MySQL存储引擎、基础数据类型、约束条件
MySQL存储引擎
存储引擎
# 存储引擎可以堪称是处理数据的不同方式
# 查看存储引擎的方式
show engines;
# 需要掌握的四个存储引擎
MyISAM
MySQL5.5之前的默认的存储引擎
不支持事务、行级锁和外键 针对数据的操作较于InnoDB不够安全
但是数据的存取速度交于InnoDB更快
InnoDB
MySQL5.5之后默认的存储引擎
支持事务、行级锁和外键 针对数据的操作更加的安全
memory
基于内存存取数据
速度最快但是断电立刻丢失
blackhole(黑洞)
写入其中的数据会立刻消失 类似于垃圾处理站
# 存储引擎创建表的不同点
create table t1(id int) engine=myisam;
create table t2(id int) engine=innodb;
create table t3(id int) engine=memory;
create table t4(id int) engine=blackhole;
'''
MyISAM会创建三个文件
.frm 表结构文件
.MYD 表数据文件
.MYI 表索引文件(索引是用来加快数据查询的)
InnoDB会创建两个文件
.frm 表结构文件
.ibd 表数据和表索引文件
memory
.frm 表结构文件
blackhole
.frm 表结构文件
'''
MySQL基本数据类型
整型与浮点型
# 1.整型
tinyint smallint int bigint
不同的int类型能够存储的数字范围是不一样的
1.要注意是否存负数(正负号需要占一个比特位)
2.针对手机号码只能用bigint
'''研究默认是否需要正负号'''
create table t5(id tinyint);
insert into t5 values(-999),(999);
# 结论:所有的int类型默认都需要正负号
create table t6(id tinyint unsigned); # 移除正负号
insert into t6 values(-999),(999);
# 2.浮点型
float double decimal
float(255,30) # 总共255位 小数位占30位
double(255,30) # 总共255位 小数位占30位
decimal(65,30) # 总共65位 小数位占30位
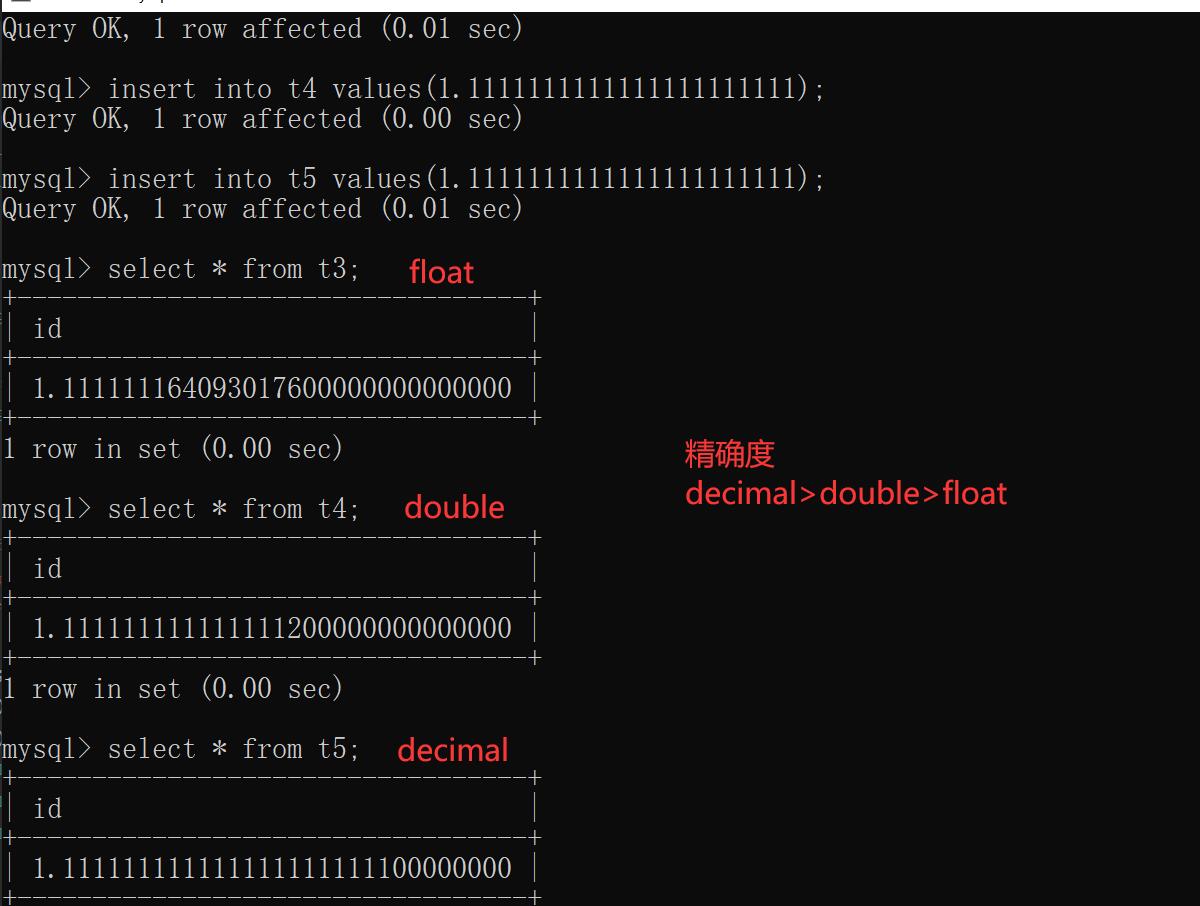
"""研究三者的不同"""
create table t7(id float(255,30));
create table t8(id double(255,30));
create table t9(id decimal(65,30));
insert into t7 values(1.11111111111111111111111);
insert into t8 values(1.11111111111111111111111);
insert into t9 values(1.11111111111111111111111);
