对 Pulsar 集群的压测与优化

前言
这段时间在做 MQ(Pulsar)相关的治理工作,其中一个部分内容关于消息队列的升级,比如:
- 一键创建一个测试集群。
- 运行一批测试用例,覆盖我们线上使用到的功能,并输出测试报告。
- 模拟压测,输出测试结果。
本质目的就是想直到新版本升级过程中和升级后对现有业务是否存在影响。
一键创建集群和执行测试用例比较简单,利用了 helm 和 k8s client 的 SDK 把整个流程串起来即可。
压测
其实稍微麻烦一点的是压测,Pulsar 官方本身是有提供一个压测工具;只是功能相对比较单一,只能对某批 topic 极限压测,最后输出测试报告。
最后参考了官方的压测流程,加入了一些实时监控数据,方便分析整个压测过程中性能的变化。
客户端 timeout
随着压测过程中的压力增大,比如压测时间和线程数的提高,客户端会抛出发送消息 timeout 异常。
org.apache.pulsar.client.api.PulsarClientException$TimeoutException:
The producer pulsar-test-212-20 can not send message to the topic persistent://my-tenant/my-ns/perf-topic-0 within given timeout : createdAt 82.964 seconds ago, firstSentAt 8.348 seconds ago, lastSentAt 8.348 seconds ago, retryCount 1
而这个异常在生产业务环境的高峰期偶尔也出现过,这会导致业务数据的丢失;所以正好这次被我复现出来后想着分析下产生的原因以及解决办法。
源码分析客户端
既然是客户端抛出的异常所以就先看从异常点开始看起,其实整个过程和产生的原因并不复杂,如下图:
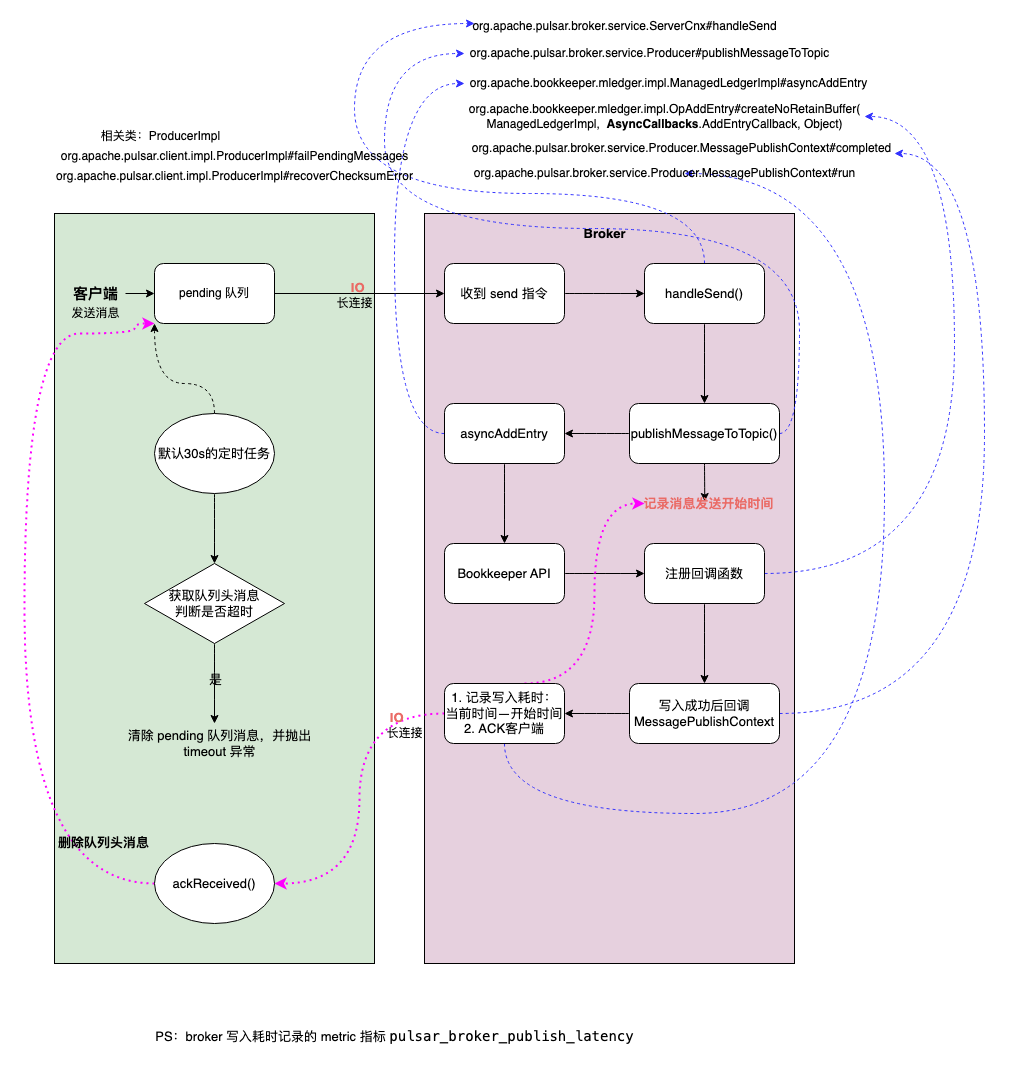
