vivo互联网机器学习平台的建设与实践
vivo 互联网产品团队 - Wang xiao
随着广告和内容等推荐场景的扩展,算法模型也在不断演进迭代中。业务的不断增长,模型的训练、产出迫切需要进行平台化管理。vivo互联网机器学习平台主要业务场景包括游戏分发、商店、商城、内容分发等。本文将从业务场景、平台功能实现两个方面介绍vivo内部的机器学习平台在建设与实践中的思考和优化思路。
一、写在前面
随着互联网领域的快速发展,数据体量的成倍增长以及算力的持续提升,行业内都在大力研发AI技术,实现业务赋能。算法业务往往专注于模型和调参,而工程领域是相对薄弱的一个环节。建设一个强大的分布式平台,整合各个资源池,提供统一的机器学习框架,将能大大加快训练速度,提升效率,带来更多的可能性,此外还有助于提升资源利用率。希望通过此文章,初学者能对机器学习平台,以及生产环境的复杂性有一定的认识。
二、业务背景
截止2022年8月份,vivo在网用户2.8亿,应用商店日活跃用户数7000万+。AI应用场景丰富,从语音识别、图像算法优化、以及互联网常见场景,围绕着应用商店、浏览器、游戏中心等业务场景的广告和推荐诉求持续上升。
如何让推荐系统的模型迭代更高效,用户体验更好,让业务场景的效果更佳,是机器学习平台的一大挑战,如何在成本、效率和体验上达到平衡。
从下图可以了解到,整个模型加工运用的场景是串行可闭环的,对于用户的反馈需要及时进行特征更新,不断提升模型的效果,基于这个链路关系的基础去做效率的优化,建设一个通用高效的平台是关键。
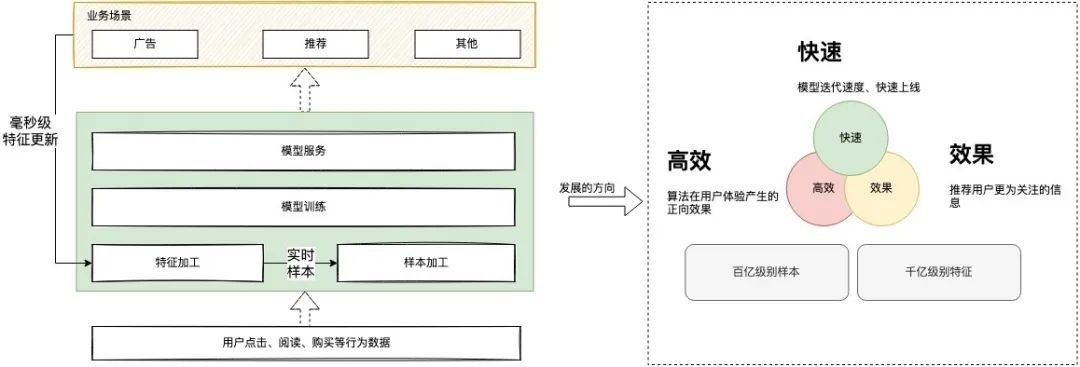
三、vivo机器学习平台的设计思路
3.1 功能模块