# 结论:三者的精确度不一样
float < double < decimal
"""
到底使用哪个
一般情况下小数点后面只保留两位 所以float足矣
如果是从事高精密业务 则需要考虑更高的精确度
ps:有时候很多看似需要用数字存储的数据 可能都是存的字符串
课外扩展:python本身对数字的精确度很低 之所以能够从事人工智能和数据分析完全得益于功能强大的模块
"""
字符类型
char(4)
定长类型 最多只能存四个字符(根据括号里数字改变) 多了报错少了自动空格填充至四个
varchar(4)
变长类型 最多只能存四个字符(根据括号里数字改变) 多了报错少了有几个则存几个
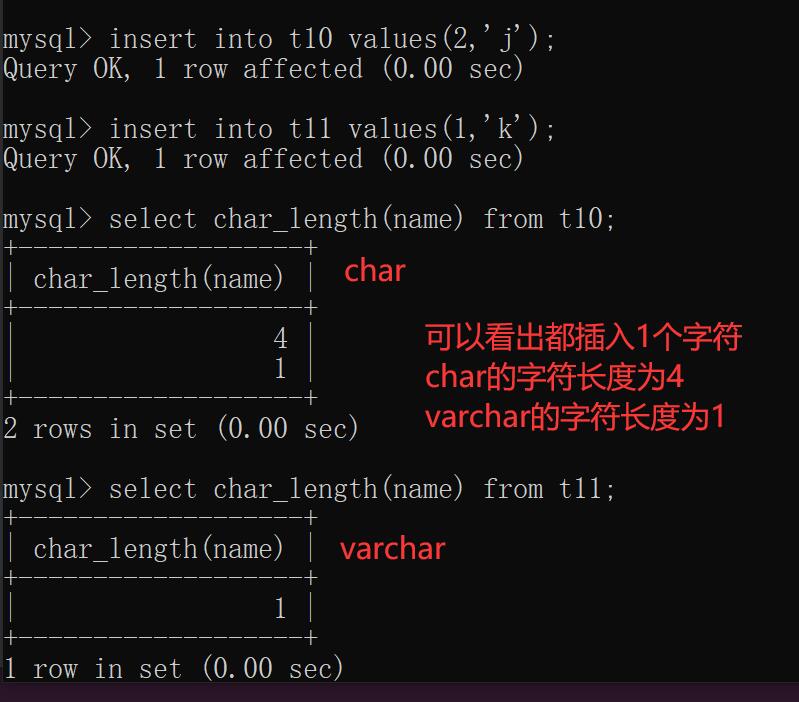
"""研究上述特征"""
create table t10(id int,name char(4));
create table t11(id int,name varchar(4));
insert into t10 values(1,'jason');
insert into t11 values(1,'jason');
# 针对5.6版本超出范围不会报错 而是自动帮你截取并保存(此行为不合理)
方式1:修改配置文件(永久)
方式2:命令修改(暂时)
show variables like '%mode%'
set session # 当前窗口有效
set global # 当前服务端有效
set gloabl sql_mode = 'strict_trans_tables'
修改完毕后退出客户端重新进入即可
再次执行上述插入命令 会直接报错
# 研究定长与变长特性
insert into t10 values(1,'j');
insert into t11 values(1,'t');
# 统计某个字段数据的长度 char_length()
'''底层确实会填充 但是取出来的时候又会自动去除'''
set global sql_mode = 'strict_trans_tables,pad_char_to_full_length'
char与varchar的对比
| 类型 | 优点 | 缺点 |
|---|---|---|
| char | 整存整取 速度快 | 浪费存储空间 |
| varchar | 节省存储空间 | 存取数据的速度较char慢 |
底层原理:
char(5)
char在存数据的时候因为不够的会用空格补全,所以长度是固定的,所以从硬盘取数据的时候,可以直接按照长度来直接读取,比如下面的数据:
jasontony kevintom oscartank sean jerry(不够的中间会有空格填充,数据规整)
varchar(5)
存:先计算数据的长度
取:先获取报头的数据
varchar在存数据的时候虽然可以不浪费空间,但是在从硬盘取的时候不知道该取到哪,所以就得给数据添加1bytes的报头,报头里面记录的是数据的长度,类似网络编程里的收数据防止黏包事件,所以在取的时候要先读取报头信息拿到数据长度后才能正确的从硬盘上取出数据,所以比char存取数据要慢.
