k8s驱逐篇(3)-kubelet节点压力驱逐-源码分析篇
kubelet节点压力驱逐-概述
kubelet监控集群节点的 CPU、内存、磁盘空间和文件系统的inode 等资源,根据kubelet启动参数中的驱逐策略配置,当这些资源中的一个或者多个达到特定的消耗水平,kubelet 可以主动地驱逐节点上一个或者多个pod,以回收资源,降低节点资源压力。
驱逐信号
节点上的memory、nodefs、pid等资源都有驱逐信号,kubelet通过将驱逐信号与驱逐策略进行比较来做出驱逐决定;
驱逐策略
kubelet节点压力驱逐包括了两种,软驱逐和硬驱逐;
软驱逐
软驱逐机制表示,当node节点的memory、nodefs等资源达到一定的阈值后,需要持续观察一段时间(宽限期),如果期间该资源又恢复到低于阈值,则不进行pod的驱逐,若高于阈值持续了一段时间(宽限期),则触发pod的驱逐。
硬驱逐
硬驱逐策略没有宽限期,当达到硬驱逐条件时,kubelet会立即触发pod的驱逐,而不是优雅终止。
关于kubelet节点压力驱逐的详细介绍,可以查看上一篇文章-kubelet节点压力驱逐;
kubelet节点压力驱逐-源码分析
负责kubelet节点压力驱逐的是kubelet中的evictionManager;
基于kubernets v1.17.4
从kubelet的Run方法为入口,通过一系列的调用,调用了evictionManager.Start方法;
调用链:kubelet.Run() --> kubelet.updateRuntimeUp() --> kubelet.initializeRuntimeDependentModules() --> kubelet.evictionManager.Start()
// pkg/kubelet/kubelet.go
func (kl *Kubelet) Run(updates <-chan kubetypes.PodUpdate) {
...
go wait.Until(kl.updateRuntimeUp, 5*time.Second, wait.NeverStop)
...
}
// pkg/kubelet/kubelet.go
func (kl *Kubelet) updateRuntimeUp() {
...
kl.oneTimeInitializer.Do(kl.initializeRuntimeDependentModules)
...
}
evictionManager在没有发生pod驱逐时,驱逐监测间隔时间为10s;
// pkg/kubelet/kubelet.go
const (
...
evictionMonitoringPeriod = time.Second * 10
...
)
func (kl *Kubelet) initializeRuntimeDependentModules() {
...
kl.evictionManager.Start(kl.StatsProvider, kl.GetActivePods, kl.podResourcesAreReclaimed, evictionMonitoringPeriod)
...
}
1.evictionManager结构体分析
managerImpl struct
分析evictionManager.Start方法前,先来分析下eviction_manager的结构体managerImpl struct,看其有哪些比较重要的属性:
(1)config:存储着eviction_manager的相关配置,根据kubelet启动参数配置值来初始化config;
(2)thresholdsMet:记录已经达到驱逐阈值,但还没有满足驱逐策略条件,触发驱逐的Threshold切片(Threshold后面做介绍);
(3)thresholdsFirstObservedAt:记录各个Threshold的第一次发现时间点;
(4)lastObservations:记录上一次调谐处理中,软驱逐、硬驱逐中各个驱逐信号的资源总量、资源可用量、探测时间;
(5)signalToRankFunc:存储软驱逐、硬驱逐中各个驱逐信号所对应的排序函数,排序函数用于计算被驱逐pod的顺序;
(6)killPodFunc:定义了驱逐pod的具体函数,在eviction_manager初始化的时候,该值被赋值为pkg/kubelet/pod_workers.go-killPodNow()函数;
// pkg/kubelet/eviction/eviction_manager.go
type managerImpl struct {
...
config Config
thresholdsMet []evictionapi.Threshold
thresholdsFirstObservedAt thresholdsObservedAt
lastObservations signalObservations
signalToRankFunc map[evictionapi.Signal]rankFunc
killPodFunc KillPodFunc
...
}
1.1 Config struct
Config存储着eviction_manager的相关配置,根据kubelet启动参数配置值来初始化Config;
其中Config.Thresholds属性存储着配置的驱逐策略信息;
// pkg/kubelet/eviction/types.go
type Config struct {
...
Thresholds []evictionapi.Threshold
MaxPodGracePeriodSeconds int64
PressureTransitionPeriod time.Duration
...
}
1.2 evictionapi.Threshold
看到Threshold结构体,重要的几个属性如下:
(1)Signal:驱逐信号;
(2)Operator:驱逐信号对应资源的实际统计值与驱逐阈值之间的比较运算符;
(3)Value:驱逐阈值;
(4)GracePeriod:驱逐信号对应资源的实际统计值达到驱逐阈值之后需要持续GracePeriod时间后,才会触发驱逐;
(5)MinReclaim:触发驱逐后的资源最小回收值;
// pkg/kubelet/eviction/api/types.go
type Threshold struct {
// Signal defines the entity that was measured.
Signal Signal
// Operator represents a relationship of a signal to a value.
Operator ThresholdOperator
// Value is the threshold the resource is evaluated against.
Value ThresholdValue
// GracePeriod represents the amount of time that a threshold must be met before eviction is triggered.
GracePeriod time.Duration
// MinReclaim represents the minimum amount of resource to reclaim if the threshold is met.
MinReclaim *ThresholdValue
}
1.3 thresholdsObservedAt
thresholdsObservedAt是个map类型,记录各个Threshold及其第一次发现时间点;
type thresholdsObservedAt map[evictionapi.Threshold]time.Time
1.4 signalObservations
signalObservations是个map类型,记录上一次调谐处理中,软驱逐、硬驱逐中各个驱逐信号的资源总量、资源可用量、探测时间;
type signalObservations map[evictionapi.Signal]signalObservation
type signalObservation struct {
// The resource capacity
capacity *resource.Quantity
// The available resource
available *resource.Quantity
// Time at which the observation was taken
time metav1.Time
}
1.5 rankFunc
rankFunc是排序函数,用于计算被驱逐pod的顺序;
其函数入参为pod列表以及一个statsFunc,statsFunc是个函数,返回pod相关资源统计的一个函数;
// pkg/kubelet/eviction/types.go
type statsFunc func(pod *v1.Pod) (statsapi.PodStats, bool)
type rankFunc func(pods []*v1.Pod, stats statsFunc)
// pkg/kubelet/apis/stats/v1alpha1/types.go
type PodStats struct {
// Reference to the measured Pod.
PodRef PodReference `json:"podRef"`
// The time at which data collection for the pod-scoped (e.g. network) stats was (re)started.
StartTime metav1.Time `json:"startTime"`
// Stats of containers in the measured pod.
Containers []ContainerStats `json:"containers" patchStrategy:"merge" patchMergeKey:"name"`
// Stats pertaining to CPU resources consumed by pod cgroup (which includes all containers' resource usage and pod overhead).
CPU *CPUStats `json:"cpu,omitempty"`
// Stats pertaining to memory (RAM) resources consumed by pod cgroup (which includes all containers' resource usage and pod overhead).
Memory *MemoryStats `json:"memory,omitempty"`
// Stats pertaining to network resources.
Network *NetworkStats `json:"network,omitempty"`
// Stats pertaining to volume usage of filesystem resources.
// VolumeStats.UsedBytes is the number of bytes used by the Volume
VolumeStats []VolumeStats `json:"volume,omitempty" patchStrategy:"merge" patchMergeKey:"name"`
// EphemeralStorage reports the total filesystem usage for the containers and emptyDir-backed volumes in the measured Pod.