基于上图业务场景的链路关系,我们可以对业务场景进行归类,根据功能不同,通用的算法平台可划分为三步骤:数据处理「对应通用的特征平台,提供特征和样本的数据支撑」、模型训练「对应通用的机器学习平台,用于提供模型的训练产出」、模型服务「对应通用的模型服务部署,用于提供在线模型预估」,三个步骤都可自成体系,成为一个独立的平台。
本文将重点阐述模型训练部分,在建设vivo机器学习平台过程中遇到的挑战以及优化思路。
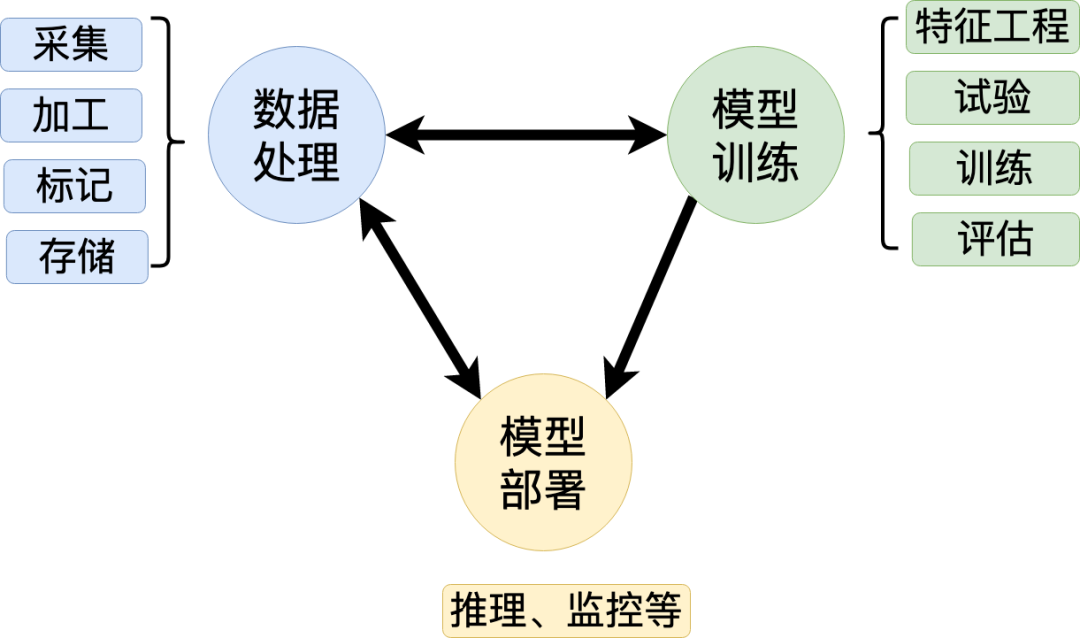
1.数据处理,围绕数据相关的工作,包括采集、加工、标记和存储。
其中,采集、加工、存储与大数据平台的场景相吻合,标记场景是算法平台所独有的。
数据采集,即从外部系统获得数据,使用Bees{vivo数据采集平台}来采集数据。
数据加工,即将数据在不同的数据源间导入导出,并对数据进行聚合、清洗等操作。
数据标记,是将人类的知识附加到数据上,产生样本数据,以便训练出模型能对新数据推理预测。
数据存储,根据存取的特点找到合适的存储方式。
2. 模型训练,即创建模型的过程,包括特征工程、试验、训练及评估模型。
特征工程,即通过算法工程师的知识来挖掘出数据更多的特征,将数据进行相应的转换后,作为模型的输入。
试验,即尝试各种算法、网络结构及超参,来找到能够解决当前问题的最好的模型。
模型训练,主要是平台的计算过程,平台能够有效利用计算资源,提高生产力并节省成本。
3.模型部署,是将模型部署到生产环境中进行推理应用,真正发挥模型的价值。
通过不断迭代演进,解决遇到的各种新问题,从而保持在较高的服务水平。
4. 对平台的通用要求,如扩展能力,运维支持,易用性,安全性等方面。