客户端流程:
- 客户端 producer 发送消息时先将消息发往本地的一个 pending 队列。
- 待 broker 处理完(写入 bookkeeper) 返回 ACK 时删除该 pending 队列头的消息。
- 后台启动一个定时任务,定期扫描队列头(头部的消息是最后写入的)的消息是否已经过期(过期时间可配置,默认30s)。
- 如果已经过期(头部消息过期,说明所有消息都已过期)则遍历队列内的消息依次抛出
PulsarClientException$TimeoutException异常,最后清空该队列。
服务端 broker 流程:
- 收到消息后调用 bookkeeper API 写入消息。
- 写入消息时同时写入回调函数。
- 写入成功后执行回调函数,这时会记录一条消息的写入延迟,并通知客户端 ACK。
- 通过 broker metric 指标
pulsar_broker_publish_latency可以获取写入延迟。
从以上流程可以看出,如果客户端不做兜底措施则在第四步会出现消息丢失,这类本质上不算是 broker 丢消息,而是客户端认为当时 broker 的处理能力达到上限,考虑到消息的实时性从而丢弃了还未发送的消息。
性能分析
通过上述分析,特别是 broker 的写入流程得知,整个写入的主要操作便是写入 bookkeeper,所以 bookkeeper 的写入性能便关系到整个集群的写入性能。
极端情况下,假设不考虑网络的损耗,如果 bookkeeper 的写入延迟是 0ms,那整个集群的写入性能几乎就是无上限;所以我们重点看看在压测过程中 bookkeeper 的各项指标。
CPU
首先是 CPU:
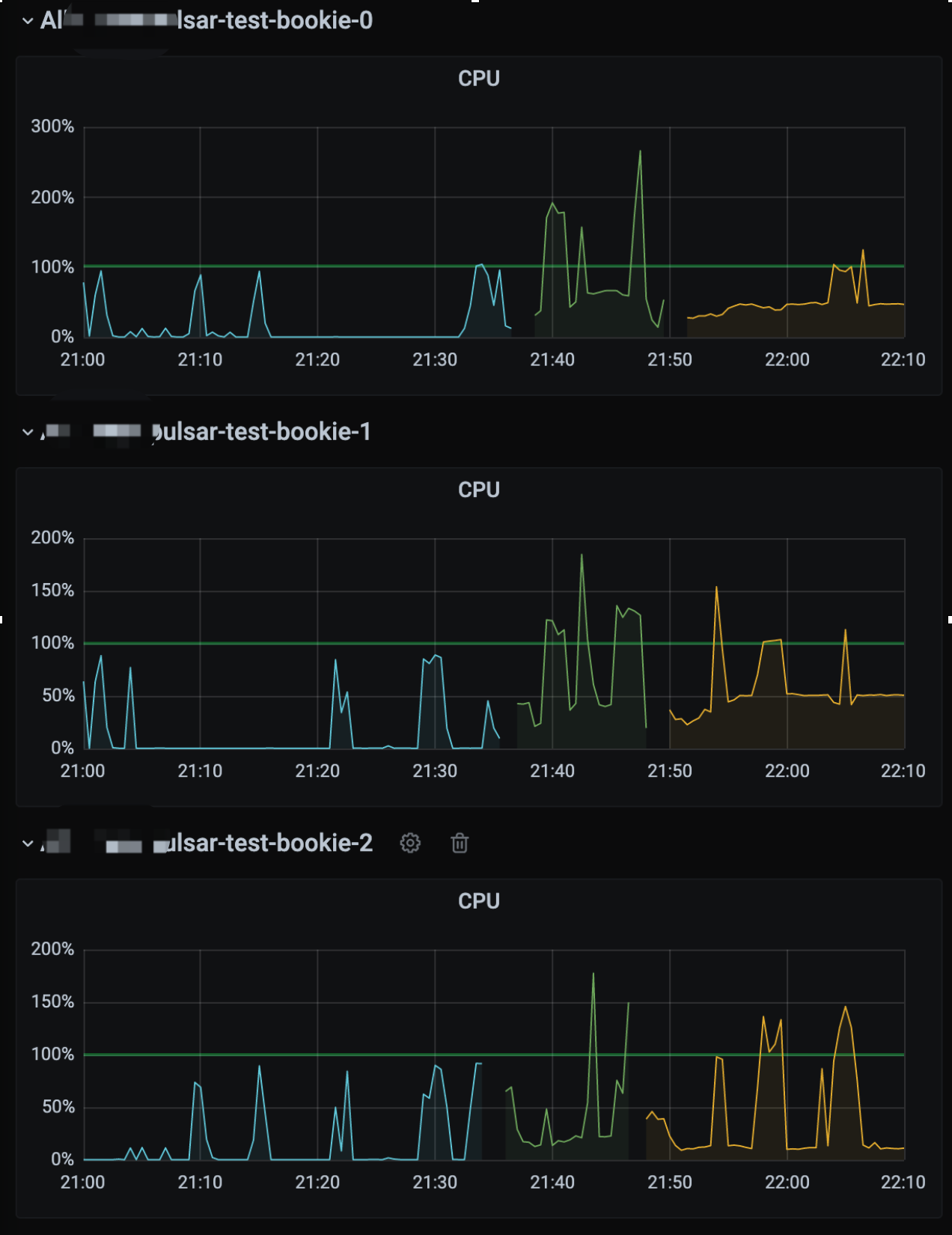
从图中可以看到压测过程中 CPU 是有明显增高的,所以我们需要找到压测过程中 bookkeeper 的 CPU 大部分损耗在哪里?