EphemeralStorage *FsStats `json:"ephemeral-storage,omitempty"`
}
2.evictionManager处理逻辑分析
evictionManager.Start
evictionManager.Start方法中包含了两部分的启动:
(1)实时驱逐:如果配置了KernelMemcgNotification(即kubelet启动参数--experimental-kernel-memcg-notification配置为true,默认为false),则会针对memory内存资源,利用kernel memcg notification,根据内核实时通知,调用m.synchronize方法执行驱逐逻辑(暂不展开分析);
(2)轮询驱逐:拉起一个goroutine,循环调用m.synchronize方法执行驱逐逻辑,如果被驱逐的pod不为空,则调用m.waitForPodsCleanup方法等待被驱逐的pod删除成功,如果没有pod被驱逐,则sleep 10秒后再循环;
// pkg/kubelet/eviction/eviction_manager.go
func (m *managerImpl) Start(diskInfoProvider DiskInfoProvider, podFunc ActivePodsFunc, podCleanedUpFunc PodCleanedUpFunc, monitoringInterval time.Duration) {
thresholdHandler := func(message string) {
klog.Infof(message)
m.synchronize(diskInfoProvider, podFunc)
}
// 启动实时驱逐
if m.config.KernelMemcgNotification {
for _, threshold := range m.config.Thresholds {
if threshold.Signal == evictionapi.SignalMemoryAvailable || threshold.Signal == evictionapi.SignalAllocatableMemoryAvailable {
notifier, err := NewMemoryThresholdNotifier(threshold, m.config.PodCgroupRoot, &CgroupNotifierFactory{}, thresholdHandler)
if err != nil {
klog.Warningf("eviction manager: failed to create memory threshold notifier: %v", err)
} else {
go notifier.Start()
m.thresholdNotifiers = append(m.thresholdNotifiers, notifier)
}
}
}
}
// 启动轮询驱逐
// start the eviction manager monitoring
go func() {
for {
if evictedPods := m.synchronize(diskInfoProvider, podFunc); evictedPods != nil {
klog.Infof("eviction manager: pods %s evicted, waiting for pod to be cleaned up", format.Pods(evictedPods))
m.waitForPodsCleanup(podCleanedUpFunc, evictedPods)
} else {
time.Sleep(monitoringInterval)
}
}
}()
}
2.1 m.synchronize
m.synchronize方法为kubelet节点压力驱逐的核心处理方法,方法中会根据kubelet配置的驱逐策略,计算并判断是否符合驱逐条件,符合则根据一定的优先级来驱逐pod,然后返回被驱逐的pod(每次调用m.synchronize方法最多只会驱逐一个pod);
且这里说的驱逐pod,只是将pod.status.phase值更新为Failed,并附上驱逐reason:Evicted以及触发驱逐的详细信息,不会删除pod;而pod.status.phase值被更新为Failed后,replicaset controller会再次创建出新的pod调用到其他节点上,达到驱逐pod的效果;
方法主要逻辑为:
(1)从kubelet启动参数中获取驱逐策略配置,返回thresholds;
(2)判断imageFs和rootfs是否为同一个,然后调用buildSignalToRankFunc函数来构建pod的排序函数(buildSignalToRankFunc函数返回软驱逐、硬驱逐中各个驱逐信号所对应的排序函数,排序函数用于计算被驱逐pod的顺序),调用buildSignalToNodeReclaimFuncs函数构建节点资源回收函数(用于后续在执行驱逐pod之前,先调用节点资源回收函数来回收资源,如果回收的资源足够,则不用走驱逐逻辑);
(3)调用podFunc,即调用kl.GetActivePods方法,获取会被驱逐的pod列表-activePods;
(4)调用m.summaryProvider.Get,获取各种统计信息,如节点上各个资源的总量以及使用量情况、容器的资源声明及使用量情况等;
(5)ThresholdNotifier相关的通知实现,ThresholdNotifier-基于观察者模式实现对特殊资源驱逐管理的支持;
(6)调用makeSignalObservations函数,根据前面获取到的节点资源总量及使用量等各种统计信息,组装返回observations,并返回获取pod资源总量及使用量等统计信息的方法statsFunc,该方法后面会用到;
(7)调用thresholdsMet函数,比较observations中的资源使用量和thresholds中的驱逐策略配置阈值之间的大小,将超过阈值的驱逐信号(即memory.available、nodefs.available等)组装成thresholds返回;
(8)判断m.thresholdsMet(m.thresholdsMet记录了已经达到驱逐阈值,但还没有满足驱逐策略条件,触发驱逐的Threshold切片)长度是否大于0,大于0则调用mergeThresholds函数,将上面得到的thresholds与m.thresholdsMet合并;
(9)调用thresholdsFirstObservedAt函数,传入thresholds与m.thresholdsFirstObservedAt(记录各个Threshold的第一次发现时间点),记录并更新各个驱逐信号的第一次超过阈值的时间,返回thresholdsFirstObservedAt;
(10)调用nodeConditionsObservedSince函数,判断距离上次更新nodeCondition时间是否已经超过了m.config.PressureTransitionPeriod(即kubelet启动参数配置--eviction-pressure-transition-period),超过则更新nodeConditions并返回(这里还没有把nodeCondition更新到node对象中去);
(11)调用thresholdsMetGracePeriod函数,筛选出驱逐信号达到驱逐阈值并持续了evictionSoftGracePeriod时间的(即kubelet启动参数配置--eviction-soft-grace-period),组装并返回thresholds,此时的thresholds是满足驱逐策略即将触发驱逐的thresholds;
(12)更新managerImpl的部分成员变量的值,如nodeConditions、thresholdsFirstObservedAt、nodeConditionsLastObservedAt、thresholdsMet、lastObservations;
(13)判断LocalStorageCapacityIsolation即localStorage驱逐的featuregate是否开启,是则先调用m.localStorageEviction处理localstorage驱逐,如果返回驱逐的pod列表不为空,则证明是localStorage触发的驱逐,且已经处理完毕,直接return;
(14)判断即将触发驱逐的thresholds长度是否为0,是则代表没有触发驱逐,不需要执行驱逐逻辑,直接return;
(15)调用sort.Sort(byEvictionPriority(thresholds)),给thresholds排序,将内存排在所有其他资源信号之前,并将没有资源可回收的阈值排在最后;
(16)根据排序结果,调用getReclaimableThreshold,遍历thresholds,从中获取第一个可以被回收的threshold,返回thresholdToReclaim;
(17)调用m.reclaimNodeLevelResources,回收上面获取到的节点级的资源thresholdToReclaim,如果回收的资源足够,则直接return,不需要往下执行驱逐pod的逻辑;
(18)调用m.signalToRankFunc[thresholdToReclaim.Signal],获取对应驱逐信号的pod排序函数;
(19)判断activePods长度是否为0,是则直接return,没有可被驱逐的pod,无法执行驱逐逻辑;
(20)调用rank(activePods, statsFunc),根据之前获取到的pod排序算法,给pod列表进行排序,再次得到activePods,用于后面驱逐pod;
(21)遍历activePods列表,获取pod的gracePeriod(硬驱逐为0,软驱逐则根据kubelet启动参数--eviction-max-pod-grace-period配置值获得),调用evictionMessage函数,构造驱逐message,后续更新到pod的event和status中,用于说明为什么发生驱逐,最后调用m.evictPod,判断pod能否被驱逐,能则开始驱逐pod;
但这里要注意的是,每次调用m.synchronize方法,最多只驱逐一个pod,驱逐成功一个pod则直接return;
// pkg/kubelet/eviction/eviction_manager.go
func (m *managerImpl) synchronize(diskInfoProvider DiskInfoProvider, podFunc ActivePodsFunc) []*v1.Pod {
// (1)获取驱逐策略配置
// if we have nothing to do, just return
thresholds := m.config.Thresholds
if len(thresholds) == 0 && !utilfeature.DefaultFeatureGate.Enabled(features.LocalStorageCapacityIsolation) {
return nil
}
klog.V(3).Infof("eviction manager: synchronize housekeeping")
// build the ranking functions (if not yet known)
// TODO: have a function in cadvisor that lets us know if global housekeeping has completed
if m.dedicatedImageFs == nil {
hasImageFs, ok := diskInfoProvider.HasDedicatedImageFs()
if ok != nil {
return nil
}
m.dedicatedImageFs = &hasImageFs
// (2)调用`buildSignalToRankFunc`函数来构建pod的排序函数(buildSignalToRankFunc函数返回软驱逐、硬驱逐中各个驱逐信号所对应的排序函数,排序函数用于计算被驱逐pod的顺序)
m.signalToRankFunc = buildSignalToRankFunc(hasImageFs)
m.signalToNodeReclaimFuncs = buildSignalToNodeReclaimFuncs(m.imageGC, m.containerGC, hasImageFs)
}
// (3)调用`podFunc`,即调用`kl.GetActivePods`方法,获取会被驱逐的pod列表-activePods
activePods := podFunc()
updateStats := true
// (4)获取各种统计信息,如节点上各个资源的总量以及使用量情况、容器的资源声明及使用量情况等
summary, err := m.summaryProvider.Get(updateStats)
if err != nil {
klog.Errorf("eviction manager: failed to get summary stats: %v", err)
return nil
}
// (5)ThresholdNotifier相关的通知实现,ThresholdNotifier-基于观察者模式实现对特殊资源驱逐管理的支持;
if m.clock.Since(m.thresholdsLastUpdated) > notifierRefreshInterval {
m.thresholdsLastUpdated = m.clock.Now()
for _, notifier := range m.thresholdNotifiers {
if err := notifier.UpdateThreshold(summary); err != nil {
klog.Warningf("eviction manager: failed to update %s: %v", notifier.Description(), err)
}
}
}
// (6)调用`makeSignalObservations`函数,根据前面获取到的节点资源总量及使用量等各种统计信息,组装返回observations,并返回获取pod资源总量及使用量等统计信息的方法statsFunc,该方法后面会用到
// make observations and get a function to derive pod usage stats relative to those observations.
