptr,"getkeysinslot") && c->argc == 4) {
/* CLUSTER GETKEYSINSLOT <slot> <count> */
long long maxkeys, slot;
unsigned int numkeys, j;
robj **keys;
// 从命令中获取slot的值并转为长整型
if (getLongLongFromObjectOrReply(c,c->argv[2],&slot,NULL) != C_OK)
return;
// 从命令中获取key的最大个数并转为长整型
if (getLongLongFromObjectOrReply(c,c->argv[3],&maxkeys,NULL)
!= C_OK)
return;
// 如果slot的值小于0或者大于CLUSTER_SLOTS或者key的最大个数为0
if (slot < 0 || slot >= CLUSTER_SLOTS || maxkeys < 0) {
addReplyError(c,"Invalid slot or number of keys");
return;
}
// 计算slot中key的数量
unsigned int keys_in_slot = countKeysInSlot(slot);
// 如果maxkeys大于slot中key的数量,更新maxkeys的值为slot中key的数量
if (maxkeys > keys_in_slot) maxkeys = keys_in_slot;
// 分配空间
keys = zmalloc(sizeof(robj*)*maxkeys);
// 从slot中获取key
numkeys = getKeysInSlot(slot, keys, maxkeys);
addReplyArrayLen(c,numkeys);
for (j = 0; j < numkeys; j++) {
// 返回key
addReplyBulk(c,keys[j]);
decrRefCount(keys[j]);
}
zfree(keys);
}
// ...
else {
addReplySubcommandSyntaxError(c);
return;
}
}
数据迁移
源节点数据迁移
完成上两步之后,接下来需要在源节点中执行MIGRATE命令进行数据迁移,MIGRATE既支持单个KEY的迁移,也支持多个KEY的迁移,语法如下:
# 单个KEY
MIGRATE host port key dbid timeout [COPY | REPLACE | AUTH password | AUTH2 username password]
# 多个KEY
MIGRATE host port "" dbid timeout [COPY | REPLACE | AUTH password | AUTH2 username password] KEYS key2 ... keyN
- host:ip地址
- Port:端口
- key:迁移的key
- KEYS:如果一次迁移多个KEY,使用KEYS,后跟迁移的key1 ... keyN
- dbid:数据库id
- COPY:如果目标节点已经存在迁移的key,则报错,如果目标节点不存在迁移的key,则正常进行迁移,在迁移完成后删除源节点中的key
- REPLACE:如果目标节点不存在迁移的key,正常进行迁移,如果目标节点存在迁移的key,进行替换,覆盖目标节点中已经存在的key
- AUTH:验证密码
migrateCommand
MIGRATE命令对应的处理函数在migrateCommand中(cluster.c文件中),处理逻辑如下:
- 解析命令中的参数,判断是否有replace、auth、keys等参数
- 如果有replace参数,表示在迁移数据时如果key已经在目标节点存在,进行替换
- 如果有keys参数,表示命令中有多个key,计算命令中key的个数记为num_keys
- 处理命令中解析到的所有key,调用lookupKeyRead函数查找key:
- 如果查找到,将key放入kv对象中,kv中存储实际要处理的KEY,value放入ov对象中,ov中存储key对应的value
- 如果未查找到key,跳过当前key,处理下一个key
- 因为有部分key可能未查询到,所以更新实际需要处理的key的数量num_keys
- 根据命令中的ip端口信息,与目标节点建立连接
- 调用rioInitWithBuffer函数初始化一块缓冲区
- 处理实际需要迁移的key,主要是将数据填入缓冲区
- 根据key获取过期时间,如果已过期不进行处理
- 判断是否开启了集群,如果开启了集群将
RESTORE-ASKING写入缓冲区,如果未开启,写入RESTORE命令 - 将key写入缓冲区
- **调用createDumpPayload函数,创建payload,将RDB版本、CRC64校验和以及value内容写入 **,目标节点收到数据时需要进行校验
- 将payload数据填充到缓冲区
- 将缓冲区的数据按照64K的块大小发送到目标节点
void migrateCommand(client *c) {
// 省略...