这里不得不吹一波阿里的 arthas 工具,可以非常方便的帮我们生成火焰图。
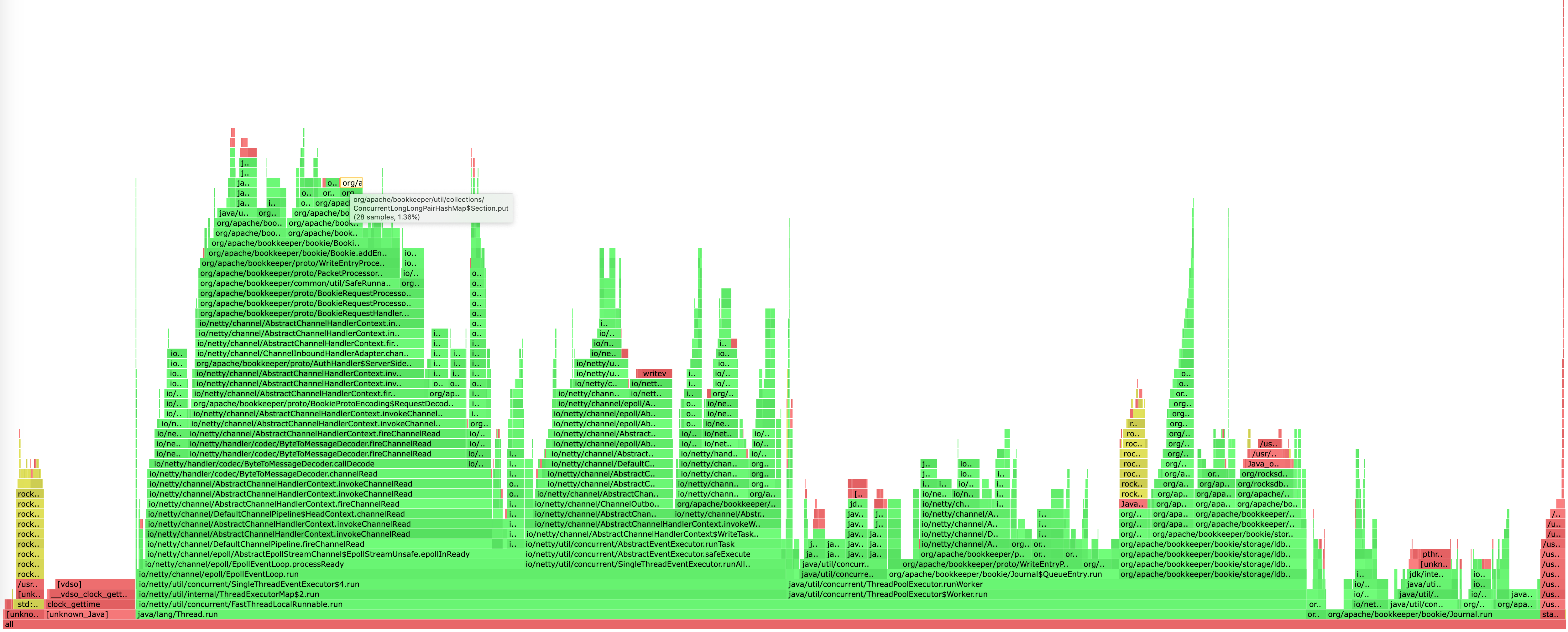
分析火焰图最简单的一个方法便是查看顶部最宽的函数是哪个,它大概率就是性能的瓶颈。
在这个图中的顶部并没有明显很宽的函数,大家都差不多,所以并没有明显损耗 CPU 的函数。
此时在借助云厂商的监控得知并没有得到 CPU 的上限(limit 限制为 8核)。
使用 arthas 过程中也有个小坑,在 k8s 环境中有可能应用启动后没有成功在磁盘写入 pid ,导致查询不到 Java 进程。
$ java -jar arthas-boot.jar
[INFO] arthas-boot version: 3.6.7
[INFO] Can not find java process. Try to pass <pid> in command line.
Please select an available pid.
