实践GoF的设计模式:迭代器模式
摘要:迭代器模式主要用在访问对象集合的场景,能够向客户端隐藏集合的实现细节。
本文分享自华为云社区《【Go实现】实践GoF的23种设计模式:迭代器模式》,作者:元闰子。
简介
有时会遇到这样的需求,开发一个模块,用于保存对象;不能用简单的数组、列表,得是红黑树、跳表等较为复杂的数据结构;有时为了提升存储效率或持久化,还得将对象序列化;但必须给客户端提供一个易用的 API,允许方便地、多种方式地遍历对象,丝毫不察觉背后的数据结构有多复杂。
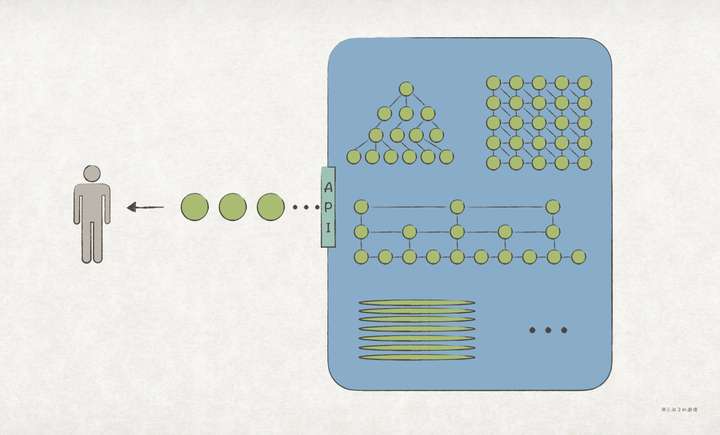
对这样的 API,很适合使用 迭代器模式(Iterator Pattern)实现。
GoF 对 迭代器模式 的定义如下:
Provide a way to access the elements of an aggregate object sequentially without exposing its underlying representation.
从描述可知,迭代器模式主要用在访问对象集合的场景,能够向客户端隐藏集合的实现细节。
Java 的 Collection 家族、C++ 的 STL 标准库,都是使用迭代器模式的典范,它们为客户端提供了简单易用的 API,并且能够根据业务需要实现自己的迭代器,具备很好的可扩展性。
UML 结构
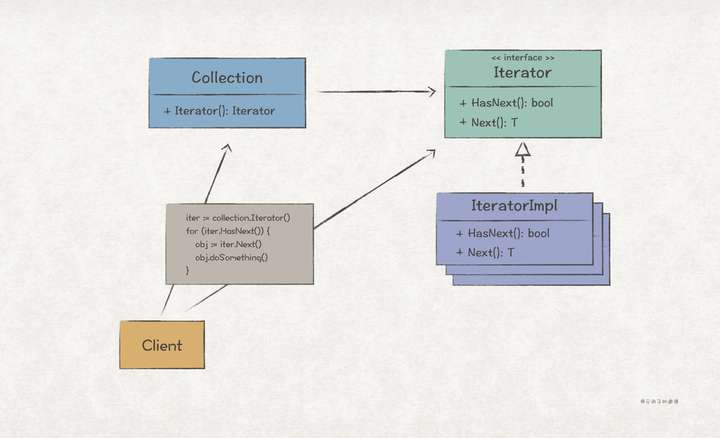
场景上下文
在简单的分布式应用系统(示例代码工程)中,db 模块用来存储服务注册和监控信息,它的主要接口如下:
// demo/db/db.go
package db
// Db 数据库抽象接口
type Db interface {
CreateTable(t *Table) error
CreateTableIfNotExist(t *Table) error
DeleteTable(tableName string) error
Query(tableName string, primaryKey interface{}, result interface{}) error
Insert(tableName string, primaryKey interface{}, record interface{}) error
Update(tableName string, primaryKey interface{}, record interface{}) error
Delete(tableName string, primaryKey interface{}) error
...
