R数据分析:用R建立预测模型
预测模型在各个领域都越来越火,今天的分享和之前的临床预测模型背景上有些不同,但方法思路上都是一样的,多了解各个领域的方法应用,视野才不会被局限。
今天试图再用一个实例给到大家一个统一的预测模型的做法框架(R中同样的操作可以有多种多样的实现方法,框架统一尤其重要,不是简单的我做出来就行)。而是要:
eliminate syntactical differences between many of the functions for building and predicting models
数据划分
通常我们的数据是有限的,所以首先第一步就是决定如何使用我们的数据,就这一步来讲都有很多流派。
数据比较少的情况下,一般还是将全部数据都拿来做训练,尽可能使得模型的代表性强一点,但是随之而来的问题就是没有样本外验证。上文写机器学习的时候提到,样本外验证是模型评估的重要一步,所以一般还是会划分数据。个人意见:好多同学就200多个数据,就别去划分数据集了,全用吧,保证下模型效度。
我现在手上有数据如下:
这是一个有4335个观测1579个变量的数据集,我现在要对其切分为训练集和测试集,代码如下:
inTrain <- createDataPartition(mutagen, p = 3/4, list = FALSE)
trainDescr <- descr[inTrain,]
testDescr <- descr[-inTrain,]
trainClass <- mutagen[inTrain]
testClass <- mutagen[-inTrain]代码的重点在createDataPartition,这个函数的p参数指的是训练集的比例,此处意味着75%的数据用来训练模型,剩下的25%的数据用来验证。使用这个函数的时候要注意一定是用结局作为划分的依据,比如说我现在做一个死亡预测模型,一定要在生存状态这个变量上进行划分,比如原来数据中死亡与否的占比是7:3,这样我们能保证划分出的训练集死亡与否的占比依然是7:3。
数据划分中会有两个常见的问题:一是zero-variance predictor的问题,二是multicollinearity的问题。
第一个问题指的是很多的变量只有一个取值,不提供信息,比如变量A可以取y和n,y占90%n占10%,划分数据后训练集中有可能全是y,此时这个变量就没法用了。为了避免这个问题我们首先应该排除数据集中本身就是单一取值的变量,还有哪些本身比例失衡的变量,可以用到nearZeroVar函数找后进行删除。
第二个问题是共线性,解决方法一个是取主成分降维后重新跑,另一个是做相关,相关系数大于某个界值后删掉,可以用到findCorrelation函数。
下面的代码就实现了去除zero-variance predictor和相关系数大于0.9的变量:
isZV <- apply(trainDescr, 2, function(u) length(unique(u)) == 1)
trainDescr <- trainDescr[, !isZV]
testDescr <- testDescr[, !isZV]
descrCorr <- cor(trainDescr)
highCorr <- findCorrelation(descrCorr, 0.90)
trainDescr <- trainDescr[, -highCorr]
testDescr <- testDescr[, -highCorr]
ncol(trainDescr)运行上面的代码之后我们的预测因子就从1575个降低到了640个。
接下来对于模型特定的预测算法,比如partial least squares, neural networks and support vector machines,都是需要我们将数值型变量中心化或标准化的,这个时候我们需要对数据进行预处理,需要用到preProcess函数,具体代码如下:
xTrans <- preProcess(trainDescr)
trainDescr <- predict(xTrans, trainDescr)
testDescr <- predict(xTrans, testDescr)在preProcess函数中,可以通过method参数很方便地对训练数据进行插补,中心化,标准化或者取主成分等等操作,我愿称其为最强数据预处理函数。
建模与调参
建模是用train函数进行的,caret提供的预测模型建立的统一框架的精髓也在train函数中,我们想要用各种各样的机器学习算法去做预测模型,就只需要在train中改动method参数即可,并且我们能用的算法也非常多,列举部分如下:

另外一个值得注意的参数就是trControl,这个参数可以用来设定交叉验证的方法:
trControl which specifies the resampling scheme, that is, how cross-validation should be performed to find the best values of the tuning parameters

比如我现在需要训练一个logistics模型(大家用的最多的),我就可以写出如下代码:
default_glm_mod = train(
form = default ~ .,
data = default_trn,
trControl = trainControl(method = "cv", number = 5),
method = "glm",
family = "binomial"
)在上面的代码中,我们设定了4个重要的参数:
一是模型公式form,二是数据来源data,三是交叉验证方法,这儿我们使用的是5折交叉验证,四是模型算法method。
我现在要训练一个支持向量机模型,代码如下:
bootControl <- trainControl(number = 200)
svmFit <- train(
trainDescr, trainClass,
method = "svmRadial",
trControl = bootControl,
scaled = FALSE)上面的代码运行需要一点时间,我们是用自助抽样法,抽样迭代次数200次,也就是抽200个数据集,所以比较耗时。
支持向量机是有两个超参的sigma和C,上面的结果输出中每一行代表一种超参组合,通过上图我们可以看到不同的超参组合下模型的表现

其中有一致性系数Kappa,如果我们的结局是十分不平衡的,这个Kappa就会是特别重要的评估模型表现的一个指标
Kappa is an excellent performance measure when the classes are highly unbalanced
我们发现超参取0.00137和2,模型会表现得更好,这个也成为我们的finalmodel。
预测新样本
模型目前已经训练好了,我们可以用训练好的最好的模型finalmodel来预测我们的测试集,进而评估模型表现。预测新样本的代码如下:
predict(svmFit$finalModel, newdata = testDescr)有时候我们会训练不同算法的多个模型,比如一个支持向量机模型,另外一个gbm模型,这个时候使用predict也可以方便的得到多个算法的预测结果,只需要将模型放在一个list中即可。
另外还有extractProb和extractPrediction两个函数,extractPrediction可以很方便地从预测模型中提出预测值,extractProb可以提出预测概率。
评估模型表现