由于机器学习从研究到生产应用处于快速发展变化的阶段,所以框架、硬件、业务上灵活的扩展能力显得非常重要。任何团队都需要或多或少的运维工作,出色的运维能力能帮助团队有效的管理服务质量,提升生产效率。
易用性对于小团队上手、大团队中新人学习都非常有价值,良好的用户界面也有利于深入理解数据的意义。
安全性则是任何软件产品的重中之重,需要在开发过程中尽可能规避。
3.2 模型训练相关
模型训练包括了两个主要部分,一是算法工程师进行试验,找到对应场景的最佳模型及参数,称之为“模型试验”,二是计算机训练模型的过程,主要侧重平台支持的能力,称之为“训练模型”。
建模是算法工程师的核心工作之一。建模过程涉及到很多数据工作,称为特征工程,主要是调整、转换数据。主要任务是要让数据发挥出最大的价值,满足业务诉求。
3.2.1 模型试验
特征工作和超参调整是建模过程中的核心工作。特征工作主要对数据进行预处理,便于这部分输入模型的数据更好的表达信息,从而提升模型输出结果的质量。
数据和特征工程决定模型质量的上限,而算法和超参是无限逼近这个上限。
超参调整包括选择算法、确认网络结构、初始参数,这些依赖于算法工程师丰富的经验,同时需要平台支持试验来测试效果。
特征工程和超参调整是相辅相成的过程。加工完特征后,需要通过超参的组合来验证效果。效果不理想时,需要从特征工程、超参两个方面进行思索、改进,反复迭代后,才能达到理想的效果。
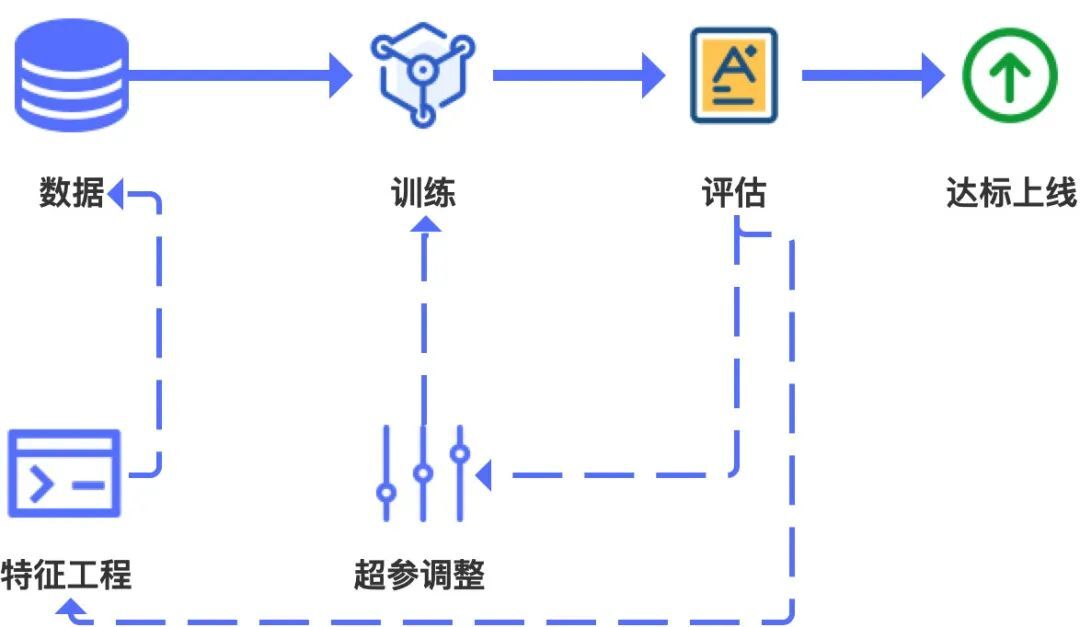
3.2.2 训练模型
可通过标准化数据接口来提高快速试验的速度,也能进行试验效果的比较。底层支持docker操作系统级的虚拟化方案,部署速度快,同时能将模型直接部署上线。用户无需对训练模型进行更多定制化的操作,批量提交任务能节约使用者的时间,平台可以将一组参数组合的试验进行比较,提供更友好的使用界面。