}
从增删查改接口可以看出,它是一个 key-value 数据库,另外,为了提供类似关系型数据库的按列查询能力,我们又抽象出 Table 对象:
// demo/db/table.go
package db
// Table 数据表定义
type Table struct {
name string
recordType reflect.Type
records map[interface{}]record
}
其中,Table 底层用 map 存储对象数据,但并没有存储对象本身,而是从对象转换而成的 record 。record 的实现原理是利用反射机制,将对象的属性名 field 和属性值 value 分开存储,以此支持按列查询能力(一类对象可以类比为一张表):
// demo/db/record.go
package db
type record struct {
primaryKey interface{}
fields map[string]int // key为属性名,value属性值的索引
values []interface{} // 存储属性值
}
// 从对象转换成record
func recordFrom(key interface{}, value interface{}) (r record, e error) {
... // 异常处理
vType := reflect.TypeOf(value)
vVal := reflect.ValueOf(value)
if vVal.Type().Kind() == reflect.Pointer {
vType = vType.Elem()
vVal = vVal.Elem()
}
record := record{
primaryKey: key,
fields: make(map[string]int, vVal.NumField()),
values: make([]interface{}, vVal.NumField()),
}
for i := 0; i < vVal.NumField(); i++ {
fieldType := vType.Field(i)
fieldVal := vVal.Field(i)
name := strings.ToLower(fieldType.Name)
record.fields[name] = i
record.values[i] = fieldVal.Interface()
}
return record, nil
}
当然,客户端并不会察觉 db 模块背后的复杂机制,它们直接使用的仍是对象:
type testRegion struct {
Id int
Name string
}
func client() {
mdb := db.MemoryDbInstance()
tableName := "testRegion"
table := NewTable(tableName).WithType(reflect.TypeOf(new(testRegion)))
mdb.CreateTable(table)
mdb.Insert(tableName, "region1", &testRegion{Id: 0, Name: "region-1"})
result := new(testRegion)
mdb.Query(tableName, "region1", result)
}
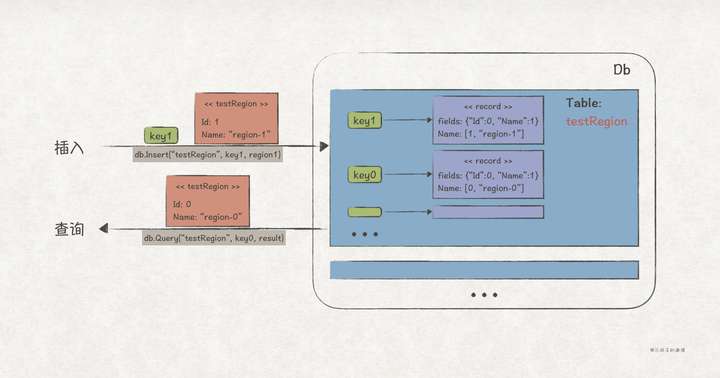
另外,除了上述按 Key 查询接口,我们还想提供全表查询接口,有随机和有序 2 种表记录遍历方式,并且支持客户端自己扩展遍历方式。下面使用迭代器模式来实现该需求。
代码实现
这里并没有按照标准的 UML 结构去实现,而是结合工厂方法模式来解决公共代码的复用问题:
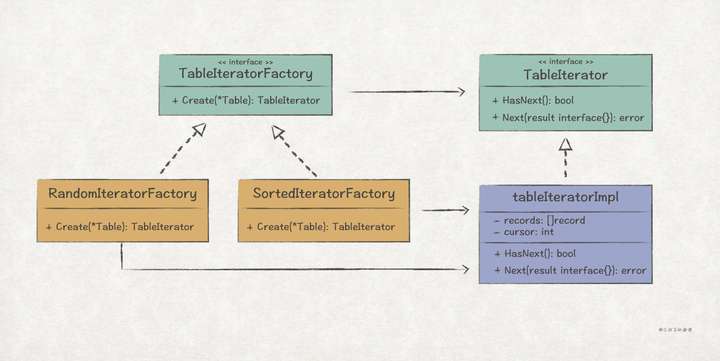
// demo/db/table_iterator.go
package db
// 关键点1: 定义迭代器抽象接口,允许后续客户端扩展遍历方式
// TableIterator 表迭代器接口
type TableIterator interface {
HasNext() bool
Next(next interface{}) error
}
// 关键点2: 定义迭代器接口的实现
// tableIteratorImpl 迭代器接口公共实现类
type tableIteratorImpl struct {
// 关键点3: 定义一个集合存储待遍历的记录,这里的记录已经排序好或者随机打散
records []record
// 关键点4: 定义一个cursor游标记录当前遍历的位置
cursor int
}
// 关键点5: 在HasNext函数中的判断是否已经遍历完所有记录