observations, statsFunc := makeSignalObservations(summary)
debugLogObservations("observations", observations)
// (7)调用thresholdsMet函数,比较observations中的资源使用量和thresholds中的驱逐策略配置阈值之间的大小,将超过阈值的驱逐信号(即`memory.available`、`nodefs.available`等)组装成`thresholds`返回
// determine the set of thresholds met independent of grace period
thresholds = thresholdsMet(thresholds, observations, false)
debugLogThresholdsWithObservation("thresholds - ignoring grace period", thresholds, observations)
// (8)判断`m.thresholdsMet`(`m.thresholdsMet`记录了已经达到驱逐阈值,但还没有满足驱逐策略条件,触发驱逐的`Threshold`切片)长度是否大于0,大于0则调用mergeThresholds函数,将上面得到的`thresholds`与`m.thresholdsMet`合并
// determine the set of thresholds previously met that have not yet satisfied the associated min-reclaim
if len(m.thresholdsMet) > 0 {
thresholdsNotYetResolved := thresholdsMet(m.thresholdsMet, observations, true)
thresholds = mergeThresholds(thresholds, thresholdsNotYetResolved)
}
debugLogThresholdsWithObservation("thresholds - reclaim not satisfied", thresholds, observations)
// (9)调用`thresholdsFirstObservedAt`函数,传入`thresholds`与`m.thresholdsFirstObservedAt`(记录各个`Threshold`的第一次发现时间点),记录并更新各个驱逐信号的第一次超过阈值的时间,返回`thresholdsFirstObservedAt`
// track when a threshold was first observed
now := m.clock.Now()
thresholdsFirstObservedAt := thresholdsFirstObservedAt(thresholds, m.thresholdsFirstObservedAt, now)
// the set of node conditions that are triggered by currently observed thresholds
nodeConditions := nodeConditions(thresholds)
if len(nodeConditions) > 0 {
klog.V(3).Infof("eviction manager: node conditions - observed: %v", nodeConditions)
}
// (10)调用nodeConditionsObservedSince函数,判断距离上次更新nodeCondition时间是否已经超过了`m.config.PressureTransitionPeriod`(即kubelet启动参数配置`--eviction-pressure-transition-period`),超过则更新nodeConditions并返回(这里还没有把nodeCondition更新到node对象中去)
// track when a node condition was last observed
nodeConditionsLastObservedAt := nodeConditionsLastObservedAt(nodeConditions, m.nodeConditionsLastObservedAt, now)
// node conditions report true if it has been observed within the transition period window
nodeConditions = nodeConditionsObservedSince(nodeConditionsLastObservedAt, m.config.PressureTransitionPeriod, now)
if len(nodeConditions) > 0 {
klog.V(3).Infof("eviction manager: node conditions - transition period not met: %v", nodeConditions)
}
// (11)调用`thresholdsMetGracePeriod`函数,筛选出驱逐信号达到驱逐阈值并持续了`evictionSoftGracePeriod`时间的(即kubelet启动参数配置`--eviction-soft-grace-period`),组装并返回`thresholds`,此时的`thresholds`是满足驱逐策略即将触发驱逐的thresholds;
// determine the set of thresholds we need to drive eviction behavior (i.e. all grace periods are met)
thresholds = thresholdsMetGracePeriod(thresholdsFirstObservedAt, now)
debugLogThresholdsWithObservation("thresholds - grace periods satisfied", thresholds, observations)
// (12)更新`managerImpl`的部分成员变量的值,如`nodeConditions`、`thresholdsFirstObservedAt`、`nodeConditionsLastObservedAt`、`thresholdsMet`、`lastObservations`
// update internal state
m.Lock()
m.nodeConditions = nodeConditions
m.thresholdsFirstObservedAt = thresholdsFirstObservedAt
m.nodeConditionsLastObservedAt = nodeConditionsLastObservedAt
m.thresholdsMet = thresholds
// determine the set of thresholds whose stats have been updated since the last sync
thresholds = thresholdsUpdatedStats(thresholds, observations, m.lastObservations)
debugLogThresholdsWithObservation("thresholds - updated stats", thresholds, observations)
m.lastObservations = observations
m.Unlock()
// (13)判断`LocalStorageCapacityIsolation`即localStorage驱逐的featuregate是否开启,是则先调用`m.localStorageEviction`处理localstorage驱逐,如果返回驱逐的pod列表不为空,则证明是localStorage触发的驱逐,且已经处理完毕,直接return
// evict pods if there is a resource usage violation from local volume temporary storage
// If eviction happens in localStorageEviction function, skip the rest of eviction action
if utilfeature.DefaultFeatureGate.Enabled(features.LocalStorageCapacityIsolation) {
if evictedPods := m.localStorageEviction(summary, activePods); len(evictedPods) > 0 {
return evictedPods
}
}
// (14)判断即将触发驱逐的`thresholds`长度是否为0,是则代表没有触发驱逐,不需要执行驱逐逻辑,直接return
if len(thresholds) == 0 {
klog.V(3).Infof("eviction manager: no resources are starved")
return nil
}
// (15)调用`sort.Sort(byEvictionPriority(thresholds))`,给`thresholds`排序,将内存排在所有其他资源信号之前,并将没有资源可回收的阈值排在最后
// rank the thresholds by eviction priority
sort.Sort(byEvictionPriority(thresholds))
// (16)根据排序结果,调用`getReclaimableThreshold`,遍历`thresholds`,从中获取第一个可以被回收的`threshold`,返回`thresholdToReclaim`
thresholdToReclaim, resourceToReclaim, foundAny := getReclaimableThreshold(thresholds)
if !foundAny {
return nil
}
klog.Warningf("eviction manager: attempting to reclaim %v", resourceToReclaim)
// record an event about the resources we are now attempting to reclaim via eviction
m.recorder.Eventf(m.nodeRef, v1.EventTypeWarning, "EvictionThresholdMet", "Attempting to reclaim %s", resourceToReclaim)
// (17)调用`m.reclaimNodeLevelResources`,回收上面获取到的节点级的资源`thresholdToReclaim`,如果回收的资源足够,则直接return,不需要往下执行驱逐pod的逻辑
// check if there are node-level resources we can reclaim to reduce pressure before evicting end-user pods.
if m.reclaimNodeLevelResources(thresholdToReclaim.Signal, resourceToReclaim) {
klog.Infof("eviction manager: able to reduce %v pressure without evicting pods.", resourceToReclaim)
return nil
}
klog.Infof("eviction manager: must evict pod(s) to reclaim %v", resourceToReclaim)
// (18)调用`m.signalToRankFunc[thresholdToReclaim.Signal]`,获取对应驱逐信号的pod排序函数
// rank the pods for eviction
rank, ok := m.signalToRankFunc[thresholdToReclaim.Signal]
if !ok {
klog.Errorf("eviction manager: no ranking function for signal %s", thresholdToReclaim.Signal)
return nil
}
// (19)判断`activePods`长度是否为0,是则直接return,没有可被驱逐的pod,无法执行驱逐逻辑
// the only candidates viable for eviction are those pods that had anything running.
if len(activePods) == 0 {
klog.Errorf("eviction manager: eviction thresholds have been met, but no pods are active to evict")
return nil
}
// (20)调用`rank(activePods, statsFunc)`,根据之前获取到的pod排序算法,给pod列表进行排序,再次得到`activePods`,用于后面驱逐pod
// rank the running pods for eviction for the specified resource
rank(activePods, statsFunc)
klog.Infof("eviction manager: pods ranked for eviction: %s", format.Pods(activePods))
//record age of metrics for met thresholds that we are using for evictions.