其次,由于训练的方向较多,需要算力管理自动规划任务和节点的分配,甚至可以根据负载情况,合理利用空闲资源。
四、vivo机器学习平台实践
前面我们介绍了机器学习平台的背景和发展方向,现在我们来介绍下,平台在解决用户问题部分的困扰和解决思路。
4.1 平台能力矩阵
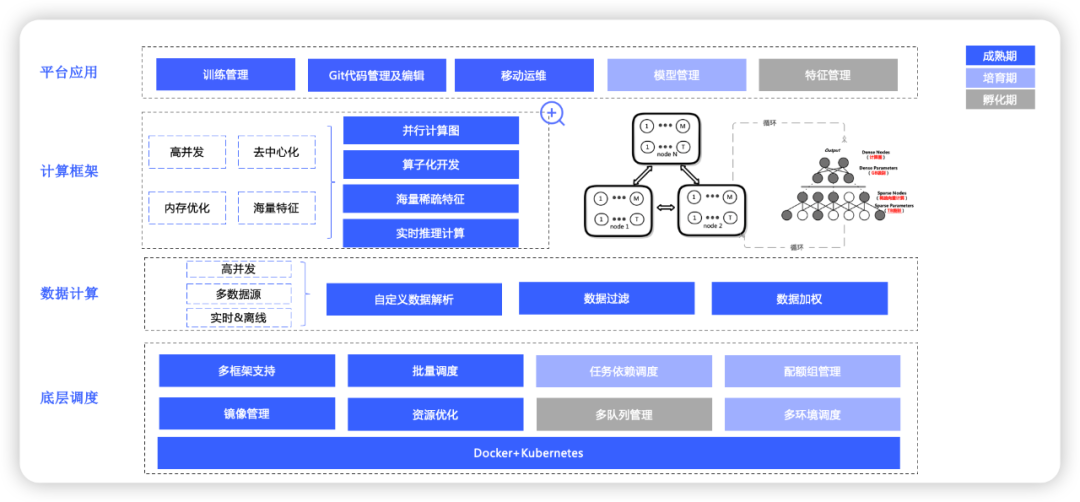
机器学习平台主要目标是围绕模型训练进行深耕,并辅助用户进行模型决策,更快的进行模型部署。
以此为目标分为两个方向,训练框架的优化能够支撑大规模模型的分布式计算,调度能力优化能够支持批次模型的执行。
在调度能力上,平台由原生k8s调度,单个训练调度的效率较低,升级为kube-batch批量调度,到以混合云精细化编排为目标,当前主要处于灵活性调度策略的形式。
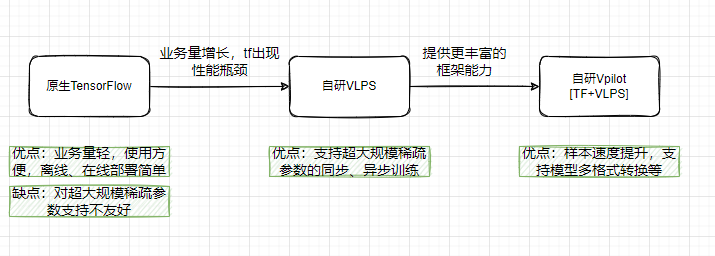
在训练框架上,从原生Tensorflow模型,随着特征和样本规模的扩大,自研了超大规模的训练框架vlps,当前处于TensorFlow+vlps结合的新框架状态。
4.2 平台能力介绍
平台能力建设主要围绕模型试验和训练模型的运用,运用过程中遇到的痛点和难点如何解决,是我们在实践中的关键。同时,训练框架也是平台关键能力的体验,基于业务的复杂度,持续对框架进行优化。
已覆盖公司内部算法工程师模型调试的工作,已达到亿级样本,百亿特征的规模。
4.2.1 资源管理
痛点:
机器学习平台属于计算密集型的平台。
业务场景不同,是否完全按照业务分组进行资源划分;
资源池划分过小,会导致资源利用率低且没办法满足业务激增的资源诉求;
资源不足以满足业务诉求时,会存在排队情况导致模型更新不及时;
如何管理好算力,提效与降本的平衡,是平台资源管理的一个核心问题。