robj **ov = NULL; /* 保存要迁移的key对应的value */
robj **kv = NULL; /* 保存要迁移的key. */
int first_key = 3; /* 第一个key */
int num_keys = 1; /* 迁移key的数量 */
/* 解析命令中的参数 */
for (j = 6; j < c->argc; j++) {
int moreargs = (c->argc-1) - j;
// 如果是copy
if (!strcasecmp(c->argv[j]->ptr,"copy")) {
copy = 1;
} else if (!strcasecmp(c->argv[j]->ptr,"replace")) { // 如果是replace
replace = 1;
} else if (!strcasecmp(c->argv[j]->ptr,"auth")) { // 如果需要验证密码
if (!moreargs) {
addReplyErrorObject(c,shared.syntaxerr);
return;
}
j++;
// 获取密码
password = c->argv[j]->ptr;
redactClientCommandArgument(c,j);
} else if (!strcasecmp(c->argv[j]->ptr,"auth2")) {
// ...
} else if (!strcasecmp(c->argv[j]->ptr,"keys")) { // 如果一次迁移多个key
if (sdslen(c->argv[3]->ptr) != 0) {
addReplyError(c,
"When using MIGRATE KEYS option, the key argument"
" must be set to the empty string");
return;
}
// 或取第一个key
first_key = j+1;
// 计算key的数量
num_keys = c->argc - j - 1;
break; /* All the remaining args are keys. */
} else {
addReplyErrorObject(c,shared.syntaxerr);
return;
}
}
/* 校验timeout和dbid的值 */
if (getLongFromObjectOrReply(c,c->argv[5],&timeout,NULL) != C_OK ||
getLongFromObjectOrReply(c,c->argv[4],&dbid,NULL) != C_OK)
{
return;
}
// 如果超时时间小于0,默认设置1000毫秒
if (timeout <= 0) timeout = 1000;
// 分配空间,kv记录在源节点中实际查找到的key
ov = zrealloc(ov,sizeof(robj*)*num_keys);
kv = zrealloc(kv,sizeof(robj*)*num_keys);
int oi = 0;
// 处理KEY
for (j = 0; j < num_keys; j++) {
// 如果可以从源节点查找到key
if ((ov[oi] = lookupKeyRead(c->db,c->argv[first_key+j])) != NULL) {
// 记录查找到的key
kv[oi] = c->argv[first_key+j];
// 记录查找到的个数
oi++;
}
}
// 只处理实际查找到的key
num_keys = oi;
// 如果为0,不进行处理
if (num_keys == 0) {
zfree(ov); zfree(kv); // 释放空间
addReplySds(c,sdsnew("+NOKEY\r\n")); // 返回NOKEY响应
return;
}
try_again:
write_error = 0;
/* 与目标节点建立连接 */
cs = migrateGetSocket(c,c->argv[1],c->argv[2],timeout);
if (cs == NULL) {
zfree(ov); zfree(kv);
return; /* error sent to the client by migrateGetSocket() */
}
// 初始化缓冲区
rioInitWithBuffer(&cmd,sdsempty());
/* 如果密码不为空,验证密码 */
if (password) {
int arity = username ? 3 : 2;
serverAssertWithInfo(c,NULL,rioWriteBulkCount(&cmd,'*',arity));
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"AUTH",4));
if (username) {
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,username,
sdslen(username)));
}
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,password,
sdslen(password)));
}
// ...