此时可以直接 ps 拿到进程 ID,然后在启动的时候直接传入 pid 即可。
$ java -jar arthas-boot.jar 1
通常情况下这个 pid 是 1。
磁盘
既然 CPU 没有问题,那就再看看磁盘是不是瓶颈;
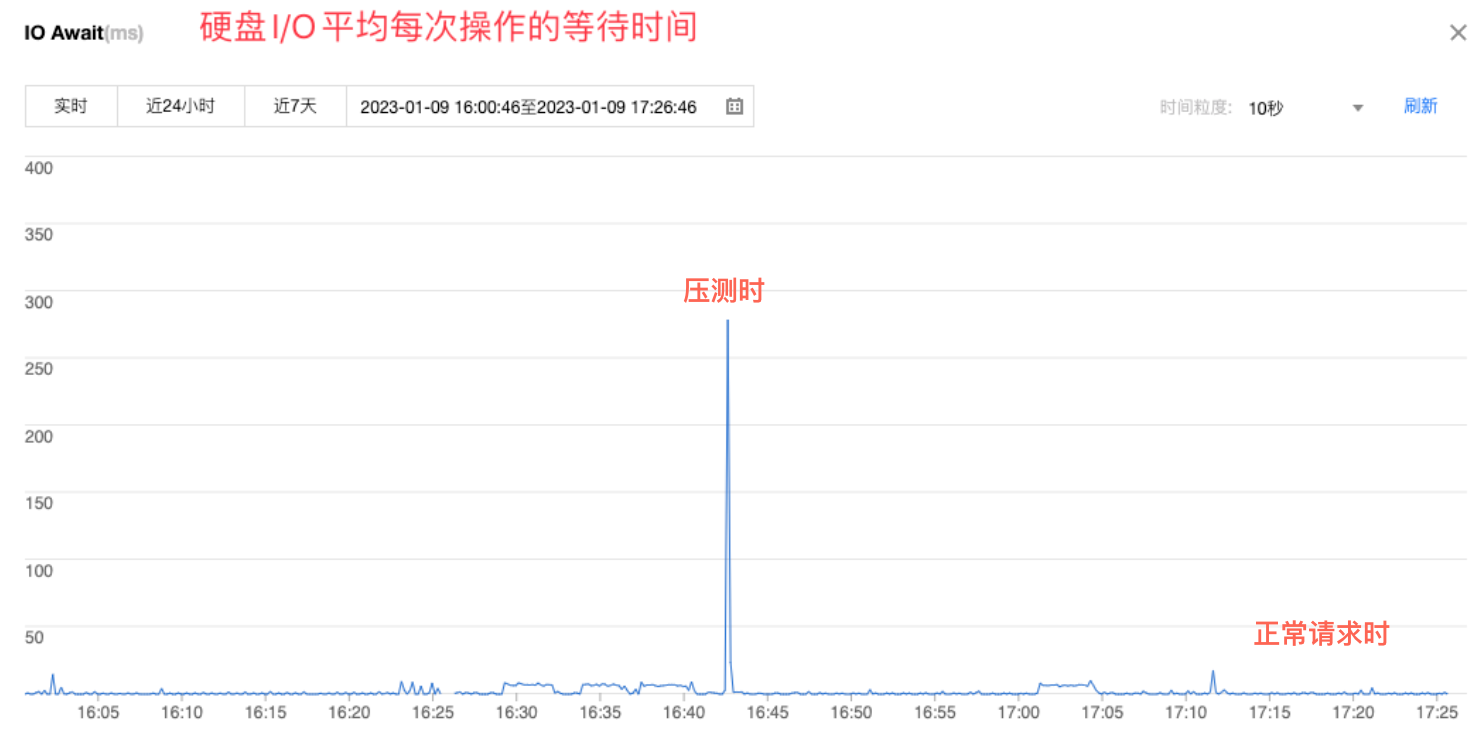
可以看到压测时的 IO 等待时间明显是比日常请求高许多,为了最终确认是否是磁盘的问题,再将磁盘类型换为 SSD 进行测试。
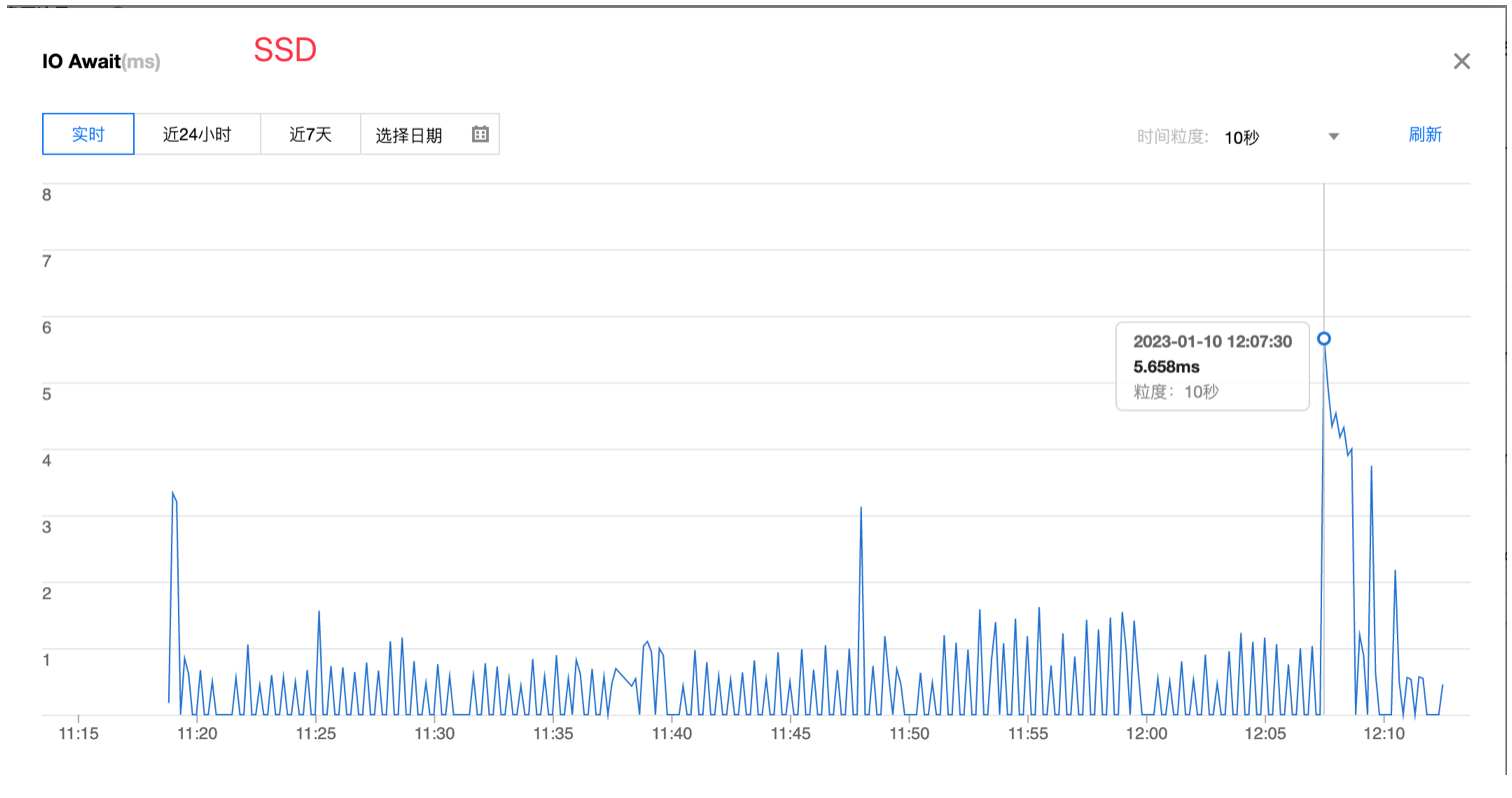
果然即便是压测,SSD磁盘的 IO 也比普通硬盘的正常请求期间延迟更低。