func (r *tableIteratorImpl) HasNext() bool {
return r.cursor < len(r.records)
}
// 关键点6: 在Next函数中取出下一个记录,并转换成客户端期望的对象类型,记得增加cursor
func (r *tableIteratorImpl) Next(next interface{}) error {
record := r.records[r.cursor]
r.cursor++
if err := record.convertByValue(next); err != nil {
return err
}
return nil
}
// 关键点7: 通过工厂方法模式,完成不同类型的迭代器对象创建
// TableIteratorFactory 表迭代器工厂
type TableIteratorFactory interface {
Create(table *Table) TableIterator
}
// 随机迭代器
type randomTableIteratorFactory struct{}
func (r *randomTableIteratorFactory) Create(table *Table) TableIterator {
var records []record
for _, r := range table.records {
records = append(records, r)
}
rand.Seed(time.Now().UnixNano())
rand.Shuffle(len(records), func(i, j int) {
records[i], records[j] = records[j], records[i]
})
return &tableIteratorImpl{
records: records,
cursor: 0,
}
}
// 有序迭代器
// Comparator 如果i<j返回true,否则返回false
type Comparator func(i, j interface{}) bool
// sortedTableIteratorFactory 根据主键进行排序,排序逻辑由Comparator定义
type sortedTableIteratorFactory struct {
comparator Comparator
}
func (s *sortedTableIteratorFactory) Create(table *Table) TableIterator {
var records []record
for _, r := range table.records {
records = append(records, r)
}
sort.Sort(newRecords(records, s.comparator))
return &tableIteratorImpl{
records: records,
cursor: 0,
}
}
最后,为 Table 对象引入 TableIterator:
// demo/db/table.go
// Table 数据表定义
type Table struct {
name string
recordType reflect.Type
records map[interface{}]record
// 关键点8: 持有迭代器工厂方法接口
iteratorFactory TableIteratorFactory // 默认使用随机迭代器
}
// 关键点9: 定义Setter方法,提供迭代器工厂的依赖注入
func (t *Table) WithTableIteratorFactory(iteratorFactory TableIteratorFactory) *Table {
t.iteratorFactory = iteratorFactory
return t
}
// 关键点10: 定义创建迭代器的接口,其中调用迭代器工厂完成实例化
func (t *Table) Iterator() TableIterator {
return t.iteratorFactory.Create(t)
}
客户端这样使用:
func client() {
table := NewTable("testRegion").WithType(reflect.TypeOf(new(testRegion))).
WithTableIteratorFactory(NewSortedTableIteratorFactory(regionIdComparator))
iter := table.Iterator()
for iter.HashNext() {
next := new(testRegion)
err := iter.Next(next)
...