// 处理KEY,只保留未过期的KEY
for (j = 0; j < num_keys; j++) {
long long ttl = 0;
// 获取KEY的过期时间,返回-1表示未设置过期时间,否则返回过期时间
long long expireat = getExpire(c->db,kv[j]);
// 如果设置了过期时间
if (expireat != -1) {
// 计算ttl:过期时间减去当前时间
ttl = expireat-mstime();
// 如果已过期
if (ttl < 0) {
continue;
}
if (ttl < 1) ttl = 1;
}
/* 记录未过期的KEY */
ov[non_expired] = ov[j];
kv[non_expired++] = kv[j];
serverAssertWithInfo(c,NULL,
rioWriteBulkCount(&cmd,'*',replace ? 5 : 4));
// 是否启用集群
if (server.cluster_enabled)
serverAssertWithInfo(c,NULL,
rioWriteBulkString(&cmd,"RESTORE-ASKING",14)); // 将RESTORE-ASKING命令写入缓冲区
else
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"RESTORE",7)); // 如果未开启集群将RESTORE命令写入缓冲区
serverAssertWithInfo(c,NULL,sdsEncodedObject(kv[j]));
// 将key写入缓冲区
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,kv[j]->ptr,
sdslen(kv[j]->ptr)));
// 将ttl写入缓存区
serverAssertWithInfo(c,NULL,rioWriteBulkLongLong(&cmd,ttl));
/* 创建payload,将RDB版本、CRC64校验和以及value内容写入 */
createDumpPayload(&payload,ov[j],kv[j]);
// 将payload数据写入缓冲区
serverAssertWithInfo(c,NULL,
rioWriteBulkString(&cmd,payload.io.buffer.ptr,
sdslen(payload.io.buffer.ptr)));
sdsfree(payload.io.buffer.ptr);
/* 如果设置了REPLACE参数,将REPLACE写入缓冲区 */
if (replace)
serverAssertWithInfo(c,NULL,rioWriteBulkString(&cmd,"REPLACE",7));
}
/* 更新实际需要处理的key */
num_keys = non_expired;
/* 将缓冲区的数据按照64K的块大小发送到目标节点 */
errno = 0;
{
sds buf = cmd.io.buffer.ptr;
size_t pos = 0, towrite;
int nwritten = 0;
while ((towrite = sdslen(buf)-pos) > 0) {
// 需要发送的数据,如果超过了64K就按照64K的大小发送
towrite = (towrite > (64*1024) ? (64*1024) : towrite);
// 发送数据
nwritten = connSyncWrite(cs->conn,buf+pos,towrite,timeout);
if (nwritten != (signed)towrite) {
write_error = 1;
goto socket_err;
}
pos += nwritten;
}
}
// 省略...
}
createDumpPayload
createDumpPayload函数在cluster.c文件中:
/* -----------------------------------------------------------------------------
* DUMP, RESTORE and MIGRATE commands
* -------------------------------------------------------------------------- */
void createDumpPayload(rio *payload, robj *o, robj *key) {
unsigned char buf[2];
uint64_t crc;
// 初始化缓冲区
rioInitWithBuffer(payload,sdsempty());
// 将value的数据类型写入缓冲区
serverAssert(rdbSaveObjectType(payload,o));
// 将value写入缓冲区
serverAssert(rdbSaveObject(payload,o,key));
/* Write the footer, this is how it looks like:
* ----------------+---------------------+---------------+
* ... RDB payload | 2 bytes RDB version | 8 bytes CRC64 |
* ----------------+---------------------+---------------+
* RDB version and CRC are both in little endian.
*/
/* 设置RDB版本 */
buf[0] = RDB_VERSION & 0xff;
buf[1] = (RDB_VERSION >> 8) & 0xff;
payload->io.buffer.ptr = sdscatlen(payload->io.buffer.ptr,buf,2);
/* 设置CRC64校验和用于校验数据 */
crc = crc64(0,(unsigned char*)payload->io.buffer.ptr,
sdslen(payload->io.buffer.ptr));
memrev64ifbe(&crc);
payload->io.buffer.ptr = sdscatlen(payload->io.buffer.ptr,&crc,8);
}
目标节点处理数据
restoreCommand
目标节点收到迁移的数据的处理逻辑在restoreCommand中(cluster.c文件中):
- 解析请求中的参数,判断是否有replace
- 如果没有replace并且key已经在当前节点存在,返回错误信息
- 调用verifyDumpPayload函数校验RDB版本和CRC校验和
- 从请求中解析value的数据类型和value值
- 如果设置了
replace先删除数据库中存在的key - 将key和vlaue添加到节点的数据库中
/* RESTORE key ttl serialized-value [REPLACE] */
void restoreCommand(client *c) {
long long ttl, lfu_freq = -1, lru_idle = -1, lru_clock = -1;
rio payload;
int j, type, replace = 0, absttl = 0;
robj *obj;
/* 解析请求中的参数 */
for (j = 4; j < c->argc; j++) {
int additional = c->argc-j-1;
if (!strcasecmp(c->argv[j]->ptr,"replace")) { // 如果有replace
replace = 1; // 标记
}
// ...