解决思路:
资源管理的基本思路是将所有计算资源集中起来,按需分配,让资源使用率尽量接近100%。任何规模的资源都是有价值的。
比如,一个用户,只有一个计算节点,有多条计算任务时,资源管理通过队列可减少任务轮换间的空闲时间,比手工启动每条计算任务要高效很多。多计算节点的情况,资源管理能自动规划任务和节点的分配,让计算节点尽量都在使用中,而不需要人为规划资源,并启动任务。多用户的情况下,资源管理可以根据负载情况,合理利用其它用户或组的空闲资源。随着节点数量的增加,基于有限算力提供更多业务支持是必经之路。
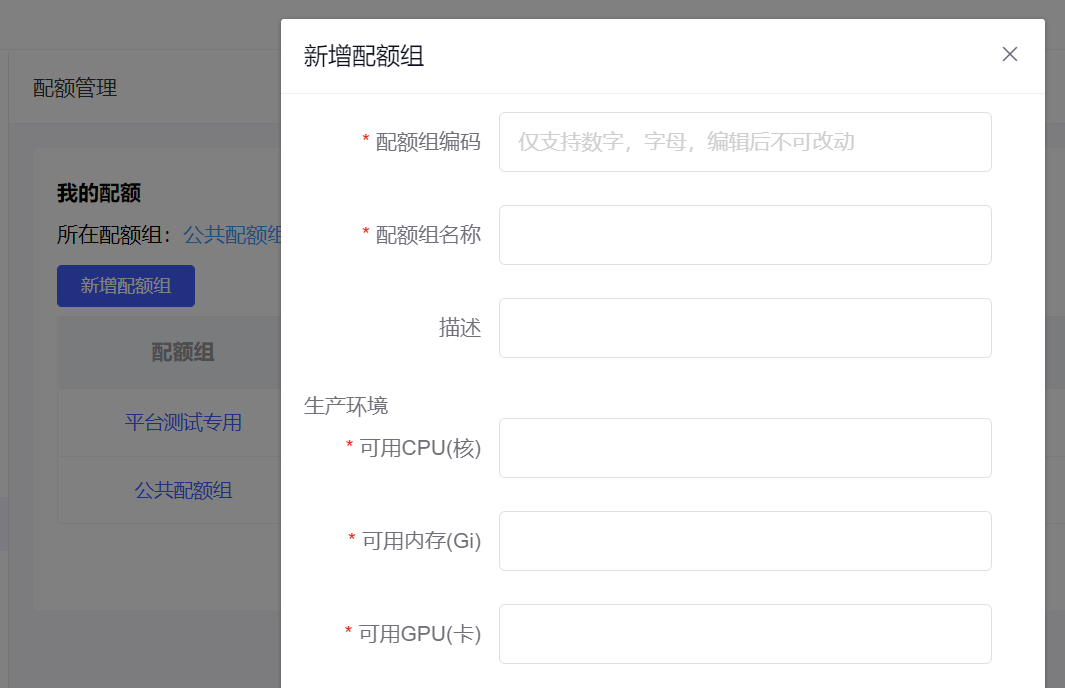
1.以配额限资源滥用:
新增配额组和个人配额,减少业务之间的相互干扰,尽可能满足各组的资源需要,并且配额组支持临时扩容和共享,解决偶发性激增的资源诉求;限额后用户仅支持在有限资源下使用,让用户自我调节高优先级训练。
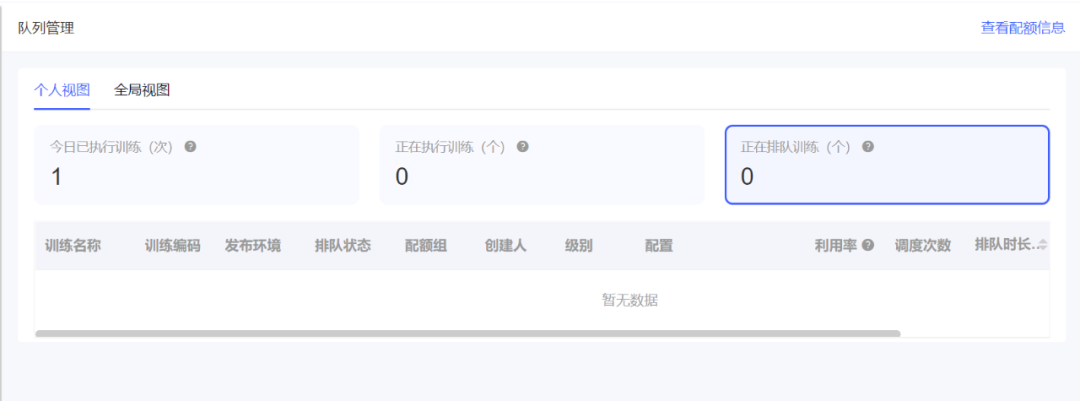
2.以调度促资源优化:
新增生产环境,确认模型已经正常迭代,在合理利用率的情况下切换至高优环境,提供更高性能的资源池;同时提供调度打分机制,围绕资源颗粒度、配置合理性等维度,让合理的训练资源更快的拉起,减少调度卡住情况;
上线多维度调度打分机制后,平台不合理训练任务有大幅度下降,资源效率提升。
围绕并不限于以下维度:最大运行时长、排队时长、cpu&内存&gpu颗粒度和总需求量等。
4.2.2 框架自研
痛点:
随着样本和特征规模增加后,框架的性能瓶颈凸显,需要提升推理计算的效率。
发展路径:
每一次的发展路径主要基于业务量的发展,寻求最佳的训练框架,框架的每一次版本升级都打包为镜像,支持更多模型训练。
