基于mnist的P-R曲线(准确率,召回率)
一.准确率,召回率
- TP(True Positive):正确的正例,一个实例是正类并且也被判定成正类
- FN(False Negative):错误的反例,漏报,本为正类但判定为假类
- FP(False Positive):错误的正例,误报,本为假类但判定为正类
- TN(True Negative):正确的反例,一个实例是假类并且也被判定成假类
准确率
所有的预测正确(正类负类)的占总的比重。
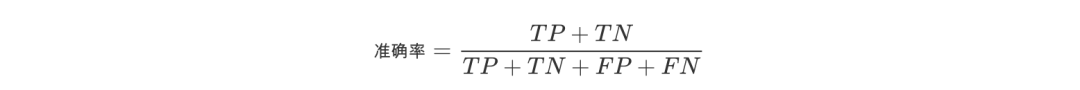
召回率
即正确预测为正的占全部实际为正的比例。
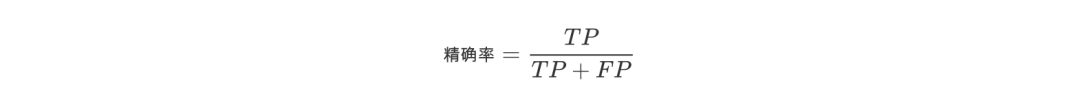
PR-曲线
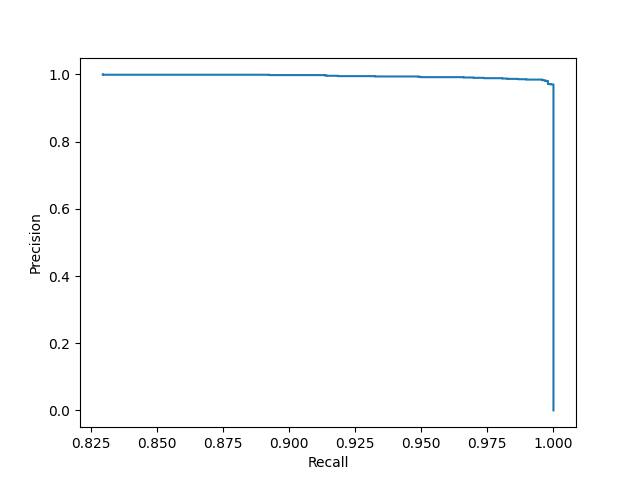
PR曲线是以召回率作为横坐标轴,精确率作为纵坐标轴,遍历所有的阈值,绘制出的曲线。
二. 代码
1.train
import torch
import torch.nn as nn
import torchvision.transforms
import os device=torch.device('cuda:0')
num_epoch=5
num_classes=2
batch_size=32
learning_rate=0.001
chack_number=8 train_dataset=torchvision.datasets.MNIST(root='../MNIST_data/',
train=True, #train(bool,可选)–如果为True,则从training.pt创建数据集,否则从test.pt创建数据集。
download=True,
transform=torchvision.transforms.ToTensor() #接受PIL图像并返回已转换版本的函数/转换。E、 g,变换。随机裁剪
)
test_dataset=torchvision.datasets.MNIST(root='../MNIST_data/',
train=False,
transform=torchvision.transforms.ToTensor()) #Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=False) class ConvNet(nn.Module):
def __init__(self, num_classes=2):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7 * 7 * 32, num_classes) def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out model=ConvNet(num_classes).to(device) checkpoint_save_path='../mnist_checkpoint_two/model.ckpt'
if os.path.exists(checkpoint_save_path):
print("---------------load the model---------------")
model.load_state_dict(torch.load(checkpoint_save_path)['model_state_dict'])
else :
os.makedirs(os.path.dirname(checkpoint_save_path),exist_ok=True) # Loss and optimizer
criterion=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate) #Train and model
total_step=len(train_loader) loss_plt = []
for epoch in range(num_epoch):
for i,(images,labels) in enumerate(train_loader):
images=images.to(device)
labels=labels.to(device)
labels = torch.tensor([1 if i == chack_number else 0 for i in labels]).to(device) #forward
output=model(images)
loss=criterion(output,labels) #backward
optimizer.zero_grad()
loss.backward()
optimizer.step() if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epoch, i+1, total_step, loss.item()))
loss_plt.append(loss.sum().mean().item()) torch.save({'model_state_dict':model.state_dict(),
},
checkpoint_save_path)
2.predict
import torch
import torch.nn as nn
import numpy as np
import torchvision
import matplotlib.pyplot as plt
import os
from sklearn.metrics import precision_recall_curve device=torch.device('cuda:0')
num_epoch=1
num_classes=10
batch_size=1 train_dataset=torchvision.datasets.MNIST(root='../MNIST_data/',
train=True, #train(bool,可选)–如果为True,则从training.pt创建数据集,否则从test.pt创建数据集。
download=True,
transform=torchvision.transforms.ToTensor() #接受PIL图像并返回已转换版本的函数/转换。E、 g,变换。随机裁剪
)
test_dataset=torchvision.datasets.MNIST(root='../MNIST_data/',
train=False,
transform=torchvision.transforms.ToTensor()) #显示图片
# image=test_dataset[0][0].view(28,28)
# plt.gray()
# plt.axis('off')
# plt.imshow(image)
# plt.show()
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True) test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False) class ConvNet(nn.Module):
def __init__(self, num_classes=2):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7 * 7 * 32, num_classes) def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out checkpoint_save_path='../mnist_checkpoint_two/model.ckpt'
model=ConvNet()
model=model.to(device)
if os.path.exists(checkpoint_save_path):
print("---------------load the model---------------")
model.load_state_dict(torch.load(checkpoint_save_path)['model_state_dict'])
#pred
model.eval()
with torch.no_grad():
check_number=8
y_pred=[]#预测得分
y_true=[]
for i,(images,labels) in enumerate(test_loader):
images=images.to(device)
labels=labels.to(device)
labels = torch.tensor([1 if i == check_number else 0 for i in labels]).to(device) #将多分类转为2分类
outputs=model(images)
pred=torch.sigmoid(outputs)[0][1]
y_true.append(labels.to('cpu')[0])
y_pred.append(pred.to('cpu'))
# _, pred = torch.max(outputs.data, 1)
# if i ==10000:
# break y_pred=np.array(y_pred)
y_true=np.array(y_true)
precision, recall, thresholds = precision_recall_curve(y_true, y_pred)
#plt画图
plt.ylabel('Recall')
plt.xlabel('Precision')
plt.plot(precision,recall)
plt.show()
3.P-R曲线
基于mnist的P-R曲线(准确率,召回率)的更多相关文章
- 准确率,召回率,F值,ROC,AUC
度量表 1.准确率 (presion) p=TPTP+FP 理解为你预测对的正例数占你预测正例总量的比率,假设实际有90个正例,10个负例,你预测80(75+,5-)个正例,20(15+,5-)个负例 ...