既然磁盘 IO 延迟降低了,根据前文的分析理论上整个集群的性能应该会有明显的上升,因此对比了升级前后的消息 TPS 写入指标:
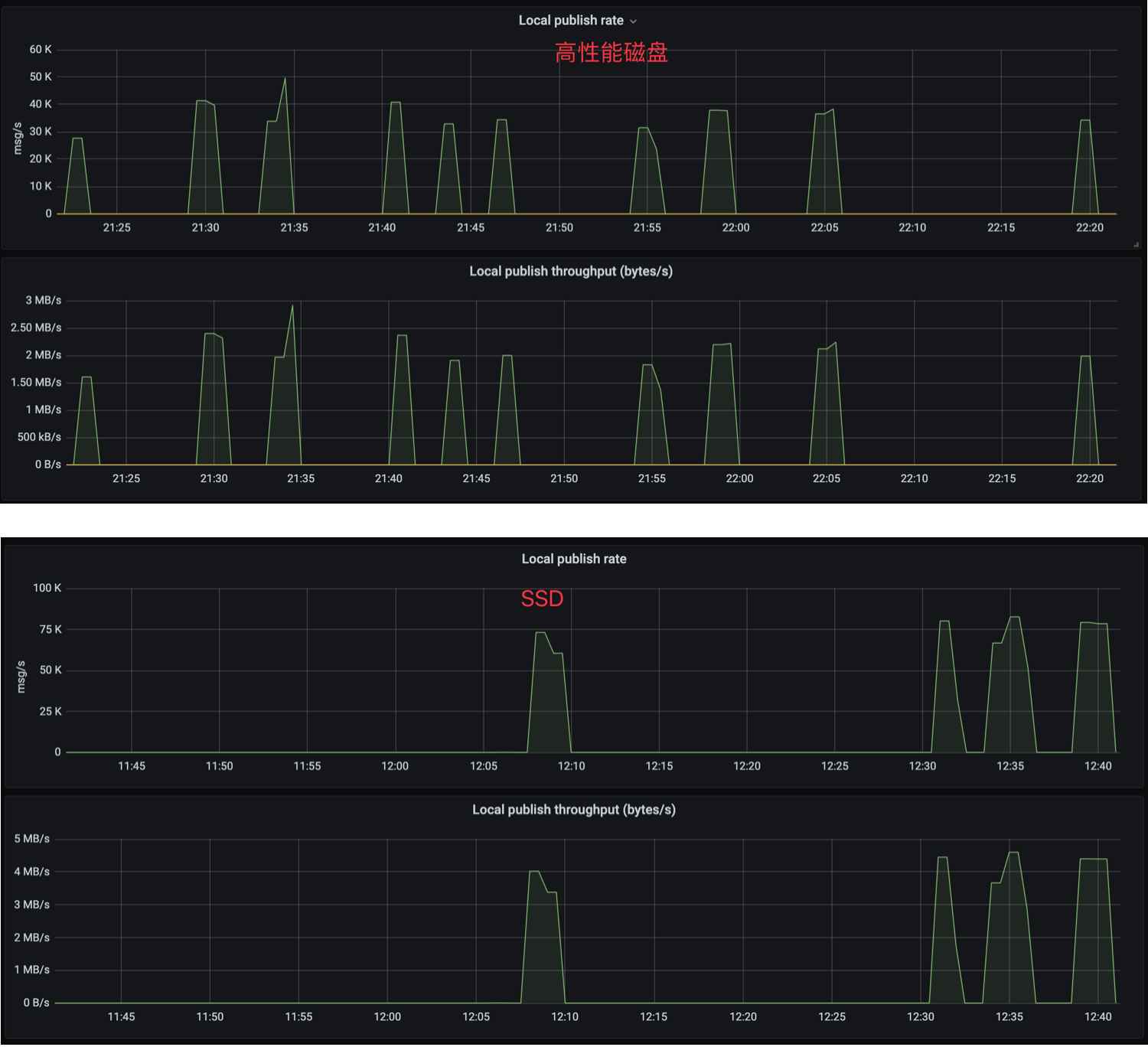
升级后每秒的写入速率由 40k 涨到 80k 左右,几乎是翻了一倍(果然用钱是最快解决问题的方式);
但即便是这样,极限压测后依然会出现客户端 timeout,这是因为无论怎么提高服务端的处理性能,依然没法做到没有延迟的写入,各个环节都会有损耗。
升级过程中的 timeout
还有一个关键的步骤必须要覆盖:模拟生产现场有着大量的生产者和消费者接入收发消息时进行集群升级,对客户端业务的影响。
根据官方推荐的升级步骤,流程如下:
- Upgrade Zookeeper.