for _, t := range thresholds {
timeObserved := observations[t.Signal].time
if !timeObserved.IsZero() {
metrics.EvictionStatsAge.WithLabelValues(string(t.Signal)).Observe(metrics.SinceInSeconds(timeObserved.Time))
metrics.DeprecatedEvictionStatsAge.WithLabelValues(string(t.Signal)).Observe(metrics.SinceInMicroseconds(timeObserved.Time))
}
}
// (21)遍历`activePods`列表,获取pod的`gracePeriod`(硬驱逐为0,软驱逐则根据kubelet启动参数`--eviction-max-pod-grace-period`配置值获得),调用`m.evictPod`,判断pod能否被驱逐,能则开始驱逐pod,但这里要注意的是,每次调用`m.synchronize`方法,最多只驱逐一个pod,驱逐成功一个pod则直接return
// we kill at most a single pod during each eviction interval
for i := range activePods {
pod := activePods[i]
gracePeriodOverride := int64(0)
if !isHardEvictionThreshold(thresholdToReclaim) {
gracePeriodOverride = m.config.MaxPodGracePeriodSeconds
}
// 调用`evictionMessage`函数,构造驱逐message,后续更新到pod的event和status中,用于说明为什么发生驱逐
message, annotations := evictionMessage(resourceToReclaim, pod, statsFunc)
if m.evictPod(pod, gracePeriodOverride, message, annotations) {
metrics.Evictions.WithLabelValues(string(thresholdToReclaim.Signal)).Inc()
return []*v1.Pod{pod}
}
}
klog.Infof("eviction manager: unable to evict any pods from the node")
return nil
}
2.1.1 m.config.Thresholds
m.config.Thresholds属性存储着配置的驱逐策略信息,在kubelet初始化的时候调用eviction.ParseThresholdConfig函数,根据函数返回被赋值;
// pkg/kubelet/eviction/types.go
type Config struct {
...
Thresholds []evictionapi.Threshold
...
}
// pkg/kubelet/kubelet.go
func NewMainKubelet(...) {
...
thresholds, err := eviction.ParseThresholdConfig(enforceNodeAllocatable, kubeCfg.EvictionHard, kubeCfg.EvictionSoft, kubeCfg.EvictionSoftGracePeriod, kubeCfg.EvictionMinimumReclaim)
if err != nil {
return nil, err
}
evictionConfig := eviction.Config{
PressureTransitionPeriod: kubeCfg.EvictionPressureTransitionPeriod.Duration,
MaxPodGracePeriodSeconds: int64(kubeCfg.EvictionMaxPodGracePeriod),
Thresholds: thresholds,
KernelMemcgNotification: experimentalKernelMemcgNotification,
PodCgroupRoot: kubeDeps.ContainerManager.GetPodCgroupRoot(),
}
...
}
调用eviction.ParseThresholdConfig函数时的入参kubeCfg.EvictionHard、kubeCfg.EvictionSoft、kubeCfg.EvictionSoftGracePeriod、kubeCfg.EvictionMinimumReclaim等值都来源于kubelet的启动参数配置;
// cmd/kubelet/app/options/options.go
func AddKubeletConfigFlags(mainfs *pflag.FlagSet, c *kubeletconfig.KubeletConfiguration) {
...
fs.Var(cliflag.NewLangleSeparatedMapStringString(&c.EvictionHard), "eviction-hard", "A set of eviction thresholds (e.g. memory.available<1Gi) that if met would trigger a pod eviction.")
fs.Var(cliflag.NewLangleSeparatedMapStringString(&c.EvictionSoft), "eviction-soft", "A set of eviction thresholds (e.g. memory.available<1.5Gi) that if met over a corresponding grace period would trigger a pod eviction.")
fs.Var(cliflag.NewMapStringString(&c.EvictionSoftGracePeriod), "eviction-soft-grace-period", "A set of eviction grace periods (e.g. memory.available=1m30s) that correspond to how long a soft eviction threshold must hold before triggering a pod eviction.")
fs.Var(cliflag.NewMapStringString(&c.EvictionMinimumReclaim), "eviction-minimum-reclaim", "A set of minimum reclaims (e.g. imagefs.available=2Gi) that describes the minimum amount of resource the kubelet will reclaim when performing a pod eviction if that resource is under pressure.")
...
}
eviction.ParseThresholdConfig
eviction.ParseThresholdConfig函数中对软驱逐、硬驱逐相关的配置值进行处理并最终合并返回存储着驱逐策略信息的[]evictionapi.Threshold结构体;
从方法中也可以看到,软驱逐、硬驱逐中的每个驱逐信号,都会生成一个evictionapi.Threshold,所以最终方法返回是[]evictionapi.Threshold;
// pkg/kubelet/eviction/helpers.go
func ParseThresholdConfig(allocatableConfig []string, evictionHard, evictionSoft, evictionSoftGracePeriod, evictionMinimumReclaim map[string]string) ([]evictionapi.Threshold, error) {
results := []evictionapi.Threshold{}
hardThresholds, err := parseThresholdStatements(evictionHard)
if err != nil {
return nil, err
}
results = append(results, hardThresholds...)
softThresholds, err := parseThresholdStatements(evictionSoft)
if err != nil {
return nil, err
}
gracePeriods, err := parseGracePeriods(evictionSoftGracePeriod)
if err != nil {
return nil, err
}
minReclaims, err := parseMinimumReclaims(evictionMinimumReclaim)
if err != nil {
return nil, err
}
for i := range softThresholds {
signal := softThresholds[i].Signal
period, found := gracePeriods[signal]
if !found {
return nil, fmt.Errorf("grace period must be specified for the soft eviction threshold %v", signal)
}
softThresholds[i].GracePeriod = period
}
results = append(results, softThresholds...)
for i := range results {
if minReclaim, ok := minReclaims[results[i].Signal]; ok {
results[i].MinReclaim = &minReclaim
}
}
for _, key := range allocatableConfig {
if key == kubetypes.NodeAllocatableEnforcementKey {
results = addAllocatableThresholds(results)
break
}
}
return results, nil
}
2.1.2 buildSignalToRankFunc
buildSignalToRankFunc函数返回map[evictionapi.Signal]rankFunc,其代表了软驱逐、硬驱逐中各个驱逐信号所对应的排序函数,排序函数用于计算被驱逐pod的顺序;
// pkg/kubelet/eviction/helpers.go
func buildSignalToRankFunc(withImageFs bool) map[evictionapi.Signal]rankFunc {
signalToRankFunc := map[evictionapi.Signal]rankFunc{
evictionapi.SignalMemoryAvailable: rankMemoryPressure,
evictionapi.SignalAllocatableMemoryAvailable: rankMemoryPressure,
evictionapi.SignalPIDAvailable: rankPIDPressure,
}
// usage of an imagefs is optional
if withImageFs {
// with an imagefs, nodefs pod rank func for eviction only includes logs and local volumes
signalToRankFunc[evictionapi.SignalNodeFsAvailable] = rankDiskPressureFunc([]fsStatsType{fsStatsLogs, fsStatsLocalVolumeSource}, v1.ResourceEphemeralStorage)
signalToRankFunc[evictionapi.SignalNodeFsInodesFree] = rankDiskPressureFunc([]fsStatsType{fsStatsLogs, fsStatsLocalVolumeSource}, resourceInodes)
// with an imagefs, imagefs pod rank func for eviction only includes rootfs
signalToRankFunc[evictionapi.SignalImageFsAvailable] = rankDiskPressureFunc([]fsStatsType{fsStatsRoot}, v1.ResourceEphemeralStorage)
signalToRankFunc[evictionapi.SignalImageFsInodesFree] = rankDiskPressureFunc([]fsStatsType{fsStatsRoot}, resourceInodes)
} else {
// without an imagefs, nodefs pod rank func for eviction looks at all fs stats.