- 准确率P 召回率R
Evaluation metricsa binary classifier accuracy,specificity,sensitivety.(整个分类器的准确性,正确率,错误率)表示分类正确:Tru ...
- 机器学习 F1-Score 精确率 - P 准确率 -Acc 召回率 - R
准确率 召回率 精确率 : 准确率->accuracy, 精确率->precision. 召回率-> recall. 三者很像,但是并不同,简单来说三者的目的对象并不相同. 大多时候 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
yu Code 15 Comments 机器学习(ML),自然语言处理(NLP),信息检索(IR)等领域,评估(Evaluation)是一个必要的 工作,而其评价指标往往有如下几点:准确率(Accu ...
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
原文地址:http://blog.csdn.net/pkueecser/article/details/8229166 在信息检索.分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常 ...
- fashion_mnist 计算准确率、召回率、F1值
本文发布于 2020-12-27,很可能已经过时 fashion_mnist 计算准确率.召回率.F1值 1.定义 首先需要明确几个概念: 假设某次预测结果统计为下图: 那么各个指标的计算方法为: A ...
- 机器学习classification_report方法及precision精确率和recall召回率 说明
classification_report简介 sklearn中的classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息. 主要 ...
- ROC 曲线/准确率、覆盖率(召回)、命中率、Specificity(负例的覆盖率)
欢迎关注博主主页,学习python视频资源 sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程) https://study.163.com/course/introduction.ht ...
- 混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值
准确率.精确率(查准率).召回率(查全率).F1值.ROC曲线的AUC值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前 ...
随机推荐
- Web 前端实战:JQ 实现下拉菜单
实现过程 实现一个简易的鼠标悬停菜单项显示其子项的下拉框控件.将用到 CSS 绝对定位.流式布局.动画等:JQuery 鼠标移入和移出事件.DOM 查找.效果图如下: HTML 结构: <div ...
- Unity 将是驱动 C# 增长的引擎吗 ?
C# 在中国的采用需要一个杀手级应用的带动, 那么这样的一个杀手级应用是 Unity吗,我这里大胆推测采用CoreCLR 的新一代完全采用C#构建的Unity 将是这样的一个杀手级应用.Unity已被 ...
- 【Swift】从零开始的Swift语言学习笔记-1:前言&Hello World
该系列分为两个大的部分. Swift基本语法 使用Xcode编写iOS应用程式 两个部分会双线并行更新. 本人的学习资料大多为Apple Develop官方上的生肉,难免会有疏漏,望斧正. 另外该系列 ...
- 部署k8s的heapster监控
Heapster是容器集群监控和性能分析工具,天然的支持Kubernetes和CoreOS heapster监控目前官网已经不更新,部署学习使用 heapster: 收集监控数据 influxdb:数 ...
- 给ShardingSphere提了个PR,不知道是不是嫌弃我
说来惭愧,干了 10 来年程序员,还没有给开源做过任何贡献,以前只知道嘎嘎写,出了问题嘎嘎改,从来没想过提个 PR 去修复他,最近碰到个问题,发现挺简单的,就随手提了个 PR 过去. 问题 问题挺简单 ...
- Python自学笔记11-函数的定义和调用
函数是组织代码的非常有效的方式,有了函数,我们就可以编写大规模的项目.可以说,函数是组织代码的最小单元. Python函数的定义 函数是代码封装的一种手段,函数中包含一段可以重复执行的代码,在需要用到 ...
- 移动教室APP
软件名:VERIMAG 官网链接:http://www.verimag.ru/mobilnoe-obrazovanie.html 移动课堂,充满活力的气息.走在时代前沿的同时,也对教育者对于编制课件的 ...
- 如何高效解决 C++内存问题,Apache Doris 实践之路|技术解析
导读:Apache Doris 使用 C++ 语言实现了执行引擎,C++ 开发过程中,影响开发效率的一个重要因素是指针的使用,包括非法访问.泄露.强制类型转换等.本文将会通过对 Sanitizer 和 ...
- 从零开始搭建gitea代码管理平台
Gitea,一款极易搭建的Git自助服务.如其名,Git with a cup of tea.跨平台的开源服务,支持Linux.Windows.macOS和ARM平台.配置要求低,甚至可以运行在树莓派 ...
- Awvs+nessus docker版本
awvs-nessus 拉取镜像 docker pull leishianquan/awvs-nessus:v2 启动 docker run --name awvs-nessus -it -d -p ...