else {
addReplyErrorObject(c,shared.syntaxerr);
return;
}
}
/* 如果没有replace并且key已经在数据库存在,返回错误信息 */
robj *key = c->argv[1];
if (!replace && lookupKeyWrite(c->db,key) != NULL) {
addReplyErrorObject(c,shared.busykeyerr);
return;
}
/* Check if the TTL value makes sense */
if (getLongLongFromObjectOrReply(c,c->argv[2],&ttl,NULL) != C_OK) {
return;
} else if (ttl < 0) {
addReplyError(c,"Invalid TTL value, must be >= 0");
return;
}
/* 校验RDB版本和CRC */
if (verifyDumpPayload(c->argv[3]->ptr,sdslen(c->argv[3]->ptr)) == C_ERR)
{
addReplyError(c,"DUMP payload version or checksum are wrong");
return;
}
rioInitWithBuffer(&payload,c->argv[3]->ptr);
// 解析value的数据类型和value值
if (((type = rdbLoadObjectType(&payload)) == -1) ||
((obj = rdbLoadObject(type,&payload,key->ptr)) == NULL))
{
addReplyError(c,"Bad data format");
return;
}
int deleted = 0;
// 如果设置了replace
if (replace)
deleted = dbDelete(c->db,key); // 先删除数据库中存在的key
if (ttl && !absttl) ttl+=mstime();
if (ttl && checkAlreadyExpired(ttl)) {
if (deleted) {
rewriteClientCommandVector(c,2,shared.del,key);
signalModifiedKey(c,c->db,key);
notifyKeyspaceEvent(NOTIFY_GENERIC,"del",key,c->db->id);
server.dirty++;
}
decrRefCount(obj);
addReply(c, shared.ok);
return;
}
/* 将key和vlaue添加到节点的数据库中 */
dbAdd(c->db,key,obj);
if (ttl) {
setExpire(c,c->db,key,ttl);
}
objectSetLRUOrLFU(obj,lfu_freq,lru_idle,lru_clock,1000);
signalModifiedKey(c,c->db,key);
notifyKeyspaceEvent(NOTIFY_GENERIC,"restore",key,c->db->id);
addReply(c,shared.ok);
server.dirty++;
}
标记迁移结果
数据迁移的最后一步,需要使用CLUSTER SETSLOT命令,在源节点和目标节点执行以下命令,标记slot最终所属的节点,并清除第一步中标记的迁移信息:
:哈希槽
:哈希槽最终所在节点id
CLUSTER SETSLOT <slot> NODE <node>
clusterCommand
CLUSTER SETSLOT <slot> NODE <node>命令的处理依旧在clusterCommand函数中,处理逻辑如下:
- 根据命令中传入的nodeid查找节点记为n,如果未查询到,返回错误信息
- 果slot已经在当前节点,但是根据nodeid查找到的节点n不是当前节点,说明slot所属节点与命令中指定的节点不一致,返回错误信息
- 在源节点上执行命令时,如果slot中key的数量为0,表示slot上的数据都已迁移完毕,而migrating_slots_to[slot]记录了slot迁移到的目标节点,既然数据已经迁移完成此时需要将migrating_slots_to[slot]迁出信息清除
- 调用clusterDelSlot函数先将slot删除
- 获取slot所属节点
- 将slot所属节点ClusterNode结构体中的slots数组对应的标记位取消,表示节点不再负责此slot
- 将slot所属节点ClusterState结构体中的slots数组对应元素置为NULL,表示当前slot所属节点为空
- 调用clusterAddSlot将slot添加到最终所属的节点中
- 在目标节点上执行命令时,如果slot所属节点为当前节点,并且importing_slots_from[slot]不为空, importing_slots_from[slot]中记录了slot是从哪个节点迁移过来,此时数据已经迁移完毕,清除 importing_slots_from[slot]中的迁入信息
void clusterCommand(client *c) {
if (server.cluster_enabled == 0) {
addReplyError(c,"This instance has cluster support disabled");
return;
}
if (c->argc == 2 && !strcasecmp(c->argv[1]->ptr,"help")) {
// ...