- Disable autorecovery.
- Upgrade Bookkeeper.
- Upgrade Broker.
- Upgrade Proxy.
- Enable autorecovery.
其中最关键的是升级 Broker 和 Proxy,因为这两个是客户端直接交互的组件。
本质上升级的过程就是优雅停机,然后使用新版本的 docker 启动;所以客户端一定会感知到 Broker 下线后进行重连,如果能快速自动重连那对客户端几乎没有影响。
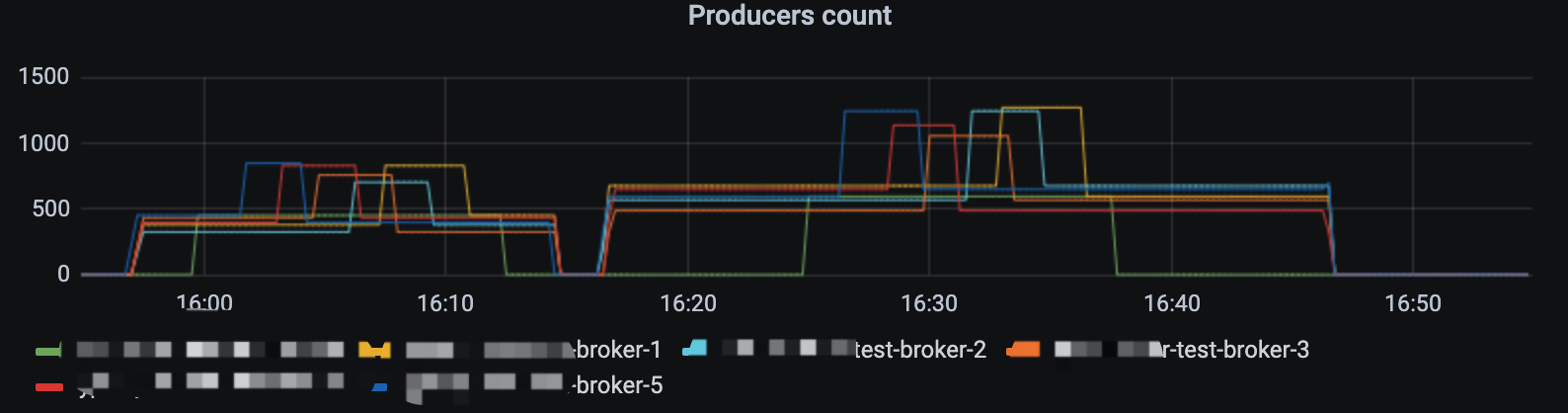
在我的测试过程中,2000左右的 producer 以 1k 的发送速率进行消息发送,在 30min 内完成所有组件升级,整个过程客户端会自动快速重连,并不会出现异常以及消息丢失。
而一旦发送频率增加时,在重启 Broker 的过程中便会出现上文提到的 timeout 异常;初步看起来是在默认的 30s 时间内没有重连成功,导致积压的消息已经超时。
经过分析源码发现关键的步骤如下:
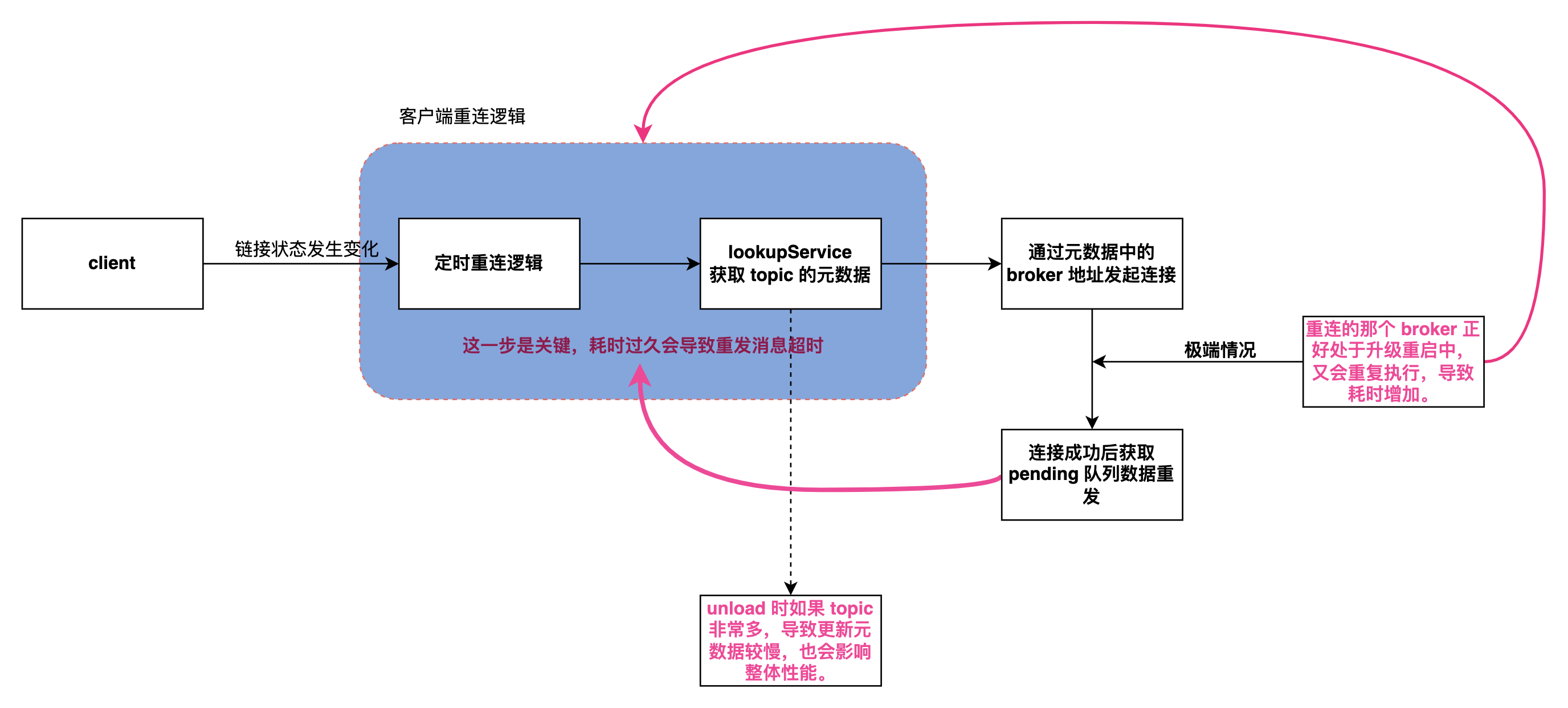
客户端在与 Broker 的长连接状态断开后会自动重连,而重连到具体哪台 Broker 节点是由 LookUpService 处理的,它会根据使用的 topic 获取到它的元数据。
理论上这个过程如果足够快,对客户端就会越无感。
在元数据中包含有该 topic 所属的 bundle 所绑定的 Broker 的具体 IP+端口,这样才能重新连接然后发送消息。
bundle 是一批 topic 的抽象,用来将一批 topic 与 Broker 绑定。
而在一个 Broker 停机的时会自动卸载它所有的 bundle,并由负载均衡器自动划分到在线的 Broker 中,交由他们处理。
这里会有两种情况降低 LookUpSerive 获取元数据的速度:
因为所有的 Broker 都是 stateful 有状态节点,所以升级时是从新的节点开始升级,假设是broker-5,假设升级的那个节点的 bundle 切好被转移 broker-4中,客户端此时便会自动重连到 4 这个Broker 中。