}
}
总结实现迭代器模式的几个关键点:
- 定义迭代器抽象接口,目的是提供客户端自扩展能力,通常包含 HashNext() 和 Next() 两个方法,上述例子为 TableIterator。
- 定义迭代器接口的实现类,上述例子为 tableIteratorImpl,这里主要起到了 Java/C++ 等带继承特性语言中,基类的作用,目的是复用代码。
- 在实现类中持有待遍历的记录集合,通常是已经排序好或随机打散后的,上述例子为 tableIteratorImpl.records。
- 在实现类中持有游标值,记录当前遍历的位置,上述例子为 tableIteratorImpl.cursor。
- 在 HashNext() 方法中判断是否已经遍历完所有记录。
- 在 Next() 方法中取出下一个记录,并转换成客户端期望的对象类型,取完后增加游标值。
- 通过工厂方法模式,完成不同类型的迭代器对象创建,上述例子为 TableIteratorFactory 接口,以及它的实现,randomTableIteratorFactory 和 sortedTableIteratorFactory。
- 在待遍历的对象中,持有迭代器工厂方法接口,上述例子为 Table.iteratorFactory。
- 为对象定义 Setter 方法,提供迭代器工厂的依赖注入,上述例子为 Table.WithTableIteratorFactory() 方法。
- 为对象定义创建迭代器的接口,上述例子为 Table.Iterator() 方法。
其中,7~9 步是结合工厂方法模式实现时的特有步骤,如果你的迭代器实现中没有用到工厂方法模式,可以省略这几步。
扩展
Go 风格的实现
前面的实现,是典型的面向对象风格,下面以随机迭代器为例,给出一个 Go 风格的实现:
// demo/db/table_iterator_closure.go
package db
// 关键点1: 定义HasNext和Next函数类型
type HasNext func() bool
type Next func(interface{}) error
// 关键点2: 定义创建迭代器的方法,返回HashNext和Next函数
func (t *Table) ClosureIterator() (HasNext, Next) {
var records []record
for _, r := range t.records {
records = append(records, r)
}
rand.Seed(time.Now().UnixNano())
rand.Shuffle(len(records), func(i, j int) {
records[i], records[j] = records[j], records[i]
})
size := len(records)
cursor := 0
// 关键点3: 在迭代器创建方法定义HasNext和Next的实现逻辑
hasNext := func() bool {
return cursor < size
}
next := func(next interface{}) error {
record := records[cursor]
cursor++
if err := record.convertByValue(next); err != nil {
return err
}
return nil
}
return hasNext, next
}
客户端这样用:
func client() {
table := NewTable("testRegion").WithType(reflect.TypeOf(new(testRegion))).
WithTableIteratorFactory(NewSortedTableIteratorFactory(regionIdComparator))
hasNext, next := table.ClosureIterator()
for hasNext() {
result := new(testRegion)
err := next(result)
...
}
}
Go 风格的实现,利用了函数闭包的特点,把原本在迭代器实现的逻辑,放到了迭代器创建方法上。相比面向对象风格,省掉了迭代器抽象接口和实现对象的定义,看起来更加的简洁。
总结几个实现关键点:
- 声明 HashNext 和 Next 的函数类型,等同于迭代器抽象接口的作用。
- 定义迭代器创建方法,返回类型为 HashNext 和 Next,上述例子为 ClosureIterator() 方法。
- 在迭代器创建方法内,定义 HasNext 和 Next 的具体实现,利用函数闭包来传递状态(records 和 cursor)。
基于 channel 的实现
我们还能基于 Go 语言中的 channel 来实现迭代器模式,因为前文的 db 模块应用场景并不适用,所以另举一个简单的例子:
type Record int
func (r *Record) doSomething() {
// ...