}
// ...
else if (!strcasecmp(c->argv[1]->ptr,"setslot") && c->argc >= 4) { // 处理setslot命令
int slot;
clusterNode *n;
if (nodeIsSlave(myself)) {
addReplyError(c,"Please use SETSLOT only with masters.");
return;
}
if ((slot = getSlotOrReply(c,c->argv[2])) == -1) return;
if (!strcasecmp(c->argv[3]->ptr,"migrating") && c->argc == 5) {
// migrating处理
// ...
} else if (!strcasecmp(c->argv[3]->ptr,"importing") && c->argc == 5) {
// importing处理
// ...
} else if (!strcasecmp(c->argv[3]->ptr,"stable") && c->argc == 4) {
// stable处理
// ...
} else if (!strcasecmp(c->argv[3]->ptr,"node") && c->argc == 5) {
/* CLUSTER SETSLOT <SLOT> NODE <NODE ID> 命令处理 */
// 根据nodeid查找节点
clusterNode *n = clusterLookupNode(c->argv[4]->ptr);
// 如果未查询到,返回错误信息
if (!n) {
addReplyErrorFormat(c,"Unknown node %s",
(char*)c->argv[4]->ptr);
return;
}
/* 如果slot已经在当前节点,但是根据node id查找到的节点不是当前节点,返回错误信息*/
if (server.cluster->slots[slot] == myself && n != myself) {
if (countKeysInSlot(slot) != 0) {
addReplyErrorFormat(c,
"Can't assign hashslot %d to a different node "
"while I still hold keys for this hash slot.", slot);
return;
}
}
/* 在源节点上执行命令时 */
/* 如果slot中key的数量为0,表示slot上的数据都已迁移完毕,而migrating_slots_to[slot]记录了slot迁移到的目标节点,既然数据已经迁移完成此时可以将迁移信息清除*/
if (countKeysInSlot(slot) == 0 &&
server.cluster->migrating_slots_to[slot])
server.cluster->migrating_slots_to[slot] = NULL;// 清除迁移信息
// 先删除slot
clusterDelSlot(slot);
// 添加slot到节点n
clusterAddSlot(n,slot);
/* 在目标节点上执行命令时 */
/* 如果slot所属节点为当前节点,并且importing_slots_from[slot]不为空, importing_slots_from[slot]中记录了slot是从哪个节点迁移过来*/
if (n == myself &&
server.cluster->importing_slots_from[slot])
{
/* 更新节点的configEpoch */
if (clusterBumpConfigEpochWithoutConsensus() == C_OK) {
serverLog(LL_WARNING,
"configEpoch updated after importing slot %d", slot);
}
// 清除importing_slots_from[slot]迁移信息
server.cluster->importing_slots_from[slot] = NULL;
/* 广播PONG消息,让其他节点尽快知道slot的最新信息 */
clusterBroadcastPong(CLUSTER_BROADCAST_ALL);
}
} else {
addReplyError(c,
"Invalid CLUSTER SETSLOT action or number of arguments. Try CLUSTER HELP");
return;
}
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|CLUSTER_TODO_UPDATE_STATE);
addReply(c,shared.ok);
}
// ...
else {
addReplySubcommandSyntaxError(c);
return;
}
}
总结
参考
Redis版本:redis-6.2.5
【Redis】集群数据迁移的更多相关文章
- redis集群数据迁移
redis集群数据备份迁移方案 n 迁移环境描述及分析 当前我们面临的数据迁移环境是:集群->集群. 源集群: 源集群为6节点,3主3备 主 备 192.168.112.33:8001 192 ...
- redis集群数据迁移txt版
./redis-trib.rb create --replicas 1 192.168.112.33:8001 192.168.112.33:8002 192.168.112.33:8003 192. ...
- 从零自学Hadoop(17):Hive数据导入导出,集群数据迁移下
阅读目录 序 将查询的结果写入文件系统 集群数据迁移一 集群数据迁移二 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephis ...
- elasticsearch7.5.0+kibana-7.5.0+cerebro-0.8.5集群生产环境安装配置及通过elasticsearch-migration工具做新老集群数据迁移
一.服务器准备 目前有两台128G内存服务器,故准备每台启动两个es实例,再加一台虚机,共五个节点,保证down一台服务器两个节点数据不受影响. 二.系统初始化 参见我上一篇kafka系统初始化:ht ...