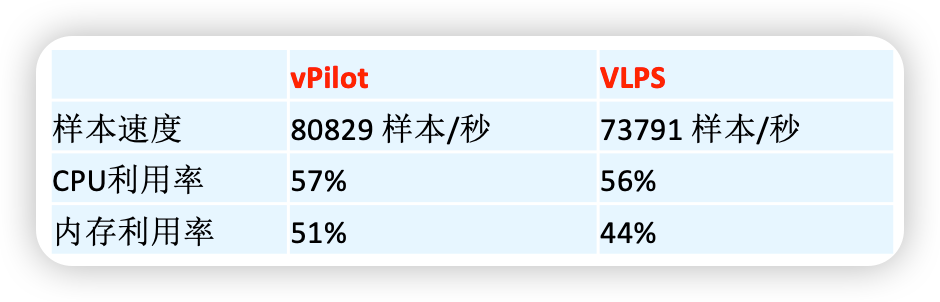
当前效果:
4.2.3 训练管理
痛点:
如何支持多种分布式训练框架,满足算法工程师的业务诉求,让用户无需关心底层机器调度和运维;如何让算法工程师快速新建训练,执行训练,可查看训练状态,是训练管理的关键。
解决思路:
上传代码至平台的文件服务器和git都可以进行读取,同时在平台填写适量的参数即可快速发起分布式训练任务。同时还支持通过OpenAPI,便于开发者在脱离控制台的情况下也能完成机器学习业务。
围绕训练模型相关的配置信息,分为基础信息设置、资源信息设置、调度依赖设置、告警信息设置和高级设置。在试验超参的过程中,经常需要对一组参数组合进行试验。
批量提交任务能节约使用者时间。平台也可以将这组结果直接进行比较,提供更友好的界面。训练读取文件服务器或git的脚本,即可快速执行训练。
1.可视化高效创建训练
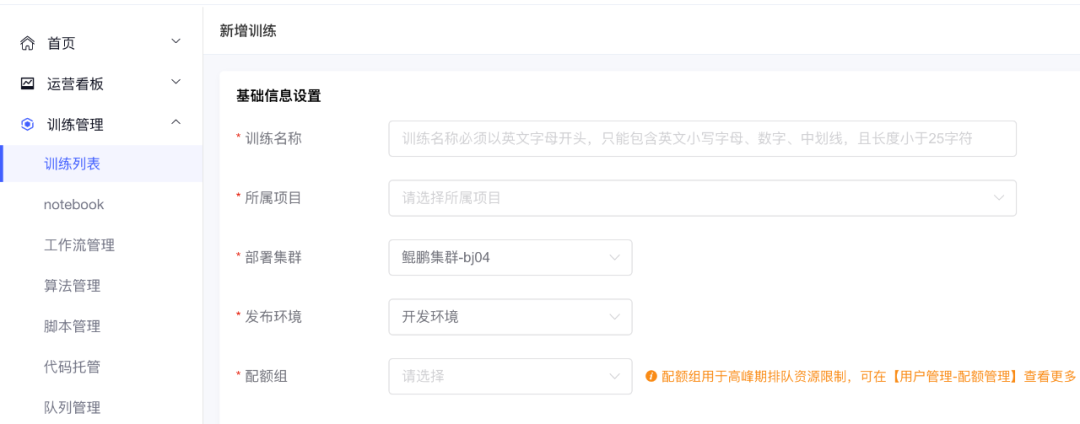
2. 准确化快速修改脚本
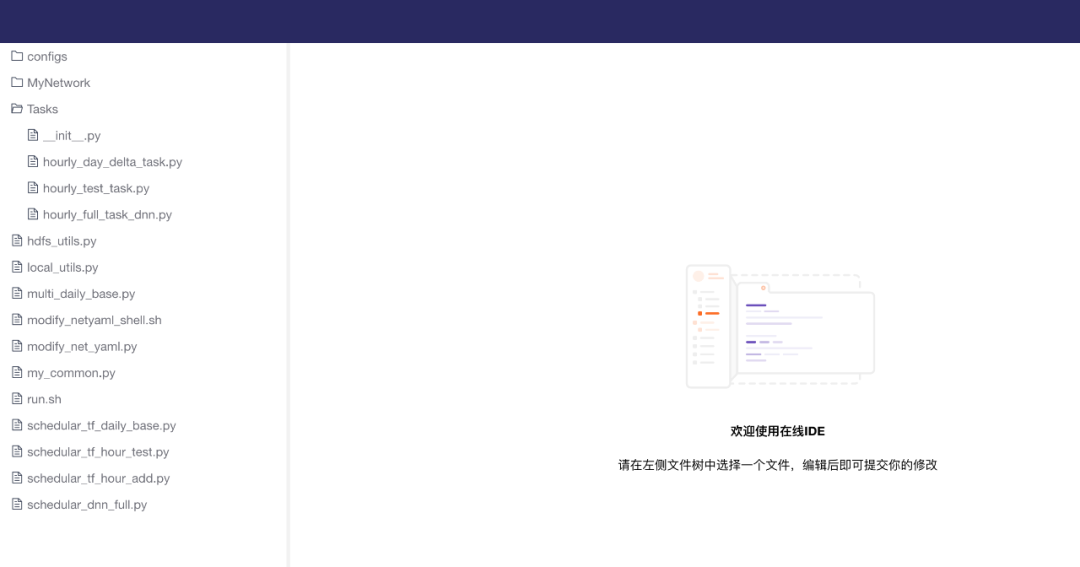
3. 实时化监控训练变动
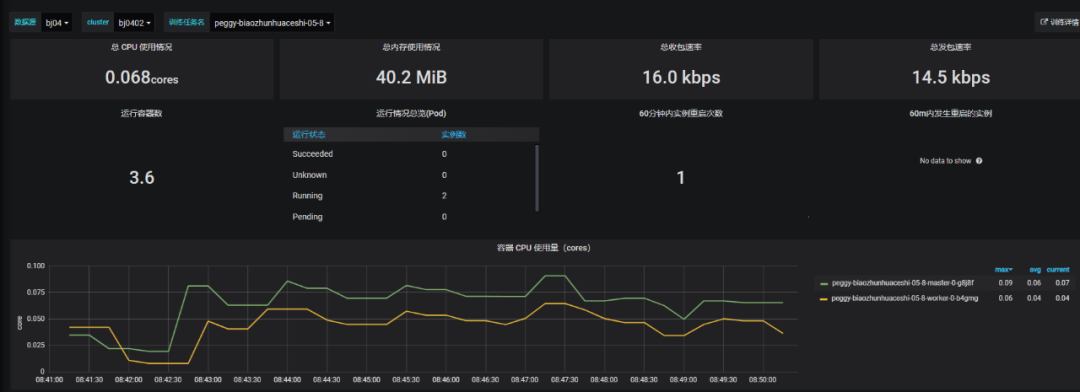
4.2.4 交互式开发
痛点:
算法工程师调试脚本成本较高,算法工程师和大数据工程师有在线调试脚本的诉求,可直接通过浏览器运行代码,同时在代码块下方展示运行结果。
解决思路:
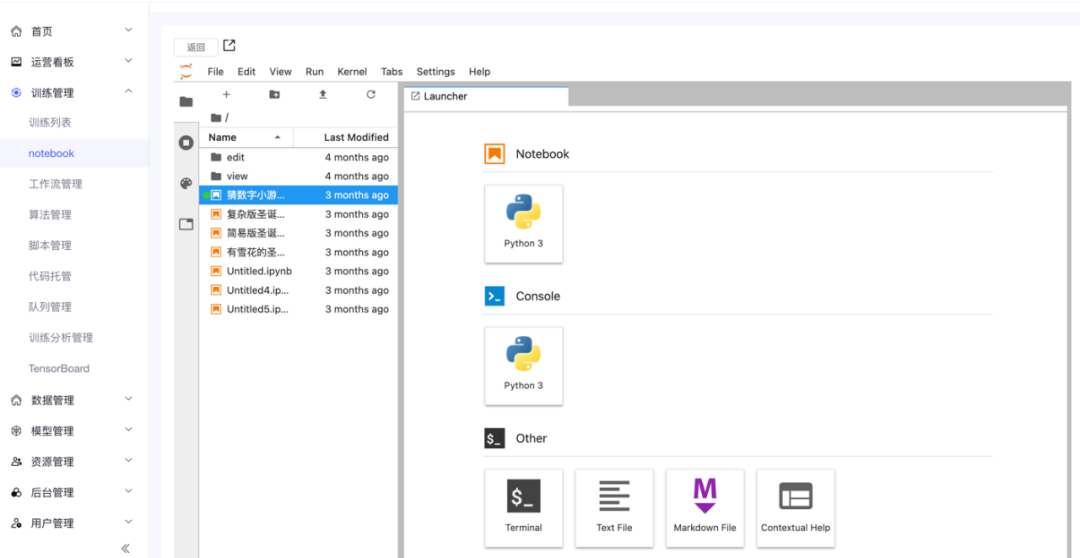
在交互式工具中进行试验、开发,如:jupyter notebook,提供所见即所得的交互式体验,对调试代码的过程非常方便。