1bytes+jason1bytes+tony1bytes+kevin1bytes+tom1bytes+oscar1bytes+tank1bytes+sean1bytes+jerry
整型中括号内数字的作用
create table t13(id int(3));
insert into t13 values(4444444);
"""
在整型中括号内的数字并不是用来限制存储的长度 而是用来控制展示的长度
我们以后在定义整型字段的时候 不需要自己添加数字 使用默认的就可以
"""
create table t14(id int(3) zerofill);
insert into t13 values(4);
# 结论:整型比较的特殊 是唯一个不是用来限制存储长度的类型
枚举与集合类型
枚举
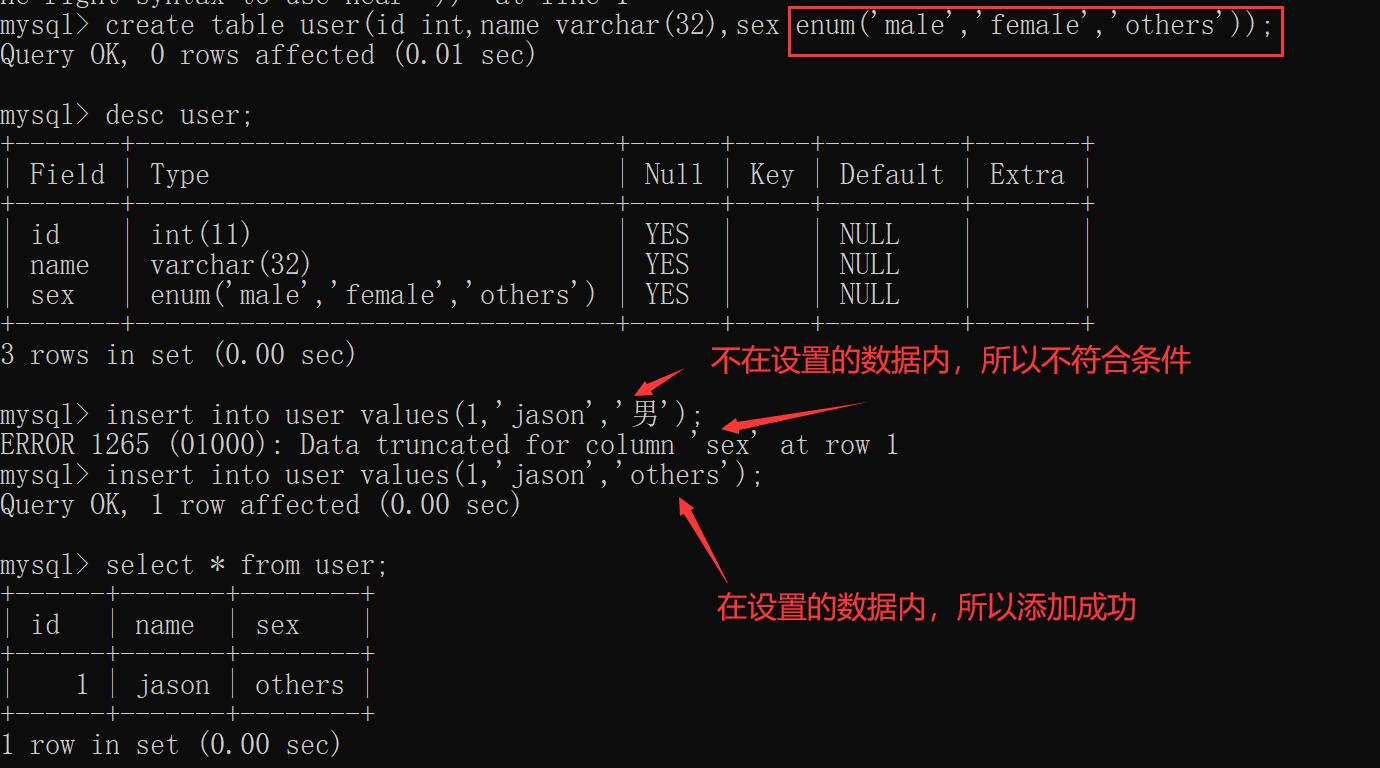
多选一,从你指定的选项中选择一个,其他数据不允许插入
枚举:enum()
create table user(
id int,
name varchar(32),
gender enum('male','female','others')
);
insert into user values(1,'jason','男') # 报错
insert into user values(2,'tony','male'); # 插入成功
集合
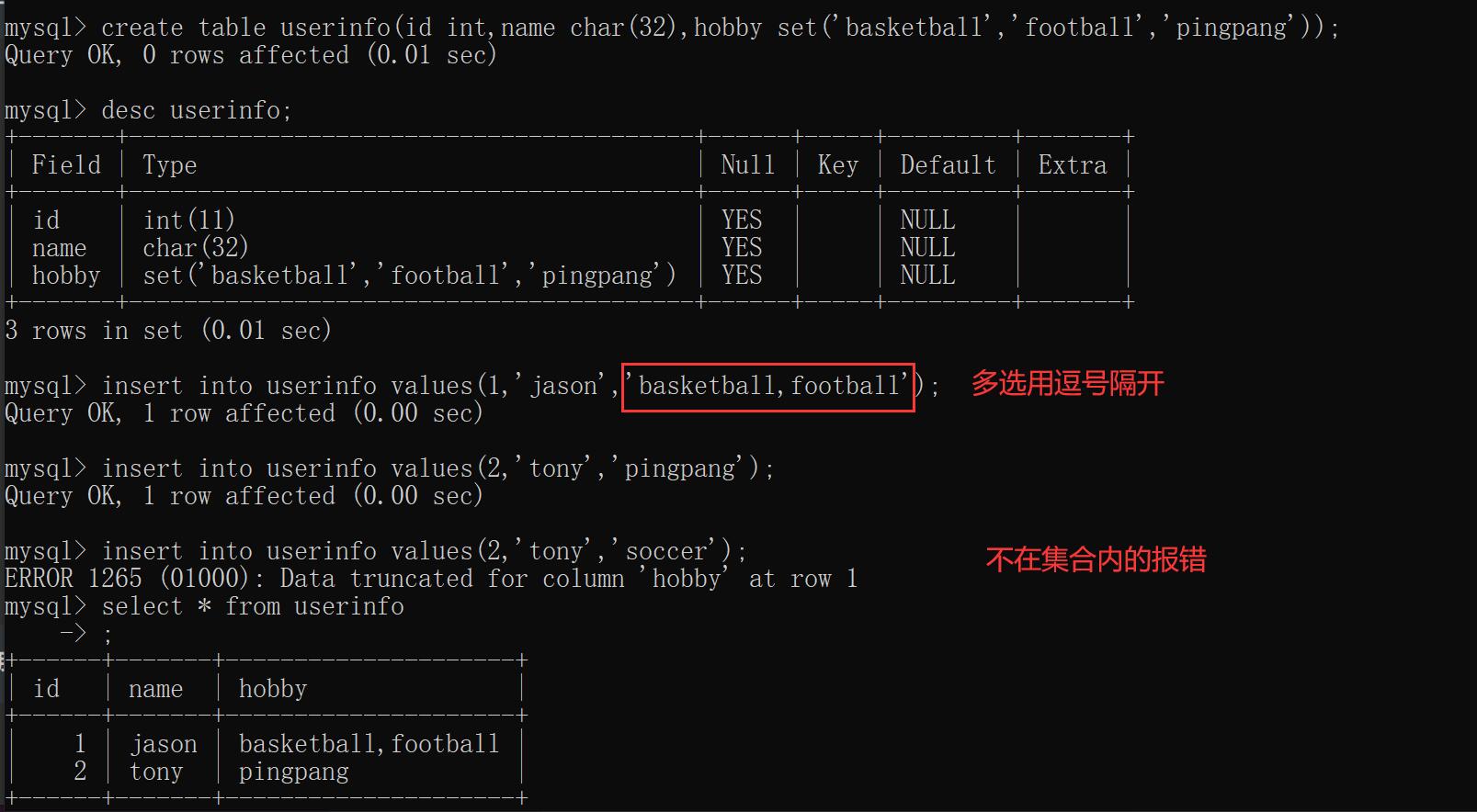
多选多(包含多选一)
集合:set()