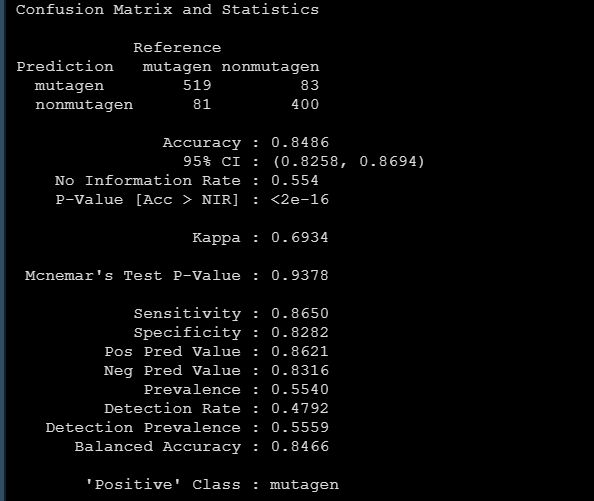
对于分类问题,我们可以用confusionMatrix很方便地得到下面的模型评估指标:
还有要报告的ROC曲线:
svmROC <- roc(svmProb$mutagen, svmProb$obs)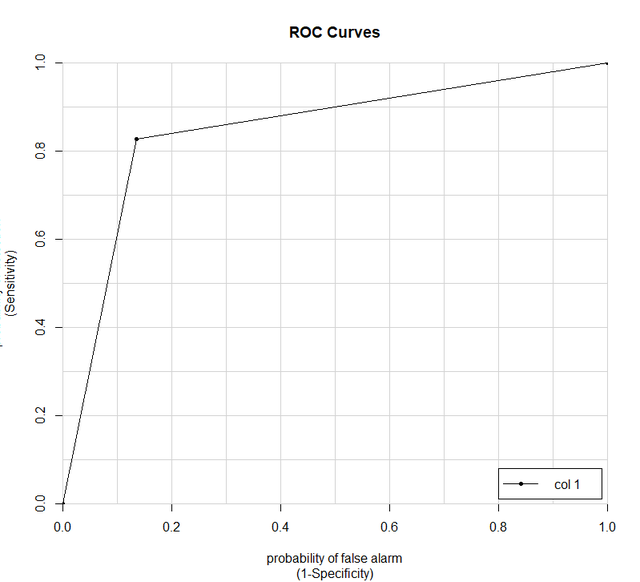
aucRoc则可以帮助我们快速地得到曲线下面积。
对于回归问题,评估模型表现的时候就没有所谓的accuracy and the Kappa statistic了,我们关心R2,plotObsVsPred可以方便地画出实际值和预测值的走势,关心rmse和mae,calc_rmse函数可以帮助计算rmse,get_best_result函数可以输出R方等指标。
预测因子选择
预测因子的重要性作图,有时候我们的数据变量很多,或者叫维度很多,从而导致维度灾难,好多的预测因子其实并不能给模型提供信息,预测因子的选择则是要在尽量使得模型精简的情况下不损害模型的表现。
varImp可以帮助我们查看各个预测因子对模型的贡献重要性,并且这个重要性是以得分的形式给出的,分怎么计算的,我也不知道。获得各个预测因子重要性得分的代码如下:
varImp(gbmFit, scale = FALSE)
更直观的我们将该对象plot下,就可以得到预测因子重要性的面条图如下:
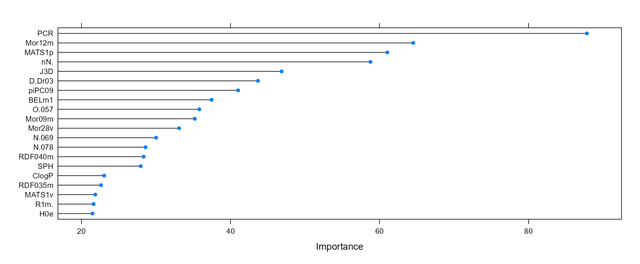
上面的图中只列出了重要性前20的变量,我们其实是有655个变量的,但是有200多个的重要性得分均为0,所以跑模型的时候其实是可以完全不要它们的。
小结
今天给大家简单介绍了在caret中做预测模型的一些知识,感谢大家耐心看完,自己的文章都写的很细,重要代码都在原文中,希望大家都可以自己做一做,
R数据分析:用R建立预测模型的更多相关文章
- R数据分析:跟随top期刊手把手教你做一个临床预测模型
临床预测模型也是大家比较感兴趣的,今天就带着大家看一篇临床预测模型的文章,并且用一个例子给大家过一遍做法. 这篇文章来自护理领域顶级期刊的文章,文章名在下面 Ballesta-Castillejos ...
- R数据分析:临床预测模型中校准曲线和DCA曲线的意义与做法
之前给大家写过一个临床预测模型:R数据分析:跟随top期刊手把手教你做一个临床预测模型,里面其实都是比较基础的模型判别能力discrimination的一些指标,那么今天就再进一步,给大家分享一些和临 ...
- 数据分析与R语言-概念点(一)
一.数据分析 1.数据分析的多层模型 常用的统计量 常用的算法 常用的数据分析工具 常见的报表 二.R语言 1.什么是R语言? R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个 ...
- 精心整理(含图版)|你要的全拿走!(R数据分析,可视化,生信实战)
本文首发于“生信补给站”公众号,https://mp.weixin.qq.com/s/ZEjaxDifNATeV8fO4krOIQ更多关于R语言,ggplot2绘图,生信分析的内容,敬请关注小号. 为 ...
- R数据分析:潜类别轨迹模型LCTM的做法,实例解析
最近看了好多潜类别轨迹latent class trajectory models的文章,发现这个方法和我之前常用的横断面数据的潜类别和潜剖面分析完全不是一个东西,做纵向轨迹的正宗流派还是这个方法,当 ...
- R数据分析:二分类因变量的混合效应,多水平logistics模型介绍
今天给大家写广义混合效应模型Generalised Linear Random Intercept Model的第一部分 ,混合效应logistics回归模型,这个和线性混合效应模型一样也有好几个叫法 ...