// since imagefs and nodefs share a common device, they share common ranking functions.
signalToRankFunc[evictionapi.SignalNodeFsAvailable] = rankDiskPressureFunc([]fsStatsType{fsStatsRoot, fsStatsLogs, fsStatsLocalVolumeSource}, v1.ResourceEphemeralStorage)
signalToRankFunc[evictionapi.SignalNodeFsInodesFree] = rankDiskPressureFunc([]fsStatsType{fsStatsRoot, fsStatsLogs, fsStatsLocalVolumeSource}, resourceInodes)
signalToRankFunc[evictionapi.SignalImageFsAvailable] = rankDiskPressureFunc([]fsStatsType{fsStatsRoot, fsStatsLogs, fsStatsLocalVolumeSource}, v1.ResourceEphemeralStorage)
signalToRankFunc[evictionapi.SignalImageFsInodesFree] = rankDiskPressureFunc([]fsStatsType{fsStatsRoot, fsStatsLogs, fsStatsLocalVolumeSource}, resourceInodes)
}
return signalToRankFunc
}
因内存资源紧张导致的驱逐比较常见,所以这里对其中内存的pod排序函数来做一下分析;
rankMemoryPressure
可以看到内存资源的pod排序逻辑为:
(1)先根据pod的内存使用量是否超过内存request排序,超过的排在前面;
(2)再根据pod的priority值大小排序,值小的排在前面;
(3)最后根据pod内存request值减去pod的内存使用量的值,得到值小的排在前面;
// pkg/kubelet/eviction/helpers.go
func rankMemoryPressure(pods []*v1.Pod, stats statsFunc) {
orderedBy(exceedMemoryRequests(stats), priority, memory(stats)).Sort(pods)
}
从这个排序函数也可以看出,当因为宿主内存资源紧张发生驱逐时,什么样的pod会最先被驱逐;
关于pod的priority详细介绍,可以查看官方文档:https://kubernetes.io/zh/docs/concepts/scheduling-eviction/pod-priority-preemption/
2.1.3 buildSignalToNodeReclaimFuncs
buildSignalToNodeReclaimFuncs用于构建节点资源回收函数,回收函数用于后续在执行驱逐pod之前,先调用节点资源回收函数来回收资源,如果回收的资源足够,则不用走驱逐逻辑;
可以看到只有nodefs.available、nodefs.inodesfree、imagefs.available、imagefs.inodesfree四个驱逐信号有回收函数,其余驱逐信号均没有;且当有专门的imageFs时,nodefs.available、nodefs.inodesfree也不会有回收函数;
// pkg/kubelet/eviction/helpers.go
func buildSignalToNodeReclaimFuncs(imageGC ImageGC, containerGC ContainerGC, withImageFs bool) map[evictionapi.Signal]nodeReclaimFuncs {
signalToReclaimFunc := map[evictionapi.Signal]nodeReclaimFuncs{}
// usage of an imagefs is optional
if withImageFs {
// with an imagefs, nodefs pressure should just delete logs
signalToReclaimFunc[evictionapi.SignalNodeFsAvailable] = nodeReclaimFuncs{}
signalToReclaimFunc[evictionapi.SignalNodeFsInodesFree] = nodeReclaimFuncs{}
// with an imagefs, imagefs pressure should delete unused images
signalToReclaimFunc[evictionapi.SignalImageFsAvailable] = nodeReclaimFuncs{containerGC.DeleteAllUnusedContainers, imageGC.DeleteUnusedImages}
signalToReclaimFunc[evictionapi.SignalImageFsInodesFree] = nodeReclaimFuncs{containerGC.DeleteAllUnusedContainers, imageGC.DeleteUnusedImages}
} else {
// without an imagefs, nodefs pressure should delete logs, and unused images
// since imagefs and nodefs share a common device, they share common reclaim functions
signalToReclaimFunc[evictionapi.SignalNodeFsAvailable] = nodeReclaimFuncs{containerGC.DeleteAllUnusedContainers, imageGC.DeleteUnusedImages}
signalToReclaimFunc[evictionapi.SignalNodeFsInodesFree] = nodeReclaimFuncs{containerGC.DeleteAllUnusedContainers, imageGC.DeleteUnusedImages}
signalToReclaimFunc[evictionapi.SignalImageFsAvailable] = nodeReclaimFuncs{containerGC.DeleteAllUnusedContainers, imageGC.DeleteUnusedImages}
signalToReclaimFunc[evictionapi.SignalImageFsInodesFree] = nodeReclaimFuncs{containerGC.DeleteAllUnusedContainers, imageGC.DeleteUnusedImages}
}
return signalToReclaimFunc
}
2.1.4 kl.GetActivePods
kl.GetActivePods方法用于获取能被驱逐的pod列表,过滤掉以下情形的pod之后,返回的pod列表即为能被驱逐的pod列表:
(1)failed状态;
(2)succeeded状态;
(3)pod的DeletionTimestamp不为空,且notRunning函数返回true;
// pkg/kubelet/kubelet_pods.go
func (kl *Kubelet) GetActivePods() []*v1.Pod {
allPods := kl.podManager.GetPods()
activePods := kl.filterOutTerminatedPods(allPods)
return activePods
}
func (kl *Kubelet) filterOutTerminatedPods(pods []*v1.Pod) []*v1.Pod {
var filteredPods []*v1.Pod
for _, p := range pods {
if kl.podIsTerminated(p) {
continue
}
filteredPods = append(filteredPods, p)
}
return filteredPods
}
func (kl *Kubelet) podIsTerminated(pod *v1.Pod) bool {
// Check the cached pod status which was set after the last sync.
status, ok := kl.statusManager.GetPodStatus(pod.UID)
if !ok {
// If there is no cached status, use the status from the
// apiserver. This is useful if kubelet has recently been
// restarted.
status = pod.Status
}
return status.Phase == v1.PodFailed || status.Phase == v1.PodSucceeded || (pod.DeletionTimestamp != nil && notRunning(status.ContainerStatuses))
}
func notRunning(statuses []v1.ContainerStatus) bool {
for _, status := range statuses {
if status.State.Terminated == nil && status.State.Waiting == nil {
return false
}
}
return true
}
2.1.5 m.summaryProvider.Get
m.summaryProvider.Get方法从各个途径获取各种统计信息,然后组装并返回,各种统计信息如节点上各种资源的总量以及使用量情况、容器的资源声明及使用量情况等;
(1)sp.provider.GetNode(),最终是从client-go informer的本地缓存中获取node对象;
(2)sp.provider.GetNodeConfig(),最终是从container_manager中获取NodeConfig结构体;
(3)sp.provider.GetCgroupStats(),从cadvisor中获取根目录“/”下的cgroup的统计信息;
(4)sp.provider.RootFsStats(),从cadvisor中获取root文件系统的统计信息;
(5)sp.provider.ImageFsStats(),获取image文件系统的统计信息,其有两个实现,一个是criStatsProvider,另一个是cadvisorStatsProvider;
(6)sp.provider.ListPodStatsAndUpdateCPUNanoCoreUsage(),更新所有容器的cpu usage信息并获取所有pod的启动时间、容器状态、cpu使用量、内存使用量等统计信息,其有两个实现,一个是criStatsProvider,另一个是cadvisorStatsProvider;
(7)sp.provider.ListPodStats(),获取所有pod的启动时间、容器状态、cpu使用量、内存使用量等统计信息,其有两个实现,一个是criStatsProvider,另一个是cadvisorStatsProvider;
(8)sp.provider.RlimitStats(),获取pid限制信息;
// pkg/kubelet/server/stats/summary.go
func (sp *summaryProviderImpl) Get(updateStats bool) (*statsapi.Summary, error) {
// TODO(timstclair): Consider returning a best-effort response if any of
// the following errors occur.
// 从client-go informer的本地缓存中获取node对象
node, err := sp.provider.GetNode()
if err != nil {
return nil, fmt.Errorf("failed to get node info: %v", err)
}
// 从container_manager中获取NodeConfig结构体
nodeConfig := sp.provider.GetNodeConfig()
// 从cadvisor中获取根目录“/”下的cgroup的统计信息
rootStats, networkStats, err := sp.provider.GetCgroupStats("/", updateStats)
if err != nil {
return nil, fmt.Errorf("failed to get root cgroup stats: %v", err)
}
// 从cadvisor中获取root文件系统的统计信息
rootFsStats, err := sp.provider.RootFsStats()
if err != nil {
return nil, fmt.Errorf("failed to get rootFs stats: %v", err)
}
// 获取image文件系统的统计信息
imageFsStats, err := sp.provider.ImageFsStats()
if err != nil {
return nil, fmt.Errorf("failed to get imageFs stats: %v", err)
}
var podStats []statsapi.PodStats
if updateStats {
// 更新所有容器的cpu usage信息并获取所有pod的启动时间、容器状态、cpu使用量、内存使用量等统计信息
podStats, err = sp.provider.ListPodStatsAndUpdateCPUNanoCoreUsage()
} else {
// 获取所有pod的启动时间、容器状态、cpu使用量、内存使用量等统计信息
podStats, err = sp.provider.ListPodStats()
}
if err != nil {
return nil, fmt.Errorf("failed to list pod stats: %v", err)
}
// 获取pid限制信息
rlimit, err := sp.provider.RlimitStats()
if err != nil {
return nil, fmt.Errorf("failed to get rlimit stats: %v", err)
}
// 组装以上的统计信息并返回
nodeStats := statsapi.NodeStats{
NodeName: node.Name,
CPU: rootStats.CPU,
Memory: rootStats.Memory,
Network: networkStats,
StartTime: sp.systemBootTime,
Fs: rootFsStats,
Runtime: &statsapi.RuntimeStats{ImageFs: imageFsStats},
Rlimit: rlimit,
SystemContainers: sp.GetSystemContainersStats(nodeConfig, podStats, updateStats),
}
summary := statsapi.Summary{
Node: nodeStats,
Pods: podStats,
}
return &summary, nil
}
2.1.6 byEvictionPriority
该排序方法将内存排在所有其他资源信号之前,并将没有资源可回收的阈值排在最后;
// pkg/kubelet/eviction/helpers.go
func (a byEvictionPriority) Less(i, j int) bool {
_, jSignalHasResource := signalToResource[a[j].Signal]
return a[i].Signal == evictionapi.SignalMemoryAvailable || a[i].Signal == evictionapi.SignalAllocatableMemoryAvailable || !jSignalHasResource
}
2.1.7 getReclaimableThreshold
getReclaimableThreshold函数遍历thresholds,从中获取第一个可以被回收的threshold并返回;
// pkg/kubelet/eviction/helpers.go
func getReclaimableThreshold(thresholds []evictionapi.Threshold) (evictionapi.Threshold, v1.ResourceName, bool) {
for _, thresholdToReclaim := range thresholds {
if resourceToReclaim, ok := signalToResource[thresholdToReclaim.Signal]; ok {
return thresholdToReclaim, resourceToReclaim, true
}
klog.V(3).Infof("eviction manager: threshold %s was crossed, but reclaim is not implemented for this threshold.", thresholdToReclaim.Signal)
}
return evictionapi.Threshold{}, "", false
}
func init() {
...