create table userinfo(
id int,
name char(32),
hobby set('basketball','football','pingpang')
);
insert into userinfo values(1,'jason','football'); # 可以
insert into userinfo values(2,'tony','football' '');
日期类型
date 年月日
datetime 年月日时分秒
time 时分秒
year 年份
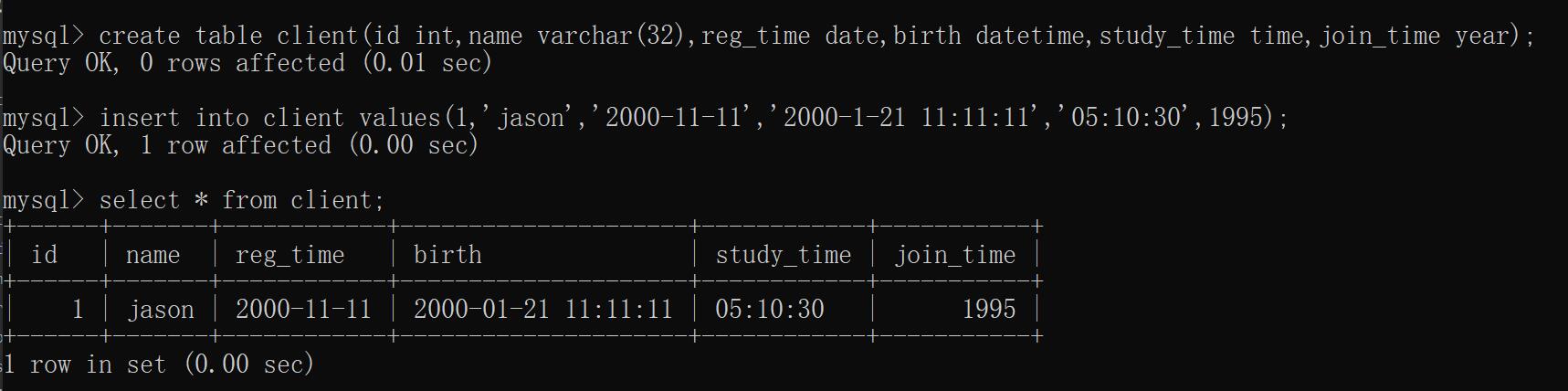
create table client(
id int,
name varchar(32),
reg_time date,
birth datetime,
study_time time,
join_time year
);
insert into client values(1,'jason','2000-11-11','2000-1-21 11:11:11','11:11:11',1995);
创建表的完整语法
create table 表名(
字段名1 字段类型(数字) 约束条件,
字段名2 字段类型(数字) 约束条件,
字段名3 字段类型(数字) 约束条件
);
"""
1.字段名和字段类型是必须的
2.数字和约束条件是可选的 并且 约束条件可以有多个空格隔开即可
3.最后一个语句的结尾不要加逗号
"""
约束条件
约束条件相当于是在字段类型的基础之上添加的额外约束
