TCAM and CAM memory usage inside networking devices(转)
TCAM and CAM memory usage inside networking devices Valter Popeskic Equipment and tools, Physical layer, Routing, Switching 8 Comments
As this is networking blog I will focus mostly on the usage of CAM and TCAM memory in routers and switches. I will explain TCAM role in router prefix lookup process and switch mac address table lookup.
However, when we talk about this specific topic, most of you will ask: how is this memory made from architectural aspect?
How is it made in order to have the capability of making lookups faster than any other hardware or software solution? That is the reason for the second part of the article where I will try to explain in short how are the most usual TCAM memory build to have the capabilities they have.
CAM AND TCAM MEMORY
When using TCAM – Ternary Content Addressable Memory inside routers it’s used for faster address lookup that enables fast routing.
In switches CAM – Content Addressable Memory is used for building and lookup of mac address table that enables L2 forwarding decisions. By implementing router prefix lookup in TCAM, we are moving process of Forwarding Information Base lookup from software to hardware.
When we implement TCAM we enable the address search process not to depend on the number of prefix entries because TCAM main characteristic is that it is able to search all its entries in parallel. It means that no matter how many address prefixes are stored in TCAM, router will find the longest prefix match in one iteration. It’s magic, right?
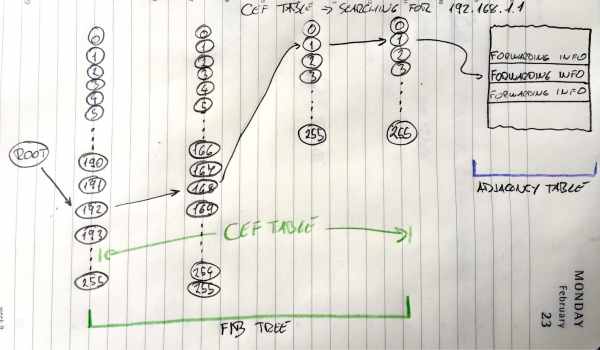
CEF Lookup
Image 1 shows how FIB lookup functions and points to an entry in the adjacency table. Search process goes through all entries in TCAM table in one iteration.
ROUTER
In routers, like High-End Cisco ones, TCAM is used to enable CEF – Cisco Express Forwarding in hardware. CEF is building FIB table from RIB table (Routing table) and Adjacency table from ARP table for building pre-prepared L2 headers for every next-hop neighbour.
TCAM finds, in one try, every destination prefix inside FIB. Every prefix in FIB points to adjacency table’s pre-prepared L2 header for every outgoing interface. Router glues the header to packet in question and send it out that interface. It seems fast to do it that way? It is fast!
SWITCH
In Layer 2 world of switches, CAM memory is most used as it enables the switch to build and lookup MAC address tables. MAC address is always unique and so CAM architecture and ability to search for only exact matches is perfect for MAC address lookup. That gives the switch ability to go over all MAC addresses of all host connected to all ports in one iteration and resolve where to send received packets.
CAM is so perfect here as the architecture of CAM provides the result of two kinds 0 or 1. So then we make the lookup on CAM table it will only get us with true (1) result if we searched for the exact same bits. L2 forwarding decisions are the one using this fast magical electronics!
MORE THAN PLAIN ROUTING AND SWITCHING
Besides Longest-Prefix Matching, TCAM in today’s Routers and Multilayer Switch devices are used to store ACL, QoS and other things from upper-layer processing. TCAM architecture and the ability of fast lookup enables us to implement Access-Lists without an impact on router/switch performance.
Devices with this ability mostly have more TCAM memory modules in order to implement Access-List in both directions and QoS at the same time at the same port without any performance impact. All those different functions and their lookup process towards a decision is made in parallel.
MORE ON TCAM
TCAM is basically a special version of CAM constructed for rapid table lookups. Not mentioned before, TCAM can get Us with three different results when doing lookups: 0, 1, and X (I don’t care state).
With this strange third state, TCAM is perfect for building and searching tables for stored longest matches in IP routing tables.
There is just one condition that IP prefixes need to be sorted before they are stored in TCAM so that longest prefixes are on upper position with higher priority (lower address location) in a table. This enables us to always select the longest prefix from given results an thus enables Longest-Prefix Matching.
TCAM ARCHITECTURE
In the Image 2 here below I showed, (please disregard my style), one of the simplest CEF Explanations I could find in scientific articles around. It is basically showing you usage of FIB on the left and Adjacency table on the right. FIB stored in TCAM table and Adjacency table stored in RAM memory. Great, it shows without words what we spoked about before in “ROUTER” section.