}
type ComplexCollection struct {
records []Record
}
// 关键点1: 定义迭代器创建方法,返回只能接收的channel类型
func (c *ComplexCollection) Iterator() <-chan Record {
// 关键点2: 创建一个无缓冲的channel
ch := make(chan Record)
// 关键点3: 另起一个goroutine往channel写入记录,如果接收端还没开始接收,会阻塞住
go func() {
for _, record := range c.records {
ch <- record
}
// 关键点4: 写完后,关闭channel
close(ch)
}()
return ch
}
客户端这样使用:
func client() {
collection := NewComplexCollection()
// 关键点5: 使用时,直接通过for-range来遍历channel读取记录
for record := range collection.Iterator() {
record.doSomething()
}
}
总结实现基于 channel 的迭代器模式的几个关键点:
- 定义迭代器创建方法,返回一个只能接收的 channel。
- 在迭代器创建方法中,定义一个无缓冲的 channel。
- 另起一个 goroutine 往 channel 中写入记录。如果接收端没有接收,会阻塞住。
- 写完后,关闭 channel。
- 客户端使用时,直接通过 for-range 遍历 channel 读取记录即可。
带有 callback 函数的实现
还可以在创建迭代器时,传入一个 callback 函数,在迭代器返回记录前,先调用 callback 函数对记录进行一些操作。
比如,在基于 channel 的实现例子中,可以增加一个 callback 函数,将每个记录打印出来:
// 关键点1: 声明callback函数类型,以Record作为入参
type Callback func(record *Record)
//关键点2: 定义具体的callback函数
func PrintRecord(record *Record) {
fmt.Printf("%+v\n", record)
}
// 关键点3: 定义以callback函数作为入参的迭代器创建方法
func (c *ComplexCollection) Iterator(callback Callback) <-chan Record {
ch := make(chan Record)
go func() {
for _, record := range c.records {
// 关键点4: 遍历记录时,调用callback函数作用在每条记录上
callback(&record)
ch <- record
}
close(ch)
}()
return ch
}
func client() {
collection := NewComplexCollection()
// 关键点5: 创建迭代器时,传入具体的callback函数
for record := range collection.Iterator(PrintRecord) {
record.doSomething()
}
}
总结实现带有 callback 的迭代器模式的几个关键点:
- 声明 callback 函数类型,以 Record 作为入参。
- 定义具体的 callback 函数,比如上述例子中打印记录的 PrintRecord 函数。
- 定义迭代器创建方法,以 callback 函数作为入参。
- 迭代器内,遍历记录时,调用 callback 函数作用在每条记录上。
- 客户端创建迭代器时,传入具体的 callback 函数。
典型应用场景
- 对象集合/存储类模块,并希望向客户端隐藏模块背后的复杂数据结构。
- 希望支持客户端自扩展多种遍历方式。
优缺点
优点
- 隐藏模块背后复杂的实现机制,为客户端提供一个简单易用的接口。
- 支持扩展多种遍历方式,具备较强的可扩展性,符合开闭原则。
- 遍历算法和数据存储分离,符合单一职责原则。
缺点
- 容易滥用,比如给简单的集合类型实现迭代器接口,反而使代码更复杂。
- 相比于直接遍历集合,迭代器效率要更低一些,因为涉及到更多对象的创建,以及可能的对象拷贝。
- 需要时刻注意在迭代器遍历过程中,由原始集合发生变更引发的并发问题。一种解决方法是,在创建迭代器时,拷贝一份原始数据(TableIterator 就这么实现),但存在效率低、内存占用大的问题。
与其他模式的关联
迭代器模式通常会与工厂方法模 一起使用,如前文实现。
文章配图
可以在用Keynote画出手绘风格的配图中找到文章的绘图方法。
参考
[1] 【Go实现】实践GoF的23种设计模式:SOLID原则, 元闰子
[2] 【Go实现】实践GoF的23种设计模式:工厂方法模式, 元闰子
[3] Design Patterns, Chapter 5. Behavioral Patterns, GoF
[4] Iterators in Go, Ewen Cheslack-Postava
[5] 迭代器模式, refactoringguru.cn
实践GoF的设计模式:迭代器模式的更多相关文章
- 19. 星际争霸之php设计模式--迭代器模式
题记==============================================================================本php设计模式专辑来源于博客(jymo ...
- java设计模式——迭代器模式
一. 定义与类型 定义:提供一种方法,顺序访问一个集合对象中的各个元素,而又不暴露该对象的内部表示 类型:行为型. 二. 使用场景 (1) 访问一个集合对象的内容而无需暴露它的内部表示 (2) 为遍 ...
- 深入浅出设计模式——迭代器模式(Iterator Pattern)
模式动机 一个聚合对象,如一个列表(List)或者一个集合(Set),应该提供一种方法来让别人可以访问它的元素,而又不需要暴露它的内部结构.针对不同的需要,可能还要以不同的方式遍历整个聚合对象,但是我 ...
- JavaScript设计模式 - 迭代器模式
迭代器模式是指提供一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示. 迭代器模式可以把迭代的过程从业务逻辑中分离出来,在使用迭代器模式之后,即使不关心对象的内部构造,也可以按顺 ...