此时客户端正在讲堆积的消息进行重发,而下一个升级的节点正好是 4,那客户端又得等待 bundle 成功 unload 到新的节点,如果恰好是 3 的话那又得套娃了,这样整个消息的重发流程就会被拉长,直到超过等待时间便会超时。
还有一种情况是 bundle 的数量比较多,导致上面讲到的 unload 时更新元数据到 zookeeper 的时间也会增加。
所以我在考虑 Broker 在升级过程中时,是否可以将 unload 的 bundle 优先与
Broker-0进行绑定,最后全部升级成功后再做一次负载均衡,尽量减少客户端重连的机会。
解决方案
如果我们想要解决这个 timeout 的异常,也有以下几个方案:
- 将 bookkeeper 的磁盘换为写入时延更低的 SSD,提高单节点性能。
- 增加 bookkeeper 节点,不过由于 bookkeeper 是有状态的,水平扩容起来比较麻烦,而且一旦扩容再想缩容也比较困难。
- 增加客户端写入的超时时间,这个可以配置。
- 客户端做好兜底措施,捕获异常、记录日志、或者入库都可以,后续进行消息重发。
- 为 bookkeeper 的写入延迟增加报警。
- Spring 官方刚出炉的 Pulsar-starter 已经内置了 producer 相关的 metrics,客户端也可以对这个进行监控报警。
以上最好实现的就是第四步了,效果好成本低,推荐还没有实现的都尽快 try catch 起来。
整个测试流程耗费了我一两周的时间,也是第一次全方位的对一款中间件进行测试,其中也学到了不少东西;不管是源码还是架构都对 Pulsar 有了更深入的理解。
对 Pulsar 集群的压测与优化的更多相关文章
- Spark集群之yarn提交作业优化案例
Spark集群之yarn提交作业优化案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.启动Hadoop集群 1>.自定义批量管理脚本 [yinzhengjie@s101 ...