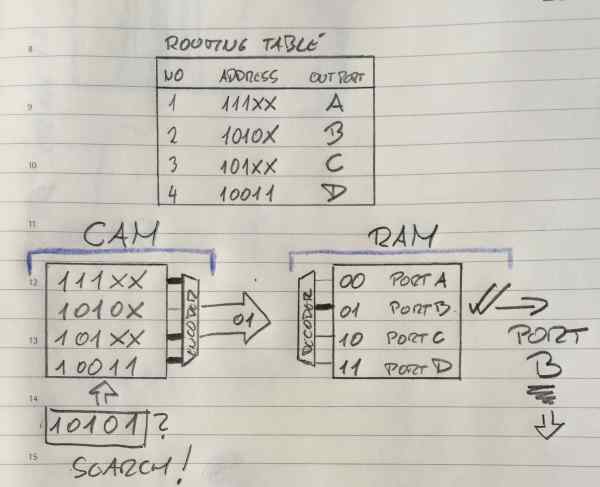
TCAM FIB
Image 2 FIB implemented in TCAM, adjacency table implemented in RAM
Ok, Here you must know that IP addresses in the example are smaller that real ones. Here we have addresses of 5 bits not 32 like IPv4, all other is the same as the real stuff.
We are looking on the left side now at the CAM part, it is basically explained for TCAM.
So in TCAM world in order to get the longest match like in the Image 2 above here, before populating the TCAM we need to sort the entries so that longer prefixes are always situated on higher priority places. As the lookup goes from top downwards it means that higher priority is higher in the table, closer to the top. OK, now that we solved this it is easy to see that TCAM here is searching in parallel from left to right all four address entries.
Entries here in TCAM are numbered 00,01,02,03 from top to bottom. Not like in Routing table above where they are numbered 1,2,3,4. Don’t let that confuse you.
Second and third entry (01 and 02 entry) are the same as the one we search in first three bits. When it comes to the fourth bit, he is “X” for entry 02.
X means don’t care or the third possible solution that can come out of TCAM table query. In the situation above, if we look at the second and third line of TCAM table, this search will make a match for both of entries. The fourth bit of “01” is matched and the fifth bit does not care. For “02” it will show true value at the encoder entrance as a fourth and fifth place do not care!
Based on the priority order from above, line “01” is the longest-prefix match and it is selected and send to encoder who will link that entry to Adjacency table entry for making the packet L2 ready. Remember, on this image, “01” is sent to Adjacency table as a pointer. It is pointing to Adjacency table entry 01 which will then be used use for this packet creation.
L2 header will be added to that packet and the packet will be sent out on port B to the neighbour.
TCAM PARALLEL SEARCH PROCESS INSIDE CIRCUITRY
Actually with CAM and TCAM chips the logic is slightly different that you might think.
For all entries that are matching the searched one, encoder entry will get “true” signal, and all not matched entries will show “false” output, no problems there. The catch is in the beginning of the process. Before search begins all entries when entered inside TCAM are closing the circuitry on TCAM word entry and show “true” at encoder side. All entries are temporarily in the match state. When parallel search is done it will brake all entries that have at least one bit that does not match the searched entry.
Here is the explanation of the “don’t care bit”, in the search process when the search gets to X bit (“don’t care bit”) it will not change the state of that matchline. That’s why No 2 and No3 lines made a match, and that’s why TCAM is perfect for longest-prefix lookup.
This also explains why TCAM memory is so power hungry. It needs to power on all circuits to be able to make a search not only the matched ones. Limited memory space and power consumption associated with a large amount of parallel active circuitry are the main issues with TCAM.
If we look at the right side of the Image 2 now, we see that adjacency table is built in RAM memory. Adjacency table uses ARP table and Routing table data for building pre-prepared L2 headers for every next-hop neighbour. As described before in “Router” section it will prepare the packet to be sent to Layer 1 and out the interface in a flash. Entries need to keep L2 data and this data does not change often. RAM memory is consequently perfect fit for adjacency table. Quick, not expensive, not space limited and not so power hungry.
TCAM and CAM memory usage inside networking devices(转)的更多相关文章
- GPU Memory Usage占满而GPU-Util却为0的调试
最近使用github上的一个开源项目训练基于CNN的翻译模型,使用THEANO_FLAGS='floatX=float32,device=gpu2,lib.cnmem=1' python run_nn ...
- Shell script for logging cpu and memory usage of a Linux process
Shell script for logging cpu and memory usage of a Linux process http://www.unix.com/shell-programmi ...