signalToResource = map[evictionapi.Signal]v1.ResourceName{}
signalToResource[evictionapi.SignalMemoryAvailable] = v1.ResourceMemory
signalToResource[evictionapi.SignalAllocatableMemoryAvailable] = v1.ResourceMemory
signalToResource[evictionapi.SignalImageFsAvailable] = v1.ResourceEphemeralStorage
signalToResource[evictionapi.SignalImageFsInodesFree] = resourceInodes
signalToResource[evictionapi.SignalNodeFsAvailable] = v1.ResourceEphemeralStorage
signalToResource[evictionapi.SignalNodeFsInodesFree] = resourceInodes
signalToResource[evictionapi.SignalPIDAvailable] = resourcePids
}
2.1.8 m.reclaimNodeLevelResources
m.reclaimNodeLevelResources方法用于提前回收节点资源,并判断是否需要继续走驱逐pod的逻辑,方法返回true则代表回收节点资源已足够,无需再执行驱逐pod逻辑,返回false则代表需要继续执行驱逐pod的逻辑;
方法主要逻辑为:
(1)根据驱逐信号,获取对应的节点资源回收函数,遍历并调用回收函数来回收资源;
(2)如果回收函数为空,直接return false;
(3)调用m.summaryProvider.Get获取实时的资源统计信息;
(4)判断调用回收函数回收节点资源过后,现在的各个资源使用情况是否还是超过配置的各个驱逐阈值,没有超过则返回true,否则返回false;
// pkg/kubelet/eviction/eviction_manager.go
func (m *managerImpl) reclaimNodeLevelResources(signalToReclaim evictionapi.Signal, resourceToReclaim v1.ResourceName) bool {
nodeReclaimFuncs := m.signalToNodeReclaimFuncs[signalToReclaim]
for _, nodeReclaimFunc := range nodeReclaimFuncs {
// attempt to reclaim the pressured resource.
if err := nodeReclaimFunc(); err != nil {
klog.Warningf("eviction manager: unexpected error when attempting to reduce %v pressure: %v", resourceToReclaim, err)
}
}
if len(nodeReclaimFuncs) > 0 {
summary, err := m.summaryProvider.Get(true)
if err != nil {
klog.Errorf("eviction manager: failed to get summary stats after resource reclaim: %v", err)
return false
}
// make observations and get a function to derive pod usage stats relative to those observations.
observations, _ := makeSignalObservations(summary)
debugLogObservations("observations after resource reclaim", observations)
// determine the set of thresholds met independent of grace period
thresholds := thresholdsMet(m.config.Thresholds, observations, false)
debugLogThresholdsWithObservation("thresholds after resource reclaim - ignoring grace period", thresholds, observations)
if len(thresholds) == 0 {
return true
}
}
return false
}
2.1.9 m.evictPod
m.evictPod方法主要逻辑:
(1)调用kubelettypes.IsCriticalPod,判断是否是critical pod,是则返回false,说明该pod不能是被驱逐的对象;
(2)调用m.recorder.AnnotatedEventf,上报驱逐event;
(3)调用m.killPodFunc,驱逐pod;
// pkg/kubelet/eviction/eviction_manager.go
func (m *managerImpl) evictPod(pod *v1.Pod, gracePeriodOverride int64, evictMsg string, annotations map[string]string) bool {
// If the pod is marked as critical and static, and support for critical pod annotations is enabled,
// do not evict such pods. Static pods are not re-admitted after evictions.
// https://github.com/kubernetes/kubernetes/issues/40573 has more details.
if kubelettypes.IsCriticalPod(pod) {
klog.Errorf("eviction manager: cannot evict a critical pod %s", format.Pod(pod))
return false
}
status := v1.PodStatus{
Phase: v1.PodFailed,
Message: evictMsg,
Reason: Reason,
}
// record that we are evicting the pod
m.recorder.AnnotatedEventf(pod, annotations, v1.EventTypeWarning, Reason, evictMsg)
// this is a blocking call and should only return when the pod and its containers are killed.
err := m.killPodFunc(pod, status, &gracePeriodOverride)
if err != nil {
klog.Errorf("eviction manager: pod %s failed to evict %v", format.Pod(pod), err)
} else {
klog.Infof("eviction manager: pod %s is evicted successfully", format.Pod(pod))
}
return true
}
IsCriticalPod
IsCriticalPod函数判断一个pod是否是critical pod;
是static pod,是mirror pod,pod.Spec.Priority属性不为空且其值大于等于2000000000,三个条件均符合则方法返回true,否则返回false;
// pkg/kubelet/types/pod_update.go
func IsCriticalPod(pod *v1.Pod) bool {
if IsStaticPod(pod) {
return true
}
if IsMirrorPod(pod) {
return true
}
if pod.Spec.Priority != nil && IsCriticalPodBasedOnPriority(*pod.Spec.Priority) {
return true
}
return false
}
IsStaticPod
看到IsStaticPod函数,可以知道是否是static pod是根据pod annotation中是否有key:"kubernetes.io/config.source",且其值为"api",满足条件则为static pod;
// pkg/kubelet/types/pod_update.go
const (
ConfigSourceAnnotationKey = "kubernetes.io/config.source"
ApiserverSource = "api"
)
func IsStaticPod(pod *v1.Pod) bool {
source, err := GetPodSource(pod)
return err == nil && source != ApiserverSource
}
func GetPodSource(pod *v1.Pod) (string, error) {
if pod.Annotations != nil {
if source, ok := pod.Annotations[ConfigSourceAnnotationKey]; ok {
return source, nil
}
}
return "", fmt.Errorf("cannot get source of pod %q", pod.UID)
}
IsCriticalPodBasedOnPriority
// pkg/kubelet/types/pod_update.go
func IsCriticalPodBasedOnPriority(priority int32) bool {
return priority >= scheduling.SystemCriticalPriority
}
// pkg/apis/scheduling/types.go
const (
HighestUserDefinablePriority = int32(1000000000)
SystemCriticalPriority = 2 * HighestUserDefinablePriority
)
2.1.10 m.killPodFunc
m.killPodFunc主要是停止pod中的所有业务容器以及sandbox容器;
前面的分析讲过,在eviction_manager初始化的时候,m.killPodFunc被赋值为pkg/kubelet/pod_workers.go-killPodNow()函数,所以接下来直接看到killPodNow函数的分析;
killPodNow函数主要逻辑:获取gracePeriod,拼凑UpdatePodOptions,并调用podWorkers.UpdatePod来kill Pod(这里的kill pod最终只是停止了pod中的所有业务容器以及sandbox容器,没有做任何删除操作);
// pkg/kubelet/pod_workers.go
func killPodNow(podWorkers PodWorkers, recorder record.EventRecorder) eviction.KillPodFunc {
return func(pod *v1.Pod, status v1.PodStatus, gracePeriodOverride *int64) error {
// determine the grace period to use when killing the pod
gracePeriod := int64(0)
if gracePeriodOverride != nil {
gracePeriod = *gracePeriodOverride
} else if pod.Spec.TerminationGracePeriodSeconds != nil {
gracePeriod = *pod.Spec.TerminationGracePeriodSeconds
}
// we timeout and return an error if we don't get a callback within a reasonable time.