- R数据分析:如何简洁高效地展示统计结果
之前给大家写过一篇数据清洗的文章,解决的问题是你拿到原始数据后如何快速地对数据进行处理,处理到你基本上可以拿来分析的地步,其中介绍了如何选变量如何筛选个案,变量重新编码,如何去重,如何替换缺失值,如何 ...
- 【R笔记】R语言函数总结
R语言与数据挖掘:公式:数据:方法 R语言特征 对大小写敏感 通常,数字,字母,. 和 _都是允许的(在一些国家还包括重音字母).不过,一个命名必须以 . 或者字母开头,并且如果以 . 开头,第二个字 ...
- python文件操作打开模式 r,w,a,r+,w+,a+ 区别辨析
主要分成三大类: r 和 r+ "读"功能 r 只读 r+ 读写(先读后写) 辨析:对于r,只有读取功能,利用光标的移动,可以选择要读取的内容. 对于r+,同时具有读和写 ...
- R语言 启动报错 *** glibc detected *** /usr/lib64/R/bin/exec/R: free(): invalid next size (fast): 0x000000000263a420 *** 错误 解决方案
*** glibc detected *** /usr/lib64/R/bin/exec/R: free(): invalid next size (fast): 0x000000000263a420 ...
随机推荐
- 记ettercap0.8.3的DNS欺骗
无意间接触到这个叫中间人攻击,找了些教程自己搞了一遍. 局域网内测试,kali虚拟机桥接本地网络,不然不在一个段上面.kali 192.168.1.191 win10 :192.168.1.7 ett ...
- python基础知识-day7(文件操作)
1.文件IO操作: 1)操作文件使用的函数是open() 2)操作文件的模式: a.r:读取文件 b.w:往文件里边写内容(先删除文件里边已有的内容) c.a:是追加(在文件基础上写入新的内容) d. ...
- oracle备份数据库数据及导入数据库
1.oracle数据库备份和导入 bat 脚本 scott oracle数据库用户名称 123456 数据库scott用户下的密码 192.168.124.8 本电脑IP orcl 为oracle库 ...
- MySql字段增删改语句
新增表字段:alter table 表名 需要添加的字段信息; ALTER TABLE nation add seq VARCHAR(20) COMMENT '顺序' 字段名的修改:alter tab ...
- Halcon图片标定,使得后续图片处理过后变成与模板图片一样
随便选择一张图片 对这张图片进行旋转矫正之后,图片就变成了一个模板图片.它的区域region位置如图所示: 当来了一张新的图片的时候,让它与region比较,与模板的位置有明显的偏差, 如图所示: ...
- 《SVDNet for Pedestrian Retrieval》理解
<SVDNet for Pedestrian Retrieval>理解 Abstract: 这篇文章提出了一个用于检索问题的SVDNet,聚焦于在行人再识别上的应用.我们查看卷积神经网络中 ...
- 云ATM架构设计
云ATM架构设计 启动程序(Start.java) public class Start { public static void main(String[] args) { MainView vie ...
- day03_2_流程控制
# 流程控制 学习目标: ~~~txt1. idea安装与使用2. 流程控制if...else结构3. 流程控制switch结构4. 流程控制循环结构5. 流程控制关键字~~~ # 一.流程控制概述 ...
- 【Azure 事件中心】Azure Event Hub 新功能尝试 -- 异地灾难恢复 (Geo-Disaster Recovery)
问题描述 关于Event Hub(事件中心)的灾备方案,大多数就是新建另外一个备用的Event Hub,当主Event Hub出现不可用的情况时,就需要切换到备Event Hub上. 而在切换的过程中 ...
- Go语言基础四:数组和指针
GO语言中数组和指针 数组 Go语言提供了数组类型的数据结构. 数组是同一数据类型元素的集合.这里的数据类型可以是整型.字符串等任意原始的数据类型.数组中不允许混合不同类型的元素.(当然,如果是int ...