eg: id int unsigned
| 约束条件 | 作用 |
|---|---|
| unsigned | 让数字没有正负号 |
| zerofill | 多余的使用数字0填充 |
| not null | 非空 |
| default | 默认值 |
| unique | 唯一值 |
| primary key(重点) | 主键(等价于not null+unique) |
| auto_increment(重点) | 自增(基本与主键连用) |
zerofill(不够用0填充)
create table t2(
id int(4) zerofill,
name char(32)
);
insert into t2 values(1,'jason');
not null(非空)
create table t2(
id int,
name varchar(32) not null
);
insert into t1(id) values(1); # 报错 因为name字段为非空 不传就报错

default(默认值)
create table t3(
id int,
name varchar(32) default 'jason'
);
insert into t3(id) values(1),(2),(3);
unique(唯一值)
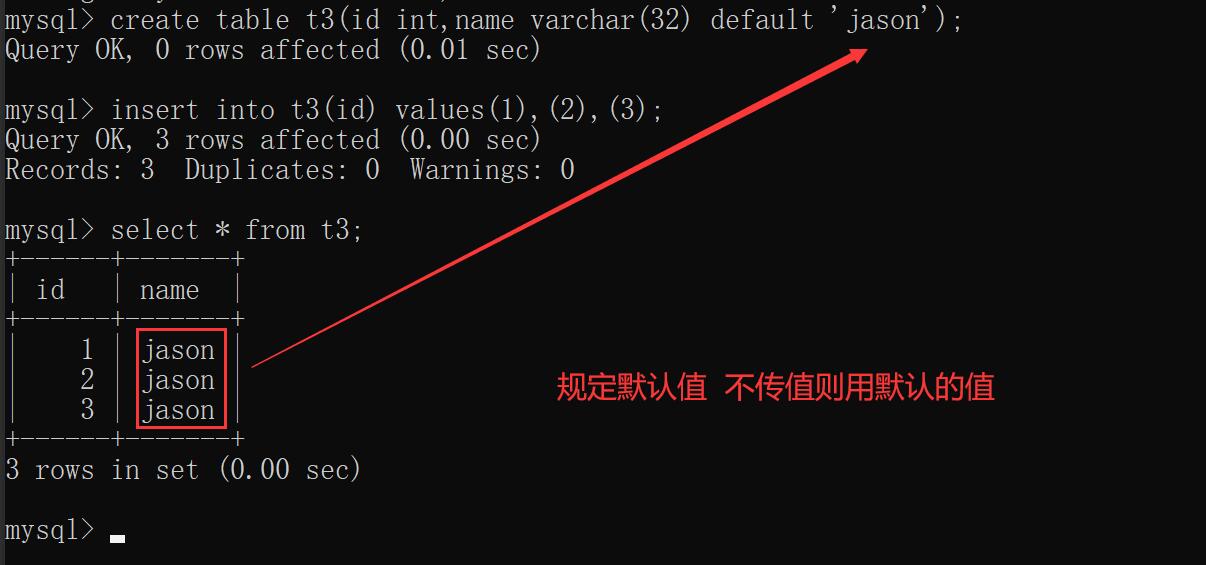
# 单列唯一
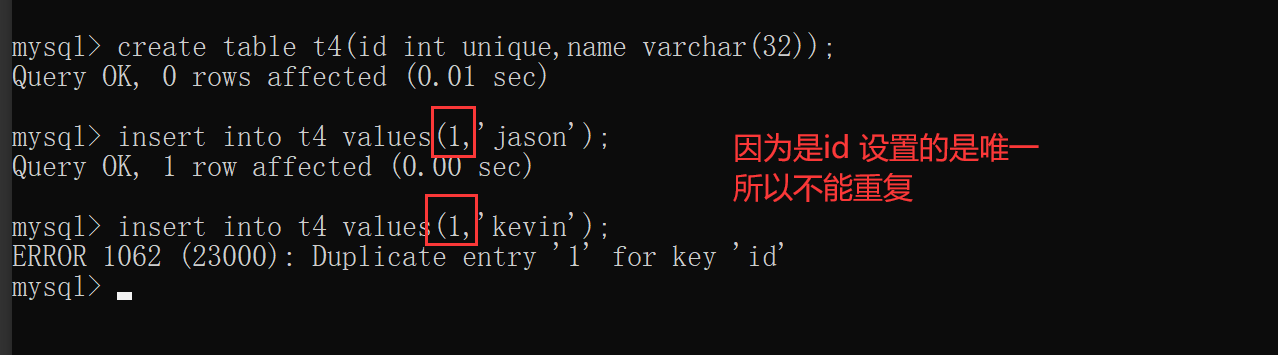