// the default timeout is relative to the grace period (we settle on 10s to wait for kubelet->runtime traffic to complete in sigkill)
timeout := int64(gracePeriod + (gracePeriod / 2))
minTimeout := int64(10)
if timeout < minTimeout {
timeout = minTimeout
}
timeoutDuration := time.Duration(timeout) * time.Second
// open a channel we block against until we get a result
type response struct {
err error
}
ch := make(chan response, 1)
podWorkers.UpdatePod(&UpdatePodOptions{
Pod: pod,
UpdateType: kubetypes.SyncPodKill,
OnCompleteFunc: func(err error) {
ch <- response{err: err}
},
KillPodOptions: &KillPodOptions{
PodStatusFunc: func(p *v1.Pod, podStatus *kubecontainer.PodStatus) v1.PodStatus {
return status
},
PodTerminationGracePeriodSecondsOverride: gracePeriodOverride,
},
})
// wait for either a response, or a timeout
select {
case r := <-ch:
return r.err
case <-time.After(timeoutDuration):
recorder.Eventf(pod, v1.EventTypeWarning, events.ExceededGracePeriod, "Container runtime did not kill the pod within specified grace period.")
return fmt.Errorf("timeout waiting to kill pod")
}
}
}
podWorkers.UpdatePod方法这里不展开分析,给出方法调用链,可自行查看;
podWorkers.UpdatePod() --> p.managePodLoop() --> kl.syncPod() --> kl.killPod() --> kl.containerRuntime.KillPod() --> kl.containerRuntime.killContainersWithSyncResult()/kl.containerRuntime.runtimeService.StopPodSandbox()
2.2 m.waitForPodsCleanup
m.waitForPodsCleanup方法会循环调用podCleanedUpFunc,等待pod的相关资源被清理、回收(pod的所有业务容器停止并被删除、volume被清理),清理完成后return;
// pkg/kubelet/eviction/eviction_manager.go
func (m *managerImpl) waitForPodsCleanup(podCleanedUpFunc PodCleanedUpFunc, pods []*v1.Pod) {
timeout := m.clock.NewTimer(podCleanupTimeout)
defer timeout.Stop()
ticker := m.clock.NewTicker(podCleanupPollFreq)
defer ticker.Stop()
for {
select {
case <-timeout.C():
klog.Warningf("eviction manager: timed out waiting for pods %s to be cleaned up", format.Pods(pods))
return
case <-ticker.C():
for i, pod := range pods {
if !podCleanedUpFunc(pod) {
break
}
if i == len(pods)-1 {
klog.Infof("eviction manager: pods %s successfully cleaned up", format.Pods(pods))
return
}
}
}
}
}
podCleanedUpFunc
podCleanedUpFunc实际上是podResourcesAreReclaimed方法,podResourcesAreReclaimed方法调用了kl.PodResourcesAreReclaimed方法做进一步处理;
// pkg/kubelet/kubelet_pods.go
func (kl *Kubelet) podResourcesAreReclaimed(pod *v1.Pod) bool {
status, ok := kl.statusManager.GetPodStatus(pod.UID)
if !ok {
status = pod.Status
}
return kl.PodResourcesAreReclaimed(pod, status)
}
从PodResourcesAreReclaimed方法中可以看出,会等待pod的所有业务容器停止运行并被删除,等待pod的volume被清理完成,等待pod的cgroup sandbox被清理完成;
// pkg/kubelet/kubelet_pods.go
func (kl *Kubelet) PodResourcesAreReclaimed(pod *v1.Pod, status v1.PodStatus) bool {
if !notRunning(status.ContainerStatuses) {
// We shouldn't delete pods that still have running containers
klog.V(3).Infof("Pod %q is terminated, but some containers are still running", format.Pod(pod))
return false
}
// pod's containers should be deleted
runtimeStatus, err := kl.podCache.Get(pod.UID)
if err != nil {
klog.V(3).Infof("Pod %q is terminated, Error getting runtimeStatus from the podCache: %s", format.Pod(pod), err)
return false
}
if len(runtimeStatus.ContainerStatuses) > 0 {
var statusStr string
for _, status := range runtimeStatus.ContainerStatuses {
statusStr += fmt.Sprintf("%+v ", *status)
}
klog.V(3).Infof("Pod %q is terminated, but some containers have not been cleaned up: %s", format.Pod(pod), statusStr)
return false
}
if kl.podVolumesExist(pod.UID) && !kl.keepTerminatedPodVolumes {
// We shouldn't delete pods whose volumes have not been cleaned up if we are not keeping terminated pod volumes
klog.V(3).Infof("Pod %q is terminated, but some volumes have not been cleaned up", format.Pod(pod))
return false
}
if kl.kubeletConfiguration.CgroupsPerQOS {
pcm := kl.containerManager.NewPodContainerManager()
if pcm.Exists(pod) {
klog.V(3).Infof("Pod %q is terminated, but pod cgroup sandbox has not been cleaned up", format.Pod(pod))
return false
}
}
return true
}
总结
kubelet节点压力驱逐中包括了两部分,一个是实时驱逐,一个是轮询驱逐;
// pkg/kubelet/eviction/eviction_manager.go
func (m *managerImpl) Start(diskInfoProvider DiskInfoProvider, podFunc ActivePodsFunc, podCleanedUpFunc PodCleanedUpFunc, monitoringInterval time.Duration) {
thresholdHandler := func(message string) {
klog.Infof(message)
m.synchronize(diskInfoProvider, podFunc)