在交互试验的场景下,需要独占计算资源。机器学习平台需要提供能为用户保留计算资源的功能。如果计算资源有限,可对每个用户申请的计算资源总量进行限制,并设定超时时间。
例如,若一周内用户没有进行资源使用后, 就收回保留资源。在收回资源后,可继续保留用户的数据。重新申请资源后,能够还原上次的工作内容。在小团队中,虽然每人保留一台机器自己决定如何使用更方便,但是用机器学习平台来统一管理,资源的利用率可以更高。团队可以聚焦于解决业务问题,不必处理计算机的操作系统、硬件等出现的与业务无关的问题。
五、总结
目前vivo机器学习平台支撑了互联网领域的算法离线训练,使算法工程师更关注于模型策略的迭代优化,从而实现为业务赋能。未来我们会在以下方面继续探索:
1.实现平台能力的贯通
当前特征、样本还是模型的读取都是通过hdfs实现的,在平台上的告警、日志信息都未关联上,后续可以进行平台能力贯通;
平台的数据和模型还有标准化的空间,降低学习成本,提升模型开发的效率。
2. 加强框架层面的预研
研究不同分布式训练框架对模型效果的影响,适配不同的业务场景;
提供预置的参数,实现算法、工程、平台的解耦,降低用户的使用门槛。
vivo互联网机器学习平台的建设与实践的更多相关文章
- vivo统一告警平台设计与实践
一.背景 一套监控系统检测和告警是密不可分的,检测用来发现异常,告警用来将问题信息发送给相应的人.vivo监控系统1.0时代各个监控系统分别维护一套计算.存储.检测.告警收敛逻辑,这种架构下对底层数据 ...
- vivo数据库与存储平台的建设和探索
本文根据Xiao Bo老师在"2021 vivo开发者大会"现场演讲内容整理而成.公众号回复[2021VDC]获取互联网技术分会场议题相关资料. 一.数据库与存储平台建设背景 以史 ...