create table t4(
id int unique,
name varchar(32)
);
insert into t4 values(1,'jaosn'); # 正常
insert into t4 values(1,'kevin'); # 报错
# 联合唯一(两组数字组合一起不唯一就行)
create table t5(
id int,
host varchar(32),
port int,
unique(host,port)
);
insert into t5 values(1,'127.0.0.1',8000) # 正常
insert into t5 values(2,'127.0.0.1',8001) # 正常
insert into t5 values(2,'127.0.0.2',8000) # 正常
primary key(主键)
从约束层面上来说 相当于是 not null + unique(非空且唯一)
优点:加快数据的查询
InnoDB存储引擎规定了一张表必须有且只有一个主键
因为InnoDB是通过主键的方式来构造表的
如果没有设置主键
情况1:没有主键和其他约束条件
InnoDB会采用隐藏的字段作为主键 不能加快数据的查询
情况2:没有主键但是有非空且唯一的字段
自动将该字段升级为主键(从上往下遇到符合的就自动设置)
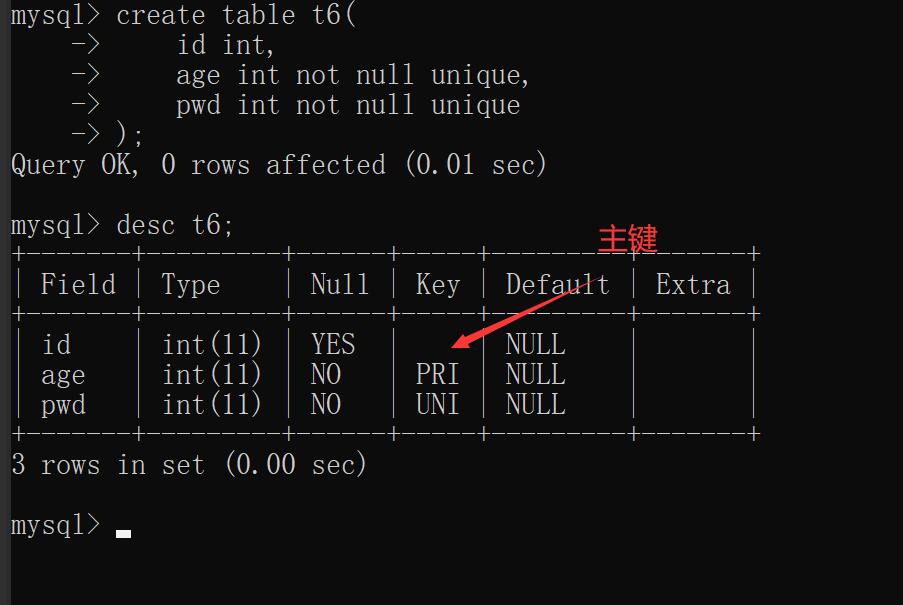
create table t6(
id int,
age int not null unique, # 自动变成逐主键