- mysql-cluster集群(亲测)
重要说明:mysql-cluste与非集群时用的mysql-server与mysql-client没有任何关系,mysql-cluste安装包中已自带了集群用的server与client,启动mysq ...
- 近千节点的Redis Cluster高可用集群案例:优酷蓝鲸优化实战(摘自高可用架构)
(原创)2016-07-26 吴建超 高可用架构导读:Redis Cluster 作者建议的最大集群规模 1,000 节点,目前优酷在蓝鲸项目中管理了超过 700 台节点,积累了 Redis Clus ...
- 消息服务dubbo接口性能压测性能优化案例
最近项目中的消息服务做了运营商的改动,导致这个服务做了重新开发 压测脚本如下: 开启200线程压测: tps只有200-300之间,平均耗时在700ms左右 开启500线程压测 500并发压测,发现平 ...
- 压测session优化
每请求一次jsp页面,会产生一个session对象,并且这个对象30分钟后才过期.我们计算了下当时的QPS是5000,也就是说每秒钟产生5000个session对象.每分钟产生300K个对象,sess ...
- nginx+tomcat集群时,tomcat参数优化
maxKeepAliveRequests=“1”: nginx动态的转给tomcat,nginx是不能keepalive的,而tomcat端默认开启了keepalive,会等待keepalive的ti ...
- 支付宝LR集群压测报告
支付宝压力测试报告 时间:2016-03-23 测试人员:XXX 目录 支付宝压力测试报告 1 目录 1 一 ...
- 生产调优2 HDFS-集群压测
目录 2 HDFS-集群压测 2.1 测试HDFS写性能 测试1 限制网络 1 向HDFS集群写10个128M的文件 测试结果分析 测试2 不限制网络 1 向HDFS集群写10个128M的文件 2 测 ...
- 全链路压测平台(Quake)在美团中的实践
背景 在美团的价值观中,以“客户为中心”被放在一个非常重要的位置,所以我们对服务出现故障越来越不能容忍.特别是目前公司业务正在高速增长阶段,每一次故障对公司来说都是一笔非常不小的损失.而整个IT基础设 ...
- jmeter 压测最近的心得体会
笔者14年入坑测试,截止到17年年初一直在游戏公司,压测,我都没有怎么用过,特别是jmeter去压测,自己学习,可是先找到切入点,于是乎, 其实也算是我学习后,先找一个更大的平台吧,我聊了几个游戏公司 ...
随机推荐
- VSCode设置鼠标滚轮滑动设置字体大小
1. 打开"文件->首选项->设置 2. 打开settings.json文件 3. 在setting.json 中添加"editor.mouseWheelZoom&qu ...
- 四、redis数据类型
四.redis数据类型 redis可以理解成一个全局的大字典,key就是数据的唯一标识符.根据key对应的值不同,可以划分成5个基本数据类型. 1. string类型: 字符串类型,是 Redis 中 ...
- 想开发DAYU200,我教你
摘要:本文主要介绍OpenHarmony富设备DAYU200开发板的入门指导. 本文分享自华为云社区<DAYU200开发指导>,作者: 星辰27. 1 概述 DAYU200开发板属于Ope ...
- .NET7 gRPC JSON转码+OpenAPI
gRPC JSON转码 gRPC JSON 转码允许浏览器应用调用 gRPC 服务,就像它们是使用 JSON 的 RESTful API 一样. 浏览器应用不需要生成 gRPC 客户端或了解 gRPC ...
- Oracle 表空间常用操作
aliases: [Oracle表空间] tags: [数据库,Oracle,Blog] summary: [Oracle表空间常用操作,包括查询.分析.扩容.删除.优化等] date: ...
- 2022年rhce最新认证—(满分通过)
RHCE认证 重要配置信息 在考试期间,除了您就坐位置的台式机之外,还将使用多个虚拟系统.您不具有台式机系统的 root 访问权,但具有对虚拟系统的完整 root 访问权. 系统信息 在本考试期间,您 ...
- htaccess如何配置隐藏index.php文件
<IfModule mod_rewrite.c> Options +FollowSymlinks -Multiviews RewriteEngine On RewriteCond %{RE ...
- gdb不能使用mac
先说问题:1.gdb不能使用,重新用homebrew install 了gdb 2.brew装的gdb可以用了,但是等start调试的时候报这些错误: dyld: Library not ...
- openstack单机部署 未完成
注:centos8单机版 注:本次实验手动配置密码均为admin 环境准备:配置hosts文件 192.168.116.85为本机IP echo '192.168.116.85 controller ...
- python小练习:涉及print,json,numpy
枚举参考文件夹中的文件,并与待比较文件件中的同名文件比较是否一致. #! /usr/bin/python3.6 # -*- coding:utf-8 -*- import os import sys ...