- 5 commands to check memory usage on Linux
Memory Usage On linux, there are commands for almost everything, because the gui might not be always ...
- SHELL:Find Memory Usage In Linux (统计每个程序内存使用情况)
转载一个shell统计linux系统中每个程序的内存使用情况,因为内存结构非常复杂,不一定100%精确,此shell可以在Ghub上下载. [root@db231 ~]# ./memstat.sh P ...
- Why does the memory usage increase when I redeploy a web application?
That is because your web application has a memory leak. A common issue are "PermGen" memor ...
- Reducing and Profiling GPU Memory Usage in Keras with TensorFlow Backend
keras 自适应分配显存 & 清理不用的变量释放 GPU 显存 Intro Are you running out of GPU memory when using keras or ten ...
- 【转】C++ Incorrect Memory Usage and Corrupted Memory(模拟C++程序内存使用崩溃问题)
http://www.bogotobogo.com/cplusplus/CppCrashDebuggingMemoryLeak.php Incorrect Memory Usage and Corru ...
- Memory usage of a Java process java Xms Xmx Xmn
http://www.oracle.com/technetwork/java/javase/memleaks-137499.html 3.1 Meaning of OutOfMemoryError O ...
- Redis: Reducing Memory Usage
High Level Tips for Redis Most of Stream-Framework's users start out with Redis and eventually move ...
- detect data races The cost of race detection varies by program, but for a typical program, memory usage may increase by 5-10x and execution time by 2-20x.
小结: 1. conflicting access 2.性能危害 优化 The cost of race detection varies by program, but for a typical ...
随机推荐
- immutable.js学习笔记(八)----- immutable.js对象 和 原生对象的相互转换
一.原生对象转换为immutable.js对象 fromJS 栗子一: 栗子二: 如果数组里面有对象,对象里面有数组,怎么转换呢 复杂结构的转换 二.immutable.js对象转换为原生对象 toJ ...
- 0基础搭建基于OpenAI的ChatGPT钉钉聊天机器人
前言:以下文章来源于我去年写的个人公众号.最近chatgpt又开始流行,顺便把原文内容发到博客园上遛一遛. 注意事项和指引: 注册openai账号,需要有梯子进行访问,最好是欧美国家的IP,亚洲国家容 ...
- 关于vue keep-alive配合swiper的问题
问题描述,首页优化使用keep-alive之后,从别的页面跳回来,swiper轮播不播放,查了好久资料,有的说要重新调用swiper的init方法进行初始化,等等,最终都没能解决问题,最终通过查看文档 ...
- 用ChatGPT,快速设计一个真实的账号系统
hi,我是熵减,见字如面. 用ChatGPT,可以尝试做很多的事情. 今天我们就来让ChatGPT做为架构师,来帮我们设计一个账号系统吧. 我的实验过程记录如下,与你分享. 用户故事 首先,我们从用户 ...
- [SHOI2006]仙人掌
[SHOI2006]仙人掌 简要解析 其实很简单 只要普通树形 \(dp\) 就行了 \(f_x\) 表示 \(x\) 能向下延深的最大距离,\(v\) 是 \(x\) 的儿子 当一个点不属于任何环时 ...
- Xmake v2.7.7 发布,支持 Haiku 平台,改进 API 检测和 C++ Modules 支持
Xmake 是一个基于 Lua 的轻量级跨平台构建工具. 它非常的轻量,没有任何依赖,因为它内置了 Lua 运行时. 它使用 xmake.lua 维护项目构建,相比 makefile/CMakeLis ...
- 3D数字孪生场景编辑器介绍
1.背景 数字孪生的建设流程涉及建模.美术.程序.仿真等多种人才的协同作业,人力要求高,实施成本高,建设周期长.如何让小型团队甚至一个人就可以完成数字孪生的开发,是数字孪生工具链要解决的重要问题.目前 ...
- STM32L431 移植 LiteOS 时 _ebss _Min_Heap_Size _Min_Stack_Size 未找到或未定义
将 LiteOS 移植完成之后,编译报如下错误: 环境 版本 Keil V5.37.0.0 Windows11 2022/12/22 ARM::CMSIS 5.9(2022-05-22) 开发板 ST ...
- 柯尼卡美能达C226打印机安装使用说明
安装驱动,选择通过IP地址安装 输入打印机IP 点击完成即可使用
- vscode注释插件
VSCODE注释插件:koro1FileHeader 按koroFileHeader 插件,配置默认注释 1.在扩展中搜索koroFileHeader,安装 2.安装完成后,在设置中搜索,koro1F ...