- C++设计模式——迭代器模式
前言 最近非常感伤,总是怀念大学的日子,做梦的时候也常常梦到.梦到大学在电脑前傻傻的敲着键盘,写着代码,对付着数据结构与算法的作业:建立一个链表,遍历链表,打印链表.现在把那个时候声明的链表的头文件拿 ...
- [Head First设计模式]生活中学设计模式——迭代器模式
系列文章 [Head First设计模式]山西面馆中的设计模式——装饰者模式 [Head First设计模式]山西面馆中的设计模式——观察者模式 [Head First设计模式]山西面馆中的设计模式— ...
- JAVA 设计模式 迭代器模式
用途 迭代器模式 (Iterator) 提供一种方法顺序访问一个聚合对象中各个元素,而又不暴露该对象的内部表示. 迭代器模式是一种行为型模式. 结构
- javascript设计模式-迭代器模式(Iterator)
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 设计模式 --迭代器模式(Iterator)
能够游走于聚合内的每一个元素,同时还可以提供多种不同的遍历方式. 基本概念: 就是提供一种方法顺序访问一个聚合对象中的各个元素,而不是暴露其内部的表示. 使用迭代器模式的优点: 遍历集合或者数 ...
随机推荐
- ELK 1.3之kibana
1.安装kibana,直接压缩包安装就可以,kibana默认端口5601 2.配置kibana配置文件 [root@kibana config]# vim /opt/kibana/config/kib ...
- @Inherited 原注解功能介绍
@Inherited 底层 package java.lang.annotation; /** * Indicates that an annotation type is automatically ...
- netty系列之:使用Jboss Marshalling来序列化java对象
目录 简介 添加JBoss Marshalling依赖 JBoss Marshalling的使用 总结 简介 在JAVA程序中经常会用到序列化的场景,除了JDK自身提供的Serializable之外, ...
- 基于.NetCore开发博客项目 StarBlog - (8) 分类层级结构展示
系列文章 基于.NetCore开发博客项目 StarBlog - (1) 为什么需要自己写一个博客? 基于.NetCore开发博客项目 StarBlog - (2) 环境准备和创建项目 基于.NetC ...
- 负载均衡之DR实验
实验环境 本实验搭建在虚拟机中.一台服务器作为DR两台作为RS,还有一台为后续内容会用到的备用机. 实验环境示意图: 1. 修改网络层VIP 修改DR,添加VIP 修改前: 修改后: 修改RS,修改A ...
- 面试官:Dubbo是什么,他有什么特性?
哈喽!大家好,我是小奇,一位热爱分享的程序员 小奇打算以轻松幽默的对话方式来分享一些技术,如果你觉得通过小奇的文章学到了东西,那就给小奇一个赞吧 文章持续更新 一.前言 书接上回,今天还是过周末,虽然 ...
- 我的第一个开源作品Kiwis2 Mock Server
我的第一个开源作品Kiwis2 Mock Server,目前公测中,欢迎大家提供宝贵意见. 代码:https://github.com/kiwis2/mockserver 主页:https://kiw ...
- go-zero 微服务实战系列(一、开篇)
前言 在社区中经常看到有人问有没有基于 go-zero 的比较完整的项目参考,该类问题本质上是想知道基于 go-zero 的项目的最佳实践.完整的项目应该是一个完整的产品功能,包含产品需求.架构设计. ...
- 支付宝开放平台--网页&移动应用(一)
前提是先在支付宝上签约自己需要的支付宝功能,然后支付宝开放平台才能设置你需要的功能 一:支付宝开放平台登录 登录进入支付宝开放平台 二:根据自己的需求创建应用(我是用的网页&移动应用) 三:点 ...
- Linux系统sed命令常用参数实战
Linux系统sed命令常用参数实战 常用参数 -n 输出某行的文本内容,通常与p联合使用, -e 命令行模式下进行sed的动作编辑,输出编辑后的内容,源文件不会发生变化 -f 以命令中指定的scri ...