pwd int not null unique
);
结论:
以后我们在创建表的时候一定要设置主键
并且主键字段一般都是表的id字段(uid sid pid cid)
create table user(
id int primary key,
name varchar(32)
);
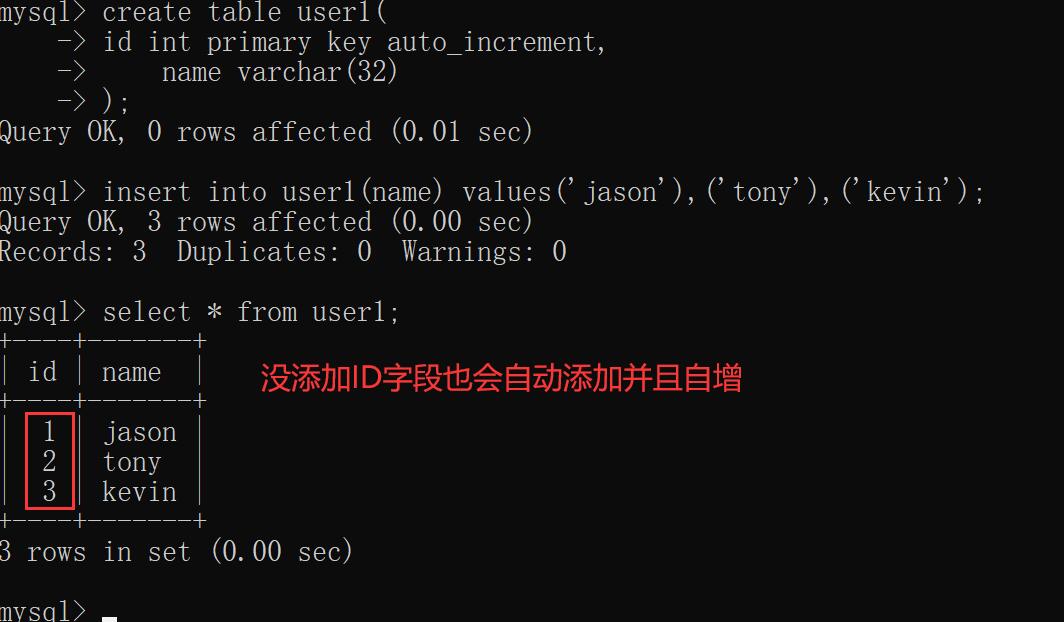
auto_increment(自增)
配合主键使用
create table user1(
id int primary key auto_increment,
name varchar(32)
);
insert into user1(name) values('jason'),('tony'),('kevin');
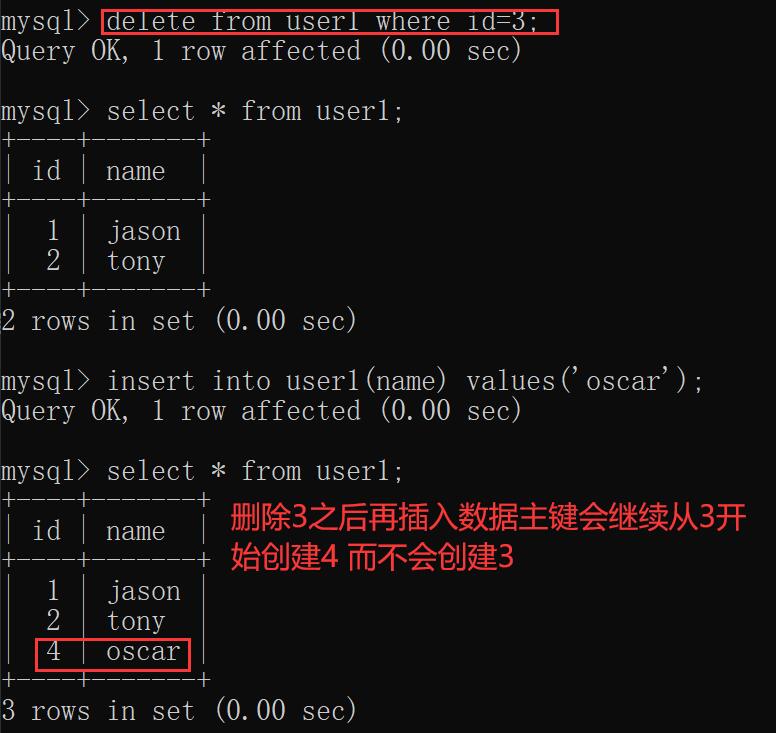
自增的特性
自增不会因为删除操作而回退
delete from无法影响自增
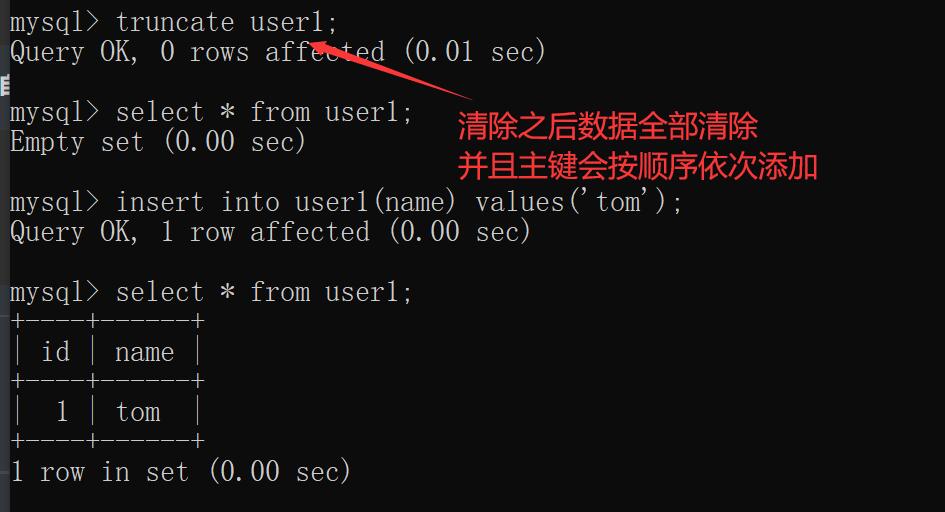
如果想要重置需需要使用truncate关键字
truncate 表名; # 清空表数据并且重置主键值
MySQL存储引擎、基础数据类型、约束条件的更多相关文章
- MySQL存储引擎与数据类型
1 数据存储引擎 存储引擎的概念是MySQL的一个特性,它指定了表的类型(诸如表怎样存储与索引数据.是否支持事务.外键等),表在计算机中的存储方式. 1.1 MySql支持的数据存储引擎 查看引擎信息 ...