- Redis 在 vivo 推送平台的应用与优化实践
一.推送平台特点 vivo推送平台是vivo公司向开发者提供的消息推送服务,通过在云端与客户端之间建立一条稳定.可靠的长连接,为开发者提供向客户端应用实时推送消息的服务,支持百亿级的通知/消息推送,秒 ...
- vivo商城促销系统架构设计与实践-概览篇
一.前言 随着商城业务渠道不断扩展,促销玩法不断增多,原商城v2.0架构已经无法满足不断增加的活动玩法,需要进行促销系统的独立建设,与商城解耦,提供纯粹的商城营销活动玩法支撑能力. 我们将分系列来介绍 ...
- 公有云上构建云原生 AI 平台的探索与实践 - GOTC 技术论坛分享回顾
7 月 9 日,GOTC 2021 全球开源技术峰会上海站与 WAIC 世界人工智能大会共同举办,峰会聚焦 AI 与云原生两大以开源驱动的前沿技术领域,邀请国家级研究机构与顶级互联网公司的一线技术专家 ...
- vivo推送平台架构演进
本文根据Li Qingxin老师在"2021 vivo开发者大会"现场演讲内容整理而成.公众号回复[2021VDC]获取互联网技术分会场议题相关资料. 一.vivo推送平台介绍 1 ...
- 网易大数据平台的Spark技术实践
网易大数据平台的Spark技术实践 作者 王健宗 网易的实时计算需求 对于大多数的大数据而言,实时性是其所应具备的重要属性,信息的到达和获取应满足实时性的要求,而信息的价值需在其到达那刻展现才能利益最 ...
- vivo 服务端监控架构设计与实践
一.业务背景 当今时代处在信息大爆发的时代,信息借助互联网的潮流在全球自由的流动,产生了各式各样的平台系统和软件系统,越来越多的业务也会导致系统的复杂性. 当核心业务出现了问题影响用户体验,开发人员没 ...
- 搭建基于python +opencv+Beautifulsoup+Neurolab机器学习平台
搭建基于python +opencv+Beautifulsoup+Neurolab机器学习平台 By 子敬叔叔 最近在学习麦好的<机器学习实践指南案例应用解析第二版>,在安装学习环境的时候 ...
随机推荐
- SDK和API的直接区别
狭义的说法,在实际工作中, 如果对方需要你提供一个api,是指一个工程提供给另外一个工程的接口(一般是基于http协议). 如果对方需要你提供一个sdk,是指基于对方工程的编程语言,提供一个代码包.在 ...
- 如何使用Solidity和Hardhat构建你自己的NFT以及NFT交易市场
目录 目录 目录 1.ERC721的基础知识 1.1.什么是不可替代代币? 1.2.什么是 ERC-721? 1.3.什么是元数据 1.4.如何在链上保存NFT的图像 2.HardHat 3.创建项目 ...
- 从零开始Blazor Server(9)--修改Layout
目前我们的MainLayout还是默认的,这里我们需要修改为BootstrapBlazor的Layout,并且处理一下菜单. 修改MainLayout BootstrapBlazor已经自带了一个La ...
- Python基础之字符串和编码
字符串和编码 字符串也是一种数据类型,但是字符串比较特殊的是还有个编码问题. 因为计算机自能处理数字,如果徐娅处理文本,就必须先把文本转换为数字才能处理,最早的计算机子设计时候采用8个比特(bit)作 ...
- Python 实现列表与二叉树相互转换并打印二叉树封装类-详细注释+完美对齐
# Python 实现列表与二叉树相互转换并打印二叉树封装类-详细注释+完美对齐 from binarytree import build import random # https://www.cn ...
- Redis 04 列表
参考源 https://www.bilibili.com/video/BV1S54y1R7SB?spm_id_from=333.999.0.0 版本 本文章基于 Redis 6.2.6 在 Redis ...
- 长篇图解java反射机制及其应用场景
一.什么是java反射? 在java的面向对象编程过程中,通常我们需要先知道一个Class类,然后new 类名()方式来获取该类的对象.也就是说我们需要在写代码的时候(编译期或者编译期之前)就知道我们 ...
- [WPF]WPF设置单实例启动
WPF设置单实例启动 使用Mutex设置单实例启动 using System; using System.Threading; using System.Windows; namespace Test ...
- axios请求响应拦截器的应用
什么是axios拦截器? 一般在使用axios时,会用到拦截器的功能,一般分为两种:请求拦截器.响应拦截器. 请求拦截器在请求发送前进行必要操作处理 例如添加统一cookie.请求体加验证.设置请求头 ...
- Android序列化的几种实现方式
一.Serializable序列化 Serializable是java提供的一种序列化方式,其使用方式非常简单,只需要实现Serializable接口就可以实现序列化. public interfac ...