}
// 启动实时驱逐
if m.config.KernelMemcgNotification {
for _, threshold := range m.config.Thresholds {
if threshold.Signal == evictionapi.SignalMemoryAvailable || threshold.Signal == evictionapi.SignalAllocatableMemoryAvailable {
notifier, err := NewMemoryThresholdNotifier(threshold, m.config.PodCgroupRoot, &CgroupNotifierFactory{}, thresholdHandler)
if err != nil {
klog.Warningf("eviction manager: failed to create memory threshold notifier: %v", err)
} else {
go notifier.Start()
m.thresholdNotifiers = append(m.thresholdNotifiers, notifier)
}
}
}
}
// 启动轮询驱逐
// start the eviction manager monitoring
go func() {
for {
if evictedPods := m.synchronize(diskInfoProvider, podFunc); evictedPods != nil {
klog.Infof("eviction manager: pods %s evicted, waiting for pod to be cleaned up", format.Pods(evictedPods))
m.waitForPodsCleanup(podCleanedUpFunc, evictedPods)
} else {
time.Sleep(monitoringInterval)
}
}
}()
}
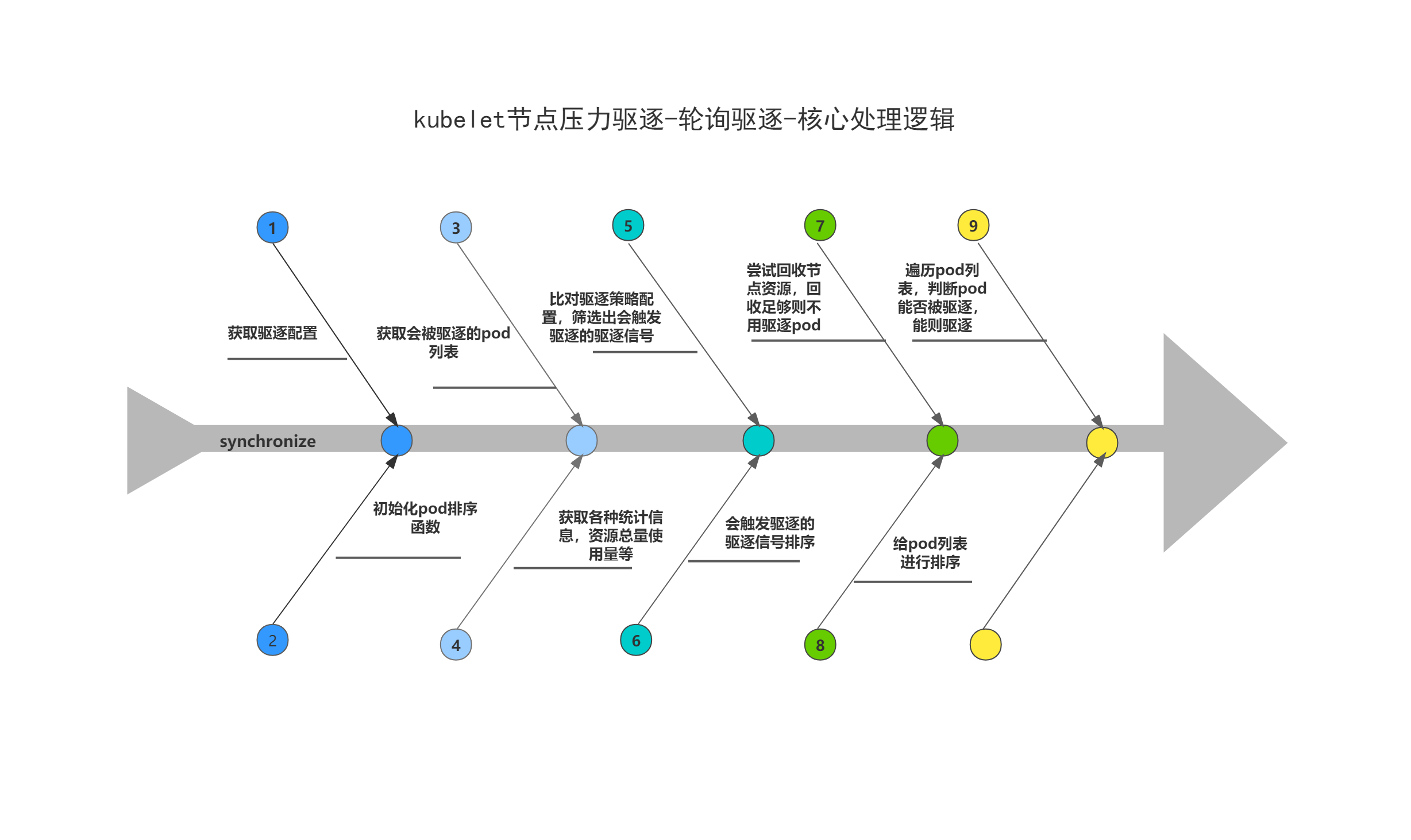
这里主要对轮询驱逐做一下分析总结,m.synchronize方法为驱逐核心逻辑所在;
m.synchronize方法驱逐逻辑概要总结:
(1)根据kubelet启动参数配置,获取驱逐策略配置;
(2)初始化软驱逐、硬驱逐中各个驱逐信号的pod排序函数;
(3)获取会被驱逐的pod列表-activePods;
(4)从cAdvisor、CRIRuntimes获取各种统计信息,如节点上各个资源的总量以及使用量情况、容器的资源声明及使用量情况等;
(5)比对驱逐策略配置以及上述的各种资源统计信息,筛选出会触发驱逐的驱逐信号;
(6)将上面筛选出来的驱逐信号做排序,将内存驱逐信号排在所有其他信号之前,并将没有资源可回收的驱逐信号排在最后,并从排序后的结果中取出第一个驱逐信号;
(7)调用m.reclaimNodeLevelResources,回收上面获取到的驱逐信号的节点级资源,如果回收的资源足够,则直接return,不需要往下执行驱逐pod的逻辑;
(8)获取上述取出的驱逐信号对应的pod排序函数,给pod列表进行排序;
(9)遍历排序后的pod列表,调用m.evictPod,判断pod能否被驱逐,能则开始驱逐pod;
驱逐逻辑三个注意点:
(1)每次调用m.synchronize方法,即每次的驱逐逻辑,最多只驱逐一个pod;
(2)如果调用m.synchronize方法没有驱逐pod,则会等待10s后再进行下一次的m.synchronize方法轮询调用,也就是说轮询驱逐会有一定的时延;
(3)驱逐pod,只是将pod.status.phase值更新为Failed,并附上驱逐reason:Evicted以及触发驱逐的详细信息,不会删除pod;而pod.status.phase值被更新为Failed后,replicaset controller会再次创建出新的pod调用到其他节点上,达到驱逐pod的效果;
k8s驱逐篇(3)-kubelet节点压力驱逐-源码分析篇的更多相关文章
- k8s驱逐篇(2)-kubelet节点压力驱逐
kubelet节点压力驱逐 kubelet监控集群节点的 CPU.内存.磁盘空间和文件系统的inode 等资源,根据kubelet启动参数中的驱逐策略配置,当这些资源中的一个或者多个达到特定的消耗水平 ...
- ASP.NET Core[源码分析篇] - 认证
追本溯源,从使用开始 首先看一下我们的通常是如何使用微软自带的认证,一般在Startup里面配置我们所需的依赖认证服务,这里通过JWT的认证方式讲解 public void ConfigureServ ...
- ASP.NET Core[源码分析篇] - WebHost
_configureServicesDelegates的承接 在[ASP.NET Core[源码分析篇] - Startup]这篇文章中,我们得知了目前为止(UseStartup),所有的动作都是在_ ...
- ASP.NET Core[源码分析篇] - Authentication认证
原文:ASP.NET Core[源码分析篇] - Authentication认证 追本溯源,从使用开始 首先看一下我们通常是如何使用微软自带的认证,一般在Startup里面配置我们所需的依赖认证服务 ...
- 11.深入k8s:kubelet工作原理及源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 源码版本是1.19 kubelet信息量是很大的,通过我这一篇文章肯定是讲不全的,大家可 ...
- 7.深入k8s:任务调用Job与CronJob及源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 在使用job中,我会结合源码进行一定的讲解,我们也可以从源码中一窥究竟,一些细节k8s是 ...
- 【Spark篇】---Spark中资源和任务调度源码分析与资源配置参数应用
一.前述 Spark中资源调度是一个非常核心的模块,尤其对于我们提交参数来说,需要具体到某些配置,所以提交配置的参数于源码一一对应,掌握此节对于Spark在任务执行过程中的资源分配会更上一层楼.由于源 ...
- ASP.NET Core[源码分析篇] - Startup
应用启动的重要类 - Startup 在ASP.NET Core - 从Program和Startup开始这篇文章里面,我们知道了Startup这个类的重要性,它主要负责了: 配置应用需要的服务(服务 ...
- 10.深入k8s:调度的优先级及抢占机制源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 源码版本是1.19 上一篇我们将了获取node成功的情况,如果是一个优先pod获取nod ...
随机推荐
- JS:函数的几种写法1
1.构造函数: var fn = new function(); 2.声明式: function fn(){}; 3.匿名函数(又称自调用函数): (function(){})(); 4.表达式: v ...
- [pwn基础]Pwntools学习
目录 [pwn基础]Pwntools学习 Pwntools介绍 Pwntools安装 Pwntools常用模块和函数 pwnlib.tubes模块学习 tubes.process pwnlib.con ...
- JavaScript 防盗链的原理以及破解方法
先说说防盗链的原理,http 协议中,如果从一个网页跳到另一个网页,http 头字段里面会带个 Referer.这里的Referer是由于历史原因导致了拼写错误 后来也就一直沿用.图片服务器通过检测 ...
- SAP Picture Control(图片加载)
Screen display 效果 源代码 program sap_picture_demo. set screen 200. TYPE-POOLS cndp. ******************* ...
- ACM组合计数入门
1 排列组合 1.1 排列 \[A_n^m=n(n-1)(n-2)\cdots(n-m+1)=\frac{n!}{(n-m)!} \] 定义:从 n 个中选择 m 个组成有序数列,其中不同数列的数量. ...
- Tapdata Cloud 版本上新!新增ClickHouse,ADB MySQL等5个数据源支持
Tapdata Cloud cloud.tapdata.net Tapdata Cloud 是国内首家异构数据库实时同步云平台,目前支持Oracle.MySQL.PG.SQL Server.Mongo ...
- freeswitch的话单模块
概述 最近因为业务需要,在看freeswitch中话单相关的一些模块. 在voip的使用过程中,话单是重要的基础模块,涉及到计费和问题查找. 呼叫话单最重要的一点是稳定,不能有错误或遗漏. 本章对fs ...
- 2022-7-9 html 第七组 刘昀航
一.基础认知 1.1 认识网页 网页的组成: 文字.图片.音频.视频.超链接 网页背后的本质:前端程序员写的代码 前端的代码通过什么软件转换成用户眼中的页面:浏览器转化(解析和渲染) 1.2 5大 ...
- vue2升级vue3指南(二)—— 语法warning&error篇
本文总结了vue2升级vue3可能会遇到的语法警告和错误,如果想知道怎样升级,可以查看我的上一篇文章:vue2升级vue3指南(一)-- 环境准备和构建篇 Warning 1.deep /deep/和 ...
- 基于infiniband(IB)网的MVAPICH2安装
一.下载安装包 下载链接:http://mvapich.cse.ohio-state.edu/downloads/ 二.解压编译安装 mkdir /home/xujb/mvapich2 tar -x ...