- MySQL数据库(二)--库相关操作、表相关操作(1)、存储引擎、数据类型
一.库相关操作 1.创建数据库 (1)语法 create database 数据库 charset utf8; (2)数据库命名规范 可以由字母.数字.下划线.@.#.$ 区分大小写 唯一性 不能使用 ...
- MySQL数据库(二)——库相关操作、表相关操作(一)、存储引擎、数据类型
库相关操作.表相关操作(一).存储引擎.数据类型 一.库相关操作 1.创建数据库 (1)语法 create database 数据库 charset utf8; (2)数据库命名规范 可以由字母.数字 ...
- Database基础(二):MySQL索引创建与删除、 MySQL存储引擎的配置
一.MySQL索引创建与删除 目标: 本案例要求熟悉MySQL索引的类型及操作方法,主要练习以下任务: 普通索引.唯一索引.主键索引的创建/删除 自增主键索引的创建/删除 建立员工表yg.工资表gz, ...
- mysql基础之-mysql存储引擎概述(八)
0x01 mysql 存储引擎:存储引擎也通常被称作“表类型” mysql> show engines; --- 查看当前所有所支持的存储引擎 mysql> show table st ...
- MySQL存储引擎的实际应用以及对MySQL数据库中各主要存储引擎的独特特点的描述
MySQL存储引擎的实际应用以及对MySQL数据库中各主要存储引擎的独特特点的描述: 1.MySQL有多种存储引擎: MyISAM.InnoDB.MERGE.MEMORY(HEAP).BDB(Berk ...
- MySQL存储引擎总结
MySQL存储引擎总结 作者:果冻想 字体:[增加 减小] 类型:转载 这篇文章主要介绍了MySQL存储引擎总结,本文讲解了什么是存储引擎.MyISAM.InnoDB.MEMORY.MERGE等内 ...
- 数据库 --> MySQL存储引擎介绍
MySQL存储引擎介绍 MyISAM是MySQL的默认数据库引擎(5.5版之前),由早期的ISAM(Indexed Sequential Access Method:有索引的顺序访问方法)所改良.虽然 ...
- mysql存储引擎和索引
正确的创建合适的索引,是提升数据库查询性能的基础. 第一章 mysql之索引 索引的定义:索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构. 我们为什么要使用索引: a.极大的减少存储引 ...
随机推荐
- @weakify 与 @strongify 实现原理
为了解决 Block 造成的循环引用,iOS 开发过程中常常使用 @weakify 与 @strongify 来解决这个问题.下面就来看下 @weakify 与 @strongify 的实现原理. 准 ...
- 报错———http://mybatis.org/dtd/mybatis-3-mapper.dtd 报红解决方案
初次使用mybatis时,下面红线上的地址报红. 解决方法是:将http://mybatis.org/dtd/mybatis-3-mapper.dtd拷贝.添加到下面标记处.
- Docker——dockerfile
dockerFile介绍 dockerFile是用来构建docker镜像的文件!命令参数脚本! 步骤: 编写dockerFile文件 docker build构建成为一个镜像 docker run运行 ...
- react中使用截图组件Cropper组件
--最近项目用react,学习react并使用cropper组件裁剪图片. (这里开发组件不够统一有用tsx(TypeScript + xml/html)写的组件,有用jsx(javascript+x ...
- bzoj3879 SvT(后缀自动机+虚树)
bzoj3879 SvT(后缀自动机+虚树) bzoj 有一个长度为n的仅包含小写字母的字符串S,下标范围为[1,n]. 现在有若干组询问,对于每一个询问,我们给出若干个后缀(以其在S中出现的起始位置 ...
- js file对象 文件大小转换可视容易阅读的单位
function returnFileSize(number) { if(number < 1024) { return number + 'bytes'; } else if(number & ...
- 什么是 NetflixFeign?它的优点是什么?
Feign 是受到 Retrofit,JAXRS-2.0 和 WebSocket 启发的 java 客户端联编程序.Feign 的第一个目标是将约束分母的复杂性统一到 http apis,而不考虑其稳定 ...
- 如何实现集群中的 session 共享存储?
Session 是运行在一台服务器上的,所有的访问都会到达我们的唯一服务器上,这 样我们可以根据客户端传来的 sessionID,来获取 session,或在对应 Session 不 存在的情况下(s ...
- Less使用@import进行Mixins
Import 指令 从其他样式表导入样式 在标准CSS中,@ import at-rules必须在所有其他类型的规则之前.但Less.js并不关心你放置@import语句的位置 Example: .f ...
- elasticsearch 的倒排索引是什么 ?
解答:通俗解释一下就可以. 传统的我们的检索是通过文章,逐个遍历找到对应关键词的位置. 而倒排索引,是通过分词策略,形成了词和文章的映射关系表,这种词典+映射表 即为倒排索引. 有了倒排索引,就能实现 ...