- redis集群在线迁移第一篇(数据在线迁移至新集群)实战一
迁移背景:1.原来redis集群在A机房,需要把其迁移到新机房B上来.2.保证现有环境稳定.3.采用在线迁移方式,因为原有redis集群内有大量数据.4.如果是一个全新的redis集群搭建会简单很多. ...
- redis集群在线迁移第二篇(redis迁移后调整主从关系,停掉14机器上的所有从节点)-实战二
变更需求为: 1.调整主从关系,所有节点都调整到10.129.51.30机器上 2.停掉10.128.51.14上的所有redis,14机器关机 14机器下线迁移至新机房,这段时间将不能提供服务. 当 ...
- 从零自学Hadoop(16):Hive数据导入导出,集群数据迁移上
阅读目录 序 导入文件到Hive 将其他表的查询结果导入表 动态分区插入 将SQL语句的值插入到表中 模拟数据文件下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并 ...
- elasticsearch跨集群数据迁移
写这篇文章,主要是目前公司要把ES从2.4.1升级到最新版本7.8,不过现在是7.9了,官方的文档:https://www.elastic.co/guide/en/elasticsearch/refe ...
- Redis集群数据没法拆分时的搭建策略
在上一篇文章中,针对服务器单点.单例.单机存在的问题: 单点故障 容量有限 可支持的连接有限(性能不足) 提出了解决的办法:根据AKF原则搭建集群,大意是先X轴拆分,创建单机的镜像,组成主主.主备.主 ...
随机推荐
- VUE3 之 全局 Mixin 与 自定义属性合并策略 - 这个系列的教程通俗易懂,适合新手
1. 概述 老话说的好:心态决定命运,好心态才能有好的命运. 言归正传,今天我们来聊聊 VUE 中的全局 Mixin 与 自定义属性合并策略. 2. Mixin 的使用 2.1 全局 Mixin 之前 ...
- 安装 UE 源码版
# 安装 UE 源码版 ## 下载安装包 > - 先去 Github 找 UE 官方开源的引擎组(这个需要申请加入) > - 加入后找到开源的源码版项目下载 zip 到本地 > - ...
- 原生微信小程序里类似于计算属性写法
可直接在wxml文件里直接写入直接调用.变量只支持var命名,不支持let const </view> <view class="wx_bgc" ...
- v74.01 鸿蒙内核源码分析(编码方式篇) | 机器指令是如何编码的 | 百篇博客分析OpenHarmony源码
本篇关键词:指令格式.条件域.类型域.操作域.数据指令.访存指令.跳转指令.SVC(软件中断) 内核汇编相关篇为: v74.01 鸿蒙内核源码分析(编码方式) | 机器指令是如何编码的 v75.03 ...
- 爬虫亚马逊Bestselling类别产品数据TOP100
1 # -*- coding: utf-8 -*- 2 # @Time : 2020/9/11 16:23 3 # @Author : Chunfang 4 # @Email : 3470959534 ...
- Ranchar中PostgreSQL容器异常 53100: could not resize shared memory segment ... bytes: No space left on device
问题: 客户查报表时描述查询一天的报表能出来,查询一个月的报表不能出来 分析原因: 从下图的异常中分析是PostgreSQL 的共享内存过小,容器默认的/dev/shm大小为64M 解决方案:调整ra ...
- Elemnt ui 组件封装(table)
<template> <div class="table"> <el-table :data="tableData2" :bord ...
- CoreWCF 1.0 正式发布,支持 .NET Core 和 .NET 5+ 的 WCF
CoreWCF 1.0 正式发布,支持 .NET Core 和 .NET 5+ 的 WCF https://devblogs.microsoft.com/dotnet/corewcf-v1-relea ...
- Vert.X CompositeFuture 用法
CompositeFuture 是一种特殊的 Future,它可以包装一个 Future 列表,从而让一组异步操作并行执行:然后协调这一组操作的结果,作为 CompositeFuture 的结果.本文 ...
- 【Vagrant】启动安装Homestead卡在 SSH auth method: private key
注意:通过查找资料发现,导致这个问题的原因有很多,我的这个情况只能是一个参考. 问题描述 今天在使用虚拟机的时候,由于存放虚拟机的虚拟磁盘(vmdk文件)的逻辑分区容量不足(可用容量为0了